Method 1, Bad: ORDER BY NEWID()
Egyszerű megírni, de úgy teljesít, mint a forró, forró szemét, mert beolvassa a teljes fürtözött indexet, kiszámítva a NEWID()-t minden sorra:
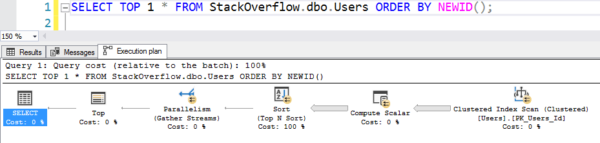
A terv a beolvasással
Ez 6 másodpercig tartott a gépemen, több szálon keresztül párhuzamosan haladva, több tíz másodperc CPU-t használva az összes számításhoz és rendezéshez. (És a Users tábla még csak nem is 1GB.)
A 2. módszer, jobb, de furcsa:
Ez 2005-ben jelent meg, és rengeteg bökkenője van. Valahogy kiválaszt egy véletlenszerű oldalt, majd visszaad egy csomó sort arról az oldalról. Az első sor véletlenszerű, de a többi nem.
Tranzak-SQL
|
1
|
SELECT * FROM StackOverflow.dbo.Users TABLESAMPLE (.01 PERCENT);
|
A terv úgy néz ki, mintha egy táblaszkennelést végezne, de csak 7 logikai olvasást végez:
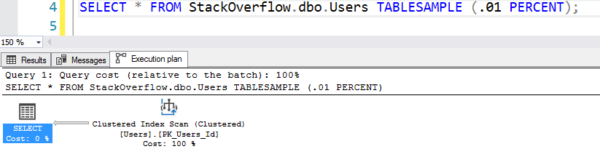
A terv a hamis szkenneléssel
De itt vannak az eredmények – látható, hogy egy véletlenszerű 8K oldalra ugrik, majd elkezdi sorban kiolvasni a sorokat. Ezek nem igazán véletlenszerű sorok.
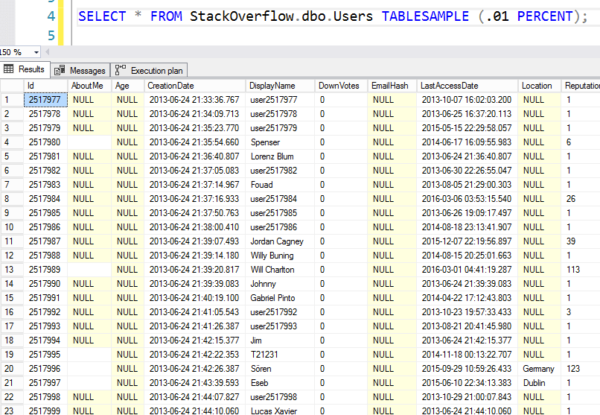
Véletlenszerű, mint a maffia lottószámok
Ehelyett használhatod a ROWS minta méretét, de az elég furcsa eredményeket ad. Például a Stack Overflow Users táblázatban, amikor azt mondtam, hogy TABLESAMPLE (50 ROWS), valójában 75 sort kaptam vissza. Ez azért van, mert az SQL Server a sorméretet százalékos értékre konvertálja át helyette.
3. módszer, a legjobb, de kódot igényel: Véletlenszerű elsődleges kulcs
Kérdezze meg a táblázat legfelső azonosító mezőjét, generáljon egy véletlen számot, és keresse meg ezt az azonosítót. Itt azért válogatunk az ID alapján, mert a valóban létező legfelső rekordot akarjuk megtalálni (míg egy véletlen számot esetleg töröltek.) Elég gyors, de csak egyetlen véletlen sorra jó. Ha 10 sort szeretnénk, akkor 10-szer kellene ilyen kódot hívni (vagy 10 véletlen számot generálni és IN záradékot használni.)
A végrehajtási terv egy fürtözött indexkeresést mutat, de csak egy sort ragad meg – mindössze 6 logikai olvasásról beszélünk mindazért, amit itt látsz, és szinte azonnal véget ér:

A terv, ami tud
Egy bökkenő van: ha az Id negatív számokat tartalmaz, akkor nem úgy működik, ahogy elvárnánk. (Tegyük fel például, hogy az identitásmeződet -1-nél kezded, és -1-gyel lépkedsz, egyre lejjebb haladva, mint az erkölcseim.)
4. módszer, OFFSET-FETCH (2012+)
Daniel Hutmacher ezt tette hozzá a hozzászólásokban:
És azt mondta: “De ez csak fürtözött indexszel működik megfelelően. Gondolom azért, mert az indexkeresés helyett egy halomban keresi a (@rows) sorokat.”
Bonus Track #1: Watch Us Discussing This
Kíváncsi voltál már arra, milyen lehet a cégünk chatszobájában? Ez a 10 perces Slack-beszélgetés elég jó képet ad:
Spoiler alert: nem volt. Csak képernyőfotókat készítettem.
Bonus Track #2: Mitch Wheat Digs Deeper
Mélyreható elemzést szeretnél több különböző technika véletlenszerűségéről? Mitch Wheat igazán mélyre merül, grafikonokkal kiegészítve!