Methode 1, slecht: ORDER BY NEWID()
Gemakkelijk om te schrijven, maar het presteert als hete, hete rotzooi omdat het de hele geclusterde index scant, waarbij NEWID() op elke rij wordt berekend:
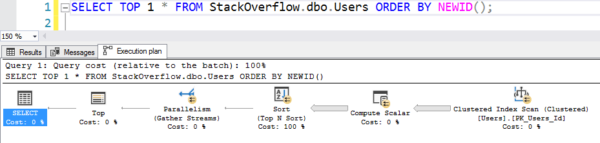
Het plan met de scan
Dat duurde 6 seconden op mijn machine, parallel over meerdere threads, waarbij tientallen seconden CPU werden gebruikt voor al dat rekenwerk en sorteren. (En de Gebruikers tabel is niet eens 1GB.)
Methode 2, Beter maar Vreemd: TABELSAMPLE
Deze kwam uit in 2005, en heeft een ton gotchas. Het is een soort willekeurige pagina kiezen, en dan een aantal rijen van die pagina terugsturen. De eerste rij is willekeurig, maar de rest niet.
Transact-SQL
|
1
|
SELECT * FROM StackOverflow.dbo.Users TABLESAMPLE (.01 PERCENT);
|
Het plan ziet eruit alsof het een table scan uitvoert, maar het doet slechts 7 logische lezingen:
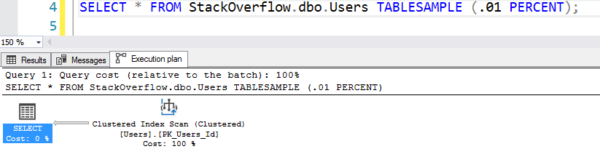
Het plan met de nepscan
Maar hier zijn de resultaten – u kunt zien dat het naar een willekeurige pagina van 8K springt en dan begint met het in volgorde voorlezen van rijen. Het zijn niet echt willekeurige rijen.
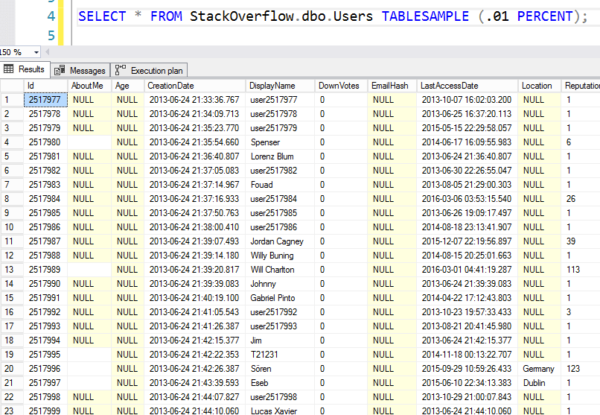
Random als maffia lotnummers
Je kunt in plaats daarvan de ROWS steekproefgrootte gebruiken, maar dat levert nogal vreemde resultaten op. Bijvoorbeeld, in de Stack Overflow Gebruikers tabel, wanneer ik TABLESAMPLE (50 ROWS) zei, kreeg ik in feite 75 rijen terug. Dat komt omdat SQL Server de rijen omzet naar een percentage.
Methode 3, de beste, maar vereist code: Random Primary Key
Geef het hoogste ID veld in de tabel, genereer een willekeurig nummer, en zoek naar dat ID. Hier sorteren we op de ID omdat we het bovenste record willen vinden dat werkelijk bestaat (terwijl een willekeurig nummer verwijderd kan zijn). Best snel, maar is slechts goed voor één enkele willekeurige rij. Als je 10 rijen wil, zou je code als deze 10 keer moeten aanroepen (of 10 willekeurige nummers genereren en een IN clausule gebruiken.
Het uitvoeringsplan toont een geclusterde indexscan, maar het pakt slechts één rij – we hebben het over slechts 6 logische lezingen voor alles wat je hier ziet, en het eindigt bijna onmiddellijk:

Het plan dat kan
Er is één probleem: als de Id negatieve getallen heeft, zal het niet werken zoals verwacht. (Bijvoorbeeld, stel je begint je identiteitsveld op -1 en stap -1, steeds naar beneden, zoals mijn moraal.)
Methode 4, OFFSET-FETCH (2012+)
Daniel Hutmacher voegde deze toe in de commentaren:
En zei: “Maar het werkt alleen goed met een geclusterde index. Ik denk dat dat komt omdat het scant voor (@rows) rijen in een heap in plaats van een index seek te doen.”
Bonus Track #1: Kijk hoe wij dit bespreken
Weleens afgevraagd hoe het is om in de chatroom van ons bedrijf te zitten? Deze 10 minuten durende Slack-discussie geeft u een aardig idee:
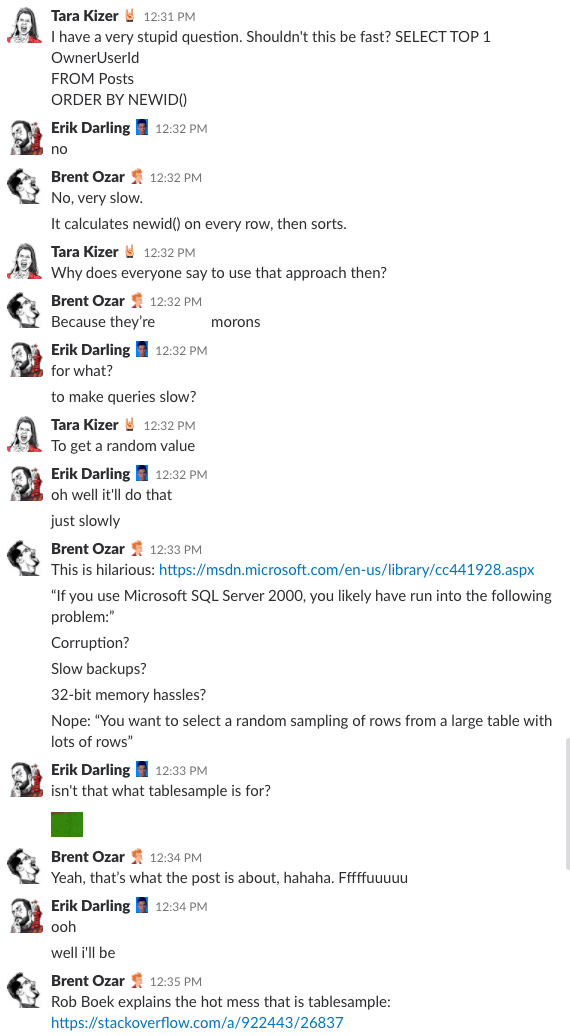
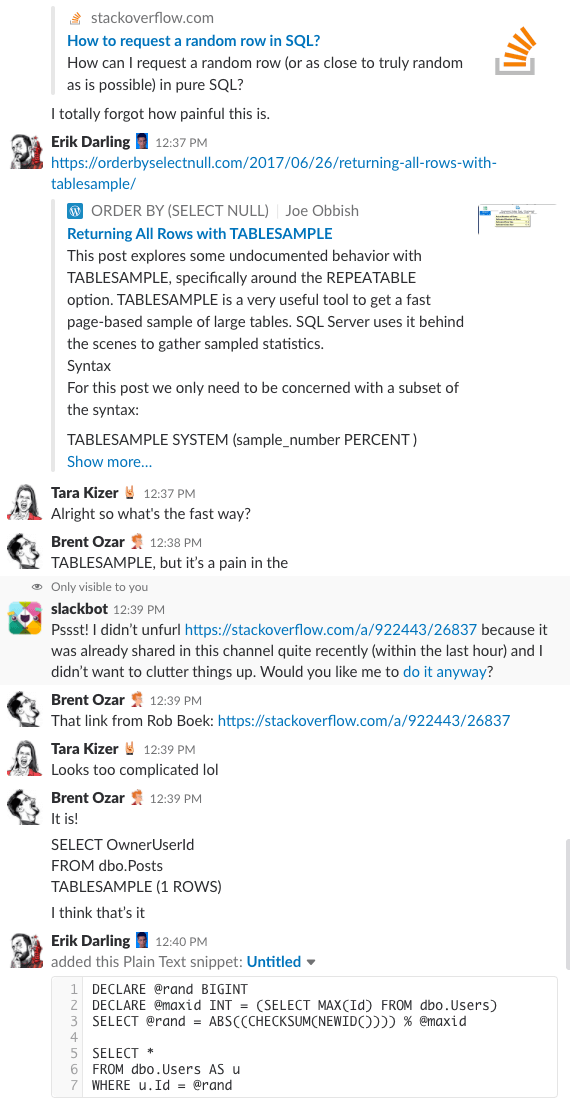
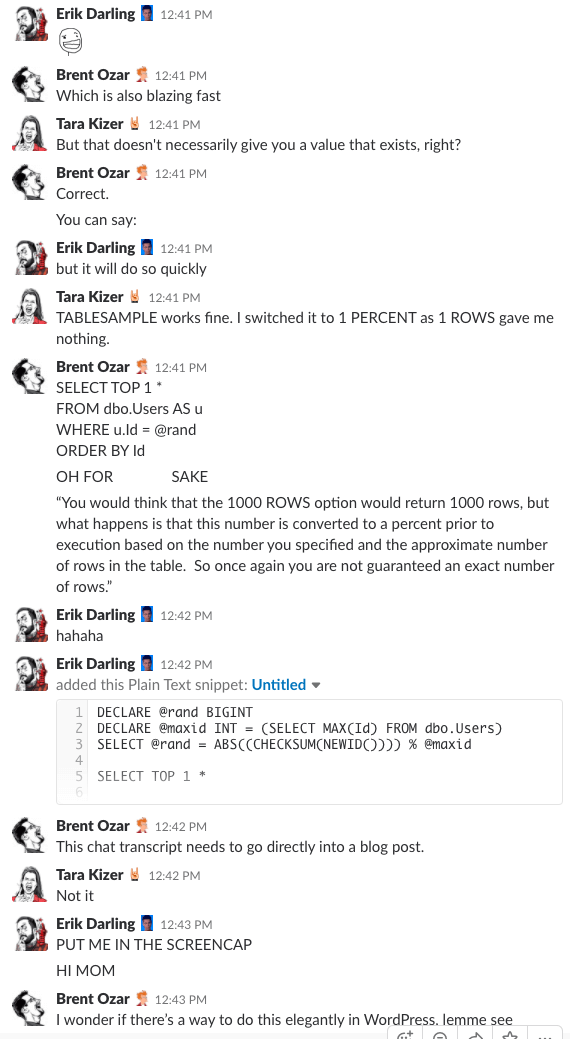
Spoiler alert: die was er niet. Ik heb alleen screenshots gemaakt.
Bonus Track #2: Mitch Wheat Digs Deeper
Wil je een diepgaande analyse van de willekeurigheid van verschillende technieken? Mitch Wheat duikt echt diep, compleet met grafieken!