Revised:
Az alanyok igazat mondanak?
Az önbevallásos adatok megbízhatósága a felmérési kutatások egyik Achilles-sarka. A közvélemény-kutatások például azt mutatták, hogy az amerikaiak több mint 40%-a hetente jár templomba. Hadaway és Marlar (2005) azonban az egyházlátogatási nyilvántartásokat megvizsgálva arra a következtetésre jutott, hogy a tényleges látogatottság kevesebb mint 22 százalék. Seth Stephens-Davidowitz (2017) “Everybody lies” (Mindenki hazudik) című alapművében bőséges bizonyítékot talált arra, hogy a legtöbb ember nem azt teszi, amit mond, és nem azt mondja, amit tesz. Például a közvélemény-kutatásokra válaszolva a legtöbb szavazó kijelentette, hogy a jelölt etnikai hovatartozása nem fontos. A Google keresőkifejezések ellenőrzésével Sephens-Davidowitz azonban az ellenkezőjét találta. konkrétan, amikor a Google-felhasználók beírták az “Obama” szót, mindig összekapcsolták a nevét néhány faji vonatkozású szóval.
A webalapú oktatással kapcsolatos kutatásokhoz a webhasználati adatokat a felhasználói hozzáférési napló elemzése, a cookie-k beállítása vagy a gyorsítótár feltöltése révén lehet megszerezni. Ezek a lehetőségek azonban korlátozottan alkalmazhatók. Például a felhasználói hozzáférési napló nem tudja nyomon követni azokat a felhasználókat, akik más weboldalakra mutató linkeket követnek. Továbbá a cookie-k vagy a gyorsítótárak használata adatvédelmi problémákat vethet fel. Ezekben a helyzetekben a felmérésekkel gyűjtött önbevallásos adatokat használják. Ez felveti a kérdést: Mennyire pontosak az önbevallásos adatok? Cook és Campbell (1979) rámutatott, hogy az alanyok (a) hajlamosak arról számolni, amit a kutató szerintük látni vél, vagy (b) arról számolnak be, ami pozitívan tükrözi saját képességeiket, tudásukat, meggyőződésüket vagy véleményüket. Az ilyen adatokkal kapcsolatos másik aggodalom arra vonatkozik, hogy az alanyok képesek-e pontosan felidézni a múltbeli viselkedésüket. A pszichológusok figyelmeztettek arra, hogy az emberi memória hibás(Loftus, 2016; Schacter, 1999). Néha az emberek olyan eseményekre “emlékeznek”, amelyek soha nem történtek meg. Így az önbevallott adatok megbízhatósága bizonytalan.Bár a statisztikai szoftvercsomagok képesek 16-32 tizedesjegyig terjedő számok kiszámítására, ez a pontosság értelmetlen, ha az adatok még egész számok szintjén sem lehetnek pontosak. Jó néhány tudós figyelmeztette a kutatókat, hogy a mérési hiba megbéníthatja a statisztikai elemzést (Blalock, 1974), és azt javasolta, hogy a jó kutatási gyakorlat megköveteli a gyűjtött adatok minőségének vizsgálatát (Fetter,Stowe, & Owings, 1984).
Mérési hiba és variancia
A mérési hibák két összetevőből állnak, nevezetesen a torzításból és a változó hibából.A torzítás olyan rendszeres hiba, amely a bejelentett eredményt az egyik véglet felé tolja. Például az IQ-tesztek több változata a nem fehérekkel szemben elfogultnak bizonyult. Ez azt jelenti, hogy a feketék és a spanyolajkúak a tényleges intelligenciájuktól függetlenül alacsonyabb pontszámot kapnak. A változó hiba, más néven variancia, általában véletlenszerű. Más szóval, a közölt pontszámok lehetnek a tényleges pontszámok felett vagy alatt (Salvucci, Walter, Conley, Fink, & Saba, 1997).
A mérési hibák e két típusának megállapításai különböző következményekkel járnak. Például egy vizsgálatban, amely az önbevalláson alapuló magassági és súlyadatokat hasonlította össze a közvetlenül mért adatokkal (Hart & Tomazic, 1999),azt találták, hogy az alanyok hajlamosak túljelentkezni a magasságukról, de aluljelentkezni a súlyukról. Nyilvánvaló, hogy ez a fajta hibamintázat inkább torzítás, mint variancia. Ennek a torzításnak az egyik lehetséges magyarázata az, hogy a legtöbb ember jobb fizikai képet szeretne mutatni másoknak. Ha azonban a mérési hiba véletlenszerű, a magyarázat bonyolultabb lehet.
Azzal érvelhetünk, hogy a véletlenszerű természetű változó hibák kioltják egymást, és így nem jelentenek veszélyt a vizsgálatra. Például az első felhasználó 10%-kal túlbecsülheti internetes tevékenységét, de a második felhasználó 10%-kal alulbecsülheti az övét. Ebben az esetben az átlag még mindig helyes lehet. A túl- és alulbecslés azonban növeli az eloszlás változékonyságát. Számos parametrikus tesztben a csoporton belüli változékonyságot hibatételként használják. A felnagyított variabilitás határozottan befolyásolná a teszt szignifikanciáját. Egyes szövegek megerősíthetik a fenti téves felfogást. Például Deese (1972) azt mondta,
A statisztikai elmélet azt mondja, hogy a megfigyelések megbízhatósága arányos a számuk négyzetgyökével. Minél több megfigyelés van, annál nagyobb a véletlen befolyás. És a statisztikai elmélet szerint minél több véletlen hiba van, annál valószínűbb, hogy ezek kioltják egymást, és normális eloszlást eredményeznek (55. o.).
Először is igaz, hogy a minta méretének növekedésével az eloszlás szórása csökken, ez nem garantálja, hogy az eloszlás alakja megközelíti a normalitást. Másodszor, a megbízhatóságot (az adatok minőségét) inkább a méréshez kell kötni, mint a mintaméret-meghatározáshoz. Egy nagy mintaméret sok mérési hibával,még véletlen hibákkal is, felduzzasztaná a parametrikus tesztek hibatermét.
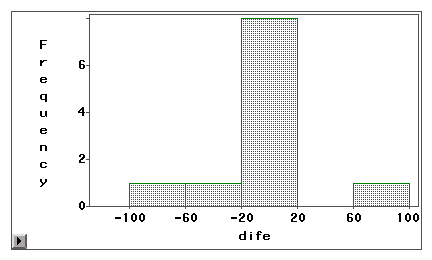
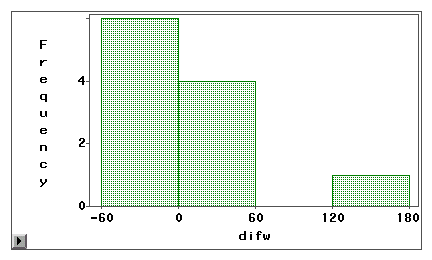
A szár- és levéldiagram vagy egy hisztogram használható annak vizuális vizsgálatára, hogy egy mérési hiba szisztematikus torzításból vagy véletlen szórásból adódik-e vagy véletlen szórásból. A következő példában az internet-hozzáférés két típusát (webböngészés és e-mail) mérik önbevallásos felméréssel és naplóval egyaránt. A különbségi pontszámokat (1. mérés – 2. mérés) a következő hisztogramokon ábrázoljuk.
Az első grafikonból kiderül, hogy a legtöbb különbségi pontszám a nulla körül helyezkedik el. Az alul- és túljelentések mindkét végpont közelében megjelennek, ami arra utal, hogy a mérési hiba inkább véletlen hiba, mint szisztematikus torzítás.
A második grafikon egyértelműen jelzi, hogy a mérési hibák nagyfokúak, mivel nagyon kevés különbözeti pontszám van a nulla körüli középpontban. Ráadásul az eloszlás negatívan ferde, így a hiba inkább torzítás, mint szórás.
Mennyire megbízható a memóriánk?
Schacter (1999) figyelmeztetett, hogy az emberi memória csalhatatlan. Emlékezetünknek hét hibája van:
- Átmenetiség: Az információ hozzáférhetőségének csökkenése az idő múlásával.
- Távollét: Figyelmetlen vagy felszínes feldolgozás, amely hozzájárul a gyenge emlékezethez.
- Blokkolás: Az emlékezetben tárolt információ átmeneti hozzáférhetetlensége.
- Téves hozzárendelés Egy emlék vagy gondolat rossz forrásnak tulajdonítása.
- Szuggesztibilitás: Olyan emlékek, amelyeket vezető kérdések vagy elvárások eredményeként ültetnek be.
- Elfogultság: Visszatekintő torzítások és tudattalan befolyások, amelyek az aktuális ismeretekkel és meggyőződésekkel kapcsolatosak.
- Megmaradás: Kóros emlékek – olyan információk vagy események, amelyeket nem tudunk elfelejteni, még ha szeretnénk is.
 |
“Ezekről már nem emlékszem. Nem emlékszem, hogy aláírtam volna a Whitewaterre vonatkozó dokumentumot. Nem emlékszem, miért tűnt el a dokumentum, de később újra előkerült. Nem emlékszem semmire.” “Emlékszem, hogy (Boszniában) mesterlövészek tüze alatt szálltam le. A repülőtéren valamiféle üdvözlő ünnepségnek kellett volna lennie, de ehelyett mi csak lehajtott fejjel futottunk, hogy beszálljunk a bázisunkra tartó járművekbe.” A személyes e-mail szerveren keresztül történő titkos információk küldésének vizsgálata során Clinton 39 alkalommal mondta az FBI-nak, hogy nem tud “visszaemlékezni” vagy “emlékezni” semmire. Vigyázat! Új számítógépes vírust fedeztek fel “Clinton” néven. Ha a számítógép megfertőződött, gyakran felugrik ez az üzenet: “kifogyott a memória”, még akkor is, ha megfelelő memóriával rendelkezik. |
| K: “Ha Vernon Jordon azt mondta nekünk, hogy önnek rendkívüli memóriája van,az egyik legjobb memóriája, amit valaha is látott egy politikustól, akkor ezt vitatná?”
A: “Valóban jó a memóriám… De arra nem emlékszem, hogy kettesben voltam-e Monica Lewinskyvel vagy sem. Hogyan tudnám számon tartani ennyi nőt az életemben?” K: Miért ajánlotta Clinton Lewinskyt a Revlonnál való munkára? A: Tudta, hogy jól tudna kitalálni dolgokat. |
 |
Fontos megjegyezni, hogy néha az emlékezetünk megbízhatósága az eredmény kívánatosságával függ össze. Amikor például egy orvoskutató megpróbál releváns adatokat gyűjteni olyan anyáktól, akiknek a gyermeke egészséges, és olyan anyáktól, akiknek a gyermeke rosszul fejlődött, az utóbbiak adatai általában pontosabbak, mint az előbbieké. Ez azért van így, mert a rosszul alakult babák anyái gondosan áttekintettek minden betegséget, amely a terhesség alatt történt, minden szedett gyógyszert, minden olyan részletet, amely közvetlenül vagy távolról kapcsolódik a tragédiához, hogy megpróbáljanak magyarázatot találni. Ezzel szemben az egészséges csecsemők édesanyjai nem fordítanak nagy figyelmet az előbbi információkra (Aschengrau & SeageIII, 2008). A GPA felfújása egy másik példa arra, hogy a kívánatlanság hogyan befolyásolja a memória pontosságát és az adatok integritását. Bizonyos helyzetekben nemek közötti különbség van a GPA felfújásában. Egy Caskie etal. által végzett tanulmány. (2014) azt találta, hogy az alacsonyabb GPA-val rendelkező egyetemi hallgatók csoportján belül a nők nagyobb valószínűséggel számoltak be a ténylegesnél magasabb GPA-ról, mint a férfiak.
Az emlékezési hibák problémájának ellensúlyozására egyes kutatók azt javasolták, hogy inkább a résztvevő pillanatnyi gondolatával vagy érzésével kapcsolatos adatokat gyűjtsenek, minthogy távoli események felidézését kérjék tőle (Csikszentmihalyi & Larson, 1987; Finnigan & Vazire,2018). Az alábbi példák a 2018-as Programme forInternational Student Assessment felmérési tételek: “Tisztelettel bántak Önnel tegnap egész nap?” “Sokat mosolyogtál vagy nevettél tegnap?” “Tanultál vagy csináltál valami érdekeset tegnap?” (Gazdasági Együttműködési és Fejlesztési Szervezet, 2017). A válasz azonban attól függ, hogy mi történt a résztvevővel az adott pillanat körül, ami nem feltétlenül jellemző. Konkrétan, még ha a válaszadó tegnap nem is mosolygott vagy nevetett sokat, ez nem feltétlenül jelenti azt, hogy a válaszadó mindig boldogtalan.
Mit tegyünk?
Egyes kutatók elutasítják az önbevallásos adatok használatát annak állítólagos rossz minősége miatt. Például amikor egy kutatócsoport azt vizsgálta, hogy a magas vallásosság vezetett-e a COVID19 világjárvány idején az Egyesült Államokban a menedékhelyen elhelyezett irányelvek kisebb mértékű betartásához, a régió vallásosságának helyettesítő mérőszámaként a 10 000 lakosra jutó gyülekezetek számát használták az önbevalláson alapuló vallásosság helyett, amely inkább a társadalmi kívánatosságot tükrözi (DeFranza, Lindow, Harrison, Mishra, &Mishra, 2020).
Chan (2009) azonban azzal érvelt, hogy az önbevallásos adatok úgynevezett rossz minősége nem több, mint városi legenda. A társadalmi kívánatosság által vezérelve a válaszadók bizonyos alkalmakkor pontatlan adatokat szolgáltathatnak a kutatóknak, de ez nem mindig történik meg. Például nem valószínű, hogy a válaszadók hazudnának a demográfiai adataikról, például a nemükről és az etnikai hovatartozásukról. Másodszor, míg igaz, hogy a kísérleti vizsgálatokban a válaszadók hajlamosak meghamisítani a válaszaikat, ez a probléma kevésbé súlyos a terepvizsgálatokban és a naturalisztikus környezetben alkalmazott méréseknél. Továbbá, számos jól bevált önbevallásos mérés létezik a különböző pszichológiai konstruktumokról, amelyek mind konvergens, mind diszkrimináns validációval bizonyították a konstruktumok érvényességét. Például a Big-five személyiségvonások, a proaktív személyiség, az affektivitási diszpozíció, az önhatékonyság, a célorientációk, az észlelt szervezeti támogatás és sok más.A járványtan területén Khoury, James és Erickson (1994) azt állította, hogy a felidézési torzítás hatása túlértékelt. Következtetésük azonban nem biztos, hogy jól alkalmazható más területekre, például az oktatásra és a pszichológiára.Az adatok pontatlanságának veszélye ellenére lehetetlen, hogy a kutató minden alanyt videokamerával kövessen és mindent rögzítsen, amit csinál. Mindazonáltal a kutató az alanyok egy részhalmazát felhasználhatja a megfigyelt adatok, például a felhasználói naplóhoz való hozzáférés vagy a web-hozzáférés napi nyomtatott naplójának megszerzésére. Az eredményeket ezután összehasonlítaná az összes alany¹ önbevallásos adatainak eredményével a mérési hiba becslése céljából.Például
- Ha a kutató rendelkezésére áll a felhasználói hozzáférési napló, megkérheti az alanyokat, hogy számoljanak be a webszerverhez való hozzáférésük gyakoriságáról.Az alanyokat nem szabad tájékoztatni arról, hogy internetes tevékenységeiket a webmester naplózza, mivel ez befolyásolhatja a résztvevők viselkedését.
- A kutató megkérheti a felhasználók egy részhalmazát, hogy egy hónapon keresztül vezessenek naplót internetes tevékenységeikről. Ezt követően ugyanazokat a felhasználókat megkéri, hogy töltsenek ki egy felmérést a webhasználatukról.
Azzal érvelhet valaki, hogy a naplós megközelítés túlságosan igényes. Valóban,sok tudományos kutatásban az alanyoktól ennél sokkal többet kérnek. Például amikor a tudósok azt vizsgálták, hogy a hosszú távú űrutazás során a mély alvás hogyan hatna az emberi egészségre, a résztvevőket arra kérték, hogy egy hónapig feküdjenek az ágyban. Egy olyan tanulmányban, amely azt vizsgálta, hogy a zárt környezet hogyan befolyásolja az emberi pszichológiát az űrutazás során, az alanyokat szintén egy hónapig külön-külön zárták be egy szobába. A tudományos igazságok felkutatása nagy költséggel jár.
A különböző adatforrások összegyűjtése után a napló és az önbevallás adatai közötti eltérés elemezhető az adatok megbízhatóságának becslése érdekében. Első pillantásra ez a megközelítés úgy néz ki, mint a teszt-retesztmegbízhatóság, de nem az. Először is, a teszt-reteszt megbízhatóságnál a két vagy több helyzetben használt eszköznek azonosnak kell lennie. Másodszor, ha a teszt-reteszt megbízhatóság alacsony, a hibák forrása a műszeren belül van. Amikor azonban a hibák forrása az eszközön kívüli, mint például az emberi hibák, az értékelők közötti megbízhatóság megfelelőbb.
A fent javasolt eljárást úgy lehet elképzelni, mint az adatok közötti megbízhatóság mérését, amely hasonlít az értékelők közötti megbízhatósághoz és az ismételt mérésekhez. Az értékelők közötti megbízhatóság becslésére négyféle módszer létezik, nevezetesen a Kappa együttható, az inkonzisztenciaindex, az ismételt mérések ANOVA és a regressziós elemzés. A következő szakasz leírja, hogy ezek az értékelők közötti megbízhatósági mérések hogyan használhatók adatközi megbízhatósági mérésekként.
Kappa együttható
A pszichológiai és oktatási kutatásokban nem ritka, hogy két vagy több értékelőt alkalmaznak a témamérési folyamatban, ha az értékelés szubjektív ítéleteket tartalmaz (pl. esszék osztályozása). Az értékelők közötti megbízhatóságot, amelyet a Kappa együtthatóval mérnek, az adatok megbízhatóságának jelzésére használják.Például a résztvevők teljesítményét két vagy több értékelő “mester” vagy “nem mester” (1 vagy 0) minősítéssel értékeli. Így ezt a mérést általában kategorikus adatelemzési eljárásokban számítják ki, mint például a PROC FREQ a SAS-ban, a “megállapodás mérése” az SPSS-ben vagy egy online Kappa-kalkulátor (Lowry, 2016). Az alábbi kép a Vassarstats online kalkulátorának képernyőképét mutatja.
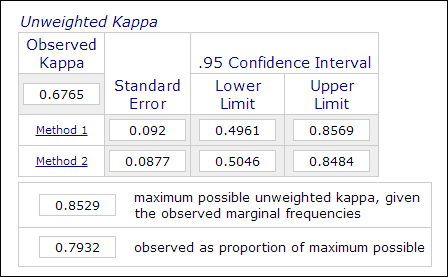
Fontos megjegyezni, hogy még ha két adatsor 60 százaléka egyezik is egymással, ez nem jelenti azt, hogy a mérések megbízhatóak.mivel az eredmény dichotóm, 50 százalék az esélye annak, hogy a két mérés megegyezik. A Kappa együttható ezt figyelembe veszi, és nagyobb mértékű egyezést követel meg a konzisztencia eléréséhez.
A webalapú oktatással összefüggésben a saját maga által bejelentett weboldal-használat minden kategóriája átkódolható bináris változóvá. Például, amikor az első kérdés a “milyen gyakran használja a telnetet”, a lehetséges kategorikus válaszok a következők: “a: naponta”, “b: hetente három-öt alkalommal”, “c: havonta három-öt alkalommal”, “d: ritkán” és “e: soha”. Ebben az esetben az öt kategória öt változóvá kódolható át: Q1A, Q1B, Q1C, Q1D és Q1E. Ezután mindezeket a bináris változókat egy R X 2 táblázatba lehet illeszteni, amint az a következő táblázatban látható.Ezzel az adatszerkezettel a válaszok “1”-ként vagy “0”-ként kódolhatók, és így lehetővé válik az osztályozási egyezés mérése. Az egyezés kiszámítható a Kappa együttható segítségével, és ezáltal megbecsülhető az adatok megbízhatósága.
Alanyok Logkönyv adatai Self-report data Subject 1 1 1 Subject 2 0 0 Tárgy 3 1 0 Subject 4 0 1 Inkonzisztenciaindex
A fent említett kategorikus adatok kiszámításának másik módja az Index ofInconsistency (IOI). A fenti példában, mivel a válaszban két mérés (log és önbevallás) és öt lehetőség van, egy 4 X 4 táblázatot képezünk. Az IOI kiszámításának első lépése az RXC tábla több 2X2 altáblára való felosztása. Például az utolsó “soha” opciót egy kategóriaként kezeljük, az összes többit pedig egy másik kategóriába, a “nem soha” kategóriába soroljuk, amint az a következő táblázatban látható.
Self-jelentett adatok Log Soha nem soha összesen Nem soha a b a+b Nem soha c d c+d összesen a+c b+d n=Sum(a-d) Az IOI százalékos arányát a következő képlettel számítjuk ki:
IOI% = 100*(b+c)/ ahol p = (a+c)/n
Az IOI kiszámítása után minden 2X2 altáblára az összes index átlagát használják az intézkedés következetlenségének mutatójaként. Az adatok konzisztenciájának megítélésére szolgáló kritérium a következő:
- A 20 alatti IOI alacsony szórást jelent
- A 20 és 50 közötti IOI közepes szórást
- A 50 feletti IOI magas szórást
Az adatok megbízhatóságát ez az egyenlet fejezi ki: Ha mindkét adatforrás folyamatos adatokat szolgáltat, akkor az adatok megbízhatóságának jelzésére kiszámítható az intraosztályos korrelációs együttható: r = 1 – IOI
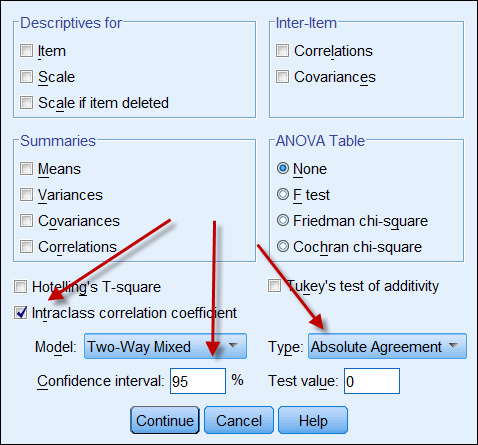
Intraosztályos korrelációs együttható
. Az alábbiakban egy képernyőképet láthatunk az SPSS ICC beállításairól. A Typethere két lehetőség van: “konzisztencia” és “abszolút egyezés”. Ha a “konzisztenciát” választja, akkor még ha az egyik számsor magas konzisztenciájú is (pl. 9, 8, 9, 9, 8, 8, 7…) és a másik alacsony konzisztenciájú (pl. 4,3, 4, 4, 3, 2…), erős korrelációjuk tévesen azt sugallja, hogy az adatok összhangban vannak egymással. Ezért célszerű az “abszolút egyezést” választani.
ismételt mérések
Az adatok közötti megbízhatóság mérése ismételt mérésiANOVA-ként is konceptualizálható és procedurálható. Az ismételt mérésekkel végzett ANOVA-ban az azonos alanyok többször kapnak méréseket, például pretestet, félidőt és posttestet. Ebben a kontextusban az alanyokat ismételten mérik a webes felhasználói napló, a napló és az önbevallásos felmérés segítségével is. A következő a SASkód egy ismételt mérési ANOVA-hoz:
data one; input user $ web_log log_book self_report;
cards;
1 215 260 200
2 178 200 150
3 100 111 120
4 135 172 100
5 139 150 140
6 198 200 230
7 135 150 180
8 120 110 100
9 289 276 300
proc glm;
classes user;
model web_log log_book self_report = user;
repeated time 3;
run;
A fenti programban a kilenc önkéntes által meglátogatott weboldalak számát a felhasználói hozzáférési naplóban, a személyes naplókönyvben és az önbevallásos felmérésben rögzítik. A felhasználókat alanyok közötti faktornak, míg a három mérést mérések közötti faktornak tekintjük. A következő egy sűrített kimenet:
Variáció forrása DF Mérőnégyzet Mérőpontok között (felhasználó) 8 10442.50 Between-measure (time) 2 488.93 Residual 16 454.80 A fenti információk alapján a megbízhatósági együttható a következő képlet segítségével számítható ki (Fisher, 1946; Horst, 1949):
r = MSbetween-measure – MSresidual —————————————————-.———- MSbetween-measure + (dfbetween-people X MSresidual) Tegyük be a számot a képletbe:
r = 488.93 – 454,80 ————————————— 488,93 + ( 8 X 454,80) A megbízhatóság körülbelül .0008, ami rendkívül alacsony. Ezért hazamehetünk, és elfelejthetjük az adatokat. Szerencsére ez csak egy hipotetikus adathalmaz. De mi van akkor, ha ez egy valós adathalmaz? Elég keménynek kell lennünk ahhoz, hogy inkább feladjuk a rossz adatokat, minthogy olyan eredményeket tegyünk közzé, amelyek teljesen megbízhatatlanok.
Korrelációs és regressziós elemzés
A korrelációs elemzés, amely a Pearson-féle termékmomentum-együtthatót használja, nagyon egyszerű és különösen hasznos, ha a két mérés skálája nem azonos. Például a webszerver naplója követheti az oldalelérések számát, míg az önbevallás adataiLikert-skálásak (pl. Milyen gyakran böngészik az internetet? 5=nagyon gyakran,4=gyakran, 3=némelykor, 2=ritkán, 5=soha). Ebben az esetben az önbevallás szerinti pontszámok prediktorként használhatók az oldalhozzáférés regressziójához.
Hasonló megközelítés a regressziós elemzés, amelyben a pontszámok egy csoportját (pl. felmérési adatok) prediktorként kezelik, míg egy másik pontszámcsoportot (pl. felhasználói napi napló) függő változónak tekintik. Ha kettőnél több mérőszámot alkalmaznak, többszörös regressziós modellt lehet alkalmazni, azaz azt, amelyik pontosabb eredményt ad (pl. webes felhasználói hozzáférési napló), függő változónak tekintik, és az összes többi mérőszámot (pl. napi felhasználói napló, felmérési adatok) független változóként kezelik.
Hivatkozás
- Aschengrau, A., & Seage III, G. (2008). A járványtan alapjai a közegészségügyben. Boston, MA: Jones and Bartlett Publishers.
- Blalock, H. M. (1974). (Szerk.) Mérés a társadalomtudományokban: Elméletek és stratégiák. Chicago, Illinois: Aldine Publishing Company.
- Caskie, G. I. L., Sutton, M. C., & Eckhardt, A. G. (2014). Az önbevalláson alapuló főiskolai GPA pontossága: Nemek által moderált különbségek a teljesítményszint és az akadémiai önhatékonyság szerint. Journal of College Student Development, 55, 385-390. 10.1353/csd.2014.0038
- Chan, D. (2009). Akkor miért engem kérdezel? Tényleg ennyire rosszak az önbevallási adatok? In Charles E. Lance és Robert J. Vandenberg (szerk.), Statisztikai és módszertani mítoszok és városi legendák: Doctrine,verity and fable in the organizational and social sciences (pp309-335). New York, NY: Routledge.
- Cook, T. D., & Campbell, D. T. (1979). Kvázi-kísérletezés: Tervezési és elemzési kérdések. Boston, MA: Houghton Mifflin Company.
- Csikszentmihalyi, M., & Larson, R. (1987). A tapasztalati mintavételi módszer érvényessége és megbízhatósága. Journal of Nervous and Mental Disease, 175, 526-536. https://doi.org/10.1097/00005053-198709000-00004
- Deese, J. (1972). A pszichológia mint tudomány és művészet. New York, NY: Harcourt Brace Jovanovich, Inc.
- DeFranza, D., Lindow, M., Harrison, K., Mishra, A., &Mishra, H. (2020, augusztus 10.). A vallás és a COVID-19mitigációs irányelvekre való reagálás. Amerikai pszichológus. Előzetes online közzététel. http://dx.doi.org/10.1037/amp0000717.
- Fetters, W., Stowe, P., & Owings, J. (1984). Középiskola és azon túl. Országos longitudinális vizsgálat az 1980-as évekre, a középiskolások kérdőíves tételekre adott válaszainak minősége. (NCES 84-216): Washington, D. C., Washington, D. C. (NCES 84-216): U.S. Department of Education. Office of EducationalResearch and Improvement. National center for Education Statistics.
- Finnigan, K. M., & Vazire, S. (2018). The incrementalvalidity of average state self-reports over global self-reports ofpersonality. Journal of Personality and Social Psychology, 115, 321-337. https://doi.org/10.1037/pspp0000136
- Fisher, R. J. (1946). Statisztikai módszerek kutatómunkások számára (10. kiadás). Edinburgh, UK: Oliver and Boyd.
- Hadaway, C. K., & Marlar, P. L. (2005). Hány amerikai jár hetente istentiszteletre? Egy alternatív megközelítés a méréshez? Journal for the Scientific Study of Religion, 44, 307-322. DOI: 10.1111/j.1468-5906.2005.00288.x
- Hart, W.; & Tomazic, T. (1999 augusztus). Az antropometriai mérések százalékos eloszlásainak összehasonlítása három adathalmaz között. Előadás az Annual Joint Statistical Meeting-en, Baltimore, MD.
- Horst, P. (1949). Egy általánosított kifejezés a mérések megbízhatóságára. Psychometrika, 14, 21-31.
- Khoury, M., James, L., & Erikson, J. (1994). On theuse of affected controls to address recall bias in case-control studiesof birth defects. Teratology, 49, 273-281.
- Loftus, E. (2016, április). Az emlékezet fikciója. A Nyugati Pszichológiai Társaság kongresszusán bemutatott előadás. Long Beach, CA.
- Lowry, R. (2016). A Kappa mint az egyezés mértéke a kategorikus válogatásban. Retrieved from http://vassarstats.net/kappa.html
- Organisation for Economic Cooperation and Development. (2017). Jóléti kérdőív a PISA 2018-hoz. Párizs: Szerző. Retrieved from https://www.oecd.org/pisa/data/2018database/CY7_201710_QST_MS_WBQ_NoNotes_final.pdf
- Schacter, D. L. (1999). A memória hét bűne: Meglátások a pszichológiából és a kognitív idegtudományból. Amerikai pszichológia, 54, 182-203.
- Salvucci, S.; Walter, E., Conley, V; Fink, S; & Saba, M. (1997). Mérési hibavizsgálatok a Nemzeti Oktatási Statisztikai Központban. Washington D. C.: Washington D. C: U. S. Department of Education.
- Stephens-Davidowitz, S. (2017). Mindenki hazudik: Nagy adatok, új adatok, és amit az internet elárul arról, hogy kik vagyunk valójában. New York, NY: Dey Street Books.
 Menjen fel a főmenübe
Menjen fel a főmenübe Más tanfolyamokKereső
|

Kapcsolat
|