Methode 1, schlecht: ORDER BY NEWID()
Einfach zu schreiben, aber es funktioniert wie heißer, heißer Müll, weil es den gesamten geclusterten Index scannt und NEWID() für jede Zeile berechnet:
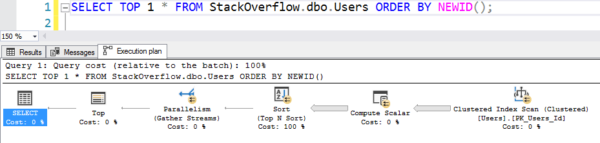
Der Plan mit dem Scan
Das dauerte 6 Sekunden auf meinem Rechner, parallel über mehrere Threads, und verbrauchte Dutzende von Sekunden CPU für all diese Berechnungen und Sortierungen. (Und die Tabelle „Benutzer“ ist nicht einmal 1 GB groß.)
Methode 2, besser aber seltsam: TABLESAMPLE
Diese Methode stammt aus dem Jahr 2005 und hat eine ganze Reihe von Problemen. Sie wählt eine zufällige Seite aus und gibt dann eine Reihe von Zeilen von dieser Seite zurück. Die erste Zeile ist irgendwie zufällig, aber der Rest nicht.
Transact-SQL
|
1
|
SELECT * FROM StackOverflow.dbo.Users TABLESAMPLE (.01 PERCENT);
|
Der Plan sieht aus, als ob er einen Tabellenscan durchführt, aber er führt nur 7 logische Lesevorgänge durch:
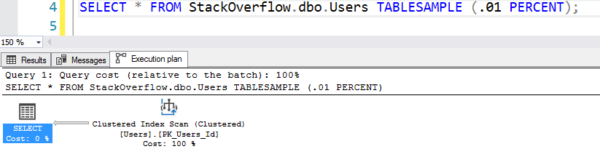
Der Plan mit dem Fake-Scan
Aber hier sind die Ergebnisse – Sie können sehen, dass er zu einer zufälligen 8K-Seite springt und dann beginnt, Zeilen der Reihe nach auszulesen. Es sind nicht wirklich zufällige Zeilen.
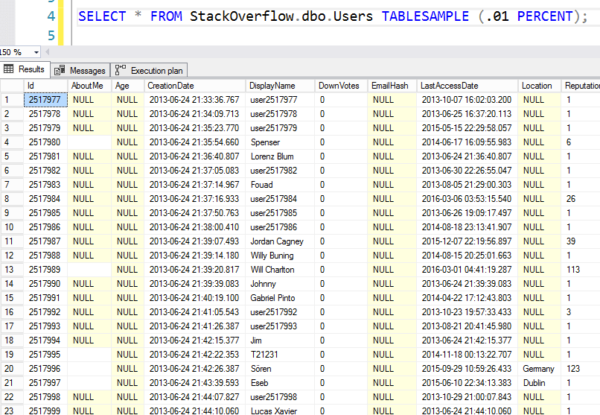
Zufällig wie Mafia-Lottozahlen
Sie können stattdessen die ROWS-Stichprobengröße verwenden, aber das führt zu ziemlich merkwürdigen Ergebnissen. Wenn ich zum Beispiel in der Tabelle Stack Overflow Users TABLESAMPLE (50 ROWS) sage, erhalte ich tatsächlich 75 Zeilen zurück. Das liegt daran, dass SQL Server die Zeilengröße stattdessen in einen Prozentsatz umwandelt.
Methode 3, am besten, aber erfordert Code: Zufälliger Primärschlüssel
Ermitteln Sie das oberste ID-Feld in der Tabelle, generieren Sie eine Zufallszahl und suchen Sie nach dieser ID. Hier sortieren wir nach der ID, weil wir den obersten Datensatz finden wollen, der tatsächlich existiert (wohingegen eine Zufallszahl gelöscht worden sein könnte.) Ziemlich schnell, aber nur für eine einzige zufällige Zeile geeignet. Wenn Sie 10 Zeilen wollten, müssten Sie Code wie diesen 10 Mal aufrufen (oder 10 Zufallszahlen erzeugen und eine IN-Klausel verwenden.)
Der Ausführungsplan zeigt einen geclusterten Index-Scan, aber er erfasst nur eine Zeile – wir sprechen hier von nur 6 logischen Lesevorgängen für alles, was Sie hier sehen, und er endet fast augenblicklich:

Der Plan, der es kann
Es gibt einen Haken: Wenn die Id negative Zahlen hat, funktioniert es nicht wie erwartet. (Nehmen wir an, Sie beginnen Ihr Identitätsfeld bei -1 und gehen einen Schritt nach unten, wie meine Moral.)
Methode 4, OFFSET-FETCH (2012+)
Daniel Hutmacher fügte dies in den Kommentaren hinzu:
Und sagte: „Aber es funktioniert nur mit einem geclusterten Index richtig. Ich vermute, das liegt daran, dass es nach (@rows)-Zeilen in einem Heap scannt, anstatt eine Indexsuche durchzuführen.“
Bonus Track #1: Schauen Sie uns bei der Diskussion zu
Haben Sie sich schon einmal gefragt, wie es ist, im Chatroom unserer Firma zu sein? Diese 10-minütige Slack-Diskussion gibt dir eine ziemlich gute Vorstellung davon:
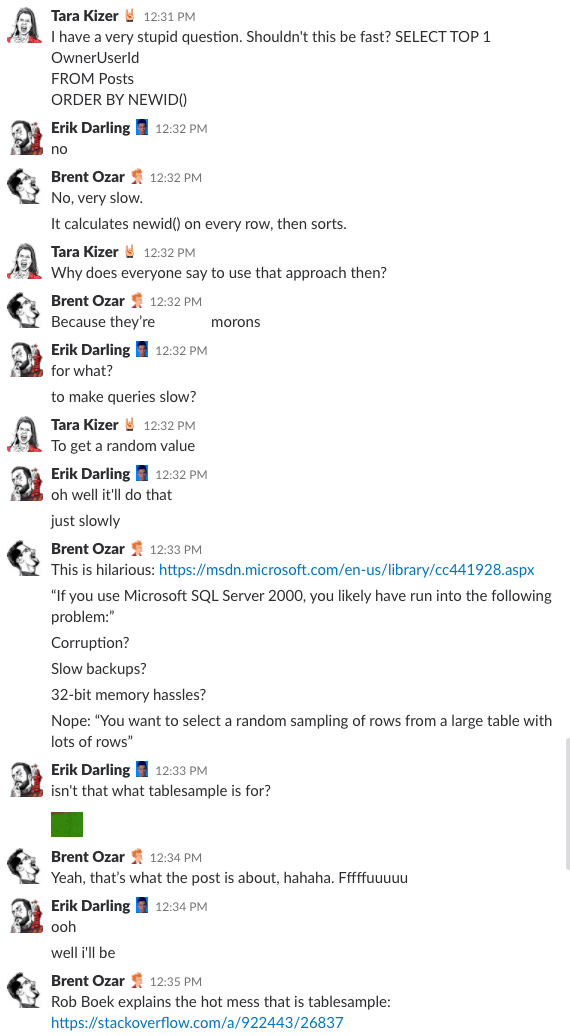
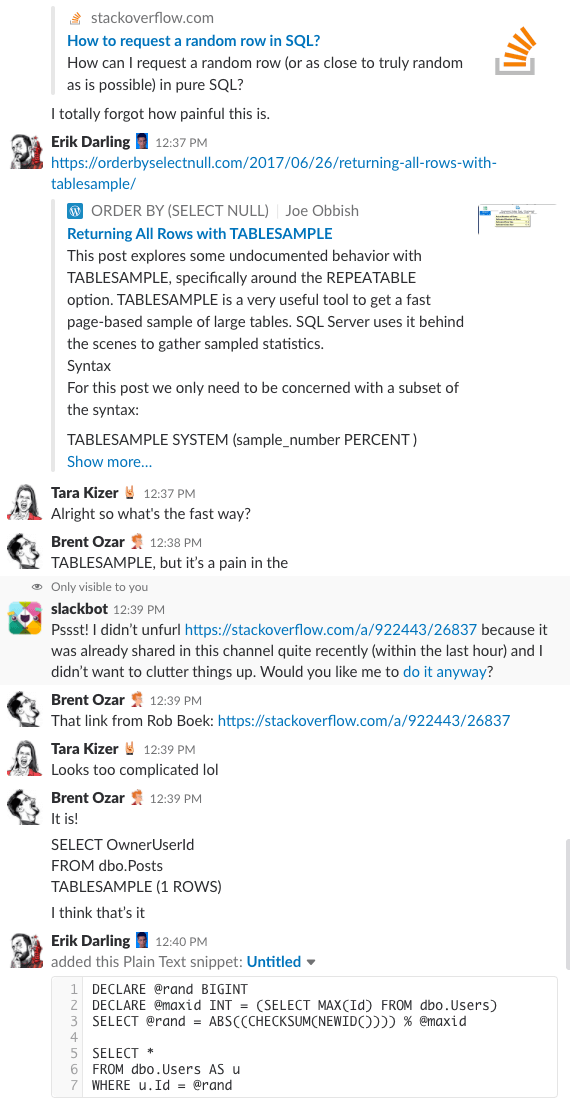
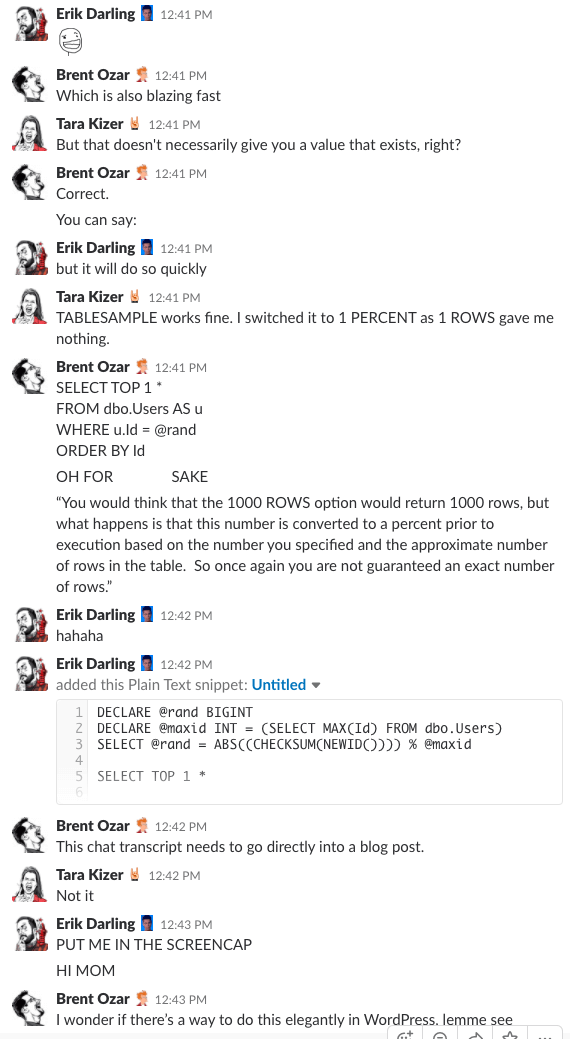
Spoiler-Alarm: Es gab keinen. Ich habe nur Screenshots gemacht.
Bonustrack #2: Mitch Wheat geht tiefer
Wollen Sie eine gründliche Analyse der Zufälligkeit verschiedener Techniken? Mitch Wheat geht wirklich in die Tiefe, komplett mit Diagrammen!