Method 1, Bad: ORDER BY NEWID()
Łatwe do napisania, ale wykonuje się jak gorące, gorące śmieci, ponieważ skanuje cały indeks klastrowany, obliczając NEWID() na każdym wierszu:
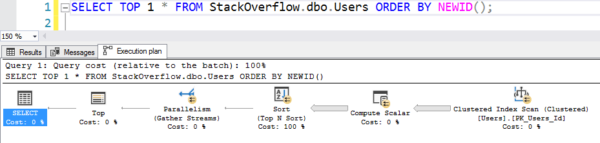
Plan ze skanowaniem
To zajęło 6 sekund na mojej maszynie, przechodząc równolegle przez wiele wątków, używając dziesiątek sekund procesora dla wszystkich tych obliczeń i sortowania. (A tabela Users nie ma nawet 1GB.)
Metoda 2, lepsza, ale dziwna: TABLESAMPLE
To wyszło w 2005 roku, i ma tonę gotchas. Jest to rodzaj wybierania losowej strony, a następnie zwracania kilku wierszy z tej strony. Pierwszy rząd jest losowy, ale reszta nie.
Transact-.SQL
|
1
|
SELECT * FROM StackOverflow.dbo.Users TABLESAMPLE (.01 PERCENT);
|
Plan wygląda, jakby wykonywał skanowanie tabeli, ale wykonuje tylko 7 logicznych odczytów:
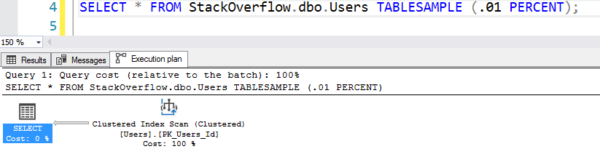
Plan z fałszywym skanowaniem
Ale oto wyniki – widać, że przeskakuje do losowej strony 8K, a następnie zaczyna odczytywać wiersze w kolejności. Nie są to naprawdę losowe wiersze.
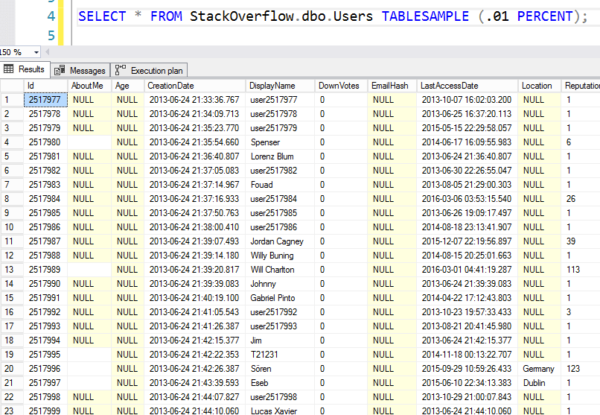
Losowe jak numery loterii mafii
Możesz zamiast tego użyć wielkości próbki ROWS, ale ma ona dość dziwne wyniki. Na przykład w tabeli Stack Overflow Users, kiedy powiedziałem TABLESAMPLE (50 ROWS), faktycznie otrzymałem 75 wierszy z powrotem. To dlatego, że SQL Server konwertuje rozmiar wiersza na wartość procentową zamiast tego.
Metoda 3, Najlepsza, ale wymaga kodu: Random Primary Key
Znajdź najwyższe pole ID w tabeli, wygeneruj losową liczbę i poszukaj tego ID. Tutaj sortujemy według ID, ponieważ chcemy znaleźć najwyższy rekord, który faktycznie istnieje (podczas gdy liczba losowa mogła zostać usunięta). Całkiem szybko, ale jest to dobre tylko dla jednego losowego wiersza. Jeśli chciałbyś mieć 10 wierszy, musiałbyś wywołać kod taki jak ten 10 razy (lub wygenerować 10 losowych numerów i użyć klauzuli IN.)
Plan wykonania pokazuje klastrowany skan indeksu, ale chwyta tylko jeden wiersz – mówimy tylko o 6 logicznych odczytach dla wszystkiego, co widzisz tutaj, i kończy się prawie natychmiast:

Plan, który może
Jest jeden problem: jeśli Id ma liczby ujemne, nie będzie działać zgodnie z oczekiwaniami. (Na przykład, powiedzmy, że zaczynasz swoje pole tożsamości na -1 i krok -1, zmierzając coraz niżej, jak moja moralność.)
Metoda 4, OFFSET-FETCH (2012+)
Daniel Hutmacher dodał to w komentarzach:
I powiedział: „Ale to działa poprawnie tylko z indeksem klastrowym. Zgaduję, że to dlatego, że będzie skanować dla (@rows) wierszy w stercie zamiast wykonywać wyszukiwanie indeksu.”
Bonus Track #1: Watch Us Discussing This
Czy kiedykolwiek zastanawiałeś się, jak to jest być na czacie w naszej firmie? Ta 10-minutowa dyskusja na Slacku da ci całkiem dobry pomysł:
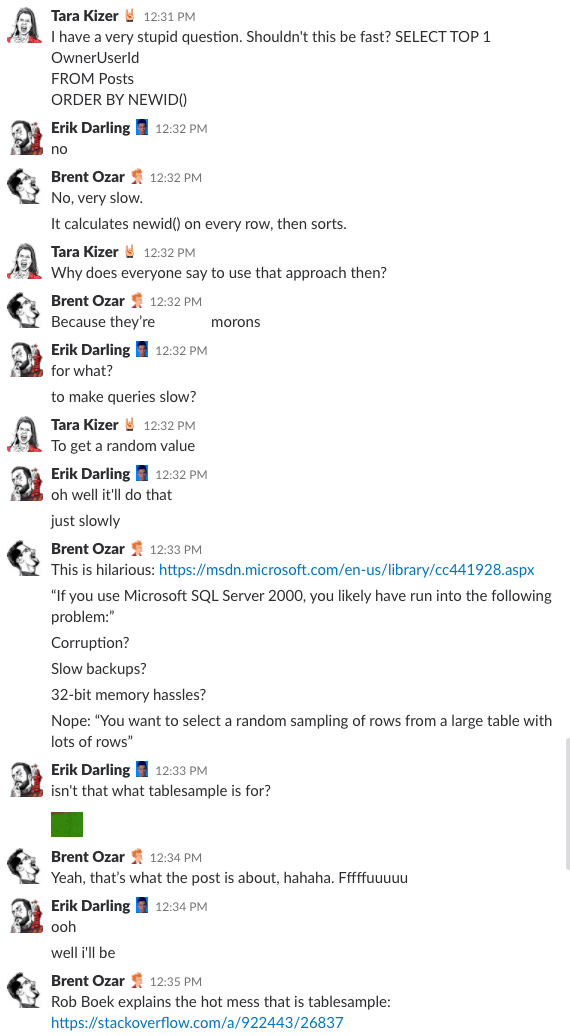
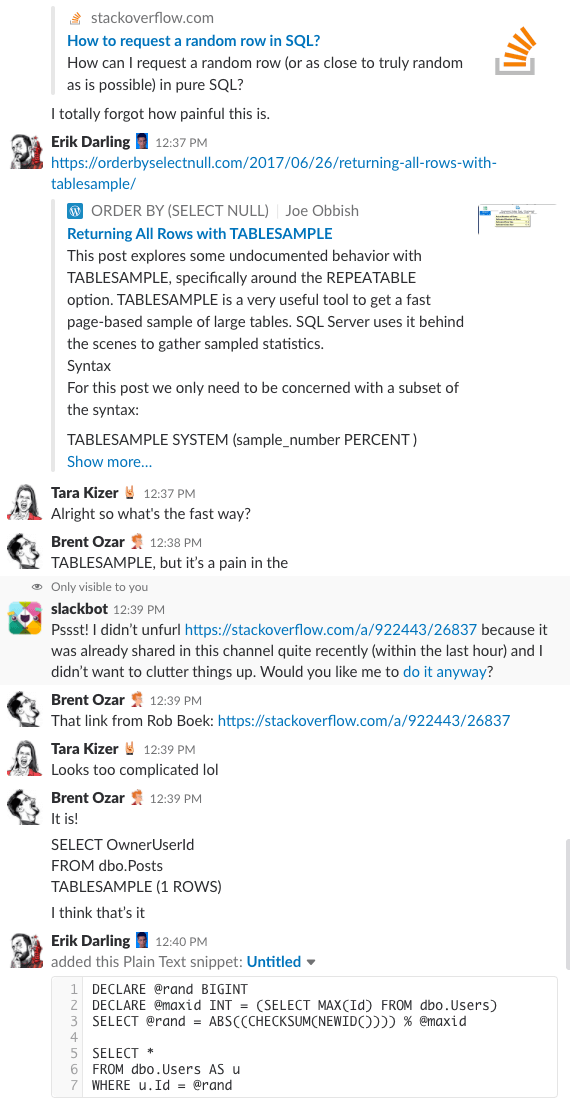
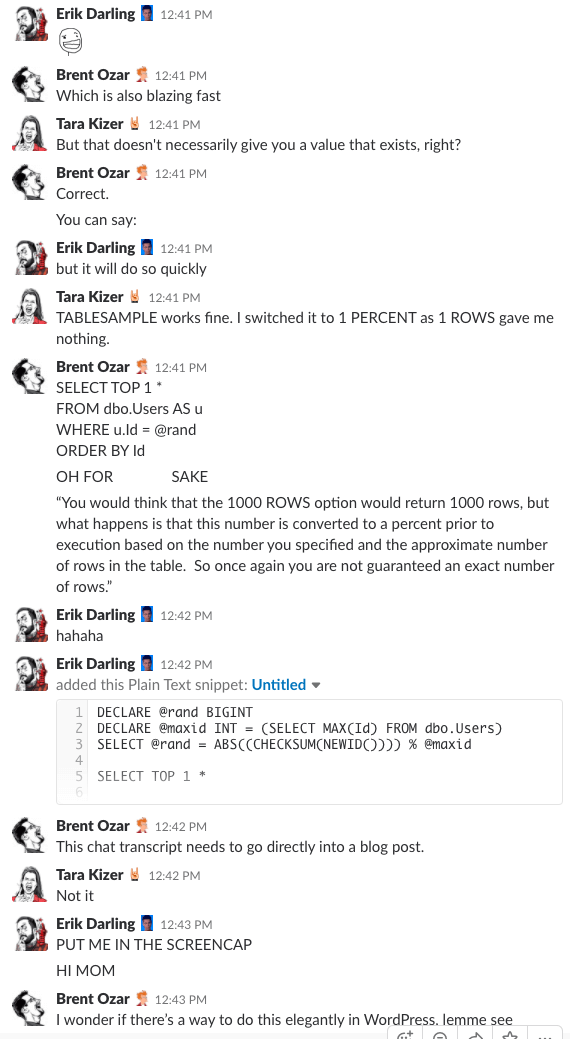
Alert spoilerowy: nie było. Po prostu zrobiłem zrzuty ekranu.
Bonus Track #2: Mitch Wheat Digs Deeper
Chcesz dogłębnej analizy losowości kilku różnych technik? Mitch Wheat nurkuje naprawdę głęboko, w komplecie z wykresami!
.