Nasze wysiłki związane z łącznością koncentrują się na rozszerzaniu dostępu do Internetu i jego rozpowszechnianiu na całym świecie. Obejmuje to naszą pracę nad technologiami takimi jak Terragraph, współpracę z operatorami komórkowymi w zakresie rozszerzania dostępu na obszarach wiejskich, naszą pracę w ramach projektu Telecom Infra oraz programy takie jak Free Basics. Kontynuując prace nad Free Basics, słuchaliśmy opinii i zaleceń społeczeństwa obywatelskiego i innych interesariuszy. Opracowaliśmy program Discover specjalnie po to, aby uwzględnić i włączyć te zalecenia do nowego produktu, który wspiera łączność. Dziś Facebook Connectivity i nasi partnerzy Bitel, Claro, Entel i Movistar uruchamiają testową wersję Discover w Peru.
Dostarczenie tej usługi przy jednoczesnym zachowaniu bezpieczeństwa ludzi przed potencjalnymi zagrożeniami bezpieczeństwa było trudnym wyzwaniem technicznym. Chcieliśmy opracować model, który pozwoliłby nam na bezpieczną prezentację stron internetowych ze wszystkich dostępnych domen, łącznie z ich zasobami (skrypty, media, arkusze stylów, itp.). Poniżej przedstawiamy zbudowany przez nas model, unikalne wybory dotyczące architektury, jakich dokonaliśmy po drodze, oraz kroki, jakie podjęliśmy, aby ograniczyć ryzyko.
- Gdzie zaczynaliśmy
- Wczesna architektura
- Projekt domeny
- Ciasteczka
- Ulepszanie tego, co zbudowaliśmy
- Ulepszenia architektury w Discover
- Skrypty JavaScript i utrwalanie plików cookie
- Rozwiązanie dwubramkowe
- Wewnętrzna ramka
- Obrączka zewnętrzna
- Interakcja ze stroną
- Asynchroniczne poprawianie ciasteczek
- Clickjacking
- Phishing
- Ciasteczka po stronie klienta
- Protokół Bootstrap
- Z protokołem localStorage
- Bez protokołu localStorage
Gdzie zaczynaliśmy
Dla Free Basics, naszym wyzwaniem było znalezienie sposobu na zapewnienie bezkosztowej usługi dla ludzi, którzy korzystają z mobilnej sieci, nawet na telefonach bez obsługi aplikacji firm trzecich. Partnerzy operatorów komórkowych mogli świadczyć tę usługę, ale ograniczenia związane z siecią i wyposażeniem bramek oznaczały, że tylko ruch do określonych miejsc docelowych (zazwyczaj zakresy adresów IP lub lista nazw domen) mógł być udostępniany bezpłatnie. Z ponad 100 partnerów na całym świecie i czas i trudności związane ze zmianą konfiguracji sprzętu sieci przewoźników, zdaliśmy sobie sprawę, że musimy wymyślić nowe podejście.
To nowe podejście wymagało od nas, aby najpierw zbudować internetową usługę proxy, gdzie operator może udostępnić usługę za darmo do jednej domeny: freebasics.com. Stamtąd pobieralibyśmy strony internetowe w imieniu użytkownika i dostarczali je na jego urządzenie. Nawet na nowoczesnych przeglądarkach istnieją pewne obawy związane z architekturą proxy opartą na sieci. W sieci, klienci są w stanie ocenić nagłówki HTTP bezpieczeństwa, takie jak cross-origin resource sharing (CORS) i Content Security Policy (CSP) i korzystać z plików cookie bezpośrednio z witryny. Ale w konfiguracji serwera proxy, klient wchodzi w interakcję z proxy, a proxy działa jako klient do witryny. Prokserowanie witryn innych firm przez pojedynczą przestrzeń nazw narusza pewne założenia dotyczące tego, jak przechowywane są pliki cookie, jak duży dostęp mają skrypty do odczytu lub edycji treści oraz jak oceniane są CORS i CSP.
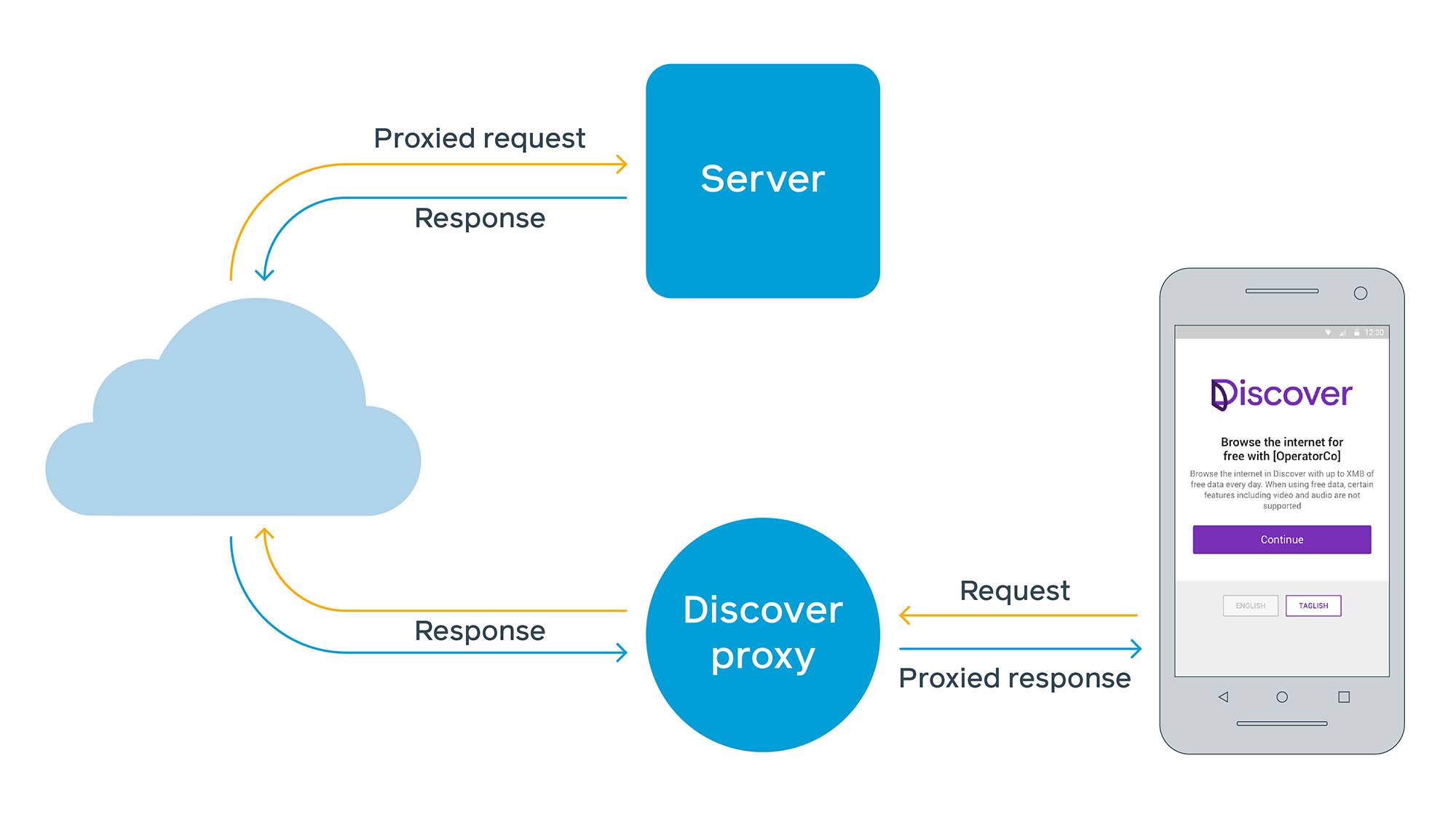
Aby rozwiać te obawy, początkowo narzuciliśmy pewne proste ograniczenia, włączając w to, które strony mogą być odwiedzane z Free Basics i niemożność uruchamiania skryptów. To ostatnie stało się z czasem większym problemem, ponieważ wiele stron internetowych, w tym mobilnych, zaczęło polegać na JavaScript dla krytycznych funkcji, w tym renderowania treści.
Wczesna architektura
Projekt domeny
Aby dostosować się do ograniczonej funkcjonalności wielu bramek operatorów komórkowych, rozważaliśmy alternatywne architektury, w tym:
- Rozwiązanie oparte na współpracy, w którym strony internetowe mogą przydzielić subdomenę (np,
free.example.com) i rozwiązywać ją w naszej przestrzeni IP, aby operatorzy mogli udostępnić ją bezpłatnie użytkownikowi.
To rozwiązanie miało zalety:
- Pozwalało na bezpośrednią komunikację end-to-end między klientem a serwerem.
- Wymagało minimalnej interwencji po stronie proxy.
Miał jednak również pewne wady:
- Strony musiały zdecydować się na ten schemat, co wiązało się z dodatkowymi kosztami inżynieryjnymi dla właścicieli witryn.
- Browserzy musieliby zażądać określonej domeny poprzez Server Name Indication (SNI), aby proxy wiedziało, gdzie się połączyć. Jednak wsparcie dla SNI nie jest powszechne, co sprawiło, że to rozwiązanie stało się mniej opłacalne.
- Jeśli abonenci przypadkowo przeglądali
example.combezpośrednio, zamiast do subdomenyfree.example.com, ponosili opłaty – i niekoniecznie byliby przekierowywani do subdomeny, chyba że operator zaimplementował jakąś dodatkową logikę.
- Enkapsulacja IPv4-in-IPv6, gdzie możemy enkapsulować całą przestrzeń IPv4 w ramach pojedynczej podsieci IPv6 z wolnymi danymi. Niestandardowy DNS resolver następnie rozwiązuje rekurencyjnie IPv4 i odpowiada z enkapsulowanymi odpowiedziami IPv6.
To rozwiązanie miało również plusy:
- Nie wymagało współpracy ze strony właściciela witryny.
- Nie było potrzeby stosowania SNI do rozwiązywania zdalnego IP.
I minusy:
- Browser widziałby domenę
www.example.com.freebasics.com, ale certyfikatwww.example.comskutkowałby błędem. - Tylko kilka bram przewoźników obsługiwało IPv6 w ten sposób.
- Jeszcze mniej urządzeń obsługiwało IPv6, zwłaszcza starsze wersje OS.
Żadne z tych rozwiązań nie było opłacalne. Ostatecznie zdecydowaliśmy, że najlepszą możliwą architekturą będzie origin collapsing, gdzie nasze proxy działa w pojedynczej przestrzeni nazw domeny origin-collapsed pod freebasics.com. Operatorzy mogą wtedy łatwiej dopuszczać ruch do tego miejsca docelowego i utrzymywać swoją konfigurację w prostocie. Każde pochodzenie strony trzeciej jest zakodowane w subdomenie, więc możemy zagwarantować, że rozwiązywanie nazw zawsze będzie kierować ruch do wolnego IP.
Na przykład:
https://example.com/path/?query=value#anchor
Przerabiamy na:
https://https-example-com.0.freebasics.com/path/?query=value#anchor
Istnieje obszerna logika po stronie serwera, aby upewnić się, że linki i href są poprawnie przekształcane. Ta sama logika pomaga zapewnić, że nawet strony HTTP-only są dostarczane bezpiecznie przez HTTPS na Free Basics między klientem a proxy. Ten schemat przepisywania adresów URL pozwala nam na użycie pojedynczej przestrzeni nazw i certyfikatu TLS, zamiast wymagać oddzielnego certyfikatu dla każdej subdomeny w Internecie.
Wszystkie poddomeny internetowe stają się rodzeństwem pod 0.freebasics.com, co podnosi pewne względy bezpieczeństwa. Nie byliśmy w stanie skorzystać z możliwości dodania domeny do Publicznej Listy Sufiksów, ponieważ musielibyśmy wystawić inny plik cookie dla każdego źródła, co ostatecznie przekroczyłoby limity plików cookie przeglądarki.
Ciasteczka
W przeciwieństwie do klientów internetowych, którzy mogą korzystać z plików cookie bezpośrednio z witryny, usługa proxy wymaga innej konfiguracji. Free Basics przechowuje ciasteczka użytkownika po stronie serwera z kilku powodów:
- Przeglądarki mobilne niższego poziomu często mają ograniczoną obsługę ciasteczek. Jeśli wystawimy nawet tylko jedno ciasteczko na stronę pod naszą domeną proxy, możemy być ograniczeni do ustawienia kilkudziesięciu ciasteczek. Jeśli Free Basics miałoby ustawić ciasteczka po stronie klienta dla każdej witryny w domenie
0.freebasics.com, starsze przeglądarki szybko uderzyłyby w limity przechowywania lokalnych ciasteczek – a nawet nowoczesne przeglądarki osiągnęłyby limit na domenę. - Ograniczenia przestrzeni nazw domen, które musieliśmy wdrożyć, również wykluczały użycie rodzeństwa i hierarchicznych ciasteczek. Na przykład, plik cookie ustawiony na dowolnej subdomenie w
.example.combyłby normalnie możliwy do odczytania w każdej innej subdomenie. Innymi słowy, jeślia.example.comustawi plik cookie na.example.com, tob.example.compowinien być w stanie go odczytać. W przypadku Free Basics,a-example-com.0.freebasics.comustawiłby ciasteczko naexample.com.0.freebasics.com, co nie jest dozwolone przez standard. Ponieważ to nie działa, inne źródła, takie jakb-example-com.0.freebasics.com, nie byłyby w stanie uzyskać dostępu do plików cookie ustawionych dla ich domeny nadrzędnej.
Aby umożliwić usłudze proxy dostęp do tego słoika z plikami cookie po stronie serwera, Free Basics wykorzystuje dwa pliki cookie po stronie klienta:
- Plik cookie
datr, identyfikator przeglądarki używany do celów integralności witryny. - Klucz
ick(klucz internetowego pliku cookie), który zawiera klucz kryptograficzny używany do szyfrowania pliku cookie po stronie serwera. Ponieważ ten klucz jest przechowywany tylko po stronie klienta, plik cookie po stronie serwera nie może zostać odszyfrowany przez Free Basics, gdy użytkownik nie korzysta z usługi.
Aby pomóc chronić prywatność i bezpieczeństwo użytkowników podczas przechowywania plików cookie po stronie serwera, upewniamy się, że:
- Pliki cookie po stronie serwera są szyfrowane za pomocą
ick, który jest przechowywany tylko na kliencie. - Kiedy klient dostarcza
ick, jest on zapominany przez serwer w każdym żądaniu, nie będąc nigdy rejestrowanym. - Oznaczamy oba pliki cookie po stronie klienta jako
SecureiHttpOnly. - Hashujemy indeks pliku cookie przy użyciu klucza po stronie klienta, aby nie można było prześledzić pliku cookie z powrotem do użytkownika, gdy klucz nie jest obecny.
Umożliwienie uruchamiania skryptów grozi utrwaleniem plików cookie po stronie serwera. Aby temu zapobiec, wykluczamy użycie JavaScript z Free Basics. Dodatkowo, mimo że każda strona może być częścią Free Basics, przeglądamy każdą stronę indywidualnie pod kątem potencjalnych wektorów nadużyć, niezależnie od zawartości.
Ulepszanie tego, co zbudowaliśmy
Aby wspierać model obsługujący każdą stronę internetową, z możliwością bezpieczniejszego uruchamiania skryptów, musieliśmy znacząco przemyśleć naszą architekturę, aby zapobiec zagrożeniom, takim jak skrypty zdolne do odczytu lub utrwalania ciasteczek użytkownika. JavaScript jest niezwykle trudny do przeanalizowania i uniemożliwienia wykonania niezamierzonego kodu.
Jako przykład, oto kilka sposobów, w jakie atakujący mógłby wstrzyknąć kod, który musielibyśmy umieć filtrować:
setTimeout();location = ' javascript:alert(1) <!--';location = 'javascript\n:alert(1) <!--';location = '\x01javascript:alert(1) <!--';var location = 'javascript:alert(1)';for(location in {'javascript:alert(1)':0}); = 'javascript:alert(1)';location.totally_not_assign=location.assign;location.totally_not_assign('javascript:alert(1)');location] = 'javascript:alert(1)';Reflect.set(location, 'href', 'javascript:alert(1)')new Proxy(location, {}).href = 'javascript:alert(1)'Object.assign(window, {location: 'javascript:alert(1)'});Object.assign(location, {href: 'javascript:alert(1)'});location.hash = '#%0a alert(1)';location.protocol = 'javascript:';Model, który wymyśliliśmy, rozszerzył projekt Free Basics, ale również chroni ciasteczko przechowujące klucz szyfrowania przed nadpisaniem przez skrypty. Używamy zewnętrznej ramki, której ufamy, aby poświadczyć, że wewnętrzna ramka, która prezentuje treści innych firm, nie jest naruszana. W dalszej części rozdziału pokazujemy szczegółowo, jak przeciwdziałamy utrwalaniu sesji i innym atakom, takim jak phishing i clickjacking. Przedstawiamy metodę bezpiecznego serwowania treści stron trzecich przy jednoczesnym umożliwieniu wykonywania JavaScript.
Ulepszenia architektury w Discover
Odniesienia do domeny w tym momencie zmienią się na naszą nową domenę, podobnie origin-collapsed discoverapp.com.
Zezwalając na JavaScript z witryn stron trzecich, musieliśmy przyznać, że umożliwia to pewne wektory, na które musieliśmy się przygotować, ponieważ skrypty mogą modyfikować i przepisywać łącza, uzyskiwać dostęp do dowolnej części DOM, a w najgorszym przypadku utrwalać pliki cookie po stronie klienta.
Rozwiązanie, które wymyśliliśmy, musiało zająć się utrwalaniem ciasteczek, więc zamiast próbować parsować i blokować pewne wywołania skryptów, zdecydowaliśmy się wykryć je w trakcie i uczynić bezużytecznymi. Osiągamy to w następujący sposób:
- Podczas rejestracji generujemy nowy, bezpieczny, losowy
ick. - Wysyłamy
ickdo przeglądarki jakoHttpOnlyplik cookie. - Następnie HMACujemy wartość o nazwie
icktze skrótu zarównoick, jak idatr(aby uniknąć utrwalenia dla obu) i przechowujemy kopięicktna kliencie, w lokalizacji wlocalStorage, do której potencjalny atakujący nie może pisać. Używana przez nas lokalizacja tohttps://www.0.discoverapp.com, która nigdy nie obsługuje treści stron trzecich. Ponieważ to źródło jest rodzeństwem wszystkich źródeł stron trzecich, obniżanie domeny lub jakikolwiek inny rodzaj modyfikacji domeny nie może wystąpić, a źródło jest uważane za zaufane. - Osadzamy
ickt, pochodzący z pliku cookieickwidocznego w żądaniu, wewnątrz HTML w każdej odpowiedzi proxy strony trzeciej. - Kiedy strona się ładuje, porównujemy osadzony
icktz zaufanymicktza pomocąwindow.postMessage()i unieważniamy sesję, jeśli występuje niezgodność, usuwając pliki cookiedatriick. - Zapobiegamy interakcji użytkownika ze stroną do czasu zakończenia tego procesu.
Jako dodatkowe zabezpieczenie ustawiamy nowy plik cookie datr, jeśli wykryjemy wiele plików cookie w tej samej lokalizacji, osadzając znacznik czasu, abyśmy zawsze mogli użyć najnowszego z nich.
Rozwiązanie dwubramkowe
Do sprawdzania poprawności potrzebujemy sposobu, aby strona innej firmy mogła odpytywać wartość ickt i sprawdzać jej poprawność. Robimy to poprzez osadzenie strony trzeciej w <iframe> na stronie w bezpiecznym miejscu pochodzenia i wstrzyknięcie fragmentu JavaScript do strony trzeciej. Budujemy bezpieczną zewnętrzną ramkę i wewnętrzną ramkę strony trzeciej.
Wewnętrzna ramka
Wewnątrz wewnętrznej ramki wstrzykujemy skrypt do każdej proxyowanej strony, którą obsługujemy. Wraz z nim wstrzykujemy również wartość ickt obliczoną na podstawie ick widzianego w żądaniu. Zachowanie wewnętrznej ramki jest następujące:
- Sprawdź z zewnętrzną ramką:
-
postMessagedo góry zicktosadzonym na stronie. - Czekaj.
- Jeśli skrypt otrzyma potwierdzenie z bezpiecznego źródła, pozwalamy użytkownikowi na interakcję ze stroną.
- Jeśli skrypt czeka zbyt długo lub otrzyma odpowiedź z nieoczekiwanego źródła, będziemy nawigować ramkę do ekranu błędu bez zawartości stron trzecich (nasza strona „Oops”), ponieważ możliwe jest, że zewnętrzna ramka albo nie istnieje, albo jest inna niż wewnętrzna ramka oczekuje.
-
- Sprawdź z
parent:-
postMessagedoparent. - Czekaj.
- Jeśli skrypt otrzyma odpowiedź z
source===parenti pochodzeniem pod.0.discoverapp.com, będzie kontynuował. - Jeśli skrypt będzie czekał zbyt długo lub otrzyma odpowiedź z nieoczekiwanego pochodzenia, przejdziemy do strony „Oops”.
-
Kilka uwag na temat wewnętrznej ramki:
- Nawet jeśli uda się ją obejść, potencjalni atakujący będą w stanie zafiksować się tylko na pochodzeniu, na którym mogą wykonać kod, co sprawi, że wektory zafiksowania ciasteczek będą zbędne.
- Zakładamy, że łagodne pochodzenie nie będzie celowo obchodzić protokołu przesyłania wiadomości inside-outer.
Obrączka zewnętrzna
Obrączka zewnętrzna jest tam po to, aby poświadczyć, że ramka wewnętrzna jest spójna:
- Upewniamy się, że ramka zewnętrzna jest zawsze górną ramką z JavaScript i
X-Frame-Options: DENY. - Czekamy na
postMessage. - Jeśli ramka zewnętrzna otrzyma wiadomość:
- Czy pochodzi ona z pochodzenia ramki wewnętrznej?
- Jeśli tak, czy zgłasza poprawną wartość
ickt?- Jeśli tak, wyślij wiadomość z potwierdzeniem.
- Jeśli nie, usuń sesję, usuń wszystkie pliki cookie i przejdź do bezpiecznego pochodzenia.
- Jeśli zewnętrzna ramka nie otrzyma wiadomości przez kilka sekund lub ramka podrzędna nie jest najwyżej położoną ramką wewnętrzną, usuwamy lokalizację z paska adresu bezpiecznej ramki.
Interakcja ze stroną
Aby uniknąć warunków wyścigu, w których osoba mogłaby wprowadzić hasło pod zafiksowanym ciasteczkiem, zanim ramka wewnętrzna zakończy weryfikację, ważne jest, aby uniemożliwić ludziom interakcję ze stroną przed zakończeniem sekwencji weryfikacji ramki wewnętrznej.
Aby temu zapobiec, serwer dodaje style="display:none" do elementu <html> każdej strony. Wewnętrzna ramka usunie go, gdy otrzyma potwierdzenie zewnętrznej ramki.
Kod JavaScript jest nadal dozwolony do uruchomienia, a zasoby są nadal pobierane. Ale tak długo, jak dana osoba nie wprowadziła żadnych danych wejściowych na stronę, przeglądarka nie robi nic, czego potencjalny atakujący nie mógłby zrobić po prostu odwiedzając witrynę – chyba że witryna jest już podatna na cross-site request forgery (CSRF).
Wybierając to rozwiązanie, musieliśmy rozwiązać inne możliwe wyniki, w szczególności:
- Asynchroniczne utrwalanie plików cookie.
- Clickjacking z powodu framingu.
- Phishing podszywający się pod domenę Discover.
Asynchroniczne poprawianie ciasteczek
Do tej pory zaimplementowane przez nas zabezpieczenia uwzględniały poprawki synchroniczne, ale mogą one również wystąpić asynchronicznie. Aby temu zapobiec, używamy klasycznej metody zapobiegania CSRF. Wymagamy, aby POSTy zawierały parametr zapytania o wartości datr widzianej podczas ładowania strony. Następnie porównujemy parametr zapytania z datr cookie widzianym w żądaniu. Jeśli się nie zgadzają, nie spełniamy żądania.
Aby uniknąć wycieku datr, osadzamy zaszyfrowaną wersję datr wewnątrz wewnętrznej ramki i zapewniamy, że ten parametr zapytania jest dodawany do każdego obiektu <form> i XHR. Ponieważ strona nie może samodzielnie uzyskać tokena datr, dodany datr jest tym, który jest widoczny w tym czasie.
Dla anonimowych żądań, wymagamy, aby miały one również parametr zapytania datr. Anonimowość jest zachowana, ponieważ nie wyciekamy jej do strony trzeciej – brakuje pliku cookie ick, więc nie możemy użyć słoika z ciasteczkami. Jednakże, w tym przypadku, nie jesteśmy w stanie walidować względem ciasteczka datr, więc anonimowe POSTy mogą być wykonywane w ramach sesji utrwalonych. Ale ponieważ są one anonimowe i brakuje im ick, żadne wrażliwe informacje nie mogą wyciec.
Clickjacking
Gdy witryna wysyła X-Frame-Options: DENY, nie załaduje się ona w wewnętrznej ramce. Ten nagłówek jest używany przez strony internetowe, aby zapobiec narażeniu się na pewne rodzaje ataków, takie jak clickjacking. Usuwamy ten nagłówek z odpowiedzi HTTP, ale prosimy wewnętrzną ramkę o sprawdzenie, czy parent jest ramką okna top za pomocą postMessage. Jeśli walidacja nie powiedzie się, kierujemy użytkownika na stronę „Oops”.
Phishing
Pasek adresu”, który umieszczamy w bezpiecznej ramce, jest używany do ujawnienia użytkownikowi najwyższego pochodzenia ramki wewnętrznej. Może on jednak zostać skopiowany przez strony phishingowe, które podszywają się pod Discover. Zapobiegamy odchodzeniu złośliwych linków od strony Discover, uniemożliwiając górną nawigację za pomocą <iframe sandbox>. Zewnętrzną ramkę można opuścić tylko poprzez bezpośrednie przejście na inną stronę.
Ciasteczka po stronie klienta
Kod document.cookie pozwala JavaScriptowi odczytywać i modyfikować ciasteczka, które nie są oznaczone HttpOnly. Obsługa tego w bezpieczny sposób stanowi wyzwanie w systemie, który utrzymuje pliki cookie na serwerze.
Dostarczanie plików cookie: Gdy żądanie zostanie odebrane, proxy wyliczy wszystkie pliki cookie, które są widoczne dla tego pochodzenia. Następnie załączy plik JSON do strony odpowiedzi. Kod po stronie klienta jest wstrzykiwany w celu shim document.cookie i uczynienia tych plików cookie widocznymi dla innych skryptów, tak jakby były to prawdziwe pliki cookie po stronie klienta.
Modyfikowanie plików cookie: Jeśli skryptom wolno arbitralnie ustawiać pliki cookie, które serwer następnie akceptuje, może to prowadzić do utrwalenia, w którym pochodzenie evil.com mogłoby ustawić wrażliwy plik cookie na example.com.
Zaufanie możliwościom CORS przeglądarki nie wystarczyłoby w tym przypadku – pochodzenie a.example.com próbujące ustawić plik cookie na example.com zostanie zablokowane przez przeglądarkę, ponieważ te pochodzenia są rodzeństwem, a nie hierarchią.
Mimo to, gdy serwer otrzymuje nowy plik cookie ustawiony przez klienta, nie może bezpiecznie wyegzekwować, czy domena docelowa jest dozwolona; pochodzenie autora jest znane tylko na kliencie i nie zawsze jest wysyłane do serwera w sposób, któremu możemy zaufać.
Aby zmusić klienta do udowodnienia, że jest uprawniony do ustawiania plików cookie w określonej domenie, serwer wyśle, oprócz ładunku JSON, listę tokenów kryptograficznych dla każdego z pochodzeń, w których żądające pochodzenie jest uprawnione do ustawiania plików cookie. Te tokeny są solone z wartością ick, więc nie mogą być przekazywane między użytkownikami.
The client-side shim for document.cookie zajmuje się rozwiązywaniem i osadzaniem tokena w rzeczywistym tekście pliku cookie, który jest wysyłany do proxy. Proxy może następnie zweryfikować, czy piszący origin rzeczywiście posiadał token do zapisu do domeny docelowej cookie i przechowuje go w słoiku cookie po stronie serwera, wysyłając go ponownie do klienta przy następnym żądaniu strony.
Protokół Bootstrap
Model zawiera trzy typy origin: portal origin (Discover portal, itp.), secure origin (outer frame) i rewrite origin (inner frame). Każdy z nich ma inne potrzeby:
- Portal origin wymaga
datr. - Secure origin wymaga
ickt. - Rewrite origin wymaga
datriick.
Z protokołem localStorage
Oto reprezentacja procesu bootstrap dla większości nowoczesnych przeglądarek mobilnych:
Należy zauważyć, że aby uniknąć refleksji, punkt końcowy bootstrap w bezpiecznym źródle zawsze wydaje nowe ick i ickt; ick nigdy nie zależy od danych wejściowych użytkownika. Zauważ, że ponieważ ustawiliśmy domain=.discoverapp.com zarówno na ick, jak i datr, są one dostępne we wszystkich typach pochodzenia, a ickt jest dostępne tylko w bezpiecznym pochodzeniu.
Bez protokołu localStorage
Ponieważ niektóre przeglądarki, takie jak Opera Mini (popularna w wielu krajach, w których działa Discover), nie obsługują localStorage, nie jesteśmy w stanie przechowywać wartości ick i ickt. Oznacza to, że musimy używać innego protokołu:
Zdecydowaliśmy się oddzielić rewrite origin od secure origin, aby nie miały one tego samego sufiksu hosta, zgodnie z Public Suffix List. Używamy www.0.discoverapp.com do przechowywania bezpiecznej kopii ickt (jako pliku cookie), a wszystkie źródła stron trzecich przenosimy pod 0.i.org. W dobrze zachowującej się przeglądarce, ustawienie ciasteczka na bezpiecznym źródle sprawi, że będzie ono niedostępne dla wszystkich źródeł przepisywania.
Ponieważ źródła są teraz oddzielne, nasz proces bootstrap staje się dwuetapowy. Wcześniej mogliśmy ustawić ick w tym samym żądaniu, w którym zapewniamy localStorage z ickt. Teraz musimy uruchomić dwa źródła, w oddzielnych żądaniach, bez otwierania wektorów utrwalania ick.
Rozwiązujemy to przez uruchomienie bezpiecznego pochodzenia z ickt cookie najpierw i dając użytkownikowi zaszyfrowaną wersję ick, z kluczem znanym tylko proxy. Tekstowi szyfrującemu ick towarzyszy nonce, który może być użyty do odszyfrowania tego konkretnego ick w źródle przepisywania i ustawienia pliku cookie, ale tylko raz.
Atakujący mógłby wybrać:
- Użyj nonce, aby ujawnić plik cookie
ick. - Przekazać go użytkownikowi, aby utrwalić jego wartość.
W obu przypadkach atakujący nie może jednocześnie znać i wymusić na użytkowniku określonej wartości ick. Proces ten również synchronizuje datr pomiędzy źródłami.
Ta architektura przeszła przez znaczące wewnętrzne i zewnętrzne testy bezpieczeństwa. Wierzymy, że opracowaliśmy projekt, który jest wystarczająco solidny, aby oprzeć się typom ataków aplikacji internetowych, które widzimy w środowisku naturalnym i bezpiecznie dostarczyć łączność, która jest zrównoważona dla operatorów komórkowych. Po uruchomieniu Discover w Peru, planujemy przeprowadzenie dodatkowych testów Discover z operatorami partnerskimi w kilku innych krajach, w których testowaliśmy funkcje produktu w wersji beta, w tym w Tajlandii, na Filipinach i w Iraku. Przewidujemy, że Discover będzie na żywo w tych dodatkowych krajach w ciągu najbliższych tygodni, a my zbadamy dodatkowe próby, gdzie operatorzy partnerscy chcą uczestniczyć.
Chcielibyśmy podziękować Berk Demir za pomoc w tej pracy.
W staraniach, aby być bardziej integracyjne w naszym języku, mamy edytowane ten post, aby zastąpić „whitelist” z „allowlist.”
.