- Introduction
- Goal
- A. Filtermethoden
- Chi-kwadraattest
- Fisher’s Score
- Correlatiecoëfficiënt
- Variantiedrempel
- Mean Absolute Difference (MAD)
- Dispersieverhouding
- B. Wrapper Methods:
- Forward Feature Selection
- Backward Feature Elimination
- Uitputtende kenmerkselectie
- Recursive Feature Elimination
- C. Ingebedde methoden:
- LASSO Regularization (L1)
- Random Forest-belang
- Conclusie
Introduction
Bij het bouwen van een machine-learningmodel in het echte leven is het bijna zeldzaam dat alle variabelen in de dataset nuttig zijn om een model te bouwen. Het toevoegen van overbodige variabelen vermindert het generalisatievermogen van het model en kan ook de algemene nauwkeurigheid van een classificator verminderen. Bovendien verhoogt het toevoegen van meer en meer variabelen aan een model de totale complexiteit van het model.
Volgens de wet van Parsimony of ‘Occam’s Razor’ is de beste verklaring voor een probleem die welke zo weinig mogelijk veronderstellingen inhoudt. Aldus wordt feature selectie een onmisbaar onderdeel van het bouwen van machine learning modellen.
Goal
Het doel van feature selectie bij machine learning is het vinden van de beste set features waarmee men bruikbare modellen van bestudeerde fenomenen kan bouwen.
De technieken voor feature selectie bij machine learning kunnen grofweg in de volgende categorieën worden ingedeeld:
Supervised Techniques: Deze technieken kunnen worden gebruikt voor gelabelde gegevens, en worden gebruikt om de relevante kenmerken te identificeren voor het verhogen van de efficiëntie van gesuperviseerde modellen zoals classificatie en regressie.
Unsupervised Techniques: Deze technieken kunnen worden gebruikt voor ongelabelde gegevens.
Vanuit een taxonomisch oogpunt worden deze technieken als volgt ingedeeld:
A. Filtermethoden
B. Wrapper-methoden
C. Ingebedde methoden
D. Hybride methoden
In dit artikel bespreken we enkele populaire technieken voor kenmerkselectie bij machinaal leren.
A. Filtermethoden
Filtermethoden pikken de intrinsieke eigenschappen van de kenmerken op, gemeten via univariate statistieken in plaats van cross-validatieprestaties. Deze methoden zijn sneller en minder rekenintensief dan wrapper-methoden. Bij hoogdimensionale gegevens is het computationeel goedkoper om filtermethoden te gebruiken.
Laten we enkele van deze technieken bespreken:
Informatiewinst
Informatiewinst berekent de vermindering in entropie door de transformatie van een dataset. Het kan worden gebruikt voor kenmerkenselectie door de informatiewinst van elke variabele in de context van de doelvariabele te evalueren.
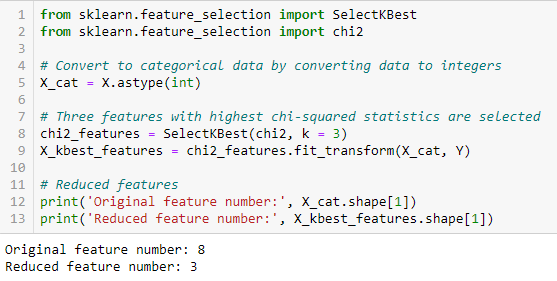
Chi-kwadraattest
De Chi-kwadraattest wordt gebruikt voor categorische kenmerken in een dataset. We berekenen de Chi-kwadraten tussen elk kenmerk en het doel en selecteren het gewenste aantal kenmerken met de beste Chi-kwadraatscores. Om de chi-kwadraat correct toe te passen om de relatie tussen verschillende features in de dataset en de doelvariabele te testen, moet aan de volgende voorwaarden worden voldaan: de variabelen moeten categorisch zijn, onafhankelijk zijn bemonsterd en de waarden moeten een verwachte frequentie hebben die groter is dan 5.
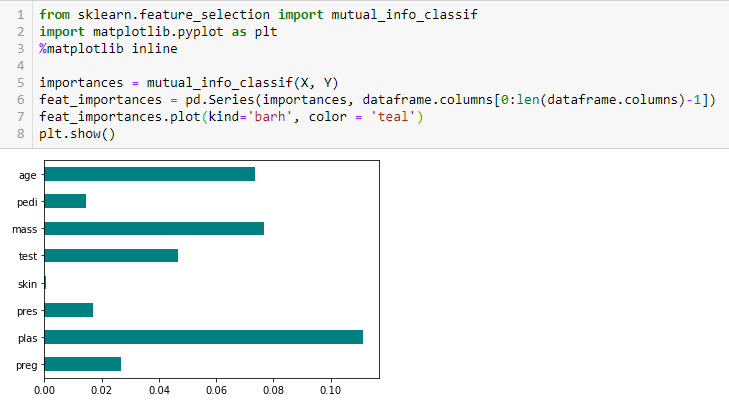
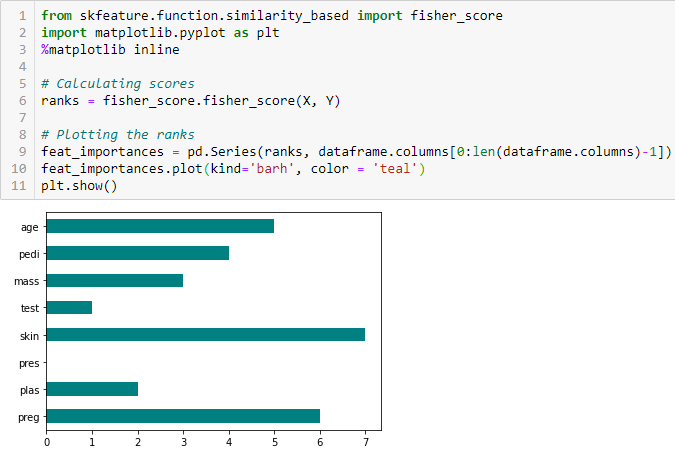
Fisher’s Score
Fisher score is een van de meest gebruikte methoden voor feature-selectie onder supervisie. Het algoritme dat we zullen gebruiken, geeft de rangschikking van de variabelen op basis van de Fisher’s Score in aflopende volgorde. Vervolgens kunnen we de variabelen selecteren op basis van het geval.
Correlatiecoëfficiënt
Correlatie is een maat voor het lineaire verband tussen 2 of meer variabelen. Door correlatie kunnen we de ene variabele voorspellen aan de hand van de andere. De logica achter het gebruik van correlatie voor kenmerkselectie is dat de goede variabelen sterk gecorreleerd zijn met het doel. Bovendien moeten variabelen gecorreleerd zijn met het doel, maar onderling niet gecorreleerd zijn.
Als twee variabelen gecorreleerd zijn, kunnen we de ene variabele voorspellen aan de hand van de andere. Als twee kenmerken gecorreleerd zijn, heeft het model er dus maar één nodig, want het tweede voegt geen extra informatie toe. We zullen hier de Pearson Correlation gebruiken.
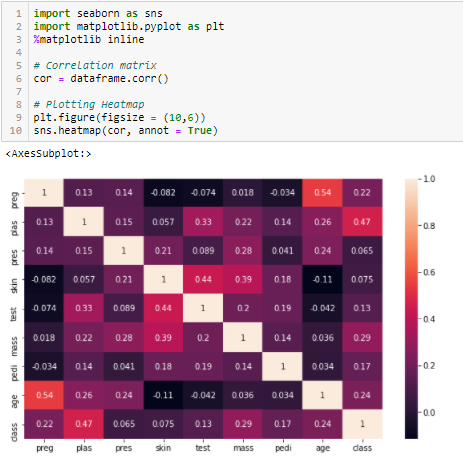
We moeten een absolute waarde, zeg 0,5, instellen als drempel voor de selectie van de variabelen. Als we vaststellen dat de voorspellende variabelen onderling gecorreleerd zijn, kunnen we de variabele laten vallen die een lagere correlatiecoëfficiëntwaarde heeft met de doelvariabele. Wij kunnen ook meervoudige correlatiecoëfficiënten berekenen om na te gaan of meer dan twee variabelen met elkaar gecorreleerd zijn. Dit fenomeen staat bekend als multicollineariteit.
Variantiedrempel
De variantiedrempel is een eenvoudige basisbenadering van kenmerkenselectie. Het verwijdert alle kenmerken waarvan de variantie niet aan een bepaalde drempelwaarde voldoet. Standaard verwijdert het alle zero-variantie features, d.w.z. features die dezelfde waarde hebben in alle samples. We nemen aan dat features met een hogere variantie meer nuttige informatie bevatten, maar we houden geen rekening met de relatie tussen feature-variabelen of tussen features en doel-variabelen, wat een van de nadelen is van filtermethoden.

De get_support retourneert een Booleaanse vector waarbij True betekent dat de variabele geen variantie nul heeft.
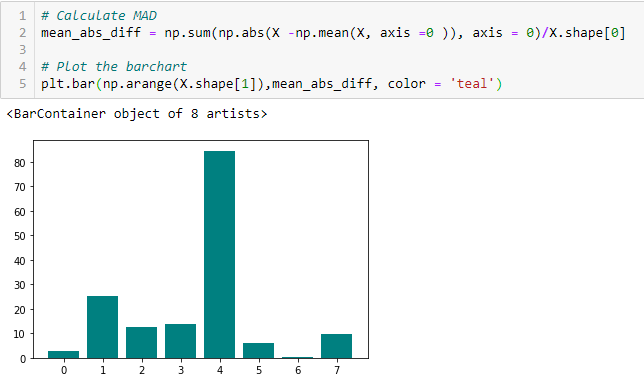
Mean Absolute Difference (MAD)
‘Het gemiddelde absolute verschil (MAD) berekent het absolute verschil ten opzichte van de gemiddelde waarde. Het belangrijkste verschil tussen de variantie- en de MAD-maatstaf is de afwezigheid van het kwadraat in de laatste. De MAD is, net als de variantie, ook een schaalvariant. Dit betekent dat hoger de MAD, hoger het discriminerend vermogen.
Dispersieverhouding
‘Een andere maat voor dispersie past het rekenkundig gemiddelde (AM) en het meetkundig gemiddelde (GM) toe. Voor een gegeven (positief) kenmerk Xi op n patronen worden het AM en het GM gegeven door respectievelijk
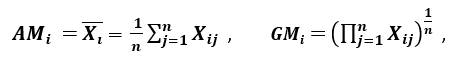
; aangezien AMi ≥ GMi, waarbij gelijkheid geldt indien en slechts indien Xi1 = Xi2 = …. = Xin, kan de verhouding
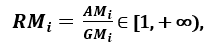
als dispersiemaat worden gebruikt. Een grotere spreiding impliceert een hogere waarde van Ri, dus een relevanter kenmerk. Omgekeerd, wanneer alle kenmerkmonsters (ongeveer) dezelfde waarde hebben, ligt Ri dicht bij 1, wat duidt op een weinig relevant kenmerk.

 ‘
‘
B. Wrapper Methods:
Wrappers vereisen een of andere methode om de ruimte van alle mogelijke subsets van features te doorzoeken en de kwaliteit daarvan te beoordelen door een classifier met die feature subset te leren en te evalueren. Het selectieproces van de features is gebaseerd op een specifiek machine-learning algoritme dat we op een gegeven dataset proberen toe te passen. Het volgt een greedy search-benadering door alle mogelijke combinaties van features te evalueren aan de hand van het evaluatiecriterium. De wrapper-methoden resulteren gewoonlijk in een betere voorspellende nauwkeurigheid dan filtermethoden.
Laten we enkele van deze technieken bespreken:
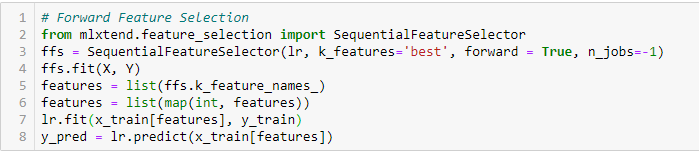
Forward Feature Selection
Dit is een iteratieve methode waarin we beginnen met de best presterende variabele ten opzichte van het doel. Vervolgens selecteren wij een andere variabele die het best presteert in combinatie met de eerste geselecteerde variabele. Dit proces gaat door totdat het vooraf ingestelde criterium is bereikt.
Backward Feature Elimination
Deze methode werkt precies tegenovergesteld aan de Forward Feature Selection-methode. Hier beginnen we met alle beschikbare features en bouwen we een model. Vervolgens kiezen we de variabele uit het model die de beste evaluatiewaarde oplevert. Dit proces wordt voortgezet totdat het vooraf ingestelde criterium is bereikt.
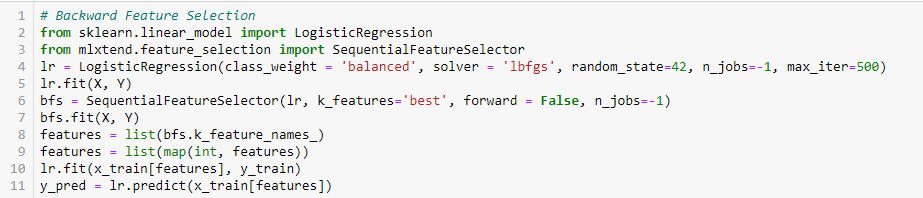
Deze methode staat samen met de hierboven besproken methode ook bekend als de sequentiële kenmerkselectiemethode.
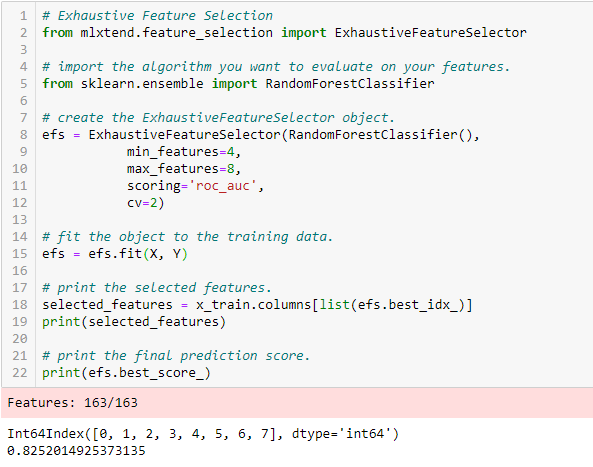
Uitputtende kenmerkselectie
Dit is de meest robuuste kenmerkselectiemethode die tot nu toe is behandeld. Dit is een brute-force evaluatie van elke feature subset. Dit betekent dat elke mogelijke combinatie van variabelen wordt geprobeerd en dat de best presterende subset wordt geretourneerd.
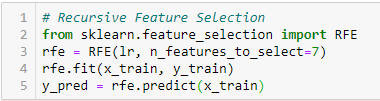
Recursive Feature Elimination
‘Gegeven een externe schatter die gewichten toekent aan kenmerken (bijv. de coëfficiënten van een lineair model), is het doel van recursieve kenmerkeliminatie (RFE) om kenmerken te selecteren door recursief steeds kleinere sets van kenmerken in overweging te nemen. Eerst wordt de schatter getraind op de initiële reeks kenmerken en wordt het belang van elk kenmerk verkregen via een coef_attribuut of via een kenmerk_belang_attribuut.
Dan worden de minst belangrijke kenmerken uit de huidige set van kenmerken gesnoeid. Deze procedure wordt recursief herhaald op de gesnoeide set, totdat het gewenste aantal te selecteren kenmerken uiteindelijk is bereikt.’
C. Ingebedde methoden:
Deze methoden omvatten de voordelen van zowel de wrapper- als de filtermethoden, door interacties van kenmerken op te nemen, maar ook redelijke computerkosten te handhaven. Ingebedde methoden zijn iteratief in de zin dat elke iteratie van het model trainingsproces verzorgt en zorgvuldig die kenmerken extraheert die het meest bijdragen aan de training voor een bepaalde iteratie.
Laten we, een aantal van deze technieken bespreken klik hier:
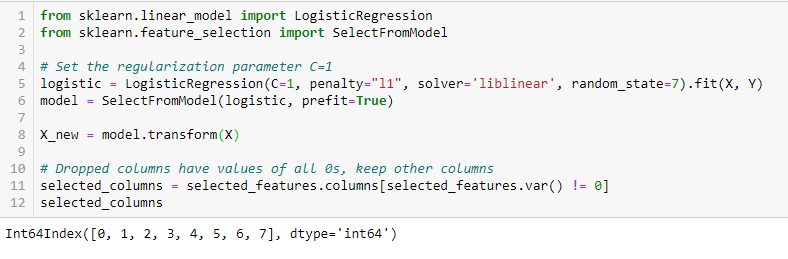
LASSO Regularization (L1)
Regularisatie bestaat uit het toevoegen van een straf aan de verschillende parameters van het machine learning model om de vrijheid van het model te verminderen, d.w.z. om over-fitting te voorkomen. Bij lineaire modelregularisatie wordt de straf toegepast op de coëfficiënten die elk van de voorspellers vermenigvuldigen. Van de verschillende soorten regularisatie heeft Lasso of L1 de eigenschap dat het in staat is sommige coëfficiënten tot nul te reduceren. Daarom kan die eigenschap uit het model worden verwijderd.
Random Forest-belang
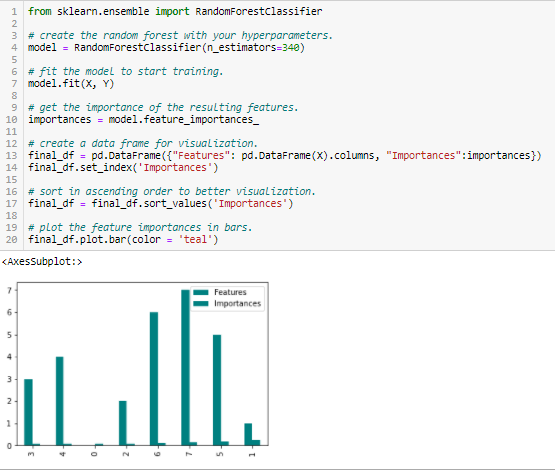
Random Forests is een soort Bagging-algoritme dat een bepaald aantal beslissingsbomen samenvoegt. De boom-gebaseerde strategieën die door random forests worden gebruikt, rangschikken natuurlijk naar hoe goed ze de zuiverheid van de knoop verbeteren, of met andere woorden een afname van de onzuiverheid (Gini onzuiverheid) over alle bomen. Knopen met de grootste afname in onzuiverheid komen aan het begin van de bomen voor, terwijl noten met de minste afname in onzuiverheid aan het einde van de bomen voorkomen. Door de bomen onder een bepaald knooppunt te snoeien, kunnen we dus een subset van de belangrijkste kenmerken creëren.
Conclusie
We hebben een paar technieken voor kenmerkenselectie besproken. We hebben bewust de feature-extractietechnieken zoals Principal Component Analysis, Singular Value Decomposition, Linear Discriminant Analysis, enz. buiten beschouwing gelaten. Deze methoden helpen de dimensionaliteit van de gegevens te verminderen of het aantal variabelen te verminderen met behoud van de variantie van de gegevens.
Naast de hierboven besproken methoden zijn er nog vele andere methoden voor feature selection. Er zijn ook hybride methoden die zowel filter- als wrappingtechnieken gebruiken. Als u meer wilt weten over feature selection-technieken, zou ik ‘Feature Selection for Data and Pattern Recognition’ van Urszula Stańczyk en Lakhmi C. Jain.