Czy zastanawiasz się, czym są schematy Postgresql, dlaczego są ważne i jak możesz ich używać, aby Twoje implementacje baz danych były bardziej wytrzymałe i łatwiejsze w utrzymaniu? Ten artykuł przedstawi podstawy schematów w Postgresql i pokaże jak je tworzyć na kilku podstawowych przykładach. Przyszłe artykuły zagłębią się w przykłady, jak zabezpieczyć i wykorzystać schematy w rzeczywistych zastosowaniach.
Po pierwsze, aby wyjaśnić potencjalne zamieszanie terminologiczne, zrozumiejmy, że w świecie Postgresql termin „schemat” jest być może nieco niefortunnie przeciążony. W szerszym kontekście systemów zarządzania relacyjnymi bazami danych (RDBMS), termin „schemat” może być rozumiany jako odnoszący się do ogólnego logicznego lub fizycznego projektu bazy danych, tj. definicji wszystkich tabel, kolumn, widoków i innych obiektów, które tworzą definicję bazy danych. W tym szerszym kontekście schemat może być wyrażony w diagramie ER (ang. entity-relationship) lub w skrypcie poleceń języka definicji danych (DDL) używanym do tworzenia bazy danych aplikacji.
W świecie Postgresql termin „schemat” może być lepiej rozumiany jako „przestrzeń nazw”. W rzeczywistości, w tabelach systemowych Postgresql, schematy są rejestrowane w kolumnach tabel o nazwie „przestrzeń nazw”, która, IMHO, jest bardziej dokładną terminologią. Jako kwestia praktyczna, ilekroć widzę „schemat” w kontekście Postgresql, po cichu reinterpretuję go jako mówiący „przestrzeń nazw”.
Możesz jednak zapytać: „Co to jest przestrzeń nazw?”. Ogólnie rzecz biorąc, przestrzeń nazw jest dość elastycznym środkiem do organizowania i identyfikowania informacji według nazwy. Na przykład, wyobraźmy sobie dwa sąsiadujące ze sobą gospodarstwa domowe, Smithów, Alice i Boba, oraz Jonesów, Boba i Cathy (por. rys. 1). Gdybyśmy używali tylko imion, mogłoby to być mylące, którą osobę mamy na myśli, gdy mówimy o Bobie. Ale dodając nazwisko, Smith lub Jones, jednoznacznie identyfikujemy, którą osobę mamy na myśli.
Często przestrzenie nazw są zorganizowane w zagnieżdżonej hierarchii. Pozwala to na efektywną klasyfikację ogromnych ilości informacji w bardzo drobnoziarnistą strukturę, taką jak na przykład system nazw domen internetowych. Na najwyższym poziomie, „.com”, „.net”, „.org”, „.edu”, i etc. definiują szerokie przestrzenie nazw, w obrębie których zarejestrowane są nazwy dla konkretnych podmiotów, więc na przykład „severalnines.com” i „postgresql.org” są jednoznacznie zdefiniowane. Ale pod każdą z nich istnieje wiele wspólnych subdomen, takich jak „www”, „mail” i „ftp”, na przykład, które same w sobie są duplikatami, ale w odpowiednich przestrzeniach nazw są unikalne.
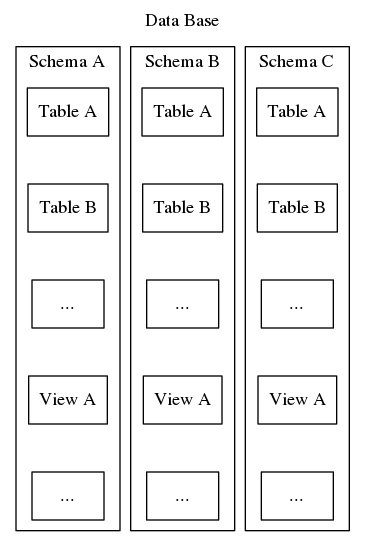
Schematy Postgresql służą temu samemu celowi organizowania i identyfikowania, jednak w przeciwieństwie do drugiego przykładu powyżej, schematy Postgresql nie mogą być zagnieżdżone w hierarchii. Podczas gdy baza danych może zawierać wiele schematów, istnieje tylko jeden poziom, a więc w obrębie bazy danych nazwy schematów muszą być unikalne. Ponadto, każda baza danych musi zawierać przynajmniej jeden schemat. Za każdym razem, gdy tworzona jest nowa baza danych, tworzony jest domyślny schemat o nazwie „public”. Zawartość schematu zawiera wszystkie inne obiekty bazy danych, takie jak tabele, widoki, procedury składowane, trigery, itp. Aby to zobrazować, odwołaj się do rysunku 2, który przedstawia zagnieżdżenie przypominające lalkę Matrixa, pokazujące, gdzie schematy pasują do struktury bazy danych Postgresql.
Poza zwykłym organizowaniem obiektów bazy danych w logiczne grupy, aby uczynić je bardziej zarządzalnymi, schematy służą praktycznemu celowi unikania kolizji nazw. Jednym z paradygmatów operacyjnych jest definiowanie schematu dla każdego użytkownika bazy danych, aby zapewnić pewien stopień izolacji, przestrzeń, w której użytkownicy mogą definiować własne tabele i widoki bez wzajemnego zakłócania się. Innym podejściem jest zainstalowanie narzędzi firm trzecich lub rozszerzeń bazy danych w poszczególnych schematach, aby zachować wszystkie powiązane komponenty logicznie razem. W późniejszym artykule z tej serii wyszczególnione zostanie nowatorskie podejście do projektowania aplikacji, wykorzystujące schematy jako środek pośredni do ograniczenia ekspozycji fizycznego projektu bazy danych, a zamiast tego przedstawiające interfejs użytkownika, który rozwiązuje problem kluczy syntetycznych i ułatwia długoterminową konserwację oraz zarządzanie konfiguracją w miarę ewolucji wymagań systemowych.
Zróbmy trochę kodu!
Najprostszym poleceniem do utworzenia schematu w bazie danych jest
CREATE SCHEMA hollywood;To polecenie wymaga uprawnień create w bazie danych, a nowo utworzony schemat „hollywood” będzie własnością użytkownika wywołującego polecenie. Bardziej złożone wywołanie może zawierać opcjonalne elementy określające innego właściciela, a nawet zawierać instrukcje DDL instytuujące obiekty bazy danych w ramach schematu w jednym poleceniu!
Ogólny format to
CREATE SCHEMA schemaname ]gdzie „username” jest nazwą użytkownika, który będzie właścicielem schematu, a „schema_element” może być jednym z określonych poleceń DDL (odnieś się do dokumentacji Postgresql dla szczegółów). Do użycia opcji AUTHORIZATION wymagane są uprawnienia superużytkownika.
Więc na przykład, aby utworzyć schemat o nazwie „hollywood” zawierający tabelę o nazwie „filmy” i widok o nazwie „zwycięzcy” w jednym poleceniu, możesz wykonać
CREATE SCHEMA hollywood CREATE TABLE films (title text, release date, awards text) CREATE VIEW winners AS SELECT title, release FROM films WHERE awards IS NOT NULL;Dodatkowe obiekty bazy danych mogą być następnie tworzone bezpośrednio, na przykład dodatkowa tabela zostanie dodana do schematu za pomocą
CREATE TABLE hollywood.actors (name text, dob date, gender text);Zauważ w powyższym przykładzie poprzedzenie nazwy tabeli nazwą schematu. Jest to wymagane, ponieważ domyślnie, czyli bez wyraźnej specyfikacji schematu, nowe obiekty bazy danych są tworzone w ramach bieżącego schematu, który omówimy w następnej kolejności.
Przypomnij sobie, jak w pierwszym przykładzie przestrzeni nazw powyżej, mieliśmy dwie osoby o imieniu Bob, i opisaliśmy, jak dekonfliktować lub odróżnić je przez włączenie nazwiska. Ale w każdym z gospodarstw domowych Smith i Jones oddzielnie, każda rodzina rozumie „Bob” odnosić się do tego, który idzie z tego konkretnego gospodarstwa domowego. Więc na przykład w kontekście każdego gospodarstwa domowego Alice nie musi zwracać się do męża jako Bob Jones, a Cathy nie musi odnosić się do męża jako Bob Smith: mogą po prostu powiedzieć „Bob”.
Obecny schemat Postgresql jest jak gospodarstwo domowe w powyższym przykładzie. Obiekty w bieżącym schemacie mogą być przywoływane bez zastrzeżeń, ale odwoływanie się do podobnie nazwanych obiektów w innych schematach wymaga zakwalifikowania nazwy przez poprzedzenie nazwy schematu, jak powyżej.
Bieżący schemat pochodzi z parametru konfiguracyjnego „search_path”. Parametr ten przechowuje oddzieloną przecinkami listę nazw schematów i można go sprawdzić za pomocą polecenia
SHOW search_path;lub ustawić na nową wartość za pomocą polecenia
SET search_path TO schema ;Pierwsza nazwa schematu na liście jest „bieżącym schematem” i jest miejscem, w którym tworzone są nowe obiekty, jeśli została określona bez kwalifikacji nazwy schematu.
Oddzielona przecinkami lista nazw schematów służy również do określania kolejności wyszukiwania, za pomocą której system znajduje istniejące obiekty o nieokreślonej nazwie. Na przykład, wracając do sąsiedztwa Smitha i Jonesa, dostawa paczki zaadresowanej tylko do „Boba” wymagałaby odwiedzenia każdego gospodarstwa domowego, aż do znalezienia pierwszego mieszkańca o imieniu „Bob”. Zauważ, że może to nie być zamierzony odbiorca. Ta sama logika odnosi się do Postgresql. System wyszukuje tabele, widoki i inne obiekty w schematach w kolejności zgodnej ze ścieżką wyszukiwania (search_path), a następnie używany jest pierwszy znaleziony obiekt pasujący do nazwy. Obiekty nazwane według schematu są używane bezpośrednio bez odniesienia do ścieżki wyszukiwania
W domyślnej konfiguracji zapytanie o zmienną konfiguracyjną search_path ujawnia tę wartość
SHOW search_path; Search_path-------------- "$user", publicSystem interpretuje pierwszą wartość pokazaną powyżej jako bieżącą nazwę zalogowanego użytkownika i uwzględnia przypadek użycia wspomniany wcześniej, w którym każdy użytkownik ma przydzielony schemat o nazwie użytkownika dla przestrzeni roboczej oddzielonej od innych użytkowników. Jeśli taki schemat nie został utworzony, wpis ten jest ignorowany, a schemat „public” staje się aktualnym schematem, w którym tworzone są nowe obiekty.
Wracając do naszego wcześniejszego przykładu tworzenia tabeli „hollywood.actors”, jeśli nie określilibyśmy nazwy tabeli nazwą schematu, wówczas tabela zostałaby utworzona w schemacie publicznym. Jeśli przewidujemy tworzenie wszystkich obiektów w ramach określonego schematu, to wygodnym rozwiązaniem może być ustawienie zmiennej search_path w następujący sposób
SET search_path TO hollywood,public;ułatwiający skrócone wpisywanie niewykwalifikowanych nazw w celu tworzenia lub dostępu do obiektów bazy danych.
Istnieje również funkcja informacji systemowej, która zwraca bieżący schemat za pomocą zapytania
select current_schema();W przypadku fat-fingingu pisowni, właściciel schematu może zmienić jego nazwę, pod warunkiem, że użytkownik ma również uprawnienia do tworzenia bazy danych, za pomocą polecenia
ALTER SCHEMA old_name RENAME TO new_name;I wreszcie, aby usunąć schemat z bazy danych, istnieje polecenie drop
DROP SCHEMA schema_name;Polecenie DROP nie powiedzie się, jeśli schemat zawiera jakiekolwiek obiekty, więc należy je najpierw usunąć, lub można opcjonalnie rekursywnie usunąć schemat z całą jego zawartością za pomocą opcji CASCADE
DROP SCHEMA schema_name CASCADE;Te podstawy pozwolą Ci zacząć rozumieć schematy!