Herzien: December 11, 2020
Vertellen de proefpersonen de waarheid?
De betrouwbaarheid van zelfrapportagegegevens is een achilleshiel van enquête-onderzoek. Opiniepeilingen gaven bijvoorbeeld aan dat meer dan 40 procent van de Amerikanen elke week naar de kerk gaat. Echter, door het onderzoeken van kerkbezoekregisters, concludeerden Hadaway en Marlar (2005) dat de werkelijke opkomst minder dan 22 procent was. In zijn baanbrekende werk “Everybody lies,” vond Seth Stephens-Davidowitz (2017) ruimschoots bewijs om aan te tonen dat de meeste mensen niet doen wat ze zeggen en niet zeggen wat ze doen. Zo verklaarden de meeste kiezers in reactie op peilingen dat de etniciteit van de kandidaat onbelangrijk is. Door zoektermen in Google te controleren, ontdekte Sephens-Davidowitz echter het tegendeel: wanneer Google-gebruikers het woord “Obama” intikten, associeerden ze zijn naam altijd met bepaalde woorden die met ras te maken hadden.
Voor onderzoek naar webgebaseerde instructie kunnen gegevens over webgebruik worden verkregen door het toegangslogboek van de gebruiker te ontleden, cookies in te stellen of de cache te uploaden. Deze opties kunnen echter beperkt toepasbaar zijn. Het logboek van de gebruiker kan bijvoorbeeld niet nagaan welke gebruikers links naar andere websites volgen. Verder kunnen cookies of cache-benaderingen privacyproblemen opleveren. In deze situaties wordt gebruik gemaakt van door middel van enquêtes verzamelde zelfrapportagegegevens. Dit doet de vraag rijzen: Hoe nauwkeurig zijn zelfgerapporteerde gegevens? Cook en Campbell (1979) hebben erop gewezen dat proefpersonen (a) de neiging hebben te rapporteren wat zij denken dat de onderzoeker verwacht te zien, of (b) rapporteren wat een positieve weerspiegeling is van hun eigen bekwaamheden, kennis, overtuigingen, of meningen. Een ander punt van zorg met betrekking tot dergelijke gegevens is de vraag of de proefpersonen in staat zijn zich gedragingen uit het verleden nauwkeurig te herinneren. Psychologen hebben gewaarschuwd dat het menselijk geheugen feilbaar is (Loftus, 2016; Schacter, 1999). Soms “herinneren” mensen zich gebeurtenissen die nooit hebben plaatsgevonden. De betrouwbaarheid van zelfgerapporteerde gegevens is dus twijfelachtig.Hoewel statistische softwarepakketten in staat zijn om getallen tot 16-32 decimalen te berekenen, is deze precisie zinloos als de gegevens zelfs op geheel niveau niet nauwkeurig kunnen zijn. Heel wat geleerden hadden onderzoekers gewaarschuwd hoe meetfouten de statistische analyse kunnen verlammen (Blalock, 1974) en suggereerden dat goed onderzoek vereist dat de kwaliteit van de verzamelde gegevens wordt onderzocht (Fetter,Stowe, & Owings, 1984).
Bias en Variantie
Metingsfouten omvatten twee componenten, namelijk bias en variabele fout.Bias is een systematische fout die de neiging heeft om de gerapporteerde score naar één uiterste te duwen. Zo blijken verschillende versies van IQ-tests een vertekening te vertonen ten nadele van niet-blanken. Dit betekent dat zwarten en Spanjaarden meestal lagere scores krijgen, ongeacht hun werkelijke intelligentie. Een variabele fout, ook wel variantie genoemd, neigt ertoe willekeurig te zijn. Met andere woorden, de gerapporteerde scores kunnen zowel boven als onder de werkelijke scores liggen (Salvucci, Walter, Conley, Fink, & Saba, 1997).
De bevindingen van deze twee soorten meetfouten hebben verschillende implicaties. In een studie waarin zelfgerapporteerde gegevens over lengte en gewicht werden vergeleken met rechtstreeks gemeten gegevens (Hart & Tomazic, 1999), bleek bijvoorbeeld dat proefpersonen geneigd waren hun lengte te overrapporteren, maar hun gewicht onder te rapporteren. Het is duidelijk dat dit soort foutenpatroon eerder bias is dan variantie. Een mogelijke verklaring voor deze bias is dat de meeste mensen een beter fysiek beeld willen geven aan anderen. Als de meetfout echter willekeurig is, kan de verklaring gecompliceerder zijn.
Men kan aanvoeren dat variabele fouten, die willekeurig van aard zijn, elkaar zouden opheffen en dus geen bedreiging voor het onderzoek zouden vormen. Bijvoorbeeld, de eerste gebruiker kan zijn Internet-activiteiten met 10% overschatten, maar de tweede gebruiker kan haar activiteiten met 10% onderschatten. In dit geval kan het gemiddelde nog steeds juist zijn. Over- en onderschatting vergroten echter de variabiliteit van de verdeling. In veel parametrische tests wordt de variabiliteit binnen een groep als foutterm gebruikt. Een te grote variabiliteit zou de significantie van de test zeker beïnvloeden. Sommige teksten kunnen de bovenstaande misvatting versterken. Deese (1972) zei bijvoorbeeld:
De statistische theorie vertelt ons dat de betrouwbaarheid van waarnemingen evenredig is met de vierkantswortel van hun aantal. Hoe meer waarnemingen er zijn, hoe meer toevallige invloed er zal zijn. En de statistische theorie zegt dat hoe meer toevallige fouten er zijn, hoe groter de kans is dat ze elkaar opheffen en een normale verdeling opleveren (p.55).
Ten eerste is het waar dat als de steekproefgrootte toeneemt, de variantie van de verdeling afneemt, maar dat garandeert niet dat de vorm van de verdeling de normaliteit zal benaderen. Ten tweede moet de betrouwbaarheid (de kwaliteit van de gegevens) worden gekoppeld aan de meting en niet aan de bepaling van de steekproefgrootte. Een grote steekproefgrootte met veel meetfouten, zelfs willekeurige, zou de foutterm voor parametrische tests opblazen.
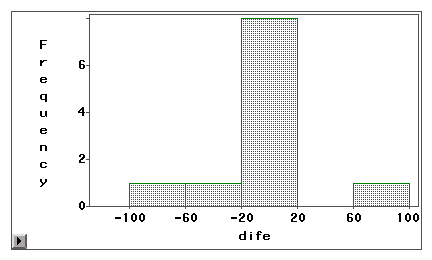
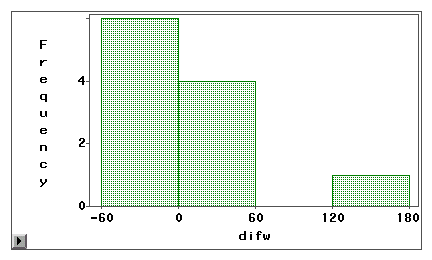
Een stam-en-blad-plot of een histogram kan worden gebruikt om visueel te onderzoeken of een meetfout het gevolg is van systematische vertekening of willekeurige variantie. In het volgende voorbeeld worden twee soorten internettoegang (surfen op het web en e-mail) gemeten door middel van zowel een zelfgerapporteerde enquête als een logboek. De verschilscores (meting 1 – meting 2) zijn uitgezet in de volgende histogrammen.
De eerste grafiek laat zien dat de meeste verschilscores rond nul gecentreerd zijn. Onder- en overrapportage aan beide uiteinden suggereren dat de meetfout eerder toevallige fouten zijn dan systematische vertekening.
De tweede grafiek geeft duidelijk aan dat er een hoge mate van meetfouten is omdat zeer weinig verschilscores om en nabij nul gecentreerd zijn. Bovendien is de verdeling negatief scheef en is de fout bias in plaats van variantie.
Hoe betrouwbaar is ons geheugen?
Schacter (1999) waarschuwde dat het menselijk geheugen feilbaar is. Er zijn zeven gebreken van ons geheugen:
- Vergankelijkheid: Afnemende toegankelijkheid van informatie in de loop van de tijd.
- Absent-mindedness: Onoplettende of oppervlakkige verwerking die bijdraagt aan zwakke herinneringen.
- Blokkering: De tijdelijke ontoegankelijkheid van informatie die in het geheugen is opgeslagen.
- Misattributie Het toeschrijven van een herinnering of idee aan de verkeerde bron.
- Suggestibiliteit: Herinneringen die worden geïmplanteerd als gevolg van leidende vragen of verwachtingen.
- Vooringenomenheid: Retrospectieve vervormingen en onbewuste invloeden die verband houden met huidige kennis en overtuigingen.
- Persistentie: Pathologische herinneringen-informatie of gebeurtenissen die we niet kunnen vergeten, ook al zouden we willen dat we dat wel konden.
 |
“Ik heb hier geen herinnering aan. Ik kan me niet herinneren dat ik het document voor Whitewater heb ondertekend. Ik weet niet meer waarom het document verdween en later weer verscheen. Ik herinner me niets.” “Ik herinner me de landing (in Bosnië) onder sluipschuttersvuur. Er zou een soort begroetingsceremonie zijn op het vliegveld, maar in plaats daarvan renden we met onze hoofden naar beneden om in de voertuigen te stappen om naar onze basis te gaan.” Tijdens het onderzoek naar het versturen van geheime informatie via een persoonlijke e-mailserver, vertelde Clinton de FBI 39 keer dat ze zich niets kon “herinneren” of “herinneren”. Voorzichtig: Er is een nieuw computervirus ontdekt met de naam “Clinton”. Als de computer is geïnfecteerd, zal deze regelmatig het bericht ‘geen geheugen meer’ tonen, zelfs als de computer voldoendeRAM heeft. |
| V: “Als Vernon Jordon ons heeft verteld dat u een buitengewoon geheugen heeft, een van de beste geheugens die hij ooit bij een politicus heeft gezien, zou u dit dan willen betwisten?”
A: “Ik heb inderdaad een goed geheugen…Maar ik kan me niet herinneren of ik alleen was met Monica Lewinsky of niet. Hoe kon ik zoveel vrouwen in mijn leven bijhouden?” Q: Waarom heeft Clinton Lewinsky aanbevolen voor een baan bij Revlon? A: Hij wist dat ze goed zou zijn in het verzinnen van dingen. |
 |
Het is belangrijk op te merken dat de betrouwbaarheid van ons geheugen soms afhangt van de wenselijkheid van het resultaat. Wanneer een medisch onderzoeker bijvoorbeeld relevante gegevens probeert te verzamelen van moeders wier baby’s gezond zijn en moeders wier kinderen misvormd zijn, zijn de gegevens van de laatste meestal nauwkeuriger dan die van de eerste. Dit komt omdat moeders van misvormde baby’s zorgvuldig alle ziektes die zich tijdens de zwangerschap hebben voorgedaan, alle medicijnen die zij hebben genomen en alle details die direct of indirect verband houden met de tragedie, hebben doorgenomen in een poging een verklaring te vinden. Integendeel, moeders van gezonde zuigelingen besteden niet veel aandacht aan de voorgaande informatie (Aschengrau & SeageIII, 2008). Het opblazen van de GPA is een ander voorbeeld van hoe onwenselijkheid de nauwkeurigheid van het geheugen en de gegevensintegriteit beïnvloedt. In sommige situaties is er een genderverschil in het opblazen van GPA. Een studie uitgevoerd door Caskie etal. (2014) vond dat binnen de groep van lagere GPA undergraduatestudents, vrouwen meer kans hadden om een hoger dan werkelijke GPA te rapporteren dan mannen.
Om het probleem van geheugenfouten tegen te gaan, stelden sommige onderzoekers voor om gegevens te verzamelen met betrekking tot de kortstondige gedachte of het gevoel van de deelnemer, in plaats van hem of haar te vragen zich gebeurtenissen uit het verleden te herinneren (Csikszentmihalyi & Larson, 1987; Finnigan & Vazire,2018). De volgende voorbeelden zijn enquête-items in 2018 Programme forInternational Student Assessment: “Werd u gisteren de hele dag met respect behandeld?” “Heb je gisteren veel gelachen of gelachen?” “Heb je gisteren iets interessants geleerd of gedaan?” (Organisatie voor Economische Samenwerking en Ontwikkeling, 2017). Het antwoord hangt echter af van wat er met de deelnemer gebeurde rond dat specifieke moment, wat misschien niet typisch is. Ook al heeft de respondent gisteren niet veel gelachen of gelachen, dan hoeft dat nog niet te betekenen dat de respondent altijd ongelukkig is.
Wat zullen we doen?
Sommige onderzoekers wijzen het gebruik van zelfgerapporteerde gegevens af vanwege de vermeende slechte kwaliteit ervan. Toen een groep onderzoekers bijvoorbeeld onderzocht of een hoge mate van religiositeit leidde tot minder naleving van richtlijnen voor schuilplaatsen in de VS tijdens de COVID19-pandemie, gebruikten zij het aantal gemeenten per 10.000 inwoners als een proxy-maatstaf voor de religiositeit van de regio, in plaats van zelfgerapporteerde religiositeit, die de neiging heeft sociale wenselijkheid te weerspiegelen (DeFranza, Lindow, Harrison, Mishra, &Mishra, 2020).
Op het gebied van de epidemiologie beweerden Khoury, James en Erickson (1994) dat het effect van recall bias wordt overschat. Maar hun conclusie is wellicht niet goed toepasbaar op andere gebieden, zoals onderwijs en psychologie.Ondanks de dreiging van onnauwkeurigheid van de gegevens, is het voor de onderzoeker onmogelijk om elke proefpersoon met een camcorder te volgen en alles op te nemen wat hij doet. Niettemin kan de onderzoeker een deel van de proefpersonen gebruiken om geobserveerde gegevens te verkrijgen, zoals de toegang tot het gebruikerslogboek of het dagelijkse logboek van webtoegang. De resultaten zouden dan worden vergeleken met de uitkomsten van alle door de proefpersonen zelf gerapporteerde gegevens voor een schatting van de meetfout.Bijvoorbeeld,
- Wanneer de onderzoeker de beschikking heeft over het logboek van de gebruikerstoegang, kan hij de proefpersonen vragen de frequentie van hun toegang tot de webserver te rapporteren.De proefpersonen mag niet worden meegedeeld dat hun Internetactiviteiten door de webmaster zijn gelogd, aangezien dit het gedrag van de deelnemers kan beïnvloeden.
- De onderzoeker kan een deel van de gebruikers vragen een logboek bij te houden van hun internetactiviteiten gedurende een maand. Daarna wordt dezelfde gebruikers gevraagd een enquête in te vullen over hun webgebruik.
Sommigen kunnen aanvoeren dat de logboekbenadering te veeleisend is. In veel wetenschappelijk onderzoek wordt de proefpersonen inderdaad om veel meer gevraagd dan dat. Bijvoorbeeld, toen wetenschappers bestudeerden hoe diepe slaap tijdens lange ruimtereizen de menselijke gezondheid zou beïnvloeden, werd de deelnemers gevraagd een maand in bed te liggen. In een onderzoek naar de invloed van een gesloten omgeving op de menselijke psychologie tijdens ruimtereizen, werden de proefpersonen ook een maand lang individueel in een kamer opgesloten. Nadat verschillende gegevensbronnen zijn verzameld, kan de discrepantie tussen het logboek en de zelfgerapporteerde gegevens worden geanalyseerd om de betrouwbaarheid van de gegevens in te schatten. Op het eerste gezicht lijkt deze benadering op een test-retestbetrouwbaarheid, maar dat is zij niet. Ten eerste moet bij test-hertestbetrouwbaarheid het instrument dat in twee of meer situaties wordt gebruikt hetzelfde zijn. Ten tweede, wanneer de test-hertestbetrouwbaarheid laag is, ligt de bron van de fouten binnen het instrument. Wanneer de bron van fouten echter buiten het instrument ligt, zoals menselijke fouten, is inter-beoordelaarsbetrouwbaarheid geschikter.
De hierboven voorgestelde procedure kan worden geconceptualiseerd als een meting van de inter-beoordelaarsbetrouwbaarheid, die lijkt op die van inter-beoordelaarsbetrouwbaarheid en herhaalde metingen. Er zijn vier manieren om de interbeoordelaarsbetrouwbaarheid te schatten, namelijk de Kappa coëfficiënt, de Index of Inconsistency, de herhaalde meting ANOVA en regressieanalyse. In het volgende hoofdstuk wordt beschreven hoe deze metingen van de inter-beoordelaarsbetrouwbaarheid kunnen worden gebruikt als metingen van de inter-data betrouwbaarheid.
Kappa coëfficiënt
In psychologisch en onderwijsonderzoek is het niet ongebruikelijk om twee of meer beoordelaars in te zetten bij het thema-onderzoek wanneer de beoordeling subjectieve oordelen inhoudt (b.v. het beoordelen van essays). De interbeoordelaarsbetrouwbaarheid, die wordt gemeten met de Kappa coëfficiënt, wordt gebruikt om de betrouwbaarheid van de gegevens aan te geven. Bijvoorbeeld, de prestaties van de deelnemers worden door twee of meer beoordelaars beoordeeld als “master” of “non-master” (1 of 0). Daarom wordt deze meting meestal berekend in categorische data-analyseprocedures zoals PROC FREQ in SAS, “measurement of agreement” in SPSS, of eenonline Kappa-calculator (Lowry, 2016). De afbeelding hieronder is een screenshot van de online calculator van Vassarstats.
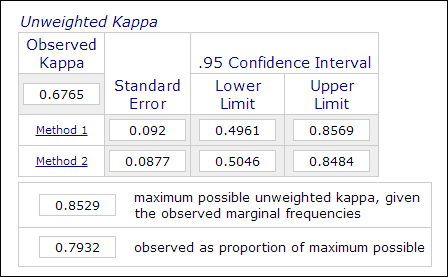
Het is belangrijk om op te merken dat zelfs als 60 procent van twee datasets met elkaar overeenkomt, dit niet betekent dat de metingen betrouwbaar zijn.Aangezien de uitkomst dichotomisch is, is er een kans van 50 procent dat de twee metingen met elkaar overeenkomen. De Kappa coëfficiënt houdt hier rekening mee en vereist een hogere mate van overeenstemming om consistentie te bereiken.
In de context van Web-gebaseerde instructie, kan elke categorie van zelf-gerapporteerd Website gebruik worden gehercodeerd als een binaire variabele. Bijvoorbeeld, wanneer vraag één luidt: “Hoe vaak gebruikt u telnet?”, zijn de mogelijke categorische antwoorden: “a: dagelijks,” “b: drie tot vijf keer per weel,” “c: drie tot vijf keer per maand,” “d: zelden,” en “e: nooit.” In dit geval kunnen de vijf categorieën worden gehercodeerd in vijf variabelen: Q1A, Q1B, Q1C, Q1D, en Q1E. Dan kunnen al deze binaire variabelen worden samengevoegd tot een R X 2 tabel zoals in de volgende tabel. Met deze gegevensstructuur kunnen antwoorden worden gecodeerd als “1” of “0” en is het dus mogelijk de overeenstemming van de classificatie te meten. De overeenstemming kan worden berekend met behulp van de Kappa coëfficiënt en daarmee kan de betrouwbaarheid van de gegevens worden geschat.
Onderwerpen Logboekgegevens Zelfrapportgegevens Subject 1 1 Subject 2 0 0 Subject 3 1 0 Subject 4 0 1 Index of Inconsistency
Een andere manier om de bovengenoemde categorische gegevens te berekenen is Index ofInconsistency (IOI). Omdat er in bovenstaand voorbeeld sprake is van twee metingen (log en zelf-gerapporteerde gegevens) en vijf opties in het antwoord, wordt een 4 X 4 tabel gevormd. De eerste stap om IOI te berekenen is de RXC-tabel te verdelen in verschillende 2X2 subtabellen. Bijvoorbeeld, de laatste optie “nooit” wordt behandeld als één categorie en alle andere opties worden samengevoegd in een andere categorie als “niet nooit”, zoals weergegeven in de volgende tabel.
Zelfgerapporteerde gegevens Log Nooit Niet nooit Totaal Nooit a b a+b Niet Nooit c d c+d Totaal a+c b+d n=Sum(a-d) Het percentage IOI wordt berekend met de volgende formule:
IOI% = 100*(b+c)/waar p = (a+c)/n
Nadat de IOI voor elke 2X2-subtabel is berekend, wordt een gemiddelde van alle indices gebruikt als indicator voor de inconsistentie van de maatregel. Het criterium om te beoordelen of de gegevens consistent zijn, is als volgt:
- Een IOI van minder dan 20 is geringe variantie
- Een IOI tussen 20 en 50 is matige variantie
- Een IOI boven 50 is grote variantie
De betrouwbaarheid van de gegevens wordt uitgedrukt in deze vergelijking: r = 1 – IOI
Intraclass correlatiecoëfficiënt
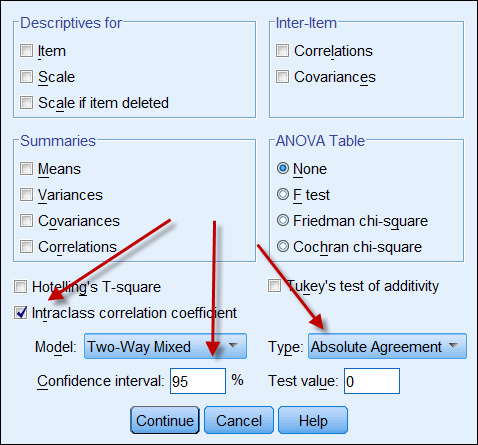
Als beide gegevensbronnen continue gegevens opleveren, kan men de intraclass correlatiecoëfficiënt berekenen om de betrouwbaarheid van de gegevens aan te geven. Hieronder volgt een screenshot van de ICC-opties van SPSS. In Typethere zijn er twee opties: “consistentie” en “absolute overeenstemming”. Als “consistentie” wordt gekozen, dan is het zo dat zelfs als de ene reeks getallen een hoge consistentie heeft (bv. 9, 8, 9, 8, 7…) en de andere een lage consistentie (bv. 4,3, 4, 3, 2…), hun sterke correlatie verkeerdelijk suggereert dat de gegevens met elkaar in overeenstemming zijn. Daarom verdient het aanbeveling te kiezen voor “absolute overeenstemming”.
Herhaalde metingen
De meting van de inter-data betrouwbaarheid kan ook worden geconceptualiseerd en geprocedeerd als een herhaalde maatregelenANOVA. Bij een ANOVA met herhaalde metingen worden de metingen bij dezelfde proefpersonen herhaaldelijk uitgevoerd, bijvoorbeeld in de vorm van een pretest, midterm en posttest. In deze context worden de proefpersonen ook herhaaldelijk gemeten via het logboek van de webgebruiker, het logboek en de zelfgerapporteerde enquête. Hieronder volgt de SAS-code voor een ANOVA met herhaalde metingen:
data one; input user $ web_log log_book self_report;
cards;
1 215 260 200
2 178 200 150
3 100 111 120
4 135 172 100
5 139 150 140
6 198 200 230
7 135 150 180
8 120 110 100
9 289 276 300
proc glm;
classes user;
model web_log log_book self_report = user;
repeated time 3;
run;
In het bovenstaande programma wordt het aantal bezochte websites door negen vrijwilligers vastgelegd in het logboek van de gebruikerstoegang, het persoonlijke logboek en de zelfgerapporteerde enquête. De gebruikers worden behandeld als een tussen-subject factor, terwijl de drie maatregelen worden beschouwd als tussen-maat factor. Hieronder volgt een beknopte weergave:
Variatiebron DF Mean Square Tussen-subject (gebruiker) 8 10442.50 Tussen-maat (tijd) 2 488,93 Residual 16 454.80 Op basis van bovenstaande gegevens kan de betrouwbaarheidscoëfficiënt worden berekend met deze formule (Fisher, 1946; Horst, 1949):
r = MS-tussenmaat – MSresidual ————————————————————– MSbetween-measure + (dfbetween-people X MSresidual) Laten we het getal in de formule stoppen:
r = 488.93 – 454,80 ————————————— 488,93 + ( 8 X 454,80) De betrouwbaarheid is ongeveer .0008, wat extreem laag is. Daarom kunnen we naar huis gaan en de gegevens vergeten. Gelukkig gaat het slechts om een hypothetische gegevensverzameling. Maar wat als het een echte dataset is? Je moet hard genoeg zijn om slechte gegevens op te geven in plaats van resultaten te publiceren die totaal onbetrouwbaar zijn.
Correlatie- en regressieanalyse
Correlatieanalyse, die gebruik maakt van Pearsons Product Momentcoëfficiënt, is heel eenvoudig en vooral nuttig wanneer de schalen van twee metingen niet dezelfde zijn. Het logboek van de webserver kan bijvoorbeeld het aantal bezochte pagina’s bijhouden, terwijl de zelfgerapporteerde gegevens een Likert-schaal hebben (b.v. Hoe vaak surft u op het Internet? 5=zeer vaak,4=vaak, 3=soms, 2=zelden, 5=nooit). In dit geval kunnen de zelfgerapporteerde scores worden gebruikt als voorspeller voor regressie tegen paginatoegang.
Een soortgelijke aanpak is regressieanalyse, waarbij een reeks scores (b.v. enquêtegegevens) als voorspeller wordt behandeld, terwijl een andere reeks scores (b.v. dagelijks logboek van de gebruiker) als afhankelijke variabele wordt beschouwd. Indien er meer dan twee metingen worden gebruikt, kan een meervoudig regressiemodel worden toegepast, d.w.z. dat de meting die de beste resultaten oplevert (b.v. logboek van de internetgebruiker) als de afhankelijke variabele wordt beschouwd en alle andere metingen (b.v. logboek van de gebruiker per dag, enquêtegegevens) als onafhankelijke variabelen worden behandeld.
Reference
- Aschengrau, A., & Seage III, G. (2008). Essentials of epidemiology in public health. Boston, MA: Jones and Bartlett Publishers.
- Blalock, H. M. (1974). (Ed.) Meting in de sociale wetenschappen: Theories and strategies. Chicago, Illinois: Aldine Publishing Company.
- Caskie, G. I. L., Sutton, M. C., & Eckhardt, A. G.(2014). Nauwkeurigheid van zelf-gerapporteerde college GPA: Gender-moderateddifferences by achievement level and academic self-efficacy. Journal of College Student Development, 55, 385-390. 10.1353/csd.2014.0038
- Chan, D. (2009). Waarom vraag je het mij dan? Zijn zelfrapportagegegevens echt zo slecht? In Charles E. Lance en Robert J. Vandenberg (Eds.), Statistical and methodological myths and urban legends: Doctrine, waarheid en fabel in de organisatie- en sociale wetenschappen (pp309-335). New York, NY: Routledge.
- Cook, T. D., & Campbell, D. T. (1979). Quasi-experimentatie: Design and analysis issues. Boston, MA: Houghton Mifflin Company.
- Csikszentmihalyi, M., & Larson, R. (1987). Validity and reliability of the experience-sampling method. Journal of Nervous and Mental Disease, 175, 526-536. https://doi.org/10.1097/00005053-198709000-00004
- Deese, J. (1972). Psychologie als wetenschap en kunst. New York, NY: Harcourt Brace Jovanovich, Inc.
- DeFranza, D., Lindow, M., Harrison, K., Mishra, A., &Mishra, H. (2020, 10 augustus). Religion and reactance to COVID-19mitigation guidelines. American Psychologist. Advance online publicatie. http://dx.doi.org/10.1037/amp0000717.
- Fetters, W., Stowe, P., & Owings, J. (1984). De middelbare school en daarna. A national longitudinal study for the 1980s, quality of responses of high school students to questionnaire items. (NCES 84-216). Washington, D. C.: U.S. Department of Education. Office of EducationalResearch and Improvement. National center for Education Statistics.
- Finnigan, K. M., & Vazire, S. (2018). The incrementalvalidity of average state self-reports over global self-reports ofpersonality. Journal of Personality and Social Psychology, 115, 321-337. https://doi.org/10.1037/pspp0000136
- Fisher, R. J. (1946). Statistical methods for research workers (10e ed.). Edinburgh, UK: Oliver and Boyd.
- Hadaway, C. K., & Marlar, P. L. (2005). Hoeveel Amerikanen gaan elke week naar de eredienst? Een alternatieve benadering van meting? Tijdschrift voor de Wetenschappelijke Studie van Religie, 44, 307-322. DOI: 10.1111/j.1468-5906.2005.00288.x
- Hart, W.; & Tomazic, T. (1999 augustus). Comparison ofpercentile distributions for anthropometric measures between three datasets. Paper gepresenteerd op de Annual Joint Statistical Meeting, Baltimore, MD.
- Horst, P. (1949). Een veralgemeende uitdrukking voor de betrouwbaarheid van maten. Psychometrika, 14, 21-31.
- Khoury, M., James, L., & Erikson, J. (1994). On the use of affected controls to address recall bias in case-control studiesof birth defects. Teratology, 49, 273-281.
- Loftus, E. (2016, april). De fictie van het geheugen. Paper gepresenteerd op de Western Psychological Association Convention. Long Beach, CA.
- Lowry, R. (2016). Kappa als maat voor concordantie bij categorisch sorteren. Retrieved from http://vassarstats.net/kappa.html
- Organisatie voor Economische Samenwerking en Ontwikkeling. (2017). Welzijnsvragenlijst voor PISA 2018. Parijs: Auteur. Retrieved from https://www.oecd.org/pisa/data/2018database/CY7_201710_QST_MS_WBQ_NoNotes_final.pdf
- Schacter, D. L. (1999). De zeven zonden van het geheugen: Inzichten uit de psychologie en de cognitieve neurowetenschappen. Amerikaanse psychologie, 54, 182-203.
- Salvucci, S.; Walter, E., Conley, V; Fink, S; & Saba, M. (1997). Onderzoek naar meetfouten bij het National Center for Education Statistics. Washington D. C.: U. S. Department of Education.
- Stephens-Davidowitz, S. (2017). Iedereen liegt: Big data, nieuwe data, en wat het internet ons kan vertellen over wie we werkelijk zijn. New York, NY: Dey Street Books.
 Ga naar het hoofdmenu
Ga naar het hoofdmenu Andere cursussenZoekmachine
|

Contacteer mij
|