- Funkcja i jej pochodna są monotoniczne
- Wyjście jest zerowe „centryczne”
- Optymalizacja jest łatwiejsza
- Podzielna/pochodna funkcji Tanh (f'(x)) będzie leżeć między 0 a 1.
Konsekwencje:
- Podzielna funkcji Tanh cierpi „znikający gradient i eksplodujący gradient problem”.
- Powolna zbieżność-jak jego obliczeniowo ciężki.(Powód użycia wykładniczej funkcji matematycznej).
„Tanh jest preferowana w stosunku do funkcji sigmoidalnej, ponieważ jest wyśrodkowana względem zera i gradienty nie są ograniczone do poruszania się w określonym kierunku”
3. Funkcja aktywacji ReLu (ReLu – Rectified Linear Units):


ReLU jest nieliniową funkcją aktywacji, która zyskała popularność w AI. Funkcja ReLu jest również reprezentowana jako f(x) = max(0,x).
- Funkcja i jej pochodna zarówno są monotoniczne.
- Główna zaleta użycia funkcji ReLU- Nie aktywuje wszystkich neuronów w tym samym czasie.
- Komputerowo wydajne
- Podzielna / Pochodna funkcji Tanh (f'(x)) będzie 1 jeśli f(x) > 0 else 0.
- Konwertuj bardzo szybko
Konsekwencje:
- Funkcja ReLu w nie „zero-centric”.To sprawia, że aktualizacje gradientu idą zbyt daleko w różnych kierunkach. 0 < wyjście < 1, a to sprawia, że optymalizacja jest trudniejsza.
- Dead neuron is the biggest problem.This is due to Non-differentiable at zero.
„Problem umierającego neuronu/Dead neuron : As the ReLu derivative f'(x) is not 0 for the positive values of the neuron (f'(x)=1 for x ≥ 0), ReLu does not saturate (exploid) and no dead neurons (Vanishing neuron)are reported. Nasycenie i zanikający gradient występują tylko dla wartości ujemnych, które podane do ReLu zamieniają się w 0- To się nazywa problem umierającego neuronu.”
4. nieszczelna funkcja aktywacji ReLu:
Leaky ReLU function to nic innego jak ulepszona wersja funkcji ReLU z wprowadzeniem „stałego nachylenia”


- Leaky ReLU jest zdefiniowana w celu rozwiązania problemu umierającego neuronu/nieżywego neuronu.
- Problem umierającego neuronu jest rozwiązany przez wprowadzenie małego nachylenia, które umożliwia ujemnym wartościom skalowanym przez α „pozostanie przy życiu” odpowiadającym im neuronom.
- Funkcja i jej pochodna są monotoniczne
- Pozwala na ujemne wartości podczas wstecznej propagacji
- Jest wydajna i łatwa do obliczenia.
- Podzielnik Leaky’ego wynosi 1, gdy f(x) > 0 i mieści się w przedziale od 0 do 1, gdy f(x) < 0.
Konsekwencje:
- Leaky ReLU nie zapewnia spójnych przewidywań dla ujemnych wartości wejściowych.
5. Funkcja aktywacji ELU (Exponential Linear Units):

- ELU jest również proponowane do rozwiązania problemu umierającego neuronu.
- Brak problemów z umierającym ReLU
- Zero-centryczne
Konsekwencje:
- Komputerowo intensywne.
- Podobnie jak Leaky ReLU, chociaż teoretycznie lepszy niż ReLU, nie ma obecnie dobrych dowodów w praktyce, że ELU jest zawsze lepszy niż ReLU.
- f(x) jest monotoniczny tylko wtedy, gdy alfa jest większa lub równa 0.
- f'(x) pochodna ELU jest monotoniczna tylko wtedy, gdy alfa leży między 0 a 1.
- Powolna zbieżność ze względu na funkcję wykładniczą.
6. P ReLu (Parametric ReLU) Funkcja aktywacji:

- Pomysł nieszczelnego ReLU można rozszerzyć jeszcze bardziej.
- Zamiast mnożyć x ze stałym członem możemy mnożyć go z „hiperparametrem (a-trainable parameter)”, który wydaje się działać lepiej niż leaky ReLU. To rozszerzenie do leaky ReLU jest znane jako Parametric ReLU.
- Parametr α jest zazwyczaj liczbą pomiędzy 0 a 1, i jest zazwyczaj stosunkowo mały.
- Ma niewielką przewagę nad Leaky Relu z powodu trenowalnego parametru.
- Radzi sobie z problemem umierającego neuronu.
Konsekwencje:
- Tak samo jak Leaky Relu.
- f(x) jest monotoniczne gdy a> lub =0 i f'(x) jest monotoniczne gdy a =1
7. Swish (A Self-Gated) Activation Function:(Sigmoid Linear Unit)

- Google Brain Team zaproponował nową funkcję aktywacji, nazwaną Swish, która jest po prostu f(x) = x – sigmoid(x).
- Eksperymenty pokazują, że Swish ma tendencję do pracy lepiej niż ReLU na głębszych modelach w wielu trudnych zestawach danych.
- Krzywa funkcji Swish jest gładka i funkcja jest różniczkowalna we wszystkich punktach. Jest to pomocne podczas procesu optymalizacji modelu i jest uważane za jeden z powodów, dla których Swish przewyższa ReLU.
- Funkcja Swish jest „nie monotoniczna”. Oznacza to, że wartość funkcji może maleć nawet wtedy, gdy wartości wejściowe rosną.
- Funkcja jest niezwiązana powyżej i związana poniżej.
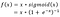
„Swish ma tendencję do ciągłego dopasowywania się lub prześcigania ReLu”
Zauważ, że wartość wyjściowa funkcji swish może spadać nawet wtedy, gdy wzrastają wartości wejściowe. Jest to interesująca i specyficzna dla Swish cecha.(Ze względu na niemonotoniczność)
f(x)=2x*sigmoid(beta*x)
Jeśli pomyślimy, że beta=0 jest prostą wersją Swish, która jest parametrem możliwym do nauczenia, wtedy część sigmoidalna jest zawsze 1/2 i f (x) jest liniowa. Z drugiej strony, jeśli beta jest bardzo dużą wartością, sigmoida staje się funkcją prawie dwucyfrową (0 dla x<0,1 dla x>0). Zatem f (x) jest zbieżna do funkcji ReLU. Dlatego jako standardową funkcję Swish wybieramy beta = 1. W ten sposób zapewniona jest miękka interpolacja (kojarzenie zbiorów wartości zmiennych z funkcją w zadanym przedziale i pożądanej precyzji). Doskonale! Znaleziono rozwiązanie problemu vanish of the gradients.
8.Softplus
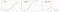
Funkcja softplus jest podobna do funkcji ReLU, ale jest stosunkowo gładsza.Funkcja Softplus lub SmoothRelu f(x) = ln(1+exp x).
Pochodna funkcji Softplus to f'(x) jest funkcją logistyczną (1/(1+exp x)).
Wartość funkcji zawiera się w przedziale (0, + inf).Zarówno f(x) jak i f'(x) są monotoniczne.
9.Softmax lub znormalizowana funkcja wykładnicza:

Funkcja „softmax” jest również rodzajem funkcji sigmoidalnej, ale jest bardzo przydatna do obsługi problemów klasyfikacji wieloklasowej.
„Softmax można opisać jako kombinację wielu funkcji sigmoidalnych.”
„Funkcja Softmax zwraca prawdopodobieństwo dla punktu danych należących do każdej indywidualnej klasy.”
Budując sieć dla problemu wieloklasowego, warstwa wyjściowa miałaby tyle neuronów, ile wynosi liczba klas w celu.
Na przykład, jeśli masz trzy klasy, w warstwie wyjściowej byłyby trzy neurony. Załóżmy, że otrzymaliśmy dane wyjściowe z neuronów jako .Stosując funkcję softmax nad tymi wartościami, otrzymamy następujący wynik – . Reprezentują one prawdopodobieństwo przynależności punktu danych do każdej klasy. Z wyniku możemy wywnioskować, że dane wejściowe należą do klasy A.
„Zauważ, że suma wszystkich wartości wynosi 1.”
Którego z nich lepiej użyć? Jak wybrać właściwą?
Będąc szczerym, nie ma twardej i szybkiej reguły wyboru funkcji aktywacji.Nie możemy rozróżnić pomiędzy funkcjami aktywacji.Każda funkcja aktywacji ma swoje zalety i wady.Wszystkie dobre i złe zostaną ustalone na podstawie ścieżki.
Ale w oparciu o właściwości problemu możemy dokonać lepszego wyboru dla łatwej i szybszej konwergencji sieci.
- Funkcje sigmoidalne i ich kombinacje generalnie działają lepiej w przypadku problemów klasyfikacyjnych
- Funkcje sigmoidalne i tanh są czasami unikane ze względu na problem znikającego gradientu
- Funkcja aktywacji ReLU jest szeroko stosowana w erze współczesnej.
- W przypadku martwych neuronów w naszych sieciach z powodu ReLu wtedy nieszczelna funkcja ReLU jest najlepszym wyborem
- Funkcja ReLU powinna być używana tylko w warstwach ukrytych
„Jako zasada kciuka, można zacząć od używania funkcji ReLU, a następnie przejść do innych funkcji aktywacji w przypadku ReLU nie zapewnia optymalnych wyników”
.