A fenti kép talán eléggé elárulta, miről szól ez a bejegyzés.
Ez a bejegyzés néhány fontos fuzzy(nem pontosan egyenlő, de lumpsum ugyanazok a karakterláncok, mondjuk RajKumar & Raj Kumar) karakterlánc-illesztő algoritmusokkal foglalkozik, amelyek közé tartozik:
Hamming Distance
Levenstein Distance
Damerau Levenstein Distance
N-Gram alapú string matching
BK Tree
Bitap algoritmus
De először is tudnunk kell, hogy miért fontos a fuzzy matching egy valós forgatókönyvet figyelembe véve. Amikor egy felhasználó bármilyen adatot megadhat, a dolgok nagyon kuszává válhatnak, mint az alábbi esetben!!!
Legyen,
- A neved ‘Saurav Kumar Agarwal’.
- Kaptál egy könyvtári kártyát (természetesen Egyedi azonosítóval), amely a családod minden tagjára érvényes.
- Minden héten elmész egy könyvtárba, hogy kiadj néhány könyvet. Ehhez azonban először bejegyzést kell tenned egy nyilvántartásba a könyvtár bejáratánál, ahová beírod az azonosítód & nevét.
A könyvtári hatóságok most úgy döntenek, hogy elemzik ennek a könyvtári nyilvántartásnak az adatait, hogy képet kapjanak a havonta látogató egyedi olvasókról. Nos, ezt több okból is meg lehet tenni (például, hogy menjünk-e területbővítésre vagy sem, növelni kell-e a könyvek számát? stb.).
Ezt úgy tervezték, hogy megszámolják az egy hónapra bejegyzett (egyedi nevek, könyvtári azonosító) párokat. Tehát ha van
123 Mehul
123 Rajesh
123 Mehul
133 Rajesh
133 Sandesh
Ez 4 egyedi olvasót adna.
So messze eddig jó
A számot 10k-10 körülire becsülték.5k-ra becsülték, de a számok a nevek pontos karakterlánc-illesztésével végzett elemzés után ~50k-ra emelkedtek.
wooohhh!!
Meg kell mondjam, elég rossz becslés!!
Vagy kihagytak itt egy trükköt?
Mélyebb elemzés után egy komoly probléma merült fel. Emlékezz a nevedre, ‘Saurav Agarwal’. Találtak néhány bejegyzést, amelyek 5 különböző felhasználóhoz vezetnek a családi könyvtár azonosítóján keresztül:
- Saurav K Aggrawal (vegye észre a dupla ‘g’-t, ‘ra-ar’, Kumarból K lesz)
- Saurav Kumar Agarwal
- Sourav Aggarwal
- SK Agarwal
- Agarwal
Létezik néhány kétértelműség, mivel a könyvtári hatóságok nem tudják
- Hányan látogatják a könyvtárat a családjából? hogy ez az 5 név egyetlen olvasót, 2 vagy 3 különböző olvasót jelent-e. Nevezzük ezt egy nem felügyelt problémának, ahol van egy karakterláncunk, amely nem szabványosított neveket képvisel, de a szabványosított nevük nem ismert (pl. Saurav Agarwal: Saurav Kumar Agarwal nem ismert)
- Mindegyiküknek össze kellene olvadnia ‘Saurav Kumar Agarwal’-nak? nem lehet megmondani, mivel SK Agarwal lehet Shivam Kumar Agarwal (mondjuk az apja neve). Továbbá, az egyetlen Agarwal lehet bárki a családból.
Az utolsó 2 eset (SK Agarwal & Agarwal) további információkat igényelne (mint például nem, születési dátum, kiadott könyvek), amelyeket egy ML-algoritmusba kell táplálni az olvasó tényleges nevének meghatározásához & egyelőre hagyjuk. De egy dologban eléggé biztos vagyok, hogy az 1. 3 név ugyanazt a személyt képviseli & Nincs szükségem extra információra ahhoz, hogy egyetlen olvasóvá egyesítsem őket, azaz ‘Saurav Kumar Agarwal’.
Hogyan lehet ezt megtenni?
Itt jön a fuzz string matching, ami szinte pontos egyezést jelent az egymástól kissé eltérő karakterláncok között (leginkább a rossz helyesírás miatt), mint például ‘Agarwal’ & ‘Aggarwal’ & ‘Aggrawal’. Ha egy elfogadható hibaarányú (mondjuk egy betű hibás ) karakterláncot kapunk, akkor azt egyezésnek tekintjük. Vizsgáljuk meg tehát a →
Hamming távolság a két azonos hosszúságú karakterlánc között számított legkézenfekvőbb távolság, amely megadja az adott indexnek megfelelő nem egyező karakterek számát. Például: ‘Denevér’ & ‘Fogadás’ hamming távolsága 1, mivel az 1. indexnél az ‘a’ nem egyenlő az ‘e’-vel
Levenstein távolság/ Edit távolság
Bár feltételezem, hogy a Levenstein távolsággal már tisztában vagy & Rekurzió. Ha nem, akkor olvasd el ezt. Az alábbi magyarázat inkább a Levenstein-távolság összefoglaló változata.
Legyen ‘x’= length(Str1) & ‘y’=length(Str2) az egész bejegyzéshez.
A Levenstein-távolság kiszámítja az ‘Str1’ ‘Str2’-vé alakításához szükséges minimális számú szerkesztést, amely vagy hozzáadás, vagy eltávolítás, vagy karakterek cseréjével történik. Így a ‘Cat’ & ‘Bat’ szerkesztési távolsága ‘1’ (C’ cseréje ‘B’-re), míg a ‘Ceat’ & ‘Bat’ esetében 2 (C’ cseréje ‘B’-re; ‘e’ törlése).
Az algoritmusról szólva, nagyjából 5 lépésből áll
int LevensteinDistance(string str1, string str2, int x, int y){if (x == len(str1)+1) return len(str2)-y+1;if (y == len(str2)+1) return len(str1)-x+1;if (str1 == str2)
return LevensteinDistance(str1, str2, x+ 1, y+ 1);return 1 + min(LevensteinDistance(str1, str2, x, y+ 1), #insert LevensteinDistance(str1, str2, x+ 1, y), #remove LevensteinDistance(str1, str2, x+ 1, y+ 1) #replace
}
LevenesteinDistance('abcd','abbd',1,1)
Azt tesszük, hogy a karakterláncok olvasását az 1. karaktertől kezdjük
- Ha a str1 ‘x’ indexén lévő karakter megegyezik a str2 ‘y’ indexén lévő karakterrel, nincs szükség szerkesztésre & kiszámítjuk a szerkesztési távolságot a
LevensteinDistance(str1,str2)
- Ha nem egyeznek, akkor tudjuk, hogy szerkesztésre van szükség. Tehát +1-et adunk az aktuális edit_távolsághoz & rekurzívan kiszámítja az edit_távolságot 3 feltételre & a háromból a minimumot veszi ki:
Levenstein(str1,str2) →beillesztés str2-be.
Levenstein(str1,str2) →eltávolítás str2-ben
Levenstein(str1,str2)→helyettesítés str2-ben
- Ha rekurzió közben bármelyik karakterláncból kifogynak a karakterek, a másik karakterláncban megmaradt karakterek hossza hozzáadódik a szerkesztési távolsághoz (az 1. két if utasítás)
Demerau-Levenstein távolság
Figyeljünk ‘abcd’ & ‘acbd’. Ha a Levenstein-távolság szerint megyünk, akkor ez a következő lenne (cserélje ki a ‘b’-‘c’ & ‘c’-‘b’ indexpozíciókban 2 & 3 az str2-ben) De ha jobban megnézzük, mindkét karakter felcserélődött, mint az str1-ben & ha bevezetünk egy új műveletet ‘Swap’ az ‘addition’, ‘ deletion’ & ‘replace’ mellett, akkor ez a probléma megoldható. Ez a bevezetés segíthet megoldani az olyan problémákat, mint az ‘Agarwal’ & ‘Agrawal’.
Ezt a műveletet az alábbi pszeudokóddal adjuk hozzá
1 +
(x - last_matching_index_y - 1 ) +
(y - last_matching_index_x - 1 ) +
LevinsteinDistance(str1, str2)
Futtassuk a fenti műveletet az ‘abcd’ & ‘acbd’-re, ahol feltételezzük
initial_x=1 & initial_y=1 (Az indexelést 1-től & nem 0-tól kezdjük mindkét string esetében).
current x=3 & y=3 tehát str1 & str2 a ‘c’ (abcd) & ‘b’ (acbd) értékeken.
A felső határokat tartalmazza az alább említett szeletelési művelet. Ezért a ‘qwerty’ jelentése ‘qwer’ lesz.
- last_matching_index_y lesz az utolsó_index a str2-ben, amely illeszkedett a str1-hez, azaz 2, mivel ‘c’ az ‘acbd’-ben (index 2)illeszkedett a ‘c’-hez az ‘abcd’-ben.
- last_matching_index_x lesz az utolsó_index a str1-ben, amely illeszkedett a str2-hez i.e 2 mint ‘b’ az ‘abcd’-ben (index 2)megegyezik ‘b’-vel az ‘acbd’-ben.
- A fenti pszeudokódot követve tehát DemarauLevenstein(‘abc’,’acb’)=
1+(4-3-1) + (4-3-1)+LevensteinDistance(‘a’,’a’)=1+0+0+0+0=1. Ez 2 lett volna, ha a Levenstein-távolságot
N-gramma
követjük Az N-gramma alapvetően nem más, mint egy karakterláncból egymás után előforduló ‘n’ karakter/szó párosításával előállított értékek halmaza. Például: n-gram n=2-vel az ‘abcd’ esetében az ‘ab’,’bc’,’cd’ lesz.
Most, ezeket az n-grammokat olyan karakterláncokhoz lehet generálni, amelyek hasonlóságát mérni kell & különböző metrikákat lehet használni a hasonlóság mérésére.
Legyen ‘abcd’ & ‘acbd’ 2 illesztendő string.
n-gramok n=2-vel
‘abcd’=ab,bc,cd
‘acbd’=ac,cb,bd
Komponens egyezés (qgramok)
A két stringre pontosan illeszkedő n-gramok száma. Itt ez 0 lenne
Kozinus hasonlóság
Pontproduktum kiszámítása a karakterláncokhoz generált n-grammok vektorokká alakítása után
Komponensillesztés (sorrendet nem veszünk figyelembe)
N-grammok komponenseinek illesztése, figyelmen kívül hagyva az elemek sorrendjét, pl. bc=cb.
Létezik még sok más ilyen mérőszám, mint a Jaccard távolság, Tversky index, stb. amelyeket itt nem tárgyaltunk.
BK fa
A BK fa a leggyorsabb algoritmusok közé tartozik, amelyekkel egy adott stringhez hasonló stringeket találhatunk (egy string-állományból). A BK fa a
- Levenstein-távolságot
- Háromszögegyenlőtlenséget használja (a fejezet végére erről is lesz szó)
a hasonló karakterláncok kitalálásához (& nem csak egy legjobb karakterláncot).
A BK fa egy rendelkezésre álló szótárból származó szóállomány felhasználásával jön létre. Tegyük fel, hogy van egy D={Book, Books, Books, Cake, Boo, Boon, Cook, Cape, Cart}
A BK fa a következő módon jön létre:
- Kiválasztunk egy gyökércsomópontot (lehet bármilyen szó). Legyen ez ‘Könyvek’
- Menjünk végig a D szótár minden W szaván, számítsuk ki a Levenstein-távolságát a gyökércsomóponttal, és tegyük a W szót a gyökér gyermekévé, ha a szülőnek nincs olyan gyermeke, amelynek Levenstein-távolsága megegyezik. Könyvek beillesztése & Sütemény.
Levenstein(Könyvek,Könyv)=1 & Levenstein(Könyvek,Sütemény)=4. Mivel a ‘Könyv’ számára nem találtunk azonos távolsággal rendelkező gyermeket, tegyük őket a gyökér új gyermekeivé.
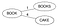
- Ha a P szülőhöz létezik azonos Levenstein-távolságú gyermek, most tekintsük ezt a gyermeket a W szó P1 szülőjének, számítsuk ki a Levenstein(szülő, szó) értéket, és ha a P1 szülőnek nincs azonos távolsággal rendelkező gyermeke, akkor tegyük a W szót a P1 új gyermekévé, különben folytassuk a fán lefelé haladva.
Megfontolandó a Boo beillesztése. Levenstein(Könyv, Boo)=1, de már létezik egy ugyanolyan gyermek, azaz Könyvek. Ezért most számítsuk ki, hogy Levenstein(Könyvek, Boo)=2. Mivel a Booksnak nincs azonos távolságú gyermeke, tegyük Boo-t a Books gyermekévé.

Hasonlóan, a szótárból az összes szót beillesztjük a BK fába

Amikor a BK fa elkészült, egy adott szóhoz (Query word) hasonló szavak kereséséhez be kell állítanunk egy tolerancia_küszöböt, mondjuk ‘t’.
- Ez a maximális edit_distance, amelyet figyelembe veszünk bármely csomópont & query_word közötti hasonlósághoz. Minden e fölötti értéket elutasítunk.
- Ezeken kívül csak azokat a szülő csomópont gyermekeit fogjuk figyelembe venni a Query-vel való összehasonlításhoz, ahol a Levenstein(Child, Parent) belül van
miért? ezt rövidesen tárgyalni fogjuk
- Ha ez a feltétel igaz egy gyermekre, akkor csak akkor fogjuk kiszámítani a Levenstein(gyermek, lekérdezés) értéket, amelyet akkor tekintünk a lekérdezéshez hasonlónak, ha
Levenshtein(gyermek, lekérdezés)≤t.
- Ezért nem fogjuk kiszámítani a Levenstein-távolságot az összes csomópontra/szóra a szótárban a lekérdezés szóval & így sok időt takarítunk meg, amikor a szóállomány hatalmas
Ezért, ahhoz, hogy egy Child hasonló legyen a Queryhez, ha
- Levenstein(Parent, Query)-t ≤ Levenstein(Child,Parent) ≤ Levenstein(Parent,Query)+t
- Levenstein(Child,Query)≤t
Menjünk át gyorsan egy példán. Legyen ‘t’=1
Legyen a szó, amelyhez hasonló szavakat kell találnunk, a ‘Care’ (Query szó)
- Levenstein(Book,Care)=4. Mivel 4>1, a ‘Könyv’ elvetésre kerül. Most csak a ‘Book’ azon gyermekeit vesszük figyelembe, amelyek LevisteinDistance(Child,’Book’) értéke 3(4-1) & 5(4+1) között van. Ezért a ‘Könyv’ & összes gyermekét elutasítjuk, mivel az 1 nem fekszik a határértékkészletben
- Mivel Levenstein(Sütemény, Könyv)=4, amely 3 & 5 között fekszik, a Levenstein(Sütemény, Gondozás)=1-et fogjuk ellenőrizni, amely ≤1, tehát egy hasonló szó.
- A határokat újra beállítva, Cake gyermekei esetében 0(1-1) & 2(1+1)
- Mivel mindkét Cape & Cart rendelkezik Levenstein(Child, Parent)=1 & 2-vel, mindkettő jogosult arra, hogy a ‘Care’-vel vizsgáljuk.
- Mivel Levenstein(Cape,Care)=1 ≤1& Levenstein(Cart,Care)=2>1, csak Cape tekinthető hasonló szónak a ‘Care’-hez.
Ezért találtunk 2 hasonló szót a ‘Care’-hez, amelyek a következők: Cake & Cape
De mi alapján döntünk a határok felett
Levenstein(Parent,Query)-t, Levenstein(Parent,Query)+t.
minden gyermek csomópont esetében?
Ez a háromszögegyenlőtlenségből következik, amely szerint
Távolság(A,B) + Távolság(B,C)≥Távolság(A,C), ahol A,B,C egy háromszög oldalai.
Hogy ez a gondolat hogyan segít nekünk ezeknek a határértékeknek a megtalálásában, lássuk:
Legyen Query,=Q Parent=P & Child=C egy háromszöget alkot, amelynek Levenstein távolsága az élek hossza. Legyen ‘t’ a tolerancia_küszöbérték. Akkor a fenti egyenlőtlenség
Levenstein(P,C) + Levenstein(P,Q)≥Levenstein(C,Q)as Levenstein(C, Q) can't exceed 't'(threshold set earlier for C to be similar to Q), HenceLevenstein(P,C) + Levenstein(P,Q)≥ t
OrLevenstein(P,C)≥|Levenstein(P,Q)-t| i.e the lower limit is set
Még a háromszög egyenlőtlenség,
Levenstein(P,Q) + Levenstein(C,Q) ≥ Levenstein(P,C) or
Levenstein(P,Q) + t ≥ Levenstein(P,C) or the upper limit is set
Bitap algoritmus
Ez is egy nagyon gyors algoritmus, amely elég hatékonyan használható fuzzy string illesztésre. Ez azért van, mert bitenkénti műveleteket használ & mivel ezek elég gyorsak, az algoritmus a gyorsaságáról ismert. Kicsit sem vesztegetve az időt, kezdjük el:
Legyen S0=’ababc’ az S1=’abdababababc’ karakterlánccal illesztendő minta.
Először is,
- Kitaláljuk S1 & S0 összes egyedi karakterét, amelyek a,b,c,d
- Képezzünk bitmintát minden karakterhez. Hogyan?

- Megfordítjuk a keresendő S0 mintát
- Az x karakterhez tartozó bitmintához tegyünk 0-t, ahol a mintában előfordul, máshol 1-et. A T-ben az ‘a’ a 3. & 5. helyen fordul elő, ezeken a helyeken 0-t helyeztünk el & a többi 1.
Hasonlóképpen alakítsuk ki az összes többi bitmintát a szótár különböző karaktereihez.
S0=ababc S1=abdababababc
- Vegyük egy(S0) hosszúságú bitminta kezdeti állapotát, amelyben minden 1 van. Esetünkben ez 11111 lenne (S állapot).
- Amint az S1-ben kezdjük a keresést és áthaladunk bármely karakteren,
a legalsó bitnél, azaz az S-ben jobbról az 5. bitnél &
VAGY művelet S-en T-vel.
Amint tehát az S1-ben az 1. ‘a’-val találkozunk, akkor
- balra tolunk egy 0-t az S-ben a legalsó bitnél, hogy 11111 →11110
- 11010 | 11110=11110
Most, ahogy a 2. ‘b’-re lépünk
- Shift 0-t az S-ben i.e, hogy 11110 →11100
- S |T=11100 | 10101=11101
Amint a ‘d’-vel találkozunk
- Shift 0-t S-re, hogy 11101 →11010
- S |T=11010 |11111=11111
Nézzük meg, hogy mivel a ‘d’ nincs az S0-ban, az S állapot visszaáll. Ha végigjárjuk a teljes S1-et, minden egyes karakternél az alábbi állapotokat kapjuk

Honnan tudom, hogy találtam-e fuzz/teljes egyezést?
- Ha egy 0 eléri az S állapot bitmintázatának legfelső bitjét (mint az utolsó ‘c’ karakterben), akkor teljes egyezést kaptunk
- A fuzz egyezéshez figyeljük meg a 0-t az S állapot különböző pozícióiban. Ha a 0 a 4. helyen van, akkor 4/5 karaktert találtunk ugyanabban a sorrendben, mint az S0-ban. Ugyanígy a többi helyen lévő 0 esetében is.
Egy dolgot talán megfigyelhettél, hogy ezek az algoritmusok mind a karakterláncok helyesírási hasonlóságán dolgoznak. Létezhet más kritérium is a fuzzy megfeleltetéshez? Igen,
Fonetikai
A következőkben a fonetikai(hangalapú, mint Saurav & Sourav, pontos egyezés kell a fonetikában) alapú fuzzy match algoritmusokkal fogunk foglalkozni !!!
- Dimenzion Reduction (3 rész)
- NLP algoritmusok(5 rész)
- Reinforcement Learning Basics (5 rész)
- Kezdve az idő-Series (7 rész)
- Object Detection using YOLO (3 rész)
- Tensorflow for beginners (concepts + Examples) (4 rész)
- Preprocessing Time Series (with codes)
- Data Analytics for beginners
- Statistics for beginners (4 rész)