Het bovenstaande plaatje heeft je misschien genoeg idee gegeven waar deze post over gaat.
Deze post behandelt enkele van de belangrijke fuzzy (niet precies gelijk, maar lumpsum dezelfde strings, zeg RajKumar & Raj Kumar) string matching algoritmen die omvat:
Hamming Distance
Levenstein Distance
Damerau Levenstein Distance
N-Gram based string matching
BK Tree
Bitap algoritme
Maar we moeten eerst weten waarom fuzzy matching belangrijk is gezien een real-world scenario. Wanneer een gebruiker gegevens mag invoeren, kan het er echt rommelig aan toe gaan, zoals in het onderstaande geval!!
Let,
- Uw naam is ‘Saurav Kumar Agarwal’.
- U hebt een bibliotheekpas gekregen (met een uniek ID natuurlijk) die voor elk lid van uw gezin geldig is.
- U gaat elke week naar een bibliotheek om een aantal boeken uit te geven. Maar hiervoor moet u eerst een aantekening maken in een register bij de ingang van de bibliotheek waar u uw ID & naam invult.
Nu besluiten de bibliotheekautoriteiten om de gegevens in dit bibliotheekregister te analyseren om een idee te krijgen van de unieke lezers die elke maand langskomen. Nu, dit kan worden gedaan voor vele redenen (zoals om te gaan voor uitbreiding van het terrein of niet, moet het aantal boeken verhoogd? etc).
Ze zijn van plan om dit te doen door het tellen van (unieke namen, Bibliotheek ID) paren geregistreerd voor een maand. Dus als we
123 Mehul
123 Rajesh
123 Mehul
133 Rajesh
133 Sandesh
Dit zou ons 4 unieke lezers moeten opleveren.
So far so good
Ze schatten dit aantal op ongeveer 10k-10.5k, maar het aantal steeg tot ~50k na analyse van de namen.
wooohhh!!
Betreurig slechte schatting moet ik zeggen!
Of hebben ze hier een truc gemist?
Na een diepere analyse kwam er een groot probleem aan het licht. Herinner je je naam, ‘Saurav Agarwal’. Ze vonden een aantal vermeldingen die leiden naar 5 verschillende gebruikers in uw familie bibliotheek ID:
- Saurav K Aggrawal (let op de dubbele ‘g’, ‘ra-ar’, Kumar wordt K)
- Saurav Kumar Agarwal
- Sourav Aggarwal
- SK Agarwal
- Agarwal
Er bestaan enkele onduidelijkheden omdat de bibliotheekautoriteiten niet weten
- Hoeveel mensen uit uw familie de bibliotheek bezoeken? of deze 5 namen een enkele lezer, 2 of 3 verschillende lezers vertegenwoordigen. Noem het een probleem zonder toezicht, waarbij we een string hebben die niet-gestandaardiseerde namen vertegenwoordigt, maar waarvan de gestandaardiseerde namen niet bekend zijn (bijvoorbeeld Saurav Agarwal: Saurav Kumar Agarwal is niet bekend)
- Zouden ze allemaal moeten worden samengevoegd tot ‘Saurav Kumar Agarwal’? kan ik niet zeggen, want SK Agarwal kan ook Shivam Kumar Agarwal zijn (zeg maar de naam van uw vader). Ook kan de enige Agarwal iedereen uit de familie zijn.
De laatste 2 gevallen (SK Agarwal & Agarwal) zou wat extra informatie vereisen (zoals geslacht, geboortedatum, uitgegeven boeken) die zal worden toegevoerd aan een ML-algoritme om de werkelijke naam van de lezer te bepalen & moet voor nu worden gelaten. Maar een ding ben ik vrij zeker is de 1e 3 namen vertegenwoordigen dezelfde persoon & Ik moet geen extra informatie nodig om ze samen te voegen tot een enkele lezer dwz ‘Saurav Kumar Agarwal’.
Hoe dit kan worden gedaan?
Hier komt fuzz string matching wat betekent een bijna exacte match tussen strings die iets van elkaar verschillen (meestal als gevolg van verkeerde spelling), zoals ‘Agarwal’ & ‘Aggarwal’ & ‘Aggrawal’. Als we een string krijgen met een acceptabele foutmarge (zeg een letter fout), dan beschouwen we die als een match. Dus laten we eens onderzoeken →
Hamming afstand is de meest voor de hand liggende afstand berekend tussen twee tekenreeksen van gelijke lengte die een telling geeft van tekens die niet overeenkomen met een bepaalde index. Bijvoorbeeld: ‘Bat’ & ‘Bet’ heeft hammingafstand 1 als bij index 1, ‘a’ niet gelijk aan ‘e’
Levensteinafstand/ Bewerkingsafstand
Ik neem aan dat u vertrouwd bent met Levensteinafstand &Recursie. Zo niet, lees dit dan. De onderstaande uitleg is meer een samengevatte versie van Levenstein’s distance.
Let ‘x’= length(Str1) & ‘y’=length(Str2) voor deze hele post.
Levenstein Distance berekent het minimum aantal bewerkingen dat nodig is om ‘Str1’ om te zetten in ‘Str2’ door het uitvoeren van ofwel Toevoeging, Verwijdering, of Vervangen van tekens. Dus ‘Cat’ & ‘Bat’ heeft bewerkingsafstand ‘1’ (Vervang ‘C’ door ‘B’) terwijl het voor ‘Ceat’ & ‘Bat’, 2 zou zijn (Vervang ‘C’ naar ‘B’; Verwijder ‘e’).
Over het algoritme gesproken, het bestaat in hoofdzaak uit 5 stappen
int LevensteinDistance(string str1, string str2, int x, int y){if (x == len(str1)+1) return len(str2)-y+1;if (y == len(str2)+1) return len(str1)-x+1;if (str1 == str2)
return LevensteinDistance(str1, str2, x+ 1, y+ 1);return 1 + min(LevensteinDistance(str1, str2, x, y+ 1), #insert LevensteinDistance(str1, str2, x+ 1, y), #remove LevensteinDistance(str1, str2, x+ 1, y+ 1) #replace
}
LevenesteinDistance('abcd','abbd',1,1)
Wat we doen is beginnen met het lezen van strings vanaf het 1e teken
- Als het teken op index ‘x’ van str1 overeenkomt met het teken op index ‘y’ van str2, &bereken de bewerkingsafstand door
LevensteinDistance(str1,str2)
- Als ze niet overeenkomen, weten we dat een bewerking nodig is. Dus voegen we +1 toe aan de huidige edit_distance & berekent recursief de edit_distance voor 3 voorwaarden & neemt het minimum uit de drie:
Levenstein(str1,str2) → invoeging in str2.
Levenstein(str1,str2) →deletion in str2
Levenstein(str1,str2)→replacement in str2
- Als een van de strings tijdens de recursie geen tekens meer heeft, wordt de lengte van de resterende tekens in de andere tekenreeks opgeteld bij de bewerkingsafstand (de eerste twee if-statements)
Demerau-Levenstein-afstand
Zie ‘abcd’ & ‘acbd’. Als we uitgaan van Levenstein Distance, zou dit zijn (vervang ‘b’-‘c’ & ‘c’-‘b’ op indexposities 2 & 3 in str2) Maar als je goed kijkt, zijn beide karakters verwisseld zoals in str1 & als we een nieuwe operatie ‘Swap’ introduceren naast ‘addition’, ‘deletion’ & ‘replace’, kan dit probleem worden opgelost. Deze introductie kan ons helpen problemen op te lossen zoals ‘Agarwal’ & ‘Agrawal’.
Deze bewerking wordt toegevoegd door de onderstaande pseudocode
1 +
(x - last_matching_index_y - 1 ) +
(y - last_matching_index_x - 1 ) +
LevinsteinDistance(str1, str2)
Laten we de bovenstaande bewerking uitvoeren voor ‘abcd’ & ‘acbd’ waarbij verondersteld wordt
initial_x=1 & initial_y=1 (Beginnen met indexeren vanaf 1 & niet vanaf 0 voor beide strings).
current x=3 & y=3 dus str1 & str2 op respectievelijk ‘c’ (abcd) & ‘b’ (acbd).
Bovengrenzen opgenomen in de hieronder genoemde slicing-operatie. Vandaar dat ‘qwerty’ ‘qwer’ zal betekenen.
- last_matching_index_y zal de laatste_index in str2 zijn die matchte met str1 d.w.z. 2 als ‘c’ in ‘acbd’ (index 2)matchte met ‘c’ in ‘abcd’.
- last_matching_index_x zal de laatste_index in str1 zijn die matchte met str2 d.w.z. 2 als ‘b’ in ‘acbd’ (index 2)matchte met ‘c’ in ‘abcd’.
- last_matching_index_x zal de laatste_index in str1 zijn die matchte met str2 d.w.z.e 2 als ‘b’ in ‘abcd’ (index 2)matched met ‘b’ in ‘acbd’.
- Dus, volgens de pseudocode hierboven, DemarauLevenstein(‘abc’,’acb’)=
1+(4-3-1) + (4-3-1)+LevensteinDistance(‘a’,’a’)=1+0+0+0=1. Dit zou 2 zijn geweest als we Levenstein Distance
N-Gram
N-gram is in feite niets anders dan een reeks waarden die uit een string worden gegenereerd door opeenvolgend voorkomende ‘n’ tekens/woorden aan elkaar te koppelen. Bijvoorbeeld: n-gram met n=2 voor ‘abcd’ zal zijn ‘ab’,’bc’,’cd’.
Nu kunnen deze n-grammen worden gegenereerd voor strings waarvan de overeenkomst moet worden gemeten & verschillende metrieken kunnen worden gebruikt om de overeenkomst te meten.
Laat ‘abcd’ & ‘acbd’ twee strings zijn die met elkaar moeten worden vergeleken.
n-grammen met n=2 voor
‘abcd’=ab,bc,cd
‘acbd’=ac,cb,bd
Component match (q-grammen)
Telling van n-grammen die voor de twee strings precies met elkaar overeenkomen. Hier zou het 0 zijn
Cosineovereenkomst
Berekening van het dot-product na omzetting van de voor de tekenreeksen gegenereerde n-grammen in vectoren
Componentovereenstemming (volgorde buiten beschouwing gelaten)
Overeenstemming van n-gramcomponenten zonder rekening te houden met de volgorde van de elementen in het geheel, d.w.z. bc=cb.
Er bestaan nog veel meer van dergelijke metrieken, zoals Jaccard-afstand, Tversky Index, enz. die hier niet zijn besproken.
BK Tree
BK tree is een van de snelste algoritmen om gelijksoortige tekenreeksen te vinden (uit een verzameling tekenreeksen) voor een gegeven tekenreeks. BK tree gebruikt een
- Levenstein-afstand
- driehoeksongelijkheid (zal aan het eind van deze sectie worden behandeld)
om gelijksoortige strings te vinden (& niet slechts één beste string).
Een BK tree wordt gemaakt met behulp van een pool van woorden uit een beschikbaar woordenboek. Stel we hebben een woordenboek D={Book, Books, Cake, Boo, Boon, Cook, Cape, Cart}
Een BK-boom wordt gemaakt door
- Selecteer een hoofdknooppunt (kan elk woord zijn). Laat het ‘Boeken’
- Ga door elk woord W in woordenboek D, bereken zijn Levenstein-afstand met de hoofdnode, en maak het woord W kind van de hoofdnode als er geen kind met dezelfde Levenstein-afstand voor de ouder bestaat. Invoegen van Boeken & Cake.
Levenstein(Boeken,Boek)=1 & Levenstein(Boeken,Cake)=4. Aangezien er geen kind met dezelfde afstand is gevonden voor ‘Boek’, maak ze nieuwe kinderen voor wortel.
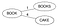
- Als er een kind met dezelfde Levenstein-afstand bestaat voor de ouder P, beschouw dat kind dan als een ouder P1 voor dat woord W, bereken Levenstein(ouder, woord) en als er geen kind met dezelfde afstand bestaat voor de ouder P1, maak dan van het woord W een nieuw kind voor P1 anders gaat u verder naar beneden in de boom.
Overweeg het invoegen van Boo. Levenstein(Book, Boo)=1 maar er bestaat al een kind met dezelfde naam, namelijk Books. Bereken daarom nu Levenstein(Boeken, Boo)=2. Omdat er geen kind met dezelfde afstand bestaat voor Boeken, maak je Boo kind van Boeken.

Op dezelfde manier, alle woorden uit het woordenboek in de BK Tree invoegen

Wanneer de BK Tree eenmaal is voorbereid, moeten we voor het zoeken naar gelijksoortige woorden voor een bepaald woord (Query word) een tolerantie_drempel instellen, zeg ’t’.
- Dit is de maximale bewerkingsafstand die we in aanmerking nemen voor de gelijkenis tussen een knooppunt & query_woord. Alles daarboven wordt verworpen.
- Ook zullen we alleen die kinderen van een ouder-knooppunt in aanmerking nemen voor vergelijking met Query waar de Levenstein(Child, Parent) binnen
ligt
Waarom? wordt binnenkort besproken
- Als deze voorwaarde waar is voor een kind, dan berekenen we alleen Levenstein(Child, Query) dat als vergelijkbaar met query zal worden beschouwd als
Levenshtein(Child, Query)≤t.
- Hiermee berekenen we niet de Levenstein-afstand voor alle knooppunten/woorden in het woordenboek met het query-woord & en besparen we dus veel tijd wanneer de woordenpool enorm is
Hiermee, een Kind lijkt op Query als
- Levenstein(Ouder, Query)-t ≤ Levenstein(Kind,Ouder) ≤ Levenstein(Ouder,Query)+t
- Levenstein(Kind,Query)≤t
Laten we snel een voorbeeld doornemen. Stel ’t’=1
Laat het woord waarvoor we gelijkende woorden moeten vinden ‘Care’ (Query-woord)
- Levenstein(Boek,Care)=4 zijn. Aangezien 4>1, wordt ‘Boek’ verworpen. Nu zullen we alleen die kinderen van ‘Boek’ overwegen die een LevisteinDistance(Kind,’Boek’) hebben tussen 3(4-1) & 5(4+1). Daarom zouden we ‘Boeken’ & al zijn kinderen verwerpen omdat 1 niet binnen de gestelde grenzen ligt
- Als Levenstein(Cake, Boek)=4 die tussen 3 & 5 ligt, zullen we Levenstein(Cake, Zorg)=1 controleren die ≤1 is vandaar een gelijkaardig woord.
- Aanpassing van de grenzen, voor Cake’s kinderen, wordt 0(1-1) & 2(1+1)
- Aangezien beide Cape & Cart respectievelijk Levenstein(Child, Parent)=1 & 2 heeft, komen beide in aanmerking om getest te worden met ‘Care’.
- Als Levenstein(Cape,Care)=1 ≤1& Levenstein(Cart,Care)=2>1, wordt alleen Cape beschouwd als een woord dat lijkt op ‘Care’.
Hiermee hebben we 2 woorden gevonden die lijken op ‘Care’ en dat zijn: Cake & Cape
Maar op basis waarvan beslissen we over de grenzen
Levenstein(Parent,Query)-t, Levenstein(Parent,Query)+t.
voor elk kinderknooppunt?
Dit volgt uit Driehoeksongelijkheid die stelt
Afstand (A,B) + Afstand(B,C)≥Afstand(A,C) waarbij A,B,C zijden van een driehoek zijn.
Hoe dit idee ons aan deze grenzen helpt, laten we eens zien:
Laat Query,=Q Ouder=P & Kind=C een driehoek vormen met Levenstein-afstand als randlengte. Laat ’t’ de tolerantie_drempel zijn. Dan, Door bovenstaande ongelijkheid
Levenstein(P,C) + Levenstein(P,Q)≥Levenstein(C,Q)as Levenstein(C, Q) can't exceed 't'(threshold set earlier for C to be similar to Q), HenceLevenstein(P,C) + Levenstein(P,Q)≥ t
OrLevenstein(P,C)≥|Levenstein(P,Q)-t| i.e the lower limit is set
Opnieuw, door Driehoeksongelijkheid,
Levenstein(P,Q) + Levenstein(C,Q) ≥ Levenstein(P,C) or
Levenstein(P,Q) + t ≥ Levenstein(P,C) or the upper limit is set
Bitap algoritme
Het is ook een zeer snel algoritme dat vrij efficiënt kan worden gebruikt voor fuzzy string matching. Dit komt omdat het gebruik maakt van bitwise operaties & omdat deze vrij snel zijn, het algoritme staat bekend om zijn snelheid. Laten we beginnen zonder iets te verspillen:
Let S0=’ababc’ is het patroon dat gematcht moet worden met string S1=’abdababc’.
Voreerst,
- Bepaal alle unieke karakters in S1 & S0 die a,b,c,d
- Vorm bitpatronen voor elk karakter. Hoe?

- Keer het te doorzoeken patroon S0 om
- Voor bitpatroon voor teken x, plaats 0 waar het voorkomt in patroon anders 1. In T, ‘a’ komt voor op de 3e & 5e plaats, we plaatsen 0 op die posities & rest 1.
Op dezelfde manier, vorm alle andere bitpatronen voor verschillende tekens in het woordenboek.
S0=ababc S1=abdababc
- Neem een begintoestand van een bitpatroon van lengte(S0) met alle 1’s. In ons geval zou dat 11111 zijn (toestand S).
- Als we beginnen te zoeken in S1 en een willekeurig teken passeren,
verschuif een 0 op het onderste bit, d.w.z. het 5e bit van rechts in S &
OR bewerking op S met T.
Dus, als we de eerste ‘a’ in S1 tegenkomen, zullen we
- Links Shift een 0 in S bij het laagste bit om 11111 →11110
- 11010 | 11110=11110
Nu, als we naar het tweede teken ‘b’ gaan,
- Shift 0 naar S i.e om 11110 te vormen →11100
- S |T=11100 | 10101=11101
Als ‘d’ wordt aangetroffen
- Verplaats 0 naar S om 11101 te vormen →11010
- S |T=11010 |11111=11111
Observeer dat als ‘d’ niet in S0 is, de toestand S wordt gereset. Als u eenmaal door heel S1 bent gegaan, krijgt u bij elk teken de onderstaande toestanden

Hoe weet ik of ik een fuzz/full match heb gevonden?
- Als een 0 het hoogste bit in het bitpatroon van status S bereikt (zoals in het laatste teken ‘c’), hebt u een volledige overeenkomst
- Voor een fuzz-match observeert u 0 op verschillende posities van status S. Als 0 op de 4e plaats staat, vinden we 4/5 tekens in dezelfde volgorde als in S0. Evenzo voor 0 op andere plaatsen.
Een ding heb je misschien opgemerkt dat al deze algoritmen werken op de spelling gelijkenis van strings. Kunnen er nog andere criteria zijn voor fuzzy matching? Ja,
Fonetiek
Wij zullen de fonetiek (op klank gebaseerd, zoals Saurav & Sourav, moet een exacte overeenkomst in fonetiek hebben) gebaseerde fuzz match algoritmen als volgende behandelen!
- Dimensie Reductie (3 delen)
- NLP Algoritmen(5 delen)
- Basisprincipes van versterkingsleren (5 delen)
- Beginnend met Tijd-Series (7 delen)
- Object Detection using YOLO (3 delen)
- Tensorflow voor beginners (concepten + voorbeelden) (4 delen)
- Preprocessing Time Series (met codes)
- Data Analytics voor beginners
- Statistiek voor beginners (4 delen)