Kíváncsi vagy, hogy mik azok a Postgresql sémák, miért fontosak, és hogyan használhatod a sémákat, hogy robusztusabbá és karbantarthatóbbá tedd az adatbázis implementációidat? Ez a cikk bemutatja a sémák alapjait a Postgresql-ben, és néhány alapvető példán keresztül megmutatja, hogyan hozhatja létre őket. A jövőbeli cikkek elmélyednek majd a sémák biztosításának és valós alkalmazásokban való használatának példáiban.
Először is, hogy tisztázzuk az esetleges terminológiai zűrzavart, értsük meg, hogy a Postgresql világában a “séma” kifejezés talán kissé sajnos túlterhelt. A relációs adatbázis-kezelő rendszerek (RDBMS) tágabb kontextusában a “séma” kifejezés alatt az adatbázis általános logikai vagy fizikai felépítését érthetjük, azaz az adatbázis definícióját alkotó összes tábla, oszlop, nézet és egyéb objektum meghatározását. Ebben a tágabb kontextusban a séma kifejezhető egy entitás-relációs (ER) diagramban vagy az alkalmazási adatbázis példányosítására használt adatdefiníciós nyelv (DDL) utasításainak szkriptjében.
A Postgresql világában a “séma” kifejezés talán jobban érthető “névtérként”. Valójában a Postgresql rendszer tábláiban a sémák a táblák “névtér” nevű oszlopaiban vannak rögzítve, ami IMHO pontosabb terminológia. Gyakorlati szempontból, amikor a Postgresql kontextusában a “séma” szót látom, csendben átértelmezem úgy, hogy “névtér”.
De kérdezheted: “Mi az a névtér?”. Általában a névtér egy meglehetősen rugalmas eszköz az információk név szerinti szervezésére és azonosítására. Képzeljünk el például két szomszédos háztartást, a Smith-eket, Alice-t és Bobot, valamint a Jones-okat, Bobot és Cathyt (vö. 1. ábra). Ha csak keresztneveket használnánk, zavarossá válhatna, hogy melyik személyre gondolunk, amikor Bobról beszélünk. De a vezetéknév, Smith vagy Jones hozzáadásával egyértelműen azonosítjuk, hogy melyik személyre gondolunk.
A névterek gyakran egymásba ágyazott hierarchiába szerveződnek. Ez lehetővé teszi hatalmas mennyiségű információ hatékony osztályozását nagyon finom struktúrába, mint például az internetes tartománynévrendszer. A legfelső szinten a “.com”, “.net”, “.org”, “.edu” stb. széles névtereket határoz meg, amelyeken belül konkrét entitások nevei vannak bejegyezve, így például a “severalnines.com” és a “postgresql.org” egyedileg meghatározott. Mindegyik alatt azonban számos közös aldomain található, mint például a “www”, “mail” és “ftp”, amelyek önmagukban duplikatívak, de az adott névtereken belül egyediek.
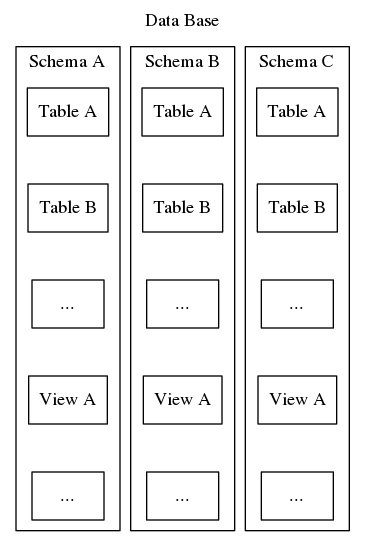
A postgresql sémák ugyanezt a szervezési és azonosítási célt szolgálják, azonban a fenti második példával ellentétben a postgresql sémák nem lehetnek hierarchikusan egymásba ágyazva. Bár egy adatbázis sok sémát tartalmazhat, mindig csak egy szint van, ezért egy adatbázison belül a sémaneveknek egyedinek kell lenniük. Továbbá minden adatbázisnak legalább egy sémát kell tartalmaznia. Minden új adatbázis létrehozásakor egy “public” nevű alapértelmezett séma jön létre. A séma tartalma magában foglalja az összes többi adatbázis-objektumot, például táblákat, nézeteket, tárolt eljárásokat, triggereket stb. A szemléltetéshez lásd a 2. ábrát, amely egy matrjoska-baba-szerű fészkelődést ábrázol, amely megmutatja, hogy a sémák hol illeszkednek egy Postgresql adatbázis szerkezetébe.
Az adatbázis-objektumok egyszerű logikai csoportokba szervezésén túl, hogy azok könnyebben kezelhetőek legyenek, a sémák gyakorlati célja a névütközések elkerülése. Az egyik működési paradigma magában foglalja egy séma meghatározását minden egyes adatbázis-felhasználó számára, hogy bizonyos fokú elszigeteltséget biztosítson, egy olyan teret, ahol a felhasználók saját tábláikat és nézeteiket definiálhatják anélkül, hogy zavarnák egymást. Egy másik megközelítés az, hogy harmadik féltől származó eszközöket vagy adatbázis-bővítményeket telepítenek az egyes sémákba, hogy az összes kapcsolódó komponenst logikailag együtt tartsák. E sorozat egy későbbi cikkében részletesen ismertetjük a robusztus alkalmazástervezés újszerű megközelítését, amely a sémákat indirekciós eszközként alkalmazza, hogy korlátozza az adatbázis fizikai tervezésének kitettségét, és ehelyett olyan felhasználói felületet mutat be, amely feloldja a szintetikus kulcsokat, és megkönnyíti a hosszú távú karbantartást és konfigurációkezelést a rendszerkövetelmények fejlődésével.
Kódoljunk egy kicsit!
A legegyszerűbb parancs egy séma létrehozására egy adatbázison belül
CREATE SCHEMA hollywood;Ez a parancs create jogosultságokat igényel az adatbázisban, és az újonnan létrehozott “hollywood” séma a parancsot meghívó felhasználó tulajdonában lesz. Egy összetettebb meghívás tartalmazhat opcionális elemeket, amelyek más tulajdonost határoznak meg, és akár DDL utasításokat is tartalmazhat, amelyek a sémán belüli adatbázis-objektumokat instanciálják egyetlen parancsban!
Az általános formátum a
CREATE SCHEMA schemaname ]ahol a “username” a séma tulajdonosa, a “schema_element” pedig bizonyos DDL parancsok egyike lehet (a részleteket lásd a Postgresql dokumentációban). Az AUTHORIZATION opció használatához Superuser jogosultságok szükségesek.
Így például egy “hollywood” nevű séma létrehozásához, amely egy “films” nevű táblát és egy “winners” nevű nézetet tartalmaz, egyetlen paranccsal a
CREATE SCHEMA hollywood CREATE TABLE films (title text, release date, awards text) CREATE VIEW winners AS SELECT title, release FROM films WHERE awards IS NOT NULL;A további adatbázis-objektumok utólag közvetlenül is létrehozhatók, például egy további táblát adhatunk a sémához a
CREATE TABLE hollywood.actors (name text, dob date, gender text);Megjegyezzük a fenti példában a tábla nevének előtagozását a séma nevével. Erre azért van szükség, mert alapértelmezés szerint, azaz explicit séma-meghatározás nélkül az új adatbázis-objektumok az aktuális sémán belül jönnek létre, amiről a következőkben lesz szó.
Emlékezzünk vissza arra, hogy a fenti első névtér-példában két Bob nevű személy volt, és leírtuk, hogyan lehet őket a vezetéknév feltüntetésével dekonfliktusmentesíteni vagy megkülönböztetni. De a Smith és Jones háztartásokon belül külön-külön minden család a “Bob” alatt azt érti, aki az adott háztartáshoz tartozik. Így például az egyes megfelelő háztartások kontextusában Alice-nek nem kell Bob Jones-ként szólítania a férjét, és Cathy-nek sem kell Bob Smith-ként hivatkoznia a férjére: mindketten egyszerűen csak “Bob”-nak mondhatják.
A Postgresql jelenlegi sémája olyan, mint a fenti példában szereplő háztartás. Az aktuális sémában lévő objektumokra minősítés nélkül lehet hivatkozni, de más sémákban lévő hasonló nevű objektumokra való hivatkozáshoz a nevet minősíteni kell a séma nevének a fenti módon történő előtagozásával.
Az aktuális séma a “search_path” konfigurációs paraméterből származik. Ez a paraméter a sémanevek vesszővel elválasztott listáját tárolja, és a
SHOW search_path;paranccsal vizsgálható, vagy új értékre állítható a
SET search_path TO schema ;paranccsal.
A lista első sémaneve az “aktuális séma”, és itt jönnek létre az új objektumok, ha a sémanév minősítése nélkül van megadva.
A sémanevek vesszővel elválasztott listája arra is szolgál, hogy meghatározza a keresési sorrendet, amely alapján a rendszer megtalálja a meglévő, minősítetlen nevű objektumokat. Például, visszatérve a Smith és Jones szomszédságához, egy csak “Bob”-nak címzett csomagküldéshez minden egyes háztartást fel kellene keresni, amíg az első “Bob” nevű lakost meg nem találjuk. Megjegyzendő, hogy ez nem feltétlenül a címzett. Ugyanez a logika érvényes a Postgresql esetében is. A rendszer a search_path sorrendjében keresi a táblákat, nézeteket és egyéb objektumokat a sémákon belül, majd az első talált névegyezéses objektumot használja. A séma-minősített névvel rendelkező objektumok közvetlenül, a search_path-ra való hivatkozás nélkül kerülnek felhasználásra.
Az alapértelmezett konfigurációban a search_path konfigurációs változó lekérdezése ezt az értéket mutatja
SHOW search_path; Search_path-------------- "$user", publicA rendszer a fent látható első értéket az aktuálisan bejelentkezett felhasználó neveként értelmezi, és alkalmazkodik a korábban említett felhasználási esethez, amikor minden felhasználónak egy felhasználó nevével ellátott sémát rendelnek a többi felhasználótól elkülönített munkaterülethez. Ha nincs ilyen felhasználó nevű séma, akkor ezt a bejegyzést a rendszer figyelmen kívül hagyja, és a “nyilvános” séma lesz az aktuális séma, ahol az új objektumok létrehozásra kerülnek.
Így, visszatérve korábbi példánkhoz, a “hollywood.actors” tábla létrehozásához, ha nem minősítettük volna a tábla nevét a séma nevével, akkor a tábla a nyilvános sémában jött volna létre. Ha az összes objektum létrehozását egy adott sémán belül terveztük, akkor kényelmes lehet a search_path változót beállítani, például
SET search_path TO hollywood,public;könnyítve a minősítetlen nevek beírásának rövidítését az adatbázis-objektumok létrehozásához vagy eléréséhez.
Létezik egy rendszerinformációs függvény is, amely egy lekérdezéssel visszaadja az aktuális sémát
select current_schema();A helyesírás kövérítése esetén egy séma tulajdonosa megváltoztathatja a nevét, feltéve, hogy a felhasználónak az adatbázis létrehozási jogosultságai is vannak, a
ALTER SCHEMA old_name RENAME TO new_name;És végül egy séma törlése az adatbázisból, van egy drop parancs
DROP SCHEMA schema_name;A DROP parancs sikertelen lesz, ha a séma objektumokat tartalmaz, így azokat kell először törölni, vagy opcionálisan a CASCADE opcióval
DROP SCHEMA schema_name CASCADE;A séma összes tartalmát rekurzívan törölheti
DROP SCHEMA schema_name CASCADE;Ezek az alapok segítenek a sémák megértésében!