- De functie en haar afgeleide zijn beide monotoon
- Output is nul “centric”
- Optimalisatie is eenvoudiger
- Derivaat /Differentiaal van de Tanh functie (f'(x)) zal tussen 0 en 1 liggen.
Cons:
- Afgeleide van Tanh-functie lijdt aan “Vanishing gradient and Exploding gradient problem”.
- Lage convergentie-als zijn computationeel zwaar.(Reden gebruik exponentiële wiskundige functie)
“Tanh heeft de voorkeur boven de sigmoïde functie, omdat het nul gecentreerd is en de gradiënten niet beperkt zijn om in een bepaalde richting te bewegen”
3. ReLu-activeringsfunctie (ReLu – Rectified Linear Units):


ReLU is de niet-lineaire activeringsfunctie die in AI aan populariteit heeft gewonnen. ReLu-functie wordt ook weergegeven als f(x) = max(0,x).
- De functie en de afgeleide ervan zijn beide monotoon.
- Hoofdvoordeel van het gebruik van de ReLU-functie-het activeert niet alle neuronen tegelijk.
- Computationeel efficiënt
- Derivaat /Differentiaal van de Tanh functie (f'(x)) zal 1 zijn als f(x) > 0 anders 0.
- Convergeert zeer snel
Cons:
- ReLu functie in niet “zero-centric”.Dit maakt de gradiënt updates gaan te ver in verschillende richtingen. 0 < output < 1, en het maakt optimalisatie moeilijker.
- Dood neuron is het grootste probleem.Dit is te wijten aan Niet-verschilbaar op nul.
“Probleem van sterven neuron/Dood neuron : Als de ReLu afgeleide f'(x) is niet 0 voor de positieve waarden van de neuron (f'(x)=1 voor x ≥ 0), ReLu niet verzadigen (exploid) en geen dode neuronen (Vanishing neuron)worden gerapporteerd. Verzadiging en verdwijnende gradiënt treden alleen op voor negatieve waarden die, gegeven aan ReLu, worden omgezet in 0- Dit wordt het probleem van het stervende neuron genoemd.”
4. lekkende ReLu-activeringsfunctie:
Leaky ReLU-functie is niets anders dan een verbeterde versie van de ReLU-functie met introductie van “constante helling”


- Leaky ReLU is gedefinieerd om het probleem van stervende neuronen/dode neuronen aan te pakken.
- Het probleem van stervende neuronen/dode neuronen wordt aangepakt door een kleine helling in te voeren met negatieve waarden die met α worden geschaald, zodat de overeenkomstige neuronen “in leven kunnen blijven”.
- De functie en de afgeleide ervan zijn beide monotoon
- Het staat negatieve waarden toe tijdens de terugvoortplanting
- Het is efficiënt en gemakkelijk te berekenen.
- Derivaat van Leaky is 1 wanneer f(x) > 0 en ligt tussen 0 en 1 wanneer f(x) < 0.
Cons:
- Leaky ReLU geeft geen consistente voorspellingen voor negatieve invoerwaarden.
5. ELU (Exponentiële Lineaire Eenheden) activeringsfunctie:

- ELU wordt ook voorgesteld om het probleem van stervende neuronen op te lossen.
- Geen problemen met dode ReLU
- Zero-centrisch
Cons:
- Computationeel intensief.
- Zoals Leaky ReLU, hoewel theoretisch beter dan ReLU, is er momenteel in de praktijk geen goed bewijs dat ELU altijd beter is dan ReLU.
- f(x) is alleen monotoon als alpha groter is dan of gelijk aan 0.
- f'(x) afgeleide van ELU is alleen monotoon als alpha tussen 0 en 1 ligt.
- Lage convergentie als gevolg van exponentiële functie.
6. P ReLu (Parametrische ReLU) Activeringsfunctie:

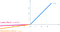
- Het idee van leaky ReLU kan nog verder worden uitgebreid.
- In plaats van x te vermenigvuldigen met een constante term kunnen we deze vermenigvuldigen met een “hyperparameter (a-trainbare parameter)”, wat beter lijkt te werken dan leaky ReLU. Deze uitbreiding op lekke ReLU staat bekend als Parametrische ReLU.
- De parameter α is meestal een getal tussen 0 en 1, en het is over het algemeen relatief klein.
- Hebben een klein voordeel ten opzichte van Leaky Relu als gevolg van trainbare parameter.
- Handelen het probleem van stervende neuron.
Cons:
- Zelfde als lek Relu.
- f(x) is monotoon als a> of =0 en f'(x) is monotoon als a =1
7. Swish (A Self-Gated) Activation Function:(Sigmoid Linear Unit)

- Google Brain Team heeft een nieuwe activatiefunctie voorgesteld, Swish genaamd, die eenvoudigweg f(x) = x – sigmoid(x) is.
- Uit hun experimenten blijkt dat Swish de neiging heeft om beter te werken dan ReLU op diepere modellen over een aantal uitdagende datasets.
- De curve van de Swish-functie is glad en de functie is differentieerbaar op alle punten. Dit is nuttig tijdens het modeloptimalisatieproces en wordt beschouwd als een van de redenen dat Swish beter presteert dan ReLU.
- De Swish-functie is “niet monotoon”. Dit betekent dat de waarde van de functie kan afnemen, zelfs wanneer de invoerwaarden toenemen.
- Functie is boven niet begrensd en beneden begrensd.
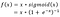
“Swish heeft de neiging de ReLu voortdurend te evenaren of te overtreffen”
Merk op dat de output van de swish-functie kan dalen, zelfs wanneer de input toeneemt. Dit is een interessante en swish-specifieke eigenschap.(Vanwege het niet-monotone karakter)
f(x)=2x*sigmoid(beta*x)
Als we ervan uitgaan dat beta=0 een eenvoudige versie van Swish is, die een leerbare parameter is, dan is het sigmoid-deel altijd 1/2 en f (x) lineair. Anderzijds, indien de beta een zeer grote waarde is, wordt de sigmoide een bijna dubbelcijferige functie (0 voor x<0,1 voor x>0). Aldus convergeert f (x) naar de ReLU-functie. Daarom wordt de standaard Swish-functie gekozen als beta = 1. Op deze manier wordt een zachte interpolatie (waarbij de variabele waardeverzamelingen worden geassocieerd met een functie in het gegeven bereik en de gewenste precisie) verkregen. Uitstekend! Er is een oplossing gevonden voor het probleem van de ijdelheid van de gradiënten.
8.Softplus
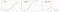
De softplusfunctie lijkt op de ReLU-functie, maar is relatief gladder.Functie van Softplus of SmoothRelu f(x) = ln(1+exp x).
Afgeleide van de Softplus-functie is f'(x) is logistische functie (1/(1+exp x)).
Functiewaarde varieert van (0, + inf).Zowel f(x) als f'(x) zijn monotoon.
9.Softmax of genormaliseerde exponentiële functie:

De “softmax”-functie is ook een soort sigmoidfunctie, maar is zeer nuttig om classificatieproblemen met meerdere klassen te behandelen.
“Softmax kan worden beschreven als de combinatie van meerdere sigmoidal-functies.”
“Softmax-functie geeft de waarschijnlijkheid terug dat een datapunt tot elke afzonderlijke klasse behoort.”
Bij het bouwen van een netwerk voor een meerklassenprobleem zou de uitvoerlaag evenveel neuronen hebben als het aantal klassen in het doel.
Als u bijvoorbeeld drie klassen hebt, zouden er drie neuronen in de uitvoerlaag zijn. Stel dat de output van de neuronen .de softmax-functie op deze waarden toepast, dan krijgt u het volgende resultaat – . Deze waarden geven de waarschijnlijkheid weer dat een gegevenspunt tot een bepaalde klasse behoort. Uit het resultaat kunnen we afleiden dat de input tot klasse A behoort.
“Merk op dat de som van alle waarden 1 is.”
Welke is beter om te gebruiken? Hoe kies je de juiste?
Om eerlijk te zijn is er geen harde en snelle regel om de activeringsfunctie te kiezen.We kunnen geen onderscheid maken tussen activeringsfuncties.Elke activeringsfunctie heeft zijn eigen voors en tegens.Alle goede en slechte zullen worden beslist op basis van het spoor.
Maar op basis van de eigenschappen van het probleem kunnen we misschien een betere keuze maken voor een gemakkelijke en snellere convergentie van het netwerk.
- Sigmoïdfuncties en hun combinaties werken over het algemeen beter bij classificatieproblemen
- Sigmoïden en tanh-functies worden soms vermeden vanwege het verdwijnende gradiëntprobleem
- ReLU-activeringsfunctie wordt veel gebruikt in de moderne tijd.
- In het geval van dode neuronen in onze netwerken als gevolg van ReLu dan is lekkende ReLU functie de beste keuze
- ReLU functie mag alleen worden gebruikt in de verborgen lagen
“Als vuistregel kan men beginnen met het gebruik van ReLU functie en dan overgaan op andere activeringsfuncties in het geval ReLU niet met optimale resultaten”