- Introduction
- Cél
- A. Szűrő módszerek
- Chi-négyzet teszt
- Fisher-pontszám
- Korrelációs együttható
- Variancia küszöb
- Mean Absolute Difference (MAD)
- Diszperziós arány
- B. Wrapper módszerek:
- Forward Feature Selection
- Backward Feature Elimination
- Exhaustive Feature Selection
- Rekurzív jellemzőelimináció
- C. Beágyazott módszerek:
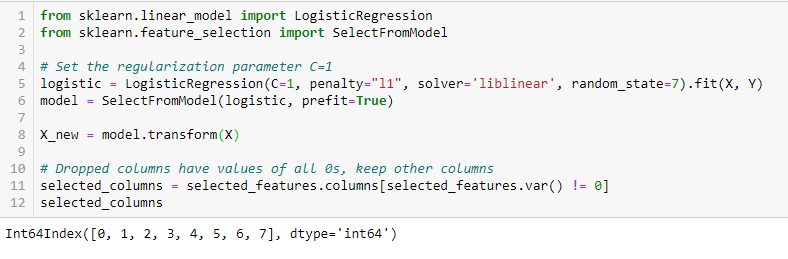
- LASSO Regularizáció (L1)
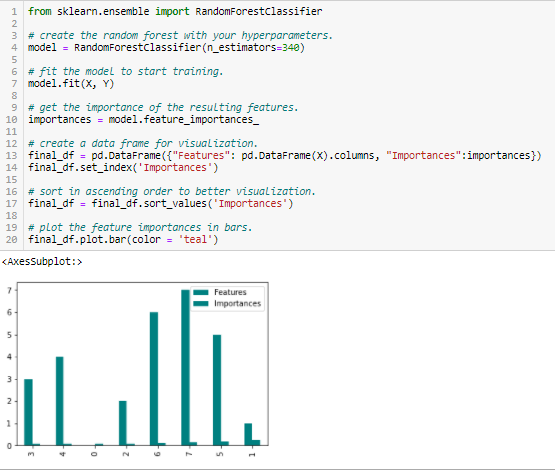
- Random Forest Importance
- Következtetés
Introduction
A gépi tanulási modell építése során a való életben szinte ritkán fordul elő, hogy az adathalmazban lévő összes változó hasznos a modell felépítéséhez. A redundáns változók hozzáadása csökkenti a modell általánosítási képességét, és csökkentheti az osztályozó általános pontosságát is. Továbbá egyre több változó hozzáadása a modellhez növeli a modell általános összetettségét.
Az “Occam borotvája” parszimónia törvénye szerint egy problémára az a legjobb magyarázat, amely a lehető legkevesebb feltételezést tartalmazza. Így a jellemzőkiválasztás a gépi tanulás modellépítésének elengedhetetlen részévé válik.
Cél
A gépi tanulásban a jellemzőkiválasztás célja, hogy megtaláljuk a legjobb jellemzőkészletet, amely lehetővé teszi a vizsgált jelenségek hasznos modelljének felépítését.
A gépi tanulásban a jellemzőkiválasztás technikái nagyjából a következő kategóriákba sorolhatók:
Supervizált technikák:
Felügyelet nélküli technikák: Ezek a technikák címkézett adatokhoz használhatók, és a releváns jellemzők azonosítására szolgálnak a felügyelt modellek, például az osztályozás és a regresszió hatékonyságának növelése érdekében.
Felügyelet nélküli technikák: Ezek a technikák címkézetlen adatokhoz használhatók.
Taxonómiai szempontból ezek a technikák a következők szerint osztályozhatók:
A. Szűrési módszerek
B. Wrapper módszerek
C. Beágyazott módszerek
D. Hibrid módszerek
Ebben a cikkben a gépi tanulásban a jellemzőválasztás néhány népszerű technikáját tárgyaljuk.
A. Szűrő módszerek
A szűrő módszerek a keresztvalidációs teljesítmény helyett az egyváltozós statisztikával mért jellemzők saját tulajdonságait veszik fel. Ezek a módszerek gyorsabbak és kevésbé számításigényesek, mint a wrapper módszerek. Nagydimenziós adatok kezelése esetén számítási szempontból olcsóbb a szűrőmódszerek használata.
Legyen, beszéljünk néhány ilyen technikáról:
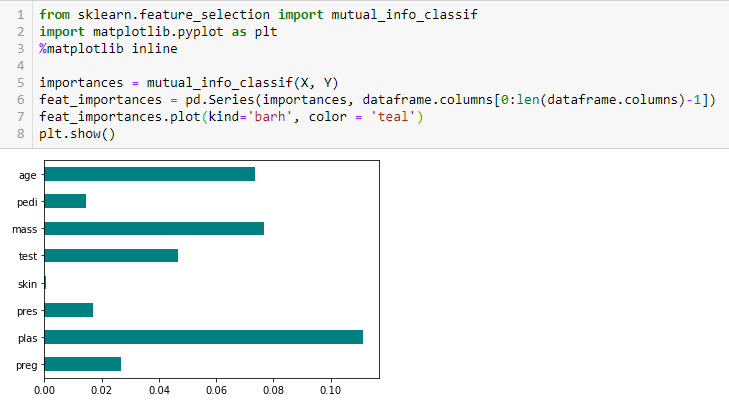
Információnyereség
Az információnyereség kiszámítja az adathalmaz átalakításából származó entrópiacsökkenést. Jellemzők kiválasztására használható az egyes változók információnyereségének a célváltozóval összefüggésben történő kiértékelésével.
Chi-négyzet teszt
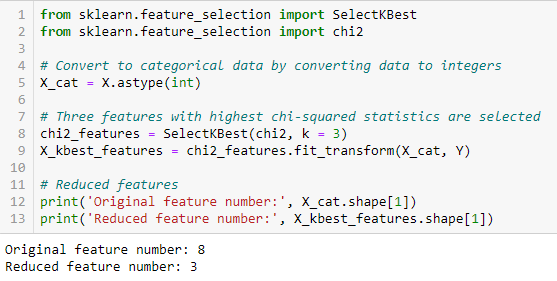
A Chi-négyzet tesztet egy adathalmaz kategorikus jellemzőire használjuk. Ki-négyzetet számolunk az egyes jellemzők és a célváltozó között, és kiválasztjuk a legjobb Ki-négyzet-értékkel rendelkező jellemzők kívánt számát. Ahhoz, hogy a Chi-négyzetet helyesen alkalmazzuk az adathalmaz különböző jellemzői és a célváltozó közötti kapcsolat tesztelésére, a következő feltételeknek kell teljesülniük: a változóknak kategorikusnak kell lenniük, függetlenül kell mintavételezni őket, és az értékek várható gyakoriságának nagyobbnak kell lennie, mint 5.
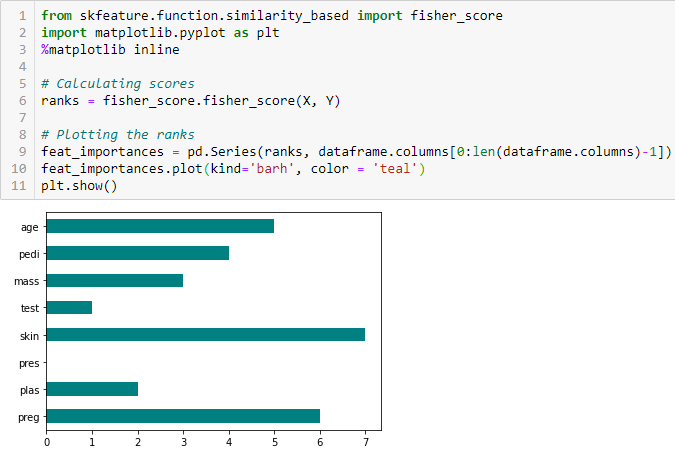
Fisher-pontszám
A Fischer-pontszám az egyik legszélesebb körben használt felügyelt jellemzőválasztási módszer. Az általunk használt algoritmus a változók rangsorát a fisher’s score alapján adja vissza csökkenő sorrendben. Ezután az esetnek megfelelően kiválaszthatjuk a változókat.
Korrelációs együttható
A korreláció 2 vagy több változó lineáris kapcsolatának mérőszáma. A korreláció révén az egyik változót meg tudjuk jósolni a másikból. A korreláció használatának logikája a jellemző kiválasztásához az, hogy a jó változók nagymértékben korrelálnak a célváltozóval. Továbbá a változóknak korrelálniuk kell a céllal, de egymás között nem szabad korrelálniuk.
Ha két változó korrelál, akkor az egyiket meg tudjuk jósolni a másikból. Ezért, ha két jellemző korrelál, a modellnek valójában csak az egyikre van szüksége, mivel a második nem ad hozzá további információt. Itt a Pearson-korrelációt fogjuk használni.
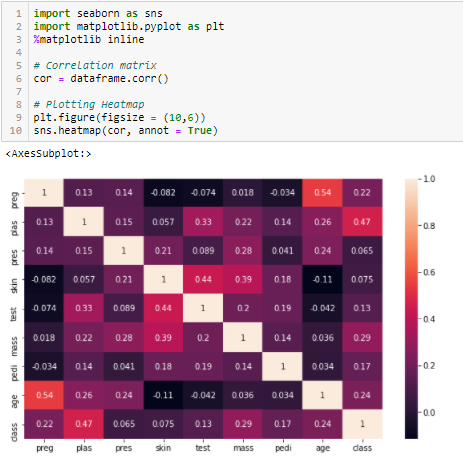
A változók kiválasztásának küszöbértékeként egy abszolút értéket, mondjuk 0,5-öt kell megadnunk. Ha úgy találjuk, hogy a prediktorváltozók korrelálnak egymással, akkor elhagyhatjuk azt a változót, amelynek alacsonyabb a korrelációs együttható értéke a célváltozóval. Többszörös korrelációs együtthatókat is kiszámíthatunk annak ellenőrzésére, hogy kettőnél több változó korrelál-e egymással. Ezt a jelenséget multikollinearitásnak nevezzük.
Variancia küszöb
A variancia küszöb a jellemzőválasztás egyszerű alapmegközelítése. Eltávolít minden olyan jellemzőt, amelynek varianciája nem felel meg valamilyen küszöbértéknek. Alapértelmezés szerint eltávolítja az összes nulla varianciájú jellemzőt, azaz azokat a jellemzőket, amelyek minden mintában azonos értékkel rendelkeznek. Feltételezzük, hogy a nagyobb varianciájú jellemzők több hasznos információt tartalmazhatnak, de megjegyezzük, hogy nem vesszük figyelembe a jellemzőváltozók vagy a jellemző és a célváltozók közötti kapcsolatot, ami a szűrőmódszerek egyik hátránya.

A get_support egy bólusvektort ad vissza, ahol a True azt jelenti, hogy a változónak nem nulla a varianciája.
Mean Absolute Difference (MAD)
‘Az átlagos abszolút különbség (MAD) kiszámítja az abszolút különbséget az átlagértéktől. A fő különbség a variancia és a MAD mértékek között az, hogy az utóbbiban nincs négyzet. A MAD, akárcsak a variancia, szintén egy skálaváltozat’. Ez azt jelenti, hogy minél nagyobb a MAD, annál nagyobb a diszkriminációs erő.”
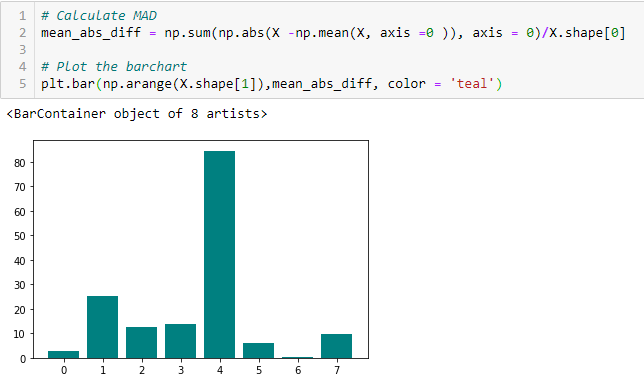
Diszperziós arány
‘A szórás másik mérőszáma az aritmetikai átlagot (AM) és a geometriai átlagot (GM) alkalmazza. Egy adott (pozitív) Xi tulajdonságra n mintán az AM és a GM a
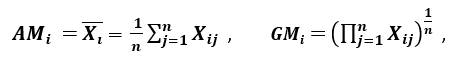
szerint adódik; mivel AMi ≥ GMi, az egyenlőség akkor és csak akkor áll fenn, ha Xi1 = Xi2 = …. = Xin, akkor az arány
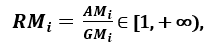
szórásmértékként használható. A nagyobb szórás magasabb Ri értéket, tehát relevánsabb jellemzőt jelent. Ezzel szemben, ha az összes jellemzőminta (nagyjából) azonos értékkel rendelkezik, az Ri közel 1, ami alacsony relevanciájú jellemzőt jelez’.

 ‘
‘
B. Wrapper módszerek:
A burkolóknak szükségük van valamilyen módszerre a jellemzők összes lehetséges részhalmazának terében való keresésre, a minőségük értékelésére egy osztályozó tanulásával és kiértékelésével az adott jellemző részhalmazzal. A jellemzőválasztási folyamat alapja egy adott gépi tanulási algoritmus, amelyet egy adott adathalmazra próbálunk illeszteni. Ez egy mohó keresési megközelítést követ a jellemzők összes lehetséges kombinációjának az értékelési kritériummal szembeni értékelésével. A wrapper módszerek általában jobb előrejelzési pontosságot eredményeznek, mint a szűrő módszerek.
Lássuk, tárgyaljunk néhányat ezek közül a technikák közül:
Forward Feature Selection
Ez egy iteratív módszer, amelyben a legjobban teljesítő változóval kezdünk a célhoz képest. Ezután kiválasztunk egy másik változót, amely az első kiválasztott változóval kombinálva a legjobb teljesítményt nyújtja. Ez a folyamat addig folytatódik, amíg az előre meghatározott kritériumot el nem érjük.
Backward Feature Elimination
Ez a módszer pontosan ellentétesen működik, mint a Forward Feature Selection módszer. Itt az összes rendelkezésre álló jellemzővel kezdünk, és felépítünk egy modellt. Ezután a modellből kivesszük azt a változót, amelyik a legjobb értékmérő értéket adja. Ezt a folyamatot addig folytatjuk, amíg az előre beállított kritériumot el nem érjük.
Ezt a módszert a fentebb tárgyalt módszerrel együtt szekvenciális funkcióválasztási módszernek is nevezik.
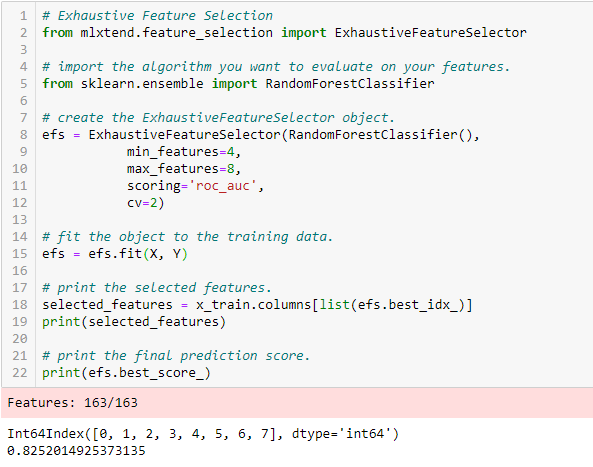
Exhaustive Feature Selection
Ez az eddig tárgyalt legrobosztusabb funkcióválasztási módszer. Ez az egyes feature részhalmazok nyers erővel történő kiértékelését jelenti. Ez azt jelenti, hogy a változók minden lehetséges kombinációját kipróbálja, és a legjobban teljesítő részhalmazt adja vissza.
Rekurzív jellemzőelimináció
‘Adott egy külső becslő, amely súlyokat rendel a jellemzőkhöz (pl. egy lineáris modell együtthatói), a rekurzív jellemzőelimináció (RFE) célja a jellemzők kiválasztása a jellemzők egyre kisebb és kisebb halmazainak rekurzív figyelembevételével. Először a becslőt a jellemzők kezdeti halmazán képezzük ki, és az egyes jellemzők fontosságát vagy egy coef_ attribútumon vagy egy feature_importances_ attribútumon keresztül kapjuk meg.
Ezután a legkevésbé fontos jellemzőket kivágjuk az aktuális jellemzőhalmazból. Ezt az eljárást rekurzívan megismételjük a metszett halmazon, amíg végül elérjük a kiválasztandó jellemzők kívánt számát.”
C. Beágyazott módszerek:
Ezek a módszerek magukban foglalják mind a wrapper, mind a szűrő módszerek előnyeit azáltal, hogy magukban foglalják a jellemzők kölcsönhatásait, ugyanakkor ésszerű számítási költségeket tartanak fenn. A beágyazott módszerek iteratívak abban az értelemben, hogy gondoskodik a modell képzési folyamatának minden egyes iterációjáról, és gondosan kivonja azokat a jellemzőket, amelyek a leginkább hozzájárulnak az adott iteráció képzéséhez.
Legyen, tárgyaljunk néhány ilyen technikát ide kattintva:
LASSO Regularizáció (L1)
A szabályozás abból áll, hogy a gépi tanulási modell különböző paramétereihez büntetést adunk hozzá a modell szabadságának csökkentése, azaz a túlillesztés elkerülése érdekében. A lineáris modell regularizálásakor a büntetést az egyes prediktorokat szorzó együtthatókra alkalmazzák. A különböző típusú regularizációk közül a Lasso vagy L1 rendelkezik azzal a tulajdonsággal, hogy képes néhány együtthatót nullára zsugorítani. Ezért ez a jellemző eltávolítható a modellből.
Random Forest Importance
A Random Forest egyfajta zsákoló algoritmus, amely meghatározott számú döntési fát aggregál. A véletlen erdők által használt fa alapú stratégiák természetesen aszerint rangsorolnak, hogy mennyire javítják a csomópont tisztaságát, vagy más szóval a tisztátalanság (Gini tisztátalanság) csökkenését az összes fa felett. A legnagyobb tisztaságcsökkenéssel rendelkező csomópontok a fák elején, míg a legkisebb tisztaságcsökkenéssel rendelkező csomópontok a fák végén fordulnak elő. Így egy adott csomópont alatti fák metszésével létrehozhatjuk a legfontosabb jellemzők részhalmazát.
Következtetés
Megbeszéltünk néhány technikát a jellemzők kiválasztására. Szándékosan elhagytuk az olyan jellemző-kiválasztási technikákat, mint a főkomponens-elemzés, a szinguláris érték dekompozíció, a lineáris diszkriminancia-elemzés stb. Ezek a módszerek segítenek az adatok dimenzionalitásának csökkentésében vagy a változók számának csökkentésében, miközben megőrzik az adatok varianciáját.
A fent tárgyalt módszereken kívül számos más módszer is létezik a jellemzők kiválasztására. Léteznek hibrid módszerek is, amelyek szűrési és csomagolási technikákat is alkalmaznak. Ha többet szeretne megtudni a feature selection technikákról, nagyszerű átfogó olvasmány véleményem szerint a ‘Feature Selection for Data and Pattern Recognition’ című könyv, melyet Urszula Stańczyk és Lakhmi C. Jain.