- A függvény és a deriváltja is monoton
- A kimenet nulla “centrikus”
- A optimalizálás könnyebb
- A Tanh függvény (f'(x)) deriváltja /Differenciálja 0 és 1 között lesz.
Hátrányok:
- A Tanh függvény deriváltja szenved a “Vanishing gradient and Exploding gradient problem”-tól.
- Lassú konvergencia- mivel számításigényes.(Az exponenciális matematikai függvény használatának oka )
“A Tanh függvényt előnyben részesítjük a szigmoid függvénnyel szemben, mivel nulla központú és a gradiensek nem korlátozódnak egy bizonyos irányba való mozgásra”
3. ReLu aktiválási függvény (ReLu – Rectified Linear Units):


A ReLu a nemlineáris aktiválási függvény, amely népszerűvé vált a mesterséges intelligenciában. A ReLu függvényt úgy is ábrázolják, hogy f(x) = max(0,x).
- A függvény és a deriváltja is monoton.
- A ReLU függvény használatának fő előnye- Nem aktiválja az összes neuront egyszerre.
- Számítási szempontból hatékony
- A Tanh függvény (f'(x)) deriváltja /Differenciálja 1 lesz, ha f(x) > 0 egyébként 0.
- Konvertálódik nagyon gyorsan
Hátrányok:
- A ReLu függvény nem “nulla-centrikus”.emiatt a gradiens frissítések túl messzire mennek különböző irányokba. 0 < kimenet < 1, és ez megnehezíti az optimalizálást.
- A halott neuron a legnagyobb probléma.ez annak köszönhető, hogy nem differenciálható nullánál.
“Problem of Dying neuron/Dead neuron : Mivel a ReLu f'(x) deriváltja nem 0 a neuron pozitív értékeire (f'(x)=1 for x ≥ 0), a ReLu nem telítődik (exploid) és nincs halott neuron (Vanishing neuron). Telítődés és eltűnő gradiens csak negatív értékek esetén fordul elő, amelyek a ReLu-nak adva 0-ra változnak- Ezt nevezzük a haldokló neuron problémájának.”
4. Szivárgó ReLu aktivációs függvény:
A szivárgó ReLU-függvény nem más, mint a ReLU-függvény továbbfejlesztett változata az “állandó meredekség” bevezetésével”


- Leaky ReLU a haldokló neuron/halott neuron problémájának kezelésére definiált.
- A haldokló neuron/halott neuron problémáját egy kis meredekség bevezetésével kezeljük, amelynek negatív értékei α-val skálázva lehetővé teszik a megfelelő neuronok “életben maradását”.
- A függvény és a deriváltja is monoton
- Megengedi a negatív értéket a visszaterjedés során
- Ez hatékony és könnyen kiszámítható.
- A Leaky deriváltja 1, ha f(x) > 0, és 0 és 1 között mozog, ha f(x) < 0.
Hátrányok:
- A Leaky ReLU nem ad konzisztens előrejelzést negatív bemeneti értékekre.
5. ELU (Exponenciális lineáris egységek) aktiválási függvény:

- ELU is javasolt a haldokló neuron problémájának megoldására.
- Nincs Halott ReLU probléma
- Nulla központú
Hátrányok:
- számításigényes.
- A Leaky ReLU-hoz hasonlóan, bár elméletileg jobb, mint a ReLU, a gyakorlatban jelenleg nincs jó bizonyíték arra, hogy az ELU mindig jobb, mint a ReLU.
- f(x) csak akkor monoton, ha alfa nagyobb vagy egyenlő 0-val.
- f'(x) ELU deriváltja csak akkor monoton, ha alfa 0 és 1 között van.
- Lassú konvergencia az exponenciális függvény miatt.
6. P ReLu (Parametrikus ReLU) Aktiválási függvény:

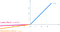
- A szivárgó ReLU gondolata még tovább bővíthető.
- Ahelyett, hogy x-et megszorozzuk egy konstans kifejezéssel, megszorozhatjuk egy “hiperparaméterrel (a-tanítható paraméter)”, ami úgy tűnik, jobban működik a leaky ReLU. A szivárgó ReLU ezen kiterjesztését Parametrikus ReLU-nak nevezik.
- A paraméter α általában egy 0 és 1 közötti szám, és általában viszonylag kicsi.
- A betanítható paraméter miatt enyhe előnye van a szivárgó Relu-val szemben.
- Kezeli a haldokló neuronok problémáját.
Hátrányok:
- Szerint a szivárgó Relu.
- f(x) monoton, ha a> vagy =0 és f'(x) monoton, ha a =1
7. Swish (A Self-Gated) Activation Function: (Sigmoid Linear Unit)

- A Google Brain Team egy új aktivációs függvényt javasolt, melynek neve Swish, ami egyszerűen f(x) = x – sigmoid(x).
- Kísérleteik azt mutatják, hogy a Swish általában jobban működik, mint a ReLU a mélyebb modelleken, számos kihívást jelentő adathalmazon keresztül.
- A Swish függvény görbéje sima, és a függvény minden ponton differenciálható. Ez hasznos a modelloptimalizálás során, és ez tekinthető az egyik oknak, amiért a Swish jobban teljesít a ReLU-nál.
- A Swish függvény “nem monoton”. Ez azt jelenti, hogy a függvény értéke akkor is csökkenhet, ha a bemeneti értékek növekednek.
- A függvény fent korlátlan és lent korlátos.
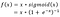
“A Swish hajlamos arra, hogy folyamatosan megegyezzen a ReLu-val vagy túlformálja azt”
Megjegyezzük, hogy a Swish függvény kimenete akkor is csökkenhet, ha a bemeneti értékek növekednek. Ez egy érdekes és swish-specifikus tulajdonság.(A nem monoton jelleg miatt)
f(x)=2x*sigmoid(béta*x)
Ha úgy gondoljuk, hogy a béta=0 a Swish egyszerű változata, ami egy tanulható paraméter, akkor a sigmoid rész mindig 1/2 és f (x) lineáris. Ha viszont a béta nagyon nagy érték, akkor a szigmoid közel kétszámjegyű függvénnyé válik (0, ha x<0,1, ha x>0). Így f (x) konvergál a ReLU függvényhez. Ezért a standard Swish függvényt választjuk béta = 1 értékkel. Ily módon lágy interpoláció (a változó értékkészleteket a megadott tartományban és a kívánt pontossággal rendelkező függvényhez társítva) biztosított. Kiváló! Megoldást találtunk a gradiensek eltűnésének problémájára.
8.Softplus
A softplus függvény hasonló a ReLU függvényhez, de viszonylag simább.A Softplus vagy SmoothRelu függvénye f(x) = ln(1+exp x).
A Softplus függvény deriváltja f'(x) logisztikus függvény (1/(1+exp x)).
A függvény értéke (0, + inf) között mozog.mind f(x), mind f'(x) monoton.
9.Softmax vagy normalizált exponenciális függvény:

A “softmax” függvény szintén egyfajta szigmoid függvény, de nagyon hasznos a többosztályos osztályozási problémák kezelésére.
“A softmax több szigmoid függvény kombinációjaként írható le.”
“A Softmax függvény visszaadja annak valószínűségét, hogy egy adatpont minden egyes osztályba tartozik.”
A többosztályos problémához való hálózatépítés során a kimeneti rétegben annyi neuron lenne, ahány osztály van a célban.”
Ha például három osztályunk van, akkor a kimeneti rétegben három neuron lenne. Tegyük fel, hogy a neuronok kimeneti értékei a következők: .A softmax függvényt ezekre az értékekre alkalmazva a következő eredményt kapjuk – . Ezek az egyes osztályokhoz tartozó adatpontok valószínűségét jelentik. Az eredményből megállapíthatjuk, hogy a bemenet az A osztályba tartozik.
“Vegyük észre, hogy az összes érték összege 1.”
Melyik a jobb ? Hogyan válasszuk ki a megfelelőt?
Hogy őszinte legyek, nincs kemény és gyors szabály az aktiválási függvény kiválasztására.Nem tudunk különbséget tenni az aktiválási függvények között.Minden aktiválási függvénynek megvannak a maga előnyei és hátrányai.Minden jó és rossz a nyomvonal alapján fog eldőlni.
De a probléma tulajdonságai alapján talán képesek vagyunk egy jobb választást tenni a hálózat könnyű és gyorsabb konvergenciája érdekében.
- A szimmoid függvények és kombinációik általában jobban működnek osztályozási problémák esetén
- A szimmoid és a tanh függvényeket néha kerüljük az eltűnő gradiens probléma miatt
- A modern korban széles körben használják a ReLU aktiválási függvényt.
- Hálózatainkban a ReLu miatt elhalt neuronok esetén a szivárgó ReLU függvény a legjobb választás
- A ReLU függvényt csak a rejtett rétegekben szabad használni
“Ökölszabályként kezdhetjük a ReLU függvény használatával, majd áttérhetünk más aktiválási függvényekre, ha a ReLU nem nyújt optimális eredményt”
.