Update 29-mei-2018: Het doel van dit artikel is drieledig (1) Laten zien dat we altijd een datamodel nodig zullen hebben (hetzij gedaan door mensen of machines) (2) Laten zien dat fysiek modelleren niet hetzelfde is als logisch modelleren. In feite is het zeer verschillend en afhankelijk van de onderliggende technologie. We hebben echter beide nodig. Ik heb dit punt geïllustreerd aan de hand van Hadoop op de fysieke laag (3) De impact laten zien van het concept van onveranderlijkheid op datamodellering.
- Is dimensionale modellering dood?
- Waarom moeten we onze gegevens modelleren?
- Waarom hebben we dimensionale modellen nodig?
- Gegevensmodellering vs. dimensionele modellering
- Waarom beweren sommigen dan dat dimensionale modellering dood is?
- Het datawarehouse is dood Verwarring
- The Schema on Read Misunderstanding
- Denormalisatie opnieuw bekeken. De fysieke aspecten van het model.
- Taking de-normalization to its full conclusion
- Gegevensdistributie op een gedistribueerde relationele database (MPP)
- Data Distribution on Hadoop
- Dimensionale modellen op Hadoop
- Hadoop en langzaam veranderende dimensies
- Storage evolution on Hadoop
- Het verdict. Zijn dimensionale modellen en sterschema’s verouderd?
- Aanvullende lectuur over dimensionele modellering in het tijdperk van Big Data
Is dimensionale modellering dood?
Voordat ik een antwoord op deze vraag geef, nemen we een stap terug en kijken we eerst naar wat we bedoelen met dimensionale datamodellering.
Waarom moeten we onze gegevens modelleren?
In tegenstelling tot een veel voorkomend misverstand, is het niet het enige doel van datamodellen om te dienen als een ER-diagram voor het ontwerpen van een fysieke database. Gegevensmodellen geven de complexiteit van bedrijfsprocessen in een onderneming weer. Zij documenteren belangrijke bedrijfsregels en -concepten en helpen bij het standaardiseren van belangrijke bedrijfsterminologie. Ze verschaffen duidelijkheid en helpen om vaag denken en dubbelzinnigheden over bedrijfsprocessen bloot te leggen. Bovendien kunt u gegevensmodellen gebruiken om te communiceren met andere belanghebbenden. U zou geen huis of brug bouwen zonder een blauwdruk. Dus waarom zou je een data-applicatie zoals een data warehouse bouwen zonder een plan?
Waarom hebben we dimensionale modellen nodig?
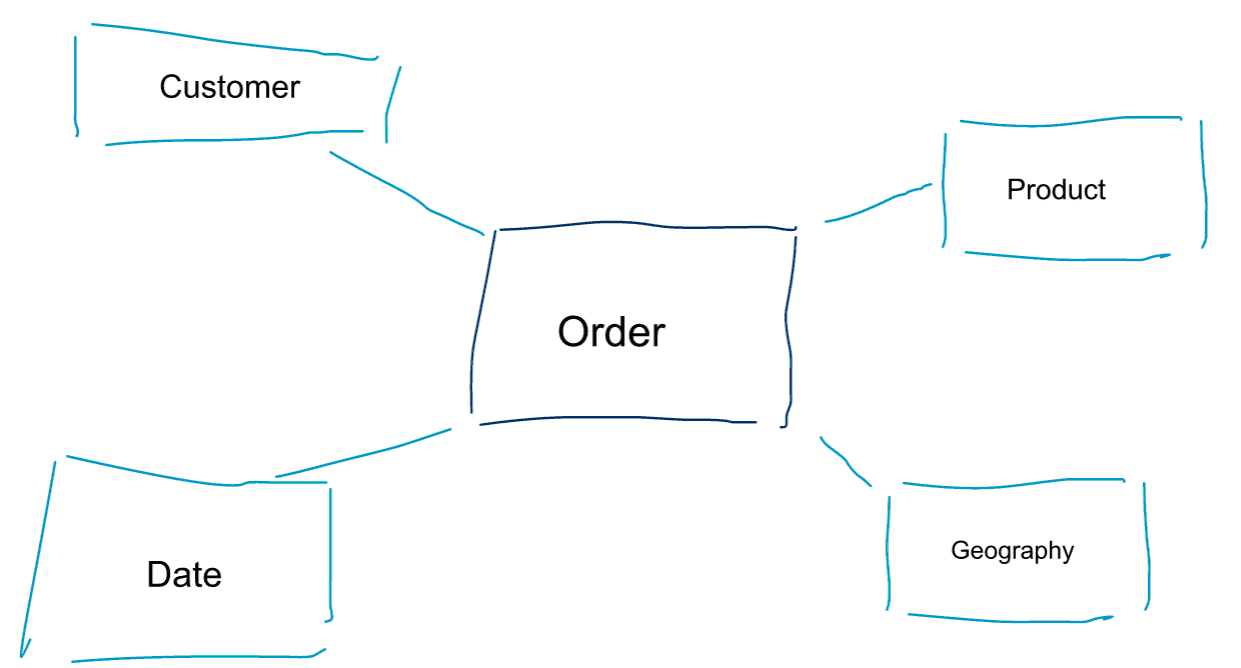
Dimensionale modellering is een speciale benadering van het modelleren van gegevens. We gebruiken ook wel de woorden data mart of ster schema als synoniemen voor een dimensioneel model. Sterrenschema’s zijn geoptimaliseerd voor data-analyse. Kijk eens naar het dimensionale model hieronder. Het is vrij intuïtief te begrijpen. We zien meteen hoe we onze ordergegevens kunnen indelen naar klant, product of datum en de prestaties van het bedrijfsproces Orders kunnen meten door metrieken te aggregeren en te vergelijken.
Eén van de kernideeën over dimensioneel modelleren is het definiëren van het laagste niveau van granulariteit in een transactioneel bedrijfsproces. Wanneer we in de gegevens gaan snijden en splitsen, is dit het bladniveau van waaruit we niet verder kunnen boren. Anders gezegd, het laagste granulariteitsniveau in een sterrenschema is een join van de feitentabel met alle dimensietabellen zonder aggregaties.
Gegevensmodellering vs. dimensionele modellering
In standaardgegevensmodellering streven we ernaar herhaling en redundantie van gegevens te elimineren. Als er een verandering in de gegevens optreedt, hoeven we die maar op één plaats aan te brengen. Dit komt ook de kwaliteit van de gegevens ten goede. Waarden lopen niet op meerdere plaatsen uit de pas. Kijk eens naar het model hieronder. Het bevat verschillende tabellen die geografische concepten vertegenwoordigen. In een genormaliseerd model hebben we een aparte tabel voor elke entiteit. In een dimensionaal model hebben we slechts één tabel: geografie. In deze tabel worden steden meerdere malen herhaald. Eenmaal voor elke stad. Als het land van naam verandert, moeten we het land op veel plaatsen bijwerken
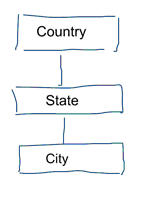
Note: standaardgegevensmodellering wordt ook 3NF-modellering genoemd.
De standaardbenadering van gegevensmodellering is niet geschikt voor Business Intelligence-workloads. Veel tabellen resulteren in veel joins. Joins vertragen de zaak. In data analytics vermijden we ze waar mogelijk. In dimensionale modellen de-normaliseren we meerdere gerelateerde tabellen tot één tabel, bijvoorbeeld de verschillende tabellen in ons vorige voorbeeld kunnen worden samengevoegd tot één tabel: geografie.
Waarom beweren sommigen dan dat dimensionale modellering dood is?
Ik denk dat je het met me eens bent dat datamodellering in het algemeen en dimensionale modellering in het bijzonder een heel nuttige oefening is. Dus waarom beweren sommige mensen dat dimensionale modellering niet nuttig is in het tijdperk van big data en Hadoop?
Zoals u zich kunt voorstellen, zijn hier verschillende redenen voor.
Het datawarehouse is dood Verwarring
Vooreerst verwarren sommige mensen dimensionale modellering met data warehousing. Zij beweren dat data warehousing dood is en dat bijgevolg dimensionele modellering ook naar de vuilnisbak van de geschiedenis kan worden verwezen. Dit is een logisch samenhangend argument. Het concept van het data warehouse is echter verre van achterhaald. We hebben altijd geïntegreerde en betrouwbare gegevens nodig voor het vullen van onze BI-dashboards. Als u hier meer over wilt weten raad ik u onze training Big Data voor Data Warehouse Professionals aan. In de cursus ga ik in op de details en leg ik uit hoe het data warehouse nog steeds relevant is. Ook laat ik zien hoe opkomende big data tools en technologieën nuttig zijn voor data warehousing.

The Schema on Read Misunderstanding
Het tweede argument dat ik vaak hoor, gaat als volgt. “We volgen een schema on read-aanpak en hoeven onze gegevens niet meer te modelleren”. Naar mijn mening is het concept van schema on read een van de grootste misverstanden in data analytics. Ik ben het ermee eens dat het nuttig is om je ruwe gegevens in eerste instantie op te slaan in een data dump die weinig schema bevat. Dit argument mag echter niet worden gebruikt als een excuus om je gegevens helemaal niet te modelleren. De schema on read aanpak is gewoon het schoppen van de kan en de verantwoordelijkheid naar downstream processen. Iemand moet nog steeds door de zure appel heen bijten bij het definiëren van de datatypes. Elk proces dat de schema-vrije gegevensdump benadert, moet zelf uitzoeken wat er aan de hand is. Dit soort werk kost handenvol geld, is volkomen overbodig, en kan gemakkelijk worden vermeden door het definiëren van gegevenstypen en een goed schema.
Denormalisatie opnieuw bekeken. De fysieke aspecten van het model.
Zijn er eigenlijk wel steekhoudende argumenten om dimensionale modellen verouderd te verklaren? Er zijn inderdaad een aantal betere argumenten dan de twee die ik hierboven heb opgesomd. Ze vereisen enig begrip van fysieke datamodellering en de manier waarop Hadoop werkt.
Eerder heb ik kort een van de redenen genoemd waarom we onze gegevens dimensioneel modelleren. Het heeft te maken met de manier waarop de gegevens fysiek worden opgeslagen in onze data store. In standaard datamodellering krijgt elke echte wereldentiteit zijn eigen tabel. Wij doen dit om redundantie van gegevens te vermijden en het risico te vermijden dat kwaliteitsproblemen in onze gegevens sluipen. Hoe meer tabellen we hebben, hoe meer joins we nodig hebben. Dat is het nadeel. Table joins zijn duur, vooral wanneer we een groot aantal records uit onze datasets samenvoegen. Wanneer we gegevens dimensioneel modelleren, consolideren we meerdere tabellen in één. We zeggen dat we de gegevens pre-joinen of de-normaliseren. We hebben nu minder tabellen, minder joins, en als gevolg daarvan een lagere latency en betere query performance.
Deel mee aan de discussie over dit bericht op LinkedIn
Taking de-normalization to its full conclusion
Waarom niet de-normalisatie tot zijn volledige conclusie nemen? Weg met alle joins en gewoon een enkele feitentabel? Dit zou inderdaad alle joins overbodig maken. Maar, zoals je je kunt voorstellen, heeft het enkele neveneffecten. Ten eerste is er meer opslagruimte nodig. We moeten nu een heleboel overbodige gegevens opslaan. Met de komst van kolom-opslagformaten voor data-analyse is dit tegenwoordig minder een probleem. Het grotere probleem van de-normalisatie is het feit dat telkens wanneer een waarde van een van de attributen verandert, we de waarde op meerdere plaatsen moeten bijwerken – mogelijk duizenden of miljoenen updates. Een manier om dit probleem te omzeilen is om onze modellen elke nacht volledig te herladen. Vaak zal dit veel sneller en gemakkelijker zijn dan een groot aantal updates toe te passen. Columnar databases volgen meestal de volgende aanpak. Ze slaan updates van gegevens eerst in het geheugen op en schrijven ze asynchroon naar schijf.
Gegevensdistributie op een gedistribueerde relationele database (MPP)
Bij het maken van dimensionale modellen op Hadoop, bijv. Hive, SparkSQL enz. moeten we een kernkenmerk van de technologie beter begrijpen dat het onderscheidt van een gedistribueerde relationele database (MPP) zoals Teradata enz. Bij het verdelen van gegevens over de nodes in een MPP hebben we controle over de plaatsing van records. Op basis van onze partitioneringsstrategie, bv. hash, lijst, bereik enz. kunnen wij de sleutels van individuele records co-loceren over tabbladen op hetzelfde knooppunt. Met data co-localiteit gegarandeerd, zijn onze joins supersnel omdat we geen data over het netwerk hoeven te sturen. Kijk eens naar het onderstaande voorbeeld. Records met dezelfde ORDER_ID uit de ORDER- en ORDER_ITEM-tabellen komen op dezelfde node terecht.
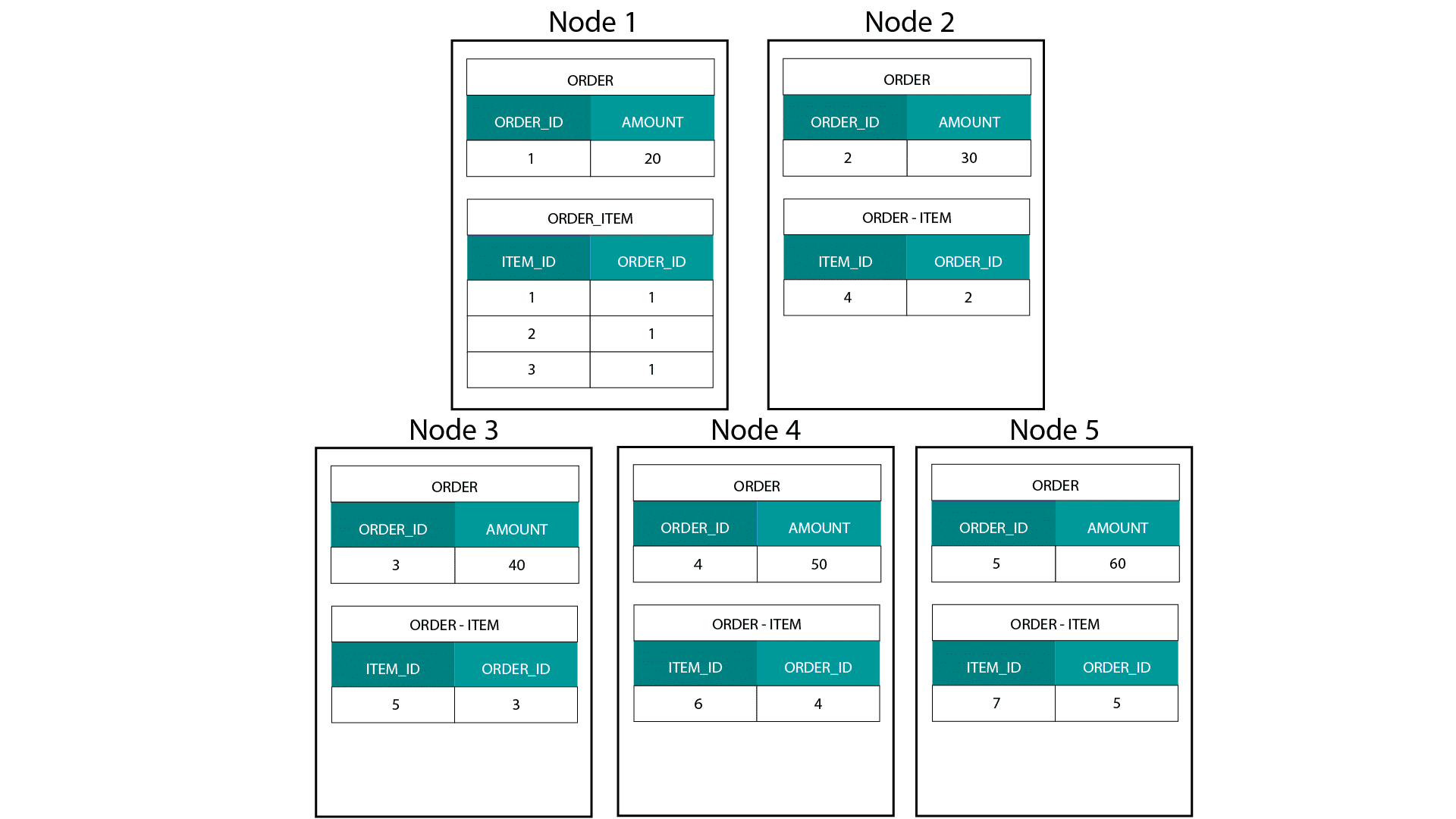
Keys voor order_id van de order- en order_item-tabel zijn co-located op dezelfde nodes.
Data Distribution on Hadoop
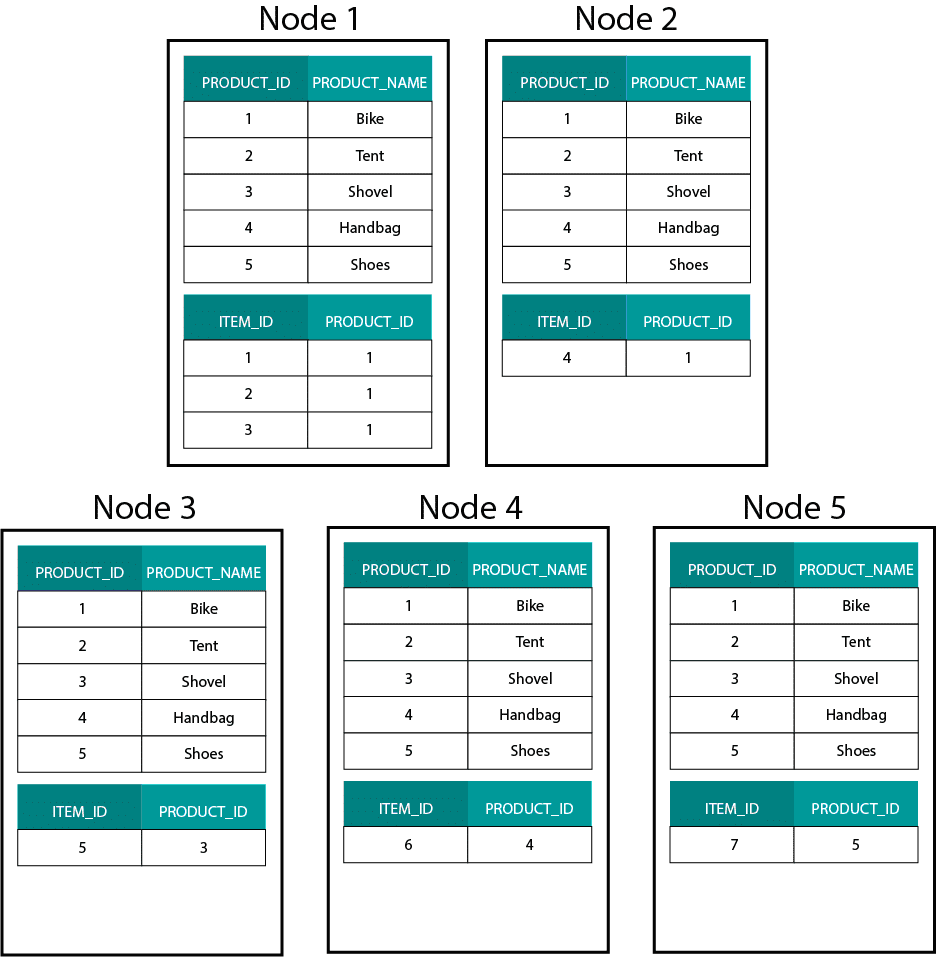
Dit is heel anders dan Hadoop-gebaseerde systemen. Daar splitsen we onze gegevens op in grote brokken en verdelen en repliceren we ze over onze nodes op het Hadoop Distributed File System (HDFS). Met deze datadistributiestrategie kunnen we de co-localiteit van de data niet garanderen. Kijk eens naar het onderstaande voorbeeld. De records voor de ORDER_ID-sleutel komen op verschillende nodes terecht.
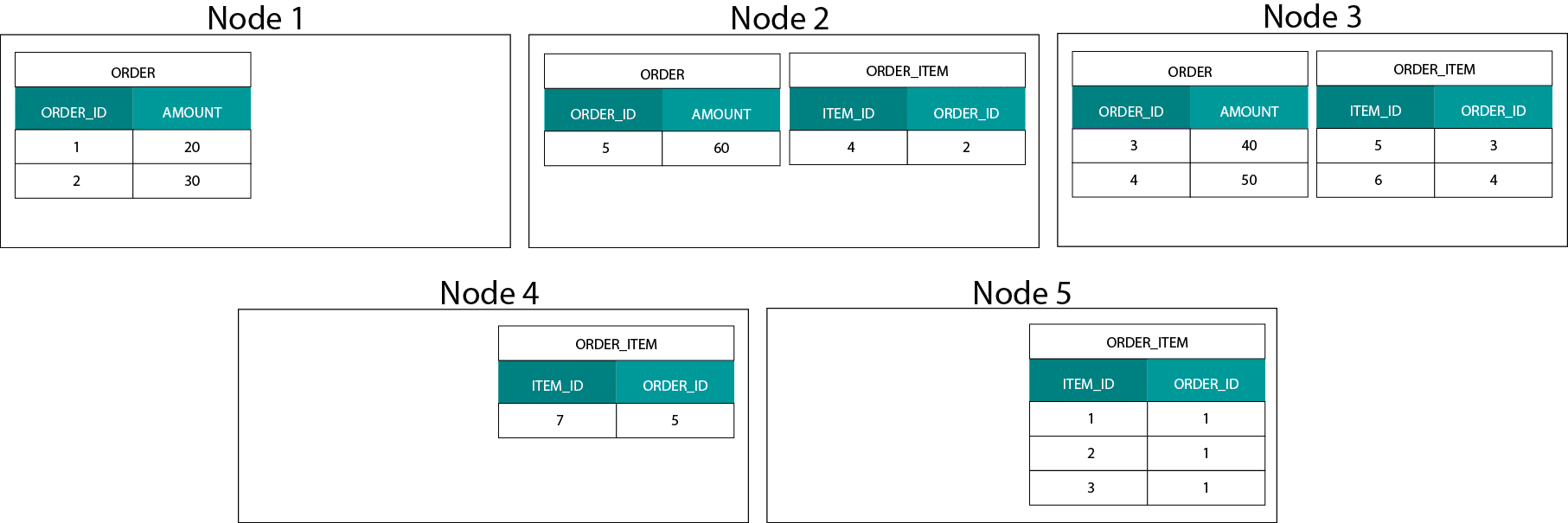
Om te joinen, moeten we gegevens over het netwerk verzenden, wat de prestaties beïnvloedt.
Eén strategie om met dit probleem om te gaan, is om een van de join-tabellen over alle nodes in het cluster te repliceren. Dit wordt een broadcast join genoemd en we gebruiken dezelfde strategie op een MPP. Zoals je je kunt voorstellen, werkt dit alleen voor kleine lookup- of dimensietabellen.
Wat doen we dan als we een grote feitentabel en een grote dimensietabel hebben, bijv. klant of product? Of zelfs wanneer we twee grote feitentabellen hebben.
Dimensionale modellen op Hadoop
Om dit prestatieprobleem te omzeilen, kunnen we grote dimensietabellen de-normaliseren in onze feitentabel om te garanderen dat gegevens op dezelfde locatie worden opgeslagen.
Om twee grote feitentabellen samen te voegen, kunnen we de tabel met de lagere granulariteit nestelen in de tabel met de hogere granulariteit, bijvoorbeeld een grote ORDER_ITEM tabel genest in de ORDER tabel. Moderne query-engines zoals Impala of Drill stellen ons in staat deze gegevens af te vlakken

Deze strategie van het nesten van gegevens is ook nuttig voor pijnlijke Kimball-concepten zoals bridgetabellen om M:N-relaties in een dimensioneel model weer te geven.
Hadoop en langzaam veranderende dimensies
Opslag op het Hadoop File System is onveranderlijk. Met andere woorden, je kunt alleen records invoegen en toevoegen. Je kunt gegevens niet wijzigen. Als je uit een relationele datawarehouse-achtergrond komt, kan dit in het begin een beetje vreemd lijken. Echter, onder de motorkap werken databases op een vergelijkbare manier. Ze slaan alle wijzigingen in gegevens op in een onveranderlijk logboek (in Oracle bekend als het redo logboek) voordat een proces asynchroon de gegevens in de gegevensbestanden bijwerkt.
Welke invloed heeft onveranderlijkheid op onze dimensionale modellen? U herinnert zich wellicht het concept van Slowly Changing Dimensions (SCD’s) uit uw cursus dimensionale modellering. SCD’s bewaren optioneel de historiek van wijzigingen aan attributen. Zij laten ons toe metrieken te rapporteren tegen de waarde van een attribuut op een bepaald tijdstip. Dit is echter niet het standaard gedrag. Standaard worden dimensie-tabellen bijgewerkt met de meest recente waarden. Dus wat zijn onze opties op Hadoop? Onthoud! We kunnen gegevens niet bijwerken. We kunnen gewoon SCD het standaardgedrag maken en alle wijzigingen controleren. Als we rapporten willen uitvoeren tegen de huidige waarden, kunnen we bovenop de SCD een View maken die alleen de laatste waarde ophaalt. Dit kan gemakkelijk worden gedaan met behulp van windowing-functies. Als alternatief kunnen we een zogenaamde compaction service draaien die fysiek een aparte versie van de dimension table maakt met alleen de laatste waarden.
Storage evolution on Hadoop
De beperkingen van Hadoop zijn niet onopgemerkt gebleven bij de verkopers van de Hadoop platforms. In Hive hebben we nu ACID-transacties en bij te werken tabellen. Gebaseerd op het aantal openstaande grote problemen en mijn eigen ervaring, lijkt deze functie echter nog niet klaar voor productie te zijn. Cloudera heeft voor een andere aanpak gekozen. Met Kudu hebben ze een nieuw updatable opslagformaat gemaakt dat niet op HDFS zit maar op het lokale OS bestandssysteem. Het ontdoet zich volledig van de Hadoop beperkingen en is vergelijkbaar met de traditionele opslaglaag in een kolomvormig MPP. In het algemeen bent u waarschijnlijk beter af met BI en dashboard use cases op een MPP, bv. Impala + Kudu dan op Hadoop. Dit gezegd zijnde, hebben MPP’s hun eigen beperkingen op het vlak van veerkracht, concurrency en schaalbaarheid. Als je tegen deze beperkingen aanloopt, zijn Hadoop en zijn naaste neef Spark goede opties voor BI-workloads. We behandelen al deze beperkingen in onze training Big Data for Data Warehouse Professionals en doen aanbevelingen wanneer een RDBMS te gebruiken en wanneer SQL op Hadoop/Spark.
Het verdict. Zijn dimensionale modellen en sterschema’s verouderd?
We weten allemaal dat Ralph Kimball met pensioen is. Maar zijn ideeën en concepten zijn nog steeds geldig en leven voort. We moeten ze aanpassen voor nieuwe technologieën en opslagtypes, maar ze zijn nog steeds van toegevoegde waarde.
Leer mij Big Data om mijn carrière vooruit te helpen
Aanvullende lectuur over dimensionele modellering in het tijdperk van Big Data
Tom Breur: Het verleden en de toekomst van dimensionale modellering
Edosa Odaro: 5 radicale tips voor snelle Big Data-integratie – het anti-datawarehousepatroon