Update 29-May-2018: Ennek a cikknek három célja van: (1) Megmutatni, hogy mindig szükségünk lesz adatmodellre (akár ember, akár gép készíti) (2) Megmutatni, hogy a fizikai modellezés nem azonos a logikai modellezéssel. Valójában nagyon is különbözik, és a mögöttes technológiától függ. Mindkettőre szükségünk van azonban. Ezt a pontot a Hadoop segítségével illusztráltam a fizikai rétegen (3) Megmutattam, hogy a megváltoztathatatlanság fogalma milyen hatással van az adatmodellezésre.
- A dimenzionális modellezés halott?
- Miért van szükségünk adataink modellezésére?
- Miért van szükségünk dimenziós modellekre?
- Adatmodellezés vs. dimenziós modellezés
- Miért állítják tehát egyesek, hogy a dimenziós modellezés halott?
- Az adattárház halott Zűrzavar
- A Schema on Read félreértés
- A denormalizáció újragondolva. A modell fizikai aspektusai.
- A de-normalizálást a végsőkig vinni
- Adatelosztás elosztott relációs adatbázisban (MPP)
- Adatelosztás a Hadoopban
- Dimenziós modellek a Hadoopon
- Hadoop és a lassan változó dimenziók
- Tárolás fejlődése a Hadoopban
- Az ítélet. A dimenziós modellek és a csillagsémák elavultak?
- Kiegészítő olvasmány a dimenziós modellezésről a Big Data korszakában
A dimenzionális modellezés halott?
Mielőtt választ adnék erre a kérdésre, lépjünk egyet hátra, és először nézzük meg, mit értünk dimenzionális adatmodellezés alatt.
Miért van szükségünk adataink modellezésére?
Egy gyakori félreértéssel ellentétben az adatmodelleknek nem az az egyetlen célja, hogy ER-diagrammként szolgáljanak a fizikai adatbázis tervezéséhez. Az adatmodellek egy vállalat üzleti folyamatainak komplexitását reprezentálják. Dokumentálják a fontos üzleti szabályokat és fogalmakat, és segítenek a kulcsfontosságú vállalati terminológia szabványosításában. Világosságot teremtenek, és segítenek feltárni az üzleti folyamatokkal kapcsolatos homályos gondolkodást és kétértelműségeket. Ezenkívül az adatmodellek segítségével kommunikálhat más érdekelt felekkel. Tervrajz nélkül nem építene házat vagy hidat. Miért építene tehát egy adatalkalmazást, például egy adattárházat terv nélkül?
Miért van szükségünk dimenziós modellekre?
A dimenziós modellezés az adatok modellezésének egy speciális megközelítése. A dimenzionális modell szinonimájaként használjuk az adattároló vagy a csillagséma szavakat is. A csillagsémák adatelemzésre optimalizáltak. Nézze meg az alábbi dimenzionális modellt. Ez elég intuitívan érthető. Rögtön látjuk, hogyan szeletelhetjük fel a rendelési adatainkat ügyfél, termék vagy dátum szerint, és mérhetjük a Megrendelések üzleti folyamat teljesítményét a mérőszámok aggregálásával és összehasonlításával.
A dimenzionális modellezés egyik alapgondolata a tranzakciós üzleti folyamat legalacsonyabb granularitási szintjének meghatározása. Amikor felszeleteljük és feldaraboljuk az adatokat, és fúrjuk őket, ez az a levélszint, ahonnan nem tudunk lejjebb fúrni. Másképpen fogalmazva, a legalacsonyabb granularitási szint egy csillagsémában a tény és az összes dimenziótábla összekapcsolása, mindenféle aggregáció nélkül.
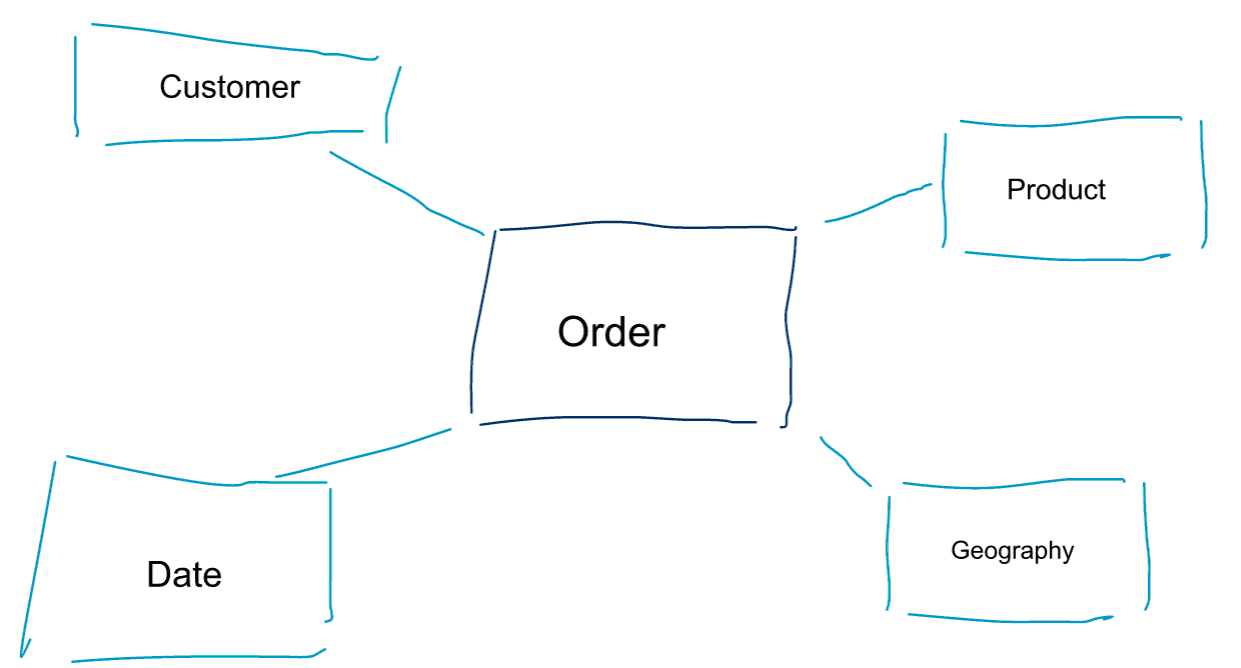
Adatmodellezés vs. dimenziós modellezés
A szabványos adatmodellezésben az adatismétlések és a redundancia kiküszöbölésére törekszünk. Ha változás történik az adatokban, csak egy helyen kell megváltoztatnunk azokat. Ez az adatminőséget is segíti. Az értékek nem kerülnek szinkronba több helyen. Nézze meg az alábbi modellt. Különböző táblákat tartalmaz, amelyek földrajzi fogalmakat képviselnek. A normalizált modellben minden entitáshoz külön táblázat tartozik. A dimenzionális modellben csak egy táblánk van: földrajz. Ebben a táblázatban a városok többször megismétlődnek. Minden városhoz egyszer. Ha az ország neve megváltozik, több helyen is frissítenünk kell az országot
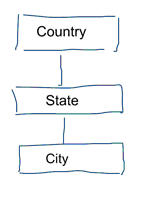
Megjegyzés: A szabványos adatmodellezést 3NF modellezésnek is nevezik.
Az adatmodellezés szabványos megközelítése nem felel meg az üzleti intelligencia munkaterheléseinek. A sok táblázat sok egyesítést eredményez. Az illesztések lelassítják a dolgokat. Az adatelemzésben lehetőség szerint kerüljük őket. A dimenziós modellekben több összefüggő táblát egyetlen táblává de-normalizálunk, például az előző példánkban szereplő különböző táblákat előzetesen egyetlen táblává lehet összekapcsolni: földrajz.
Miért állítják tehát egyesek, hogy a dimenziós modellezés halott?
Azt hiszem, egyetértünk abban, hogy az adatmodellezés általában és különösen a dimenziós modellezés meglehetősen hasznos feladat. Miért állítják tehát egyesek, hogy a dimenzionális modellezés nem hasznos a nagy adatok és a Hadoop korában?
Amint elképzelheti, ennek több oka is van.
Az adattárház halott Zűrzavar
Először is, egyesek összekeverik a dimenzionális modellezést az adattárházzal. Azt állítják, hogy az adattárházak halottak, és ennek következtében a dimenzionális modellezés is a történelem szemétdombjára kerülhet. Ez egy logikailag koherens érv. Az adattárház fogalma azonban korántsem elavult. Mindig is szükségünk van integrált és megbízható adatokra a BI műszerfalaink feltöltéséhez. Ha többet szeretne megtudni, ajánlom a Big Data for Data Warehouse Professionals című képzésünket. A tanfolyamon belemegyek a részletekbe, és elmagyarázom, hogy az adattárház ugyanolyan releváns, mint valaha. Azt is bemutatom, hogy a feltörekvő big data eszközök és technológiák hogyan hasznosak az adattárházak számára.

A Schema on Read félreértés
A második érv, amit gyakran hallok, így hangzik. ‘Mi a schema on read megközelítést követjük, és már nem kell modelleznünk az adatainkat’. Véleményem szerint a schema on read koncepció az egyik legnagyobb félreértés az adatelemzésben. Egyetértek azzal, hogy kezdetben hasznos a nyers adatokat egy olyan adatdömpingben tárolni, amely kevés sémát tartalmaz. Ezt az érvet azonban nem szabad kifogásként használni arra, hogy egyáltalán ne modellezzük az adatokat. A schema on read megközelítés csak a doboz és a felelősség lerúgása a downstream folyamatokra. Valakinek még mindig bele kell harapnia az adattípusok definiálásába. Minden egyes folyamatnak, amely hozzáfér a séma nélküli adatdömpinghez, magának kell kitalálnia, hogy mi történik. Ez a fajta munka összeadódik, teljesen felesleges, és könnyen elkerülhető az adattípusok és egy megfelelő séma meghatározásával.
A denormalizáció újragondolva. A modell fizikai aspektusai.
Valóban vannak érvényes érvek a dimenziós modellek elavultnak nyilvánítása mellett? Valóban vannak jobb érvek is, mint az általam felsorolt kettő. Ezekhez szükség van a fizikai adatmodellezés és a Hadoop működésének némi megértésére. Legyen türelemmel.
Korábban röviden megemlítettem az egyik okot, amiért az adatainkat dimenzionálisan modellezzük. Ez azzal kapcsolatban van, ahogyan az adatokat fizikailag tároljuk az adattárolónkban. A szabványos adatmodellezésben minden valós világbeli entitás saját táblázatot kap. Ezt azért tesszük, hogy elkerüljük az adatredundanciát és az adatminőségi problémák kockázatát az adatainkban. Minél több táblánk van, annál több joinra van szükségünk. Ez a hátránya. A táblaösszekötések drágák, különösen akkor, ha nagyszámú rekordot kapcsolunk össze az adathalmazainkból. Amikor az adatokat dimenzionálisan modellezzük, több táblát összevonunk egybe. Azt mondjuk, hogy előcsatlakoztatjuk vagy de-normalizáljuk az adatokat. Így már kevesebb táblánk van, kevesebb az egyesítés, és ennek eredményeképpen kisebb a késleltetés és jobb a lekérdezési teljesítményünk.”
Vegyen részt a bejegyzés megvitatásában a LinkedIn-en
A de-normalizálást a végsőkig vinni
Miért ne vinnénk a de-normalizálást a végsőkig? Megszabadulni az összes jointól, és csak egyetlen ténytábla legyen? Ezzel valóban megszűnne minden egyesítés szükségessége. Azonban, ahogy el tudod képzelni, ennek van néhány mellékhatása. Először is, növeli a szükséges tárhely mennyiségét. Mostantól rengeteg felesleges adatot kell tárolnunk. Az adatelemzéshez használt oszlopos tárolási formátumok megjelenésével ez manapság már kevésbé jelent gondot. A de-normalizálás nagyobb problémája az a tény, hogy minden egyes alkalommal, amikor az egyik attribútum értéke megváltozik, több helyen kell frissítenünk az értéket – esetleg több ezer vagy millió frissítéssel. Ezt a problémát úgy tudjuk megkerülni, hogy éjszakánként teljesen újratöltjük a modelljeinket. Ez gyakran sokkal gyorsabb és egyszerűbb, mint a nagyszámú frissítés alkalmazása. Az oszlopos adatbázisok jellemzően a következő megközelítést alkalmazzák. Az adatok frissítéseit először a memóriában tárolják, majd aszinkron módon írják ki a lemezre.
Adatelosztás elosztott relációs adatbázisban (MPP)
A Hadoopon, pl. Hive, SparkSQL stb. dimenzionális modellek létrehozásakor jobban meg kell értenünk a technológia egyik alapvető jellemzőjét, amely megkülönbözteti azt az elosztott relációs adatbázistól (MPP), például a Teradatától stb. Az adatoknak egy MPP csomópontjai közötti elosztásakor a rekordok elhelyezése felett rendelkezünk. A partícionálási stratégiánk alapján, pl. hash, lista, tartomány stb. alapján az egyes rekordok kulcsait ugyanazon csomóponton lévő lapok között együtt helyezhetjük el. Mivel az adatok ko-lokalitása garantált, az egyesítéseink szupergyorsak, mivel nem kell adatokat küldenünk a hálózaton keresztül. Nézze meg az alábbi példát. Az ORDER és ORDER_ITEM táblák azonos ORDER_ID azonosítóval rendelkező rekordjai ugyanarra a csomópontra kerülnek.
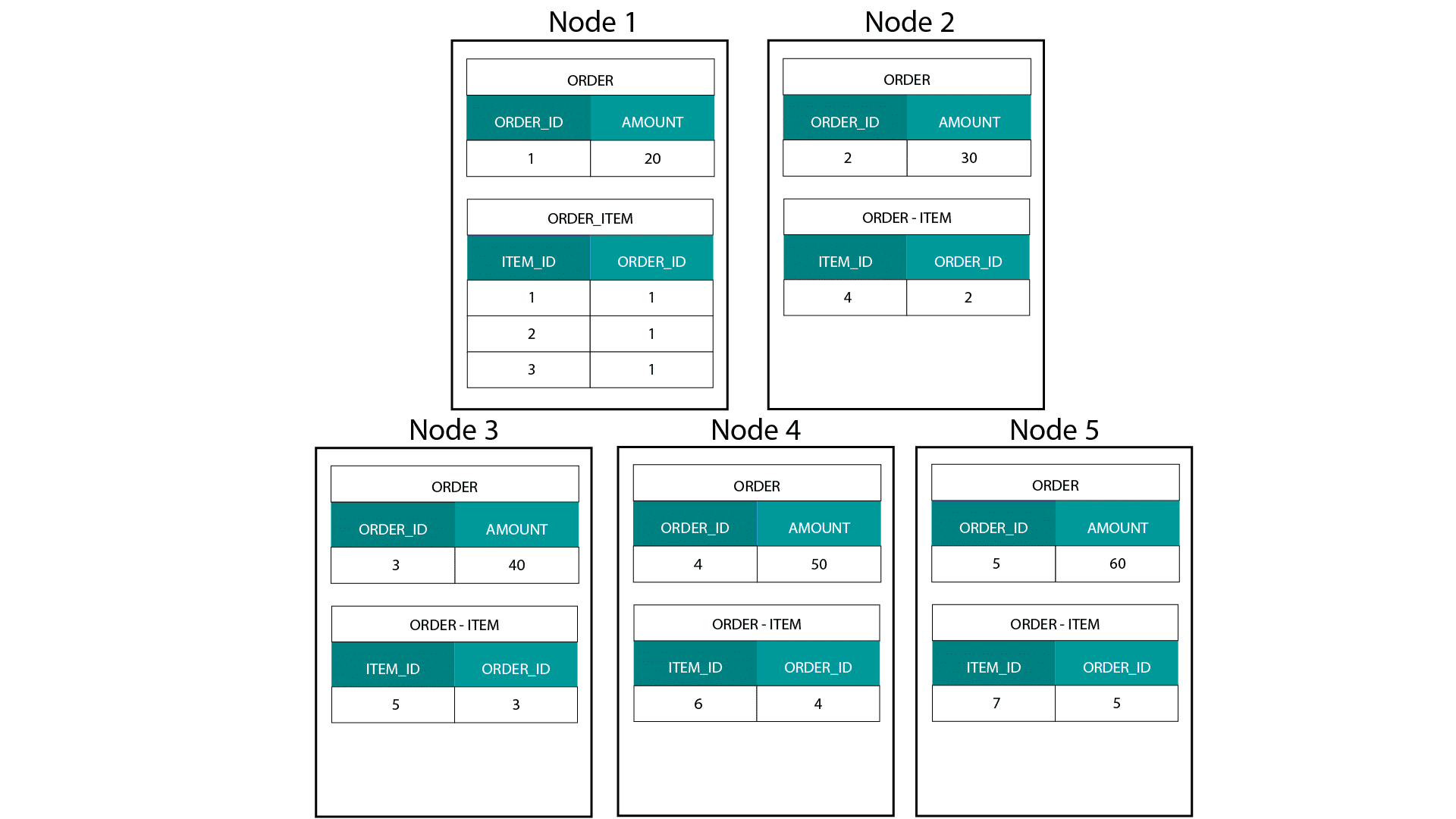
A order és order_item tábla order_id kulcsai ugyanazon csomópontokon vannak együtt elhelyezve.
Adatelosztás a Hadoopban
Ez nagyon különbözik a Hadoop alapú rendszerektől. Ott az adatainkat nagy méretű darabokra osztjuk, és a Hadoop elosztott fájlrendszerén (HDFS) elosztjuk és replikáljuk a csomópontjaink között. Ezzel az adatelosztási stratégiával nem tudjuk garantálni az adatok ko-lokalitását. Nézze meg az alábbi példát. Az ORDER_ID kulcshoz tartozó rekordok különböző csomópontokon kötnek ki.
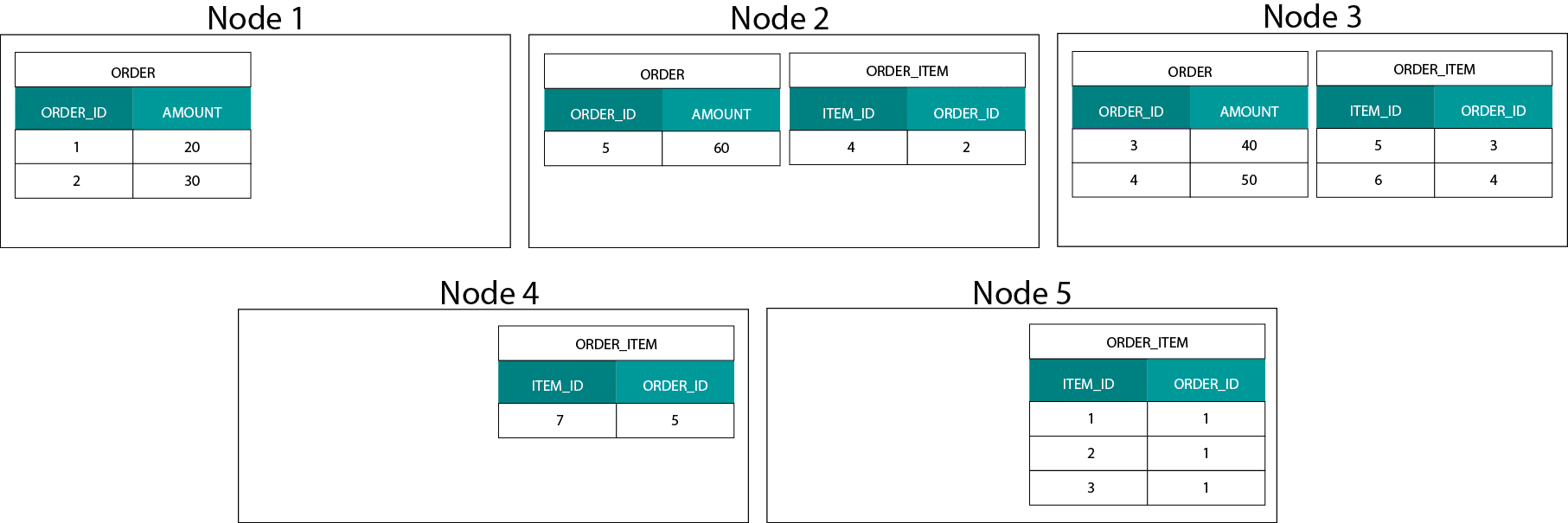
A joinhoz adatokat kell küldenünk a hálózaton keresztül, ami hatással van a teljesítményre.
A probléma kezelésének egyik stratégiája, hogy az egyik join táblát replikáljuk a fürt összes csomópontjára. Ezt broadcast joinnak nevezzük, és ugyanezt a stratégiát használjuk egy MPP-nél is. Mint elképzelhető, ez csak kis lookup- vagy dimenziótáblák esetében működik.
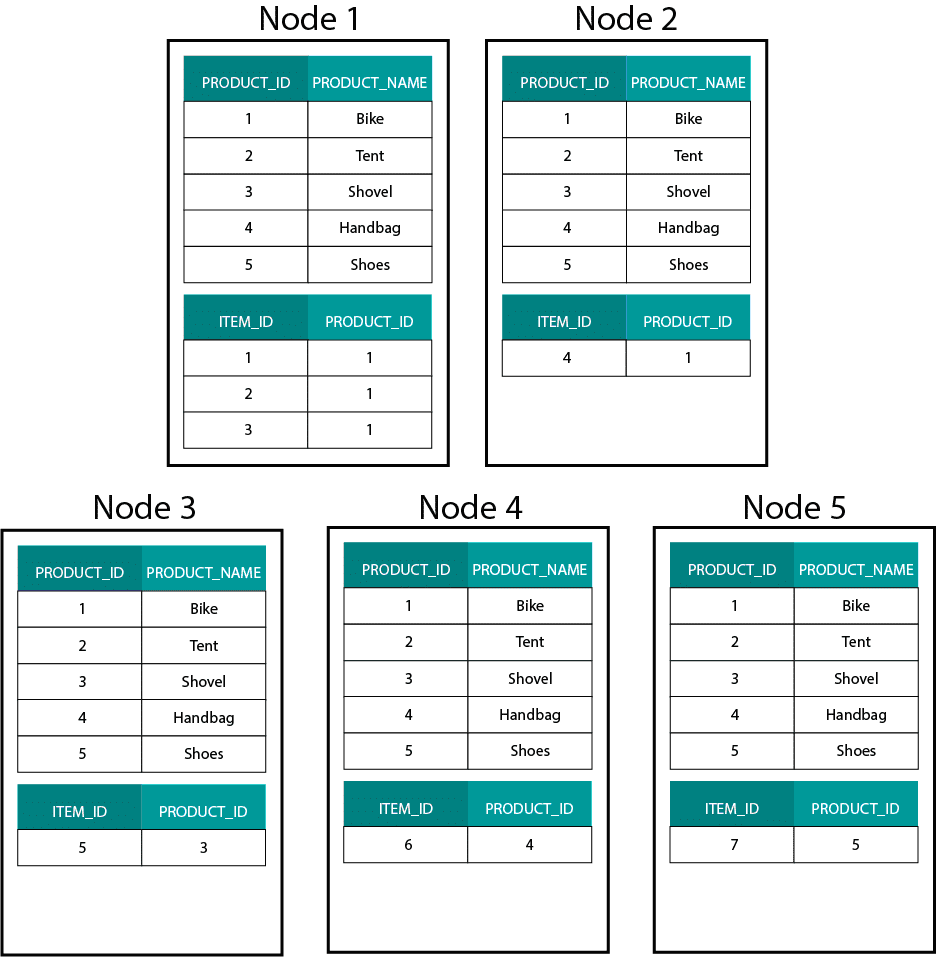
Mit tegyünk tehát, ha van egy nagy ténytáblánk és egy nagy dimenziótáblánk, például ügyfél vagy termék? Vagy egyáltalán, ha két nagy ténytáblánk van.
Dimenziós modellek a Hadoopon
Azért, hogy megkerüljük ezt a teljesítményproblémát, a nagy dimenziós táblákat de-normalizálhatjuk a ténytáblánkba, hogy garantáljuk az adatok együttes elhelyezését. A kisebb dimenziós táblákat szétküldhetjük az összes csomópontunkra.
Két nagy ténytábla összekapcsolásához az alacsonyabb granularitású táblát beágyazhatjuk a magasabb granularitású táblába, például egy nagy ORDER_ITEM táblát beágyazva az ORDER táblába. A modern lekérdezőmotorok, például az Impala vagy a Drill lehetővé teszik számunkra, hogy ezeket az adatokat ellaposítsuk

Az adatok egymásba fészkelésének ez a stratégiája hasznos az olyan fájdalmas Kimball-koncepciókhoz is, mint a híd-táblák az M:N kapcsolatok ábrázolásához egy dimenziós modellben.
Hadoop és a lassan változó dimenziók
A Hadoop fájlrendszerben a tárolás megváltoztathatatlan. Más szóval csak rekordok beszúrása és hozzáadása lehetséges. Az adatokat nem lehet módosítani. Ha relációs adattárházi háttérből érkezik, ez elsőre kissé furcsának tűnhet. A motorháztető alatt azonban az adatbázisok hasonló módon működnek. Az adatok minden változását egy megváltoztathatatlan, írást megelőző naplóban (az Oracle-ben redo log néven ismert) tárolják, mielőtt egy folyamat aszinkron módon frissítené az adatokat az adatfájlokban.
Milyen hatással van a megváltoztathatatlanság a dimenziós modelljeinkre? Talán emlékszik a lassan változó dimenziók (Slowly Changing Dimensions, SCD) fogalmára a dimenziómodellezési tanfolyamról. Az SCD-k opcionálisan megőrzik az attribútumok változásainak előzményeit. Lehetővé teszik, hogy egy adott időpontban egy attribútum értékéhez viszonyított mérőszámokat jelenthessünk. Ez azonban nem az alapértelmezett viselkedés. Alapértelmezés szerint a dimenziós táblákat a legfrissebb értékekkel frissítjük. Milyen lehetőségeink vannak tehát a Hadoopon? Ne feledje! Nem frissíthetjük az adatokat. Egyszerűen beállíthatjuk az SCD-t alapértelmezett viselkedéssé, és ellenőrizhetünk minden változást. Ha jelentéseket akarunk futtatni az aktuális értékek alapján, akkor létrehozhatunk egy olyan nézetet az SCD tetején, amely csak a legfrissebb értéket kéri le. Ezt könnyen megtehetjük az ablakozási függvények segítségével. Alternatívaként futtathatunk egy úgynevezett tömörítési szolgáltatást, amely fizikailag létrehozza a dimenziótábla egy külön változatát, amely csak a legfrissebb értékeket tartalmazza.
Tárolás fejlődése a Hadoopban
Ezek a Hadoop korlátozások nem maradtak észrevétlenül a Hadoop platformok gyártóitól. A Hive-ban már vannak ACID tranzakciók és frissíthető táblák. A nyitott fő problémák száma és saját tapasztalataim alapján ez a funkció azonban még nem tűnik gyártásra késznek . A Cloudera más megközelítést választott. A Kudu-val egy új frissíthető tárolási formátumot hoztak létre, amely nem a HDFS-en, hanem a helyi operációs rendszer fájlrendszerén helyezkedik el. Ez teljesen megszabadul a Hadoop korlátaitól, és hasonló a hagyományos tárolási réteghez egy oszlopos MPP-ben. Általánosságban elmondható, hogy valószínűleg jobban jársz, ha bármilyen BI és dashboard felhasználási esetet egy MPP-n, pl. Impala + Kudu, mint a Hadoopon futtatsz. Ennek ellenére az MPP-knek megvannak a maguk korlátai a rugalmasság, a párhuzamosság és a skálázhatóság tekintetében. Ha ezekbe a korlátokba ütközik, a Hadoop és közeli rokona, a Spark jó választás a BI-munkaterhelésekhez. A Big Data for Data Warehouse Professionals című képzésünkben kitérünk mindezekre a korlátokra, és ajánlásokat teszünk arra, hogy mikor használjon RDBMS-t és mikor SQL-t Hadoop/Sparkon.
Az ítélet. A dimenziós modellek és a csillagsémák elavultak?
Mindannyian tudjuk, hogy Ralph Kimball nyugdíjba vonult. De az ő alapvető ötletei és koncepciói még mindig érvényesek és tovább élnek. Az új technológiákhoz és tárolási típusokhoz kell igazítanunk őket, de még mindig hozzáadott értéket képviselnek.
Tanítson meg a Big Data-ra, hogy előrébb jussak a karrieremben
Kiegészítő olvasmány a dimenziós modellezésről a Big Data korszakában
Tom Breur: A dimenziós modellezés múltja és jövője
Edosa Odaro: 5 radikális tipp a gyors big data integrációhoz – Az anti-adattárház minta