Niezależnie od twojego wcześniejszego doświadczenia z macierzami RAID, i czy prześledziłeś wszystkie tutoriale z tej serii, czy nie, zarządzanie programowymi macierzami RAID w Linuksie nie jest bardzo skomplikowanym zadaniem po zapoznaniu się z poleceniem mdadm --manage.

W tym tutorialu przejrzymy funkcjonalność dostarczaną przez to narzędzie, abyś mógł je mieć pod ręką, gdy będziesz go potrzebował.
- Scenariusz testowania macierzy RAID
- Zarządzanie urządzeniami RAID za pomocą narzędzia mdadm
- Przykład 1: Dodanie urządzenia do macierzy RAID
- Przykład 2: Oznaczenie urządzenia RAID jako uszkodzonego i usunięcie go z macierzy
- Przykład 3: Ponowne dodanie urządzenia, które było częścią macierzy, a które zostało wcześniej usunięte
- Przykład 4: Zastąp urządzenie Raid określonym dyskiem
- Przykład 5: Oznaczanie macierzy Raid jako ro lub rw
- Summary
Scenariusz testowania macierzy RAID
Tak jak w ostatnim artykule z tej serii, dla uproszczenia użyjemy macierzy RAID 1 (lustrzanej), która składa się z dwóch dysków 8 GB (/dev/sdb i /dev/sdc) oraz początkowego urządzenia zapasowego (/dev/sdd) do zilustrowania, ale polecenia i koncepcje wymienione tutaj mają zastosowanie również do innych typów konfiguracji. Na szczęście mdadm udostępnia flagę built-in --help, która dostarcza wyjaśnień i dokumentacji dla każdej z głównych opcji.
Zacznijmy więc od wpisania:
# mdadm --manage --help
aby zobaczyć, jakie są zadania, które mdadm --manage pozwoli nam wykonać i w jaki sposób:
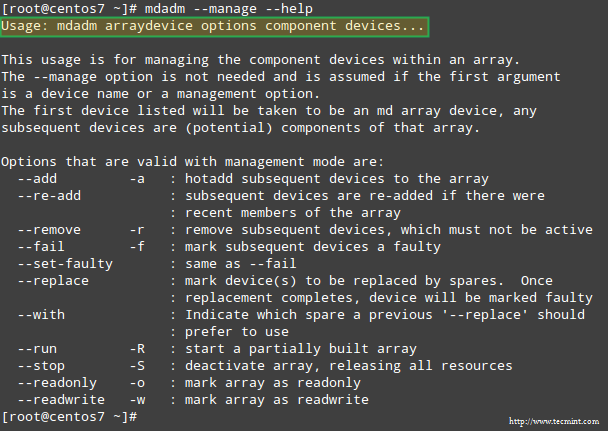
Jak widzimy na powyższym obrazku, zarządzanie macierzą RAID polega na wykonywaniu w tym czy innym czasie następujących zadań:
- (Re)Adding a device to the array.
- Oznaczenie urządzenia jako uszkodzonego.
- Usunięcie wadliwego urządzenia z macierzy.
- Wymiana wadliwego urządzenia na zapasowe.
- Uruchomienie częściowo zbudowanej macierzy.
- Zatrzymanie macierzy.
- Zaznaczyć macierz jako ro (tylko do odczytu) lub rw (odczyt-zapis).
Zarządzanie urządzeniami RAID za pomocą narzędzia mdadm
Zauważ, że jeśli pominiesz opcję --manage, mdadm i tak przyjmie tryb zarządzania. Pamiętaj o tym fakcie, aby uniknąć problemów w dalszej części drogi.
Podświetlony tekst na poprzednim obrazku pokazuje podstawową składnię do zarządzania RAIDami:
# mdadm --manage RAID options devices
Zilustrujmy to kilkoma przykładami.
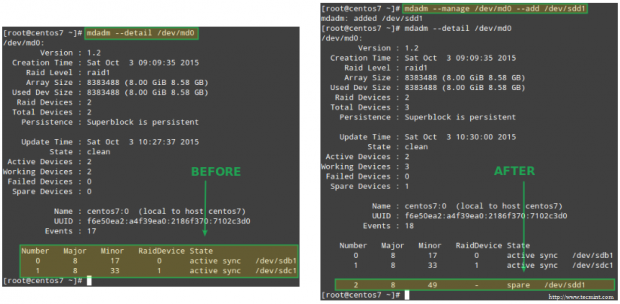
Przykład 1: Dodanie urządzenia do macierzy RAID
Zwykle dodajemy nowe urządzenie podczas wymiany uszkodzonego lub gdy mamy część zapasową, którą chcemy mieć pod ręką w razie awarii:
# mdadm --manage /dev/md0 --add /dev/sdd1
Przykład 2: Oznaczenie urządzenia RAID jako uszkodzonego i usunięcie go z macierzy
Jest to obowiązkowy krok przed logicznym usunięciem urządzenia z macierzy, a później fizycznym wyciągnięciem go z maszyny – w tej kolejności (pominięcie jednego z tych kroków może skończyć się faktycznym uszkodzeniem urządzenia):
# mdadm --manage /dev/md0 --fail /dev/sdb1
Zauważ, że urządzenie zapasowe dodane w poprzednim przykładzie jest używane do automatycznego zastąpienia uszkodzonego dysku. Ponadto natychmiast rozpoczyna się odzyskiwanie i odbudowa danych macierzy raid:
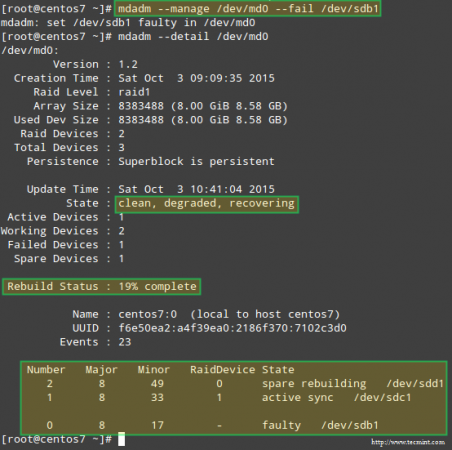
Po ręcznym wskazaniu urządzenia jako uszkodzonego można je bezpiecznie usunąć z macierzy:
# mdadm --manage /dev/md0 --remove /dev/sdb1
Przykład 3: Ponowne dodanie urządzenia, które było częścią macierzy, a które zostało wcześniej usunięte
Do tego momentu mamy działającą macierz RAID 1, która składa się z 2 aktywnych urządzeń: /dev/sdc1 oraz /dev/sdd1. Jeśli spróbujemy teraz ponownie dodać /dev/sdb1 do /dev/md0:
# mdadm --manage /dev/md0 --re-add /dev/sdb1
napotkamy błąd:
mdadm: --re-add for /dev/sdb1 to /dev/md0 is not possible
ponieważ macierz składa się już z maksymalnej możliwej liczby dysków. Mamy więc dwie możliwości: a) dodać /dev/sdb1 jako dysk zapasowy, jak pokazano w przykładzie #1, lub b) usunąć /dev/sdd1 z tablicy, a następnie ponownie dodać /dev/sdb1.
Wybieramy opcję b), i zaczniemy od zatrzymania macierzy, aby później ponownie ją złożyć:
# mdadm --stop /dev/md0# mdadm --assemble /dev/md0 /dev/sdb1 /dev/sdc1
Jeśli powyższe polecenie nie zakończy się pomyślnie dodaniem /dev/sdb1 z powrotem do macierzy, użyj polecenia z Przykładu #1, aby to zrobić.
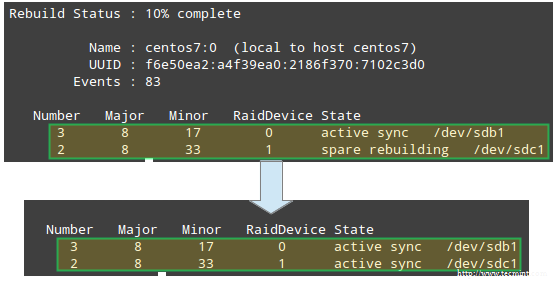
Pomimo, że mdadm początkowo wykryje nowo dodane urządzenie jako zapasowe, rozpocznie odbudowę danych, a gdy skończy to robić, powinien rozpoznać urządzenie jako aktywną część RAID:
Przykład 4: Zastąp urządzenie Raid określonym dyskiem
Zastąpienie dysku w macierzy dyskiem zapasowym jest tak proste jak:
# mdadm --manage /dev/md0 --replace /dev/sdb1 --with /dev/sdd1

W wyniku tego urządzenie po przełączniku --with zostaje dodane do macierzy RAID, natomiast dysk wskazany poprzez --replace zostaje oznaczony jako uszkodzony:
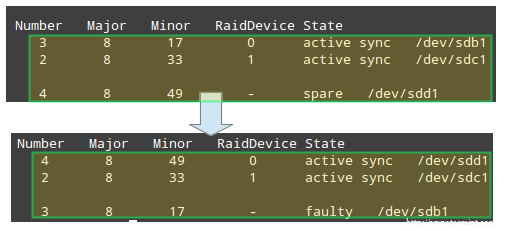
Przykład 5: Oznaczanie macierzy Raid jako ro lub rw
Po utworzeniu macierzy, aby móc z niej korzystać, musiałeś utworzyć na niej system plików i zamontować go w katalogu. To, czego prawdopodobnie nie wiedziałeś, to fakt, że możesz oznaczyć RAID jako ro, pozwalając w ten sposób na wykonywanie na nim tylko operacji odczytu, lub rw, aby móc również zapisywać na urządzeniu.
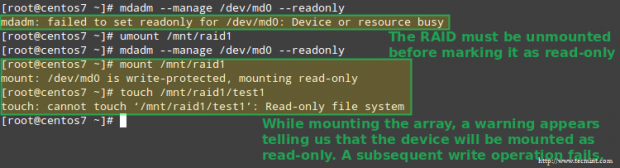
Aby oznaczyć urządzenie jako ro, należy je najpierw odmontować:
# umount /mnt/raid1# mdadm --manage /dev/md0 --readonly# mount /mnt/raid1# touch /mnt/raid1/test1
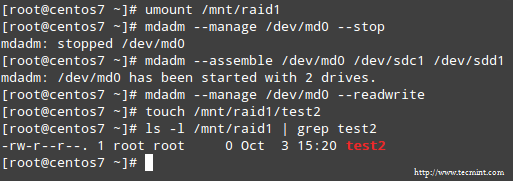
Aby skonfigurować macierz tak, aby pozwalała również na operacje zapisu, użyj opcji --readwrite. Należy pamiętać, że trzeba będzie odmontować urządzenie i zatrzymać go przed ustawieniem flagi rw:
# umount /mnt/raid1# mdadm --manage /dev/md0 --stop# mdadm --assemble /dev/md0 /dev/sdc1 /dev/sdd1# mdadm --manage /dev/md0 --readwrite# touch /mnt/raid1/test2
Summary
W tej serii wyjaśniliśmy, jak skonfigurować różne macierze RAID oprogramowania, które są używane w środowiskach korporacyjnych. Jeśli prześledziłeś artykuły i przykłady podane w tych artykułach jesteś przygotowany do wykorzystania mocy RAID w Linuksie.
Jeśli masz pytania lub sugestie, prosimy o kontakt za pomocą poniższego formularza.