Powyższy obrazek mógł dać ci wystarczające pojęcie o czym jest ten post.
Ten post obejmuje niektóre z ważnych rozmytych (nie dokładnie równe, ale lumpsum te same ciągi, powiedzmy RajKumar & Raj Kumar) algorytmy dopasowania ciągów, które obejmuje:
Hamming Distance
Levenstein Distance
Damerau Levenstein Distance
N-Gram based string matching
BK Tree
Bitap algorithm
Ale powinniśmy najpierw wiedzieć, dlaczego dopasowanie rozmyte jest ważne biorąc pod uwagę scenariusz świata rzeczywistego. Ilekroć użytkownik ma prawo wprowadzić jakiekolwiek dane, sprawy mogą potoczyć się naprawdę niechlujnie, jak w poniższym przypadku!!!
Pozwól,
- Nazywasz się 'Saurav Kumar Agarwal’.
- Dostałeś kartę biblioteczną (oczywiście z unikalnym identyfikatorem), która jest ważna dla każdego członka Twojej rodziny.
- Co tydzień idziesz do biblioteki, aby wydać kilka książek. Ale w tym celu musisz najpierw dokonać wpisu do rejestru przy wejściu do biblioteki, gdzie wpisujesz swoje ID & imię.
Teraz władze biblioteki decydują się analizować dane w tym rejestrze bibliotecznym, aby mieć pojęcie o unikalnych czytelnikach odwiedzających każdy miesiąc. Teraz można to zrobić z wielu powodów (np. czy rozbudować bibliotekę, czy nie, czy należy zwiększyć liczbę książek, itp). Więc jeśli mamy
123 Mehul
123 Rajesh
123 Mehul
133 Rajesh
133 Sandesh
To powinno dać nam 4 unikalnych czytelników.
So far so good
Oszacowali tę liczbę na około 10k-10.5k, ale liczby wzrosły do ~50k po analizie dokładnego dopasowania ciągów nazwisk.
wooohhh!!
Bardzo złe oszacowanie muszę powiedzieć !!!
Albo przegapili jakąś sztuczkę tutaj?
Po głębszej analizie, pojawił się poważny problem. Zapamiętaj swoje nazwisko, „Saurav Agarwal”. Znaleźli kilka wpisów prowadzących do 5 różnych użytkowników w całej twojej rodzinie ID biblioteki:
- Saurav K Aggrawal (zauważ podwójne 'g’, 'ra-ar’, Kumar staje się K)
- Saurav Kumar Agarwal
- Sourav Aggarwal
- SK Agarwal
- Agarwal
Istnieją pewne niejasności, ponieważ władze biblioteki nie wiedzą
- Ile osób z Twojej rodziny odwiedza bibliotekę? czy te 5 nazwisk reprezentuje jednego czytelnika, 2 lub 3 różnych czytelników. Nazwij to nienadzorowanym problemem, w którym mamy ciąg reprezentujący niestandaryzowane nazwy, ale ich standardowe nazwy nie są znane (np. Saurav Agarwal: Saurav Kumar Agarwal nie jest znany)
- Czy wszystkie z nich powinny połączyć się z 'Saurav Kumar Agarwal’? nie może powiedzieć jako SK Agarwal może być Shivam Kumar Agarwal (powiedzmy, że imię twojego ojca). Również jedynym Agarwal może być każdy z rodziny.
Ostatnie 2 przypadki (SK Agarwal & Agarwal) wymagałyby pewnych dodatkowych informacji (jak płeć, Data urodzenia, Książki wydane), które będą podawane do jakiegoś algorytmu ML w celu określenia rzeczywistej nazwy czytelnika & należy pozostawić na razie. Ale jedną rzeczą, której jestem całkiem pewien jest to, że pierwsze 3 nazwiska reprezentują tę samą osobę & Nie powinienem potrzebować dodatkowych informacji aby połączyć je w jednego czytelnika tj. 'Saurav Kumar Agarwal’.
Jak można to zrobić?
W tym miejscu pojawia się dopasowanie rozmycia ciągu znaków, które oznacza prawie dokładne dopasowanie ciągów znaków, które są nieco różne od siebie (głównie z powodu błędnej pisowni) jak 'Agarwal’ & 'Aggarwal’ & 'Aggrawal’. Jeśli otrzymamy ciąg z akceptowalnym poziomem błędu (powiedzmy jedną błędną literę), będziemy uważać go za dopasowanie. Zbadajmy więc →
Odległość Hamminga jest najbardziej oczywistą odległością obliczaną między dwoma ciągami o równej długości, która daje liczbę znaków, które nie pasują do danego indeksu. Na przykład: 'Bat’ & 'Bet’ ma odległość hamminga 1 przy indeksie 1, 'a’ nie jest równe 'e’
Levenstein Distance/ Edit Distance
Zakładam, że czujesz się komfortowo z odległością Levensteina & Rekursja. Jeśli nie, przeczytaj to. Poniższe wyjaśnienie jest bardziej streszczoną wersją odległości Levensteina.
Let 'x’= length(Str1) & 'y’=length(Str2) for this entire post.
Levenstein Distance oblicza minimalną liczbę edycji wymaganych do konwersji 'Str1′ do 'Str2′ poprzez wykonanie albo Dodawania, Usuwania, lub Zastępowania znaków. Stąd 'Cat’ & 'Bat’ ma odległość edycyjną '1′ (Zamień 'C’ na 'B’), podczas gdy dla 'Ceat’ & 'Bat’, będzie to 2 (Zamień 'C’ na 'B’; Usuń 'e’).
Mówiąc o algorytmie, ma on głównie 5 kroków
int LevensteinDistance(string str1, string str2, int x, int y){if (x == len(str1)+1) return len(str2)-y+1;if (y == len(str2)+1) return len(str1)-x+1;if (str1 == str2)
return LevensteinDistance(str1, str2, x+ 1, y+ 1);return 1 + min(LevensteinDistance(str1, str2, x, y+ 1), #insert LevensteinDistance(str1, str2, x+ 1, y), #remove LevensteinDistance(str1, str2, x+ 1, y+ 1) #replace
}
LevenesteinDistance('abcd','abbd',1,1)
To co robimy, to zaczynamy czytać ciągi znaków od pierwszego znaku
- Jeśli znak na indeksie 'x’ w str1 pasuje do znaku na indeksie 'y’ w str2, nie jest wymagana edycja &oblicz odległość edycji przez wywołanie
LevensteinDistance(str1,str2)
- Jeśli nie pasują do siebie, wiemy, że wymagana jest edycja. Więc dodajemy +1 do aktualnego edit_distance & rekurencyjnie oblicza edit_distance dla 3 warunków & bierze minimum z trzech:
Levenstein(str1,str2) →insertion w str2.
Levenstein(str1,str2) →delecja w str2
Levenstein(str1,str2)→wstawienie w str2
- Jeśli w którymś z ciągów zabraknie znaków podczas rekurencji, długość pozostałych znaków w drugim łańcuchu jest dodawana do odległości edycji (pierwsze dwie instrukcje if)
Demerau-Levenstein Distance
Rozważ 'abcd’ & 'acbd’. Jeśli pójdziemy za Levenstein Distance, to będzie (replace 'b’-’c’ & 'c’-’b’ at index positions 2 & 3 in str2) But if you look closely, both the characters got swapped as in str1 & if we introduce a new operation 'Swap’ alongside 'addition’, ’ deletion’ & 'replace’, this problem can be solved. To wprowadzenie może nam pomóc rozwiązać problemy takie jak 'Agarwal’ & 'Agrawal’.
Ta operacja jest dodawana przez poniższy pseudokod
1 +
(x - last_matching_index_y - 1 ) +
(y - last_matching_index_x - 1 ) +
LevinsteinDistance(str1, str2)
Uruchommy powyższą operację dla 'abcd’ & 'acbd’ gdzie załóżmy
initial_x=1 & initial_y=1 (Rozpoczęcie indeksowania od 1 & nie od 0 dla obu ciągów).
current x=3 & y=3 stąd str1 & str2 odpowiednio na 'c’ (abcd) & 'b’ (acbd).
Górne granice uwzględnione w operacji krojenia, o której mowa poniżej. Stąd 'qwerty’ będzie oznaczać 'qwer’.
- last_matching_index_y będzie ostatnim_indeksem w str2, który pasuje do str1 i.e 2 jako 'c’ w 'acbd’ (indeks 2)pasuje do 'c’ w 'abcd’.
- last_matching_index_x będzie ostatnim_indeksem w str1, który pasuje do str2 i.e 2 jako 'b’ w 'abcd’ (indeks 2) pasowało do 'b’ w 'acbd’.
- Więc, zgodnie z powyższym pseudokodem, DemarauLevenstein(’abc’,’acb’)=
1+(4-3-1) + (4-3-1)+LevensteinDistance(’a’,’a’)=1+0+0+0=1. Byłoby to 2, gdybyśmy podążali za Levenstein Distance
N-Gram
N-gram jest w zasadzie niczym innym jak zbiorem wartości wygenerowanych z łańcucha poprzez sparowanie kolejno występujących 'n’ znaków/wyrazów. Na przykład: n-gram z n=2 dla 'abcd’ będzie 'ab’,’bc’,’cd’.
Teraz, te n-gramy mogą być generowane dla ciągów, których podobieństwo musi być mierzone &różne metryki mogą być użyte do pomiaru podobieństwa.
Let 'abcd’ & 'acbd’ be 2 strings to be matched.
n-grams with n=2 for
’abcd’=ab,bc,cd
’acbd’=ac,cb,bd
Component match (qgrams)
Count of n-grams matched exactly for the two strings. Tutaj będzie to 0
Podobieństwo cosinusowe
Obliczanie iloczynu punktowego po konwersji n-gramów wygenerowanych dla ciągów do wektorów
Dopasowanie składowych (bez uwzględniania kolejności)
Dopasowanie składowych n-gramów ignorując kolejność elementów w obrębie i.e. bc=cb.
Istnieje wiele innych takich metryk jak Jaccard distance, Tversky Index, etc, które nie zostały tutaj omówione.
Drzewo BK
Drzewo BK jest jednym z najszybszych algorytmów do znajdowania podobnych ciągów (z puli ciągów) dla danego ciągu. Drzewo BK używa
- Dystansu Levensteina
- Nierówności trójkątnej (zajmiemy się tym pod koniec tej sekcji)
do znalezienia podobnych ciągów (&nie tylko jednego najlepszego ciągu).
Drzewo BK jest tworzone przy użyciu puli słów z dostępnego słownika. Say we have a dictionary D={Book, Books, Cake, Boo, Boon, Cook, Cape, Cart}
A BK Tree is created by
- Select a root node (can be any word). Niech to będzie 'Books’
- Przejrzyj każde słowo W w słowniku D, oblicz jego odległość Levensteina z węzłem głównym i uczyń słowo W dzieckiem korzenia, jeśli dla rodzica nie istnieje dziecko o tej samej odległości Levensteina. Wstawiając Książki & Ciasto.
Levenstein(Książki,Książka)=1 & Levenstein(Książki,Ciasto)=4. Ponieważ nie znaleziono żadnego dziecka o tej samej odległości dla 'Book’, uczyń je nowymi dziećmi dla korzenia.
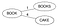
- Jeśli dziecko z taką samą odległością Levensteina istnieje dla rodzica P, teraz rozważ to dziecko jako rodzica P1 dla tego słowa W, oblicz Levenstein(rodzic, słowo) i jeśli żadne dziecko z tą samą odległością nie istnieje dla rodzica P1, uczyń słowo W nowym dzieckiem dla P1 lub kontynuuj schodzenie w dół drzewa.
Rozważ wstawienie Boo. Levenstein(Book, Boo)=1 ale istnieje już dziecko o tym samym tj. Books. Stąd, teraz oblicz Levenstein(Książki, Boo)=2. Ponieważ nie ma dziecka o tej samej odległości dla Książek, zrób Boo dzieckiem Książek.

Podobnie, wstawiamy wszystkie słowa ze słownika do drzewa BK

Gdy drzewo BK jest już przygotowane, do wyszukiwania podobnych słów dla danego słowa (Query word) musimy ustawić próg tolerancji 't’.
- Jest to maksymalny edit_distance, który weźmiemy pod uwagę dla podobieństwa pomiędzy dowolnym węzłem & query_word. Wszystko powyżej tej wartości jest odrzucane.
- Również, będziemy brać pod uwagę tylko te dzieci węzła nadrzędnego do porównania z Query, gdzie Levenstein(Child, Parent) jest w
dlaczego? omówimy to wkrótce
- Jeśli ten warunek jest prawdziwy dla dziecka, wtedy tylko będziemy obliczać Levenstein(Child, Query), który będzie uważany za podobny do zapytania, jeśli
Levenshtein(Child, Query)≤t.
- Więc, nie będziemy obliczać odległości Levensteina dla wszystkich węzłów/słów w słowniku ze słowem zapytania & stąd zaoszczędzimy dużo czasu, gdy pula słów jest ogromna
Więc, aby dziecko było podobne do zapytania if
- Levenstein(Parent, Query)-t ≤ Levenstein(Child,Parent) ≤ Levenstein(Parent,Query)+t
- Levenstein(Child,Query)≤t
Przejrzyjmy szybko przykład. Niech 't’=1
Niech słowo, dla którego musimy znaleźć podobne słowa to 'Care’ (Query word)
- Levenstein(Book,Care)=4. Ponieważ 4>1, 'Książka’ jest odrzucona. Teraz będziemy rozważać tylko te dzieci 'Księgi’, które mają LevisteinDistance(Dziecko,’Księga’) pomiędzy 3(4-1) & 5(4+1). Stąd odrzucilibyśmy 'Książki’ & wszystkie jej dzieci, ponieważ 1 nie leży w wyznaczonych granicach
- Jako Levenstein(Ciasto, Książka)=4, która leży pomiędzy 3 & 5, będziemy sprawdzać Levenstein(Ciasto, Opieka)=1, która jest ≤1 stąd podobne słowo.
- Readjusting the limits, for Cake’s children, become 0(1-1) & 2(1+1)
- As both Cape & Cart has Levenstein(Child, Parent)=1 & 2 respectively, both are eligible to get tested with 'Care’.
- As Levenstein(Cape,Care)=1 ≤1& Levenstein(Cart,Care)=2>1, only Cape is considered as similar word to 'Care’.
Hence, we found 2 words similar to 'Care’ that are: Cake & Cape
Ale na jakiej podstawie decydujemy o granicach
Levenstein(Parent,Query)-t, Levenstein(Parent,Query)+t.
dla dowolnego węzła-dziecka?
Wynika to z nierówności trójkąta, która stwierdza
Dystans (A,B) + Dystans(B,C)≥Dystans(A,C) gdzie A,B,C są bokami trójkąta.
Jak ta idea pomaga nam dojść do tych granic, zobaczmy:
Let Query,=Q Parent=P & Child=C tworzą trójkąt z odległością Levensteina jako długością krawędzi. Niech 't’ będzie progiem tolerancji. Then, By above inequality
Levenstein(P,C) + Levenstein(P,Q)≥Levenstein(C,Q)as Levenstein(C, Q) can't exceed 't'(threshold set earlier for C to be similar to Q), HenceLevenstein(P,C) + Levenstein(P,Q)≥ t
OrLevenstein(P,C)≥|Levenstein(P,Q)-t| i.e the lower limit is set
Again, by Triangle Inequality,
Levenstein(P,Q) + Levenstein(C,Q) ≥ Levenstein(P,C) or
Levenstein(P,Q) + t ≥ Levenstein(P,C) or the upper limit is set
Algorytm Bitap
Jest to również bardzo szybki algorytm, który może być używany do rozmytego dopasowywania ciągów całkiem wydajnie. Dzieje się tak, ponieważ używa operacji bitowych &, ponieważ są one dość szybkie, algorytm jest znany ze swojej szybkości. Nie marnując ani trochę, zacznijmy:
Let S0=’ababc’ is the pattern to be matched with string S1=’abdabababc’.
First of all,
- Figure out all unique characters in S1 & S0 that are a,b,c,d
- Form bit patterns for each character. How?

- Odwróć wzorzec S0 do przeszukiwania
- Dla wzorca bitowego dla znaku x, umieść 0 tam, gdzie występuje on we wzorcu w przeciwnym razie 1. W T, 'a’ występuje na 3 & 5 miejscu, umieściliśmy 0 na tych pozycjach & reszta 1.
Podobnie, utwórz wszystkie inne wzorce bitowe dla różnych znaków w słowniku.
S0=ababc S1=abdababc
- Przyjmij stan początkowy wzorca bitowego o długości(S0) ze wszystkimi 1. W naszym przypadku będzie to 11111 (stan S).
- Jak zaczniemy szukać w S1 i przejdziemy przez dowolny znak,
przesuń 0 na najniższy bit tj. 5 bit od prawej w S &
operacjaOR na S z T.
Więc, jak napotkamy 1. 'a’ w S1, będziemy
- Lewy Shift a 0 w S na najniższym bicie, aby utworzyć 11111 →11110
- 11010 | 11110=11110
Teraz, jak przejdziemy do 2. znaku 'b’
- Shift 0 do S i.e do postaci 11110 →11100
- S |T=11100 | 10101=11101
Jak napotkamy 'd’
- Przesuń 0 do S do postaci 11101 →11010
- S |T=11010 |11111=11111
Zauważ, że ponieważ 'd’ nie jest w S0, stan S zostaje zresetowany. Po przejściu przez całe S1, otrzymamy poniższe stany przy każdym znaku

Skąd mam wiedzieć, czy znalazłem jakieś rozmycie/pełne dopasowanie?
- Jeśli 0 osiągnie najwyższy bit we wzorcu bitowym stanu S (jak w ostatnim znaku 'c’), masz pełne dopasowanie
- Dla dopasowania rozmytego, obserwuj 0 na różnych pozycjach stanu S. Jeśli 0 jest na 4 miejscu, znaleźliśmy 4/5 znaków w tej samej sekwencji, jak w S0. Podobnie dla 0 w innych miejscach.
Jedna rzecz, którą mogłeś zauważyć, że wszystkie te algorytmy działają na podobieństwie ortograficznym ciągów. Czy mogą istnieć jakieś inne kryteria dopasowania rozmytego? Tak,
Fonetyka
Będziemy pokrywać fonetyki (oparte na dźwięku, jak Saurav & Sourav, powinien mieć dokładne dopasowanie w fonetyce) oparte algorytmy dopasowania rozmyte następny !!!
- Redukcja wymiaru (3 części)
- Algorytmy NLP(5 części)
- Podstawy Reinforcement Learning (5 części)
- Zaczynając od Time-Series (7 części)
- Wykrywanie obiektów przy użyciu YOLO (3 części)
- Tensorflow dla początkujących (koncepcje + przykłady) (4 części)
- Preprocessing Time Series (z kodami)
- Analityka danych dla początkujących
- Statystyka dla początkujących (4 części)
.