- Einführung
- Ziel
- A. Filtermethoden
- Chi-Quadrat-Test
- Fisher’s Score
- Korrelationskoeffizient
- Varianzschwelle
- Mittlere absolute Differenz (MAD)
- Dispersionsverhältnis
- B. Wrapper Methoden:
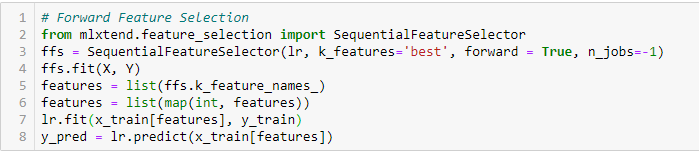
- Forward Feature Selection
- Backward Feature Elimination
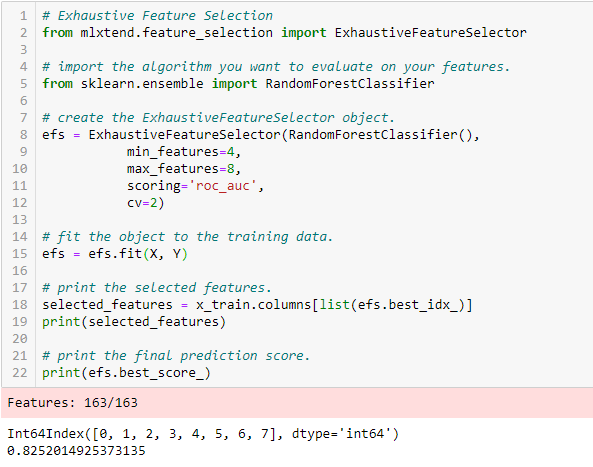
- Exhaustive Merkmalsauswahl
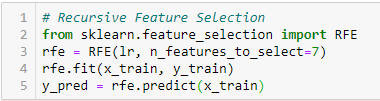
- Rekursive Merkmalseliminierung
- C. Eingebettete Methoden:
- LASSO Regularization (L1)
- Random Forest Importance
- Schlussfolgerung
Einführung
Bei der Erstellung eines maschinellen Lernmodells in der Praxis ist es fast selten, dass alle Variablen im Datensatz für die Erstellung eines Modells nützlich sind. Das Hinzufügen redundanter Variablen verringert die Generalisierungsfähigkeit des Modells und kann auch die Gesamtgenauigkeit eines Klassifikators verringern. Außerdem erhöht das Hinzufügen von immer mehr Variablen zu einem Modell die Gesamtkomplexität des Modells.
Nach dem Gesetz der Parsimonie von „Occam’s Razor“ ist die beste Erklärung für ein Problem diejenige, die die wenigsten Annahmen beinhaltet. Somit wird die Merkmalsauswahl zu einem unverzichtbaren Bestandteil der Erstellung von Modellen für maschinelles Lernen.
Ziel
Das Ziel der Merkmalsauswahl beim maschinellen Lernen ist es, die beste Menge von Merkmalen zu finden, die es ermöglicht, nützliche Modelle der untersuchten Phänomene zu erstellen.
Die Techniken für die Merkmalsauswahl beim maschinellen Lernen lassen sich grob in die folgenden Kategorien einteilen:
Überwachte Techniken: Diese Techniken können für gelabelte Daten verwendet werden und dienen dazu, die relevanten Merkmale zu identifizieren, um die Effizienz von überwachten Modellen wie Klassifizierung und Regression zu erhöhen.
Unüberwachte Techniken: Diese Techniken können für nicht beschriftete Daten verwendet werden.
Aus taxonomischer Sicht werden diese Techniken wie folgt klassifiziert:
A. Filtermethoden
B. Wrapper-Methoden
C. Eingebettete Methoden
D. Hybride Methoden
In diesem Artikel werden wir einige beliebte Techniken der Merkmalsauswahl beim maschinellen Lernen besprechen.
A. Filtermethoden
Filtermethoden greifen die intrinsischen Eigenschaften der Merkmale auf, die über univariate Statistiken anstelle der Kreuzvalidierungsleistung gemessen werden. Diese Methoden sind schneller und weniger rechenaufwändig als Wrapper-Methoden. Bei hochdimensionalen Daten ist es rechnerisch günstiger, Filtermethoden zu verwenden.
Lassen Sie uns einige dieser Techniken diskutieren:
Informationsgewinn
Informationsgewinn berechnet die Verringerung der Entropie durch die Transformation eines Datensatzes. Er kann für die Auswahl von Merkmalen verwendet werden, indem der Informationsgewinn jeder Variablen im Kontext der Zielvariablen bewertet wird.
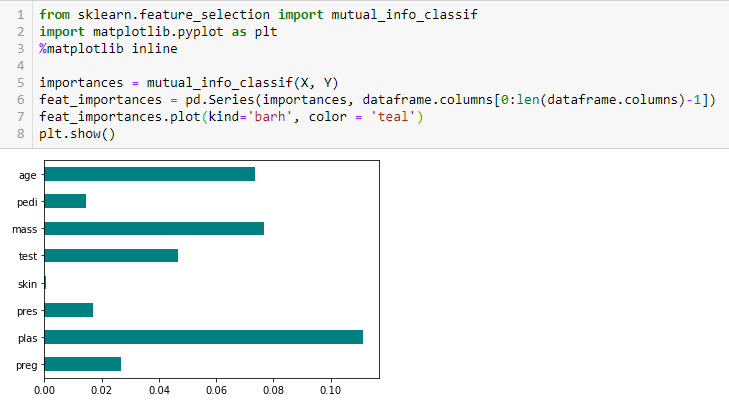
Chi-Quadrat-Test
Der Chi-Quadrat-Test wird für kategoriale Merkmale in einem Datensatz verwendet. Wir berechnen das Chi-Quadrat zwischen jedem Merkmal und dem Ziel und wählen die gewünschte Anzahl von Merkmalen mit den besten Chi-Quadrat-Werten aus. Um das Chi-Quadrat korrekt anwenden zu können, um die Beziehung zwischen verschiedenen Merkmalen im Datensatz und der Zielvariablen zu testen, müssen folgende Bedingungen erfüllt sein: Die Variablen müssen kategorisch sein, unabhängig abgetastet werden und die Werte sollten eine erwartete Häufigkeit von mehr als 5 haben.
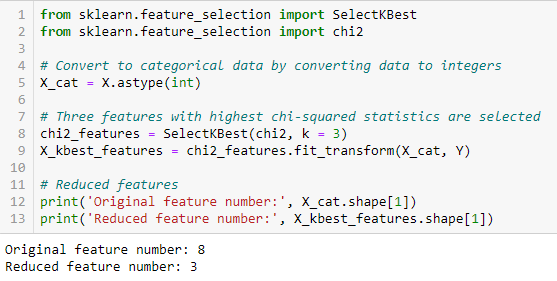
Fisher’s Score
Fisher’s Score ist eine der am häufigsten verwendeten überwachten Merkmalsauswahlmethoden. Der Algorithmus, den wir verwenden werden, liefert die Ränge der Variablen auf der Grundlage des Fisher’s Score in absteigender Reihenfolge. Wir können dann die Variablen je nach Fall auswählen.
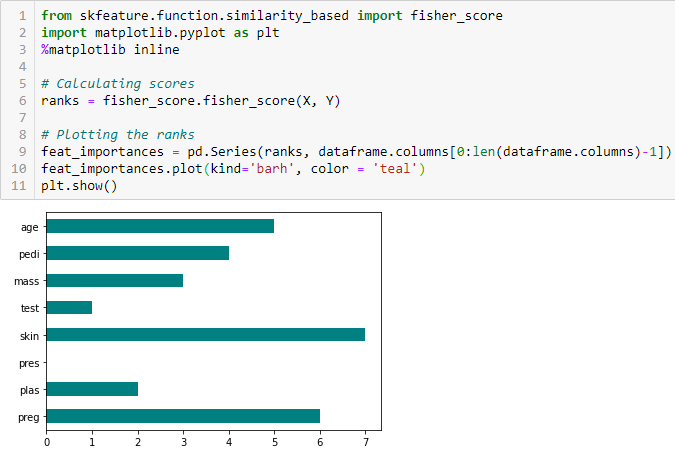
Korrelationskoeffizient
Korrelation ist ein Maß für die lineare Beziehung zwischen 2 oder mehr Variablen. Durch die Korrelation können wir eine Variable aus der anderen vorhersagen. Die Logik hinter der Verwendung der Korrelation für die Merkmalsauswahl ist, dass die guten Variablen hoch mit dem Ziel korreliert sind. Außerdem sollten die Variablen mit dem Ziel korreliert sein, aber untereinander unkorreliert sein.
Wenn zwei Variablen korreliert sind, können wir eine aus der anderen vorhersagen. Wenn also zwei Merkmale korreliert sind, braucht das Modell nur eines von ihnen, da das zweite keine zusätzlichen Informationen liefert. Wir verwenden hier die Pearson-Korrelation.
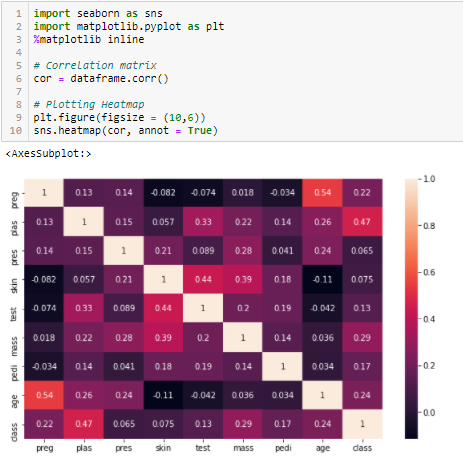
Wir müssen einen absoluten Wert, beispielsweise 0,5, als Schwellenwert für die Auswahl der Variablen festlegen. Wenn wir feststellen, dass die Prädiktorvariablen untereinander korreliert sind, können wir die Variable, die einen niedrigeren Korrelationskoeffizientenwert mit der Zielvariable hat, weglassen. Es können auch mehrere Korrelationskoeffizienten berechnet werden, um zu prüfen, ob mehr als zwei Variablen miteinander korreliert sind. Dieses Phänomen wird als Multikollinearität bezeichnet.
Varianzschwelle
Die Varianzschwelle ist ein einfacher Basisansatz für die Merkmalsauswahl. Es werden alle Merkmale entfernt, deren Varianz einen bestimmten Schwellenwert nicht erreicht. Standardmäßig werden alle Merkmale mit einer Varianz von Null entfernt, d. h. Merkmale, die in allen Stichproben denselben Wert haben. Wir gehen davon aus, dass Merkmale mit einer höheren Varianz mehr nützliche Informationen enthalten können, beachten aber, dass wir die Beziehung zwischen Merkmalsvariablen oder Merkmals- und Zielvariablen nicht berücksichtigen, was einer der Nachteile von Filtermethoden ist.

Die Funktion get_support gibt einen booleschen Vektor zurück, wobei True bedeutet, dass die Variable keine Nullvarianz hat.
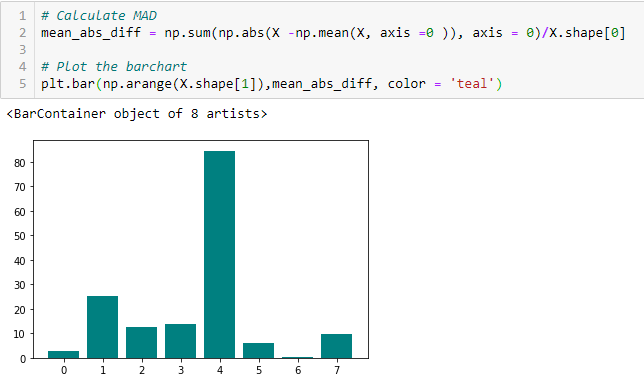
Mittlere absolute Differenz (MAD)
‚Die mittlere absolute Differenz (MAD) berechnet die absolute Differenz zum Mittelwert. Der Hauptunterschied zwischen den Maßen der Varianz und der MAD ist das Fehlen des Quadrats bei letzterer. Die MAD ist, wie die Varianz, eine Skalenvariante.‘ Das bedeutet, je höher die MAD, desto höher die Trennschärfe.
Dispersionsverhältnis
‚Ein weiteres Streuungsmaß ist das arithmetische Mittel (AM) und das geometrische Mittel (GM). Für ein gegebenes (positives) Merkmal Xi auf n Mustern sind AM und GM jeweils gegeben durch
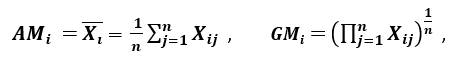
; da AMi ≥ GMi ist, wobei Gleichheit nur dann besteht, wenn Xi1 = Xi2 = …. = Xin, kann das Verhältnis
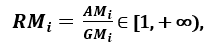
als Streuungsmaß verwendet werden. Eine höhere Streuung impliziert einen höheren Wert von Ri und damit ein relevanteres Merkmal. Umgekehrt liegt Ri nahe bei 1, wenn alle Merkmalsmuster (ungefähr) den gleichen Wert haben, was auf ein Merkmal mit geringer Relevanz hinweist.‘

 ‚
‚
B. Wrapper Methoden:
Wrapper erfordern eine Methode, um den Raum aller möglichen Teilmengen von Merkmalen zu durchsuchen und ihre Qualität durch das Lernen und Bewerten eines Klassifikators mit dieser Teilmenge von Merkmalen zu beurteilen. Der Prozess der Merkmalsauswahl basiert auf einem spezifischen Algorithmus für maschinelles Lernen, den wir auf einen bestimmten Datensatz anwenden wollen. Er folgt einem gierigen Suchansatz, bei dem alle möglichen Kombinationen von Merkmalen anhand des Bewertungskriteriums bewertet werden. Die Wrapper-Methoden führen in der Regel zu einer besseren Vorhersagegenauigkeit als Filtermethoden.
Lassen Sie uns einige dieser Techniken erörtern:
Forward Feature Selection
Dies ist eine iterative Methode, bei der wir mit der Variable beginnen, die die beste Leistung im Vergleich zum Ziel hat. Als nächstes wird eine andere Variable ausgewählt, die in Kombination mit der zuerst ausgewählten Variable die beste Leistung erbringt. Dieser Prozess wird so lange fortgesetzt, bis das vorgegebene Kriterium erreicht ist.
Backward Feature Elimination
Diese Methode funktioniert genau umgekehrt wie die Forward Feature Selection Methode. Hier beginnen wir mit allen verfügbaren Merkmalen und erstellen ein Modell. Anschließend wird die Variable aus dem Modell entfernt, die den besten Wert für das Bewertungsmaß liefert. Dieser Prozess wird so lange fortgesetzt, bis das vorgegebene Kriterium erreicht ist.
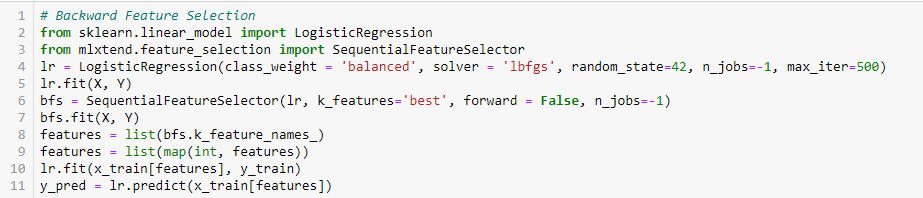
Diese Methode wird zusammen mit der oben beschriebenen auch als sequenzielle Merkmalsauswahlmethode bezeichnet.
Exhaustive Merkmalsauswahl
Dies ist die robusteste Merkmalsauswahlmethode, die bisher behandelt wurde. Es handelt sich um eine Brute-Force-Bewertung jeder Merkmalsuntergruppe. Das bedeutet, dass alle möglichen Kombinationen der Variablen ausprobiert werden und die beste Teilmenge zurückgegeben wird.
Rekursive Merkmalseliminierung
‚Bei einem externen Schätzer, der den Merkmalen (z. B. den Koeffizienten eines linearen Modells) Gewichte zuweist, besteht das Ziel der rekursiven Merkmalseliminierung (RFE) darin, Merkmale auszuwählen, indem rekursiv immer kleinere Merkmalsmengen berücksichtigt werden. Zunächst wird der Schätzer auf der anfänglichen Menge von Merkmalen trainiert, und die Wichtigkeit jedes Merkmals wird entweder durch ein coef_-Attribut oder durch ein feature_importances_-Attribut ermittelt.
Dann werden die am wenigsten wichtigen Merkmale aus dem aktuellen Satz von Merkmalen herausgefiltert. Diese Prozedur wird rekursiv auf der beschnittenen Menge wiederholt, bis schließlich die gewünschte Anzahl der auszuwählenden Merkmale erreicht ist.‘
C. Eingebettete Methoden:
Diese Methoden vereinen die Vorteile der Wrapper- und Filter-Methoden, indem sie Interaktionen von Merkmalen einbeziehen, aber auch angemessene Rechenkosten beibehalten. Eingebettete Methoden sind iterativ in dem Sinne, dass sie sich um jede Iteration des Modelltrainings kümmern und sorgfältig diejenigen Merkmale extrahieren, die am meisten zum Training für eine bestimmte Iteration beitragen.
Lassen Sie uns einige dieser Techniken diskutieren, indem wir hier klicken:
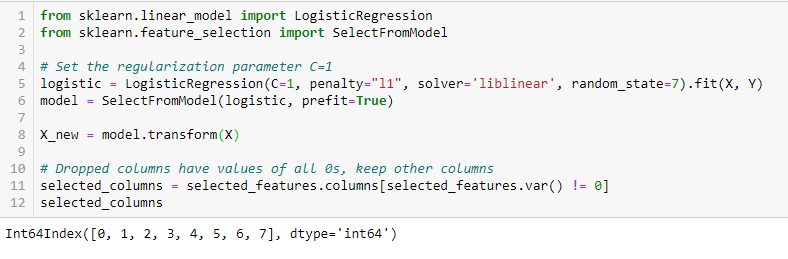
LASSO Regularization (L1)
Regularisierung besteht darin, den verschiedenen Parametern des maschinellen Lernmodells eine Strafe hinzuzufügen, um die Freiheit des Modells zu reduzieren, d.h. um eine Überanpassung zu vermeiden. Bei der Regularisierung eines linearen Modells wird die Strafe auf die Koeffizienten angewendet, die jeden der Prädiktoren multiplizieren. Von den verschiedenen Arten der Regularisierung hat Lasso oder L1 die Eigenschaft, einige der Koeffizienten auf Null zu schrumpfen. Daher kann dieses Merkmal aus dem Modell entfernt werden.
Random Forest Importance
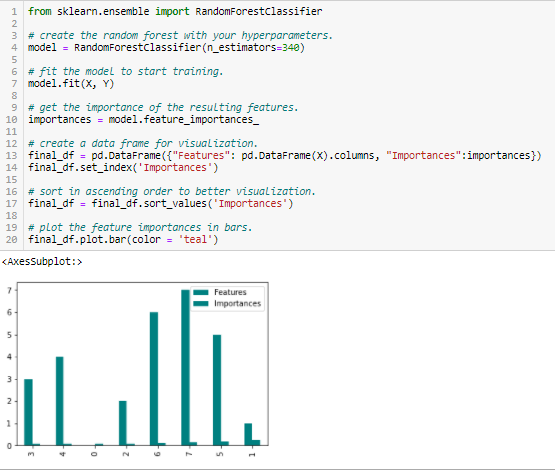
Random Forests ist eine Art Bagging-Algorithmus, der eine bestimmte Anzahl von Entscheidungsbäumen zusammenfasst. Die baumbasierten Strategien, die von Random Forests verwendet werden, werden natürlich danach eingestuft, wie gut sie die Reinheit des Knotens verbessern, oder anders ausgedrückt, eine Verringerung der Unreinheit (Gini-Unreinheit) über alle Bäume. Knoten mit der größten Verringerung der Unreinheit befinden sich am Anfang der Bäume, während Knoten mit der geringsten Verringerung der Unreinheit am Ende der Bäume auftreten. Indem wir Bäume unterhalb eines bestimmten Knotens beschneiden, können wir also eine Teilmenge der wichtigsten Merkmale erstellen.
Schlussfolgerung
Wir haben einige Techniken für die Merkmalsauswahl erörtert. Wir haben die Techniken zur Merkmalsextraktion wie die Hauptkomponentenanalyse, die Singulärwertzerlegung, die lineare Diskriminanzanalyse usw. absichtlich verlassen. Diese Methoden helfen, die Dimensionalität der Daten zu reduzieren oder die Anzahl der Variablen zu verringern, während die Varianz der Daten erhalten bleibt.
Abgesehen von den oben besprochenen Methoden gibt es viele andere Methoden der Merkmalsauswahl. Es gibt auch hybride Methoden, die sowohl Filter- als auch Wrapping-Techniken verwenden. Wenn Sie mehr über Merkmalsauswahltechniken erfahren möchten, ist die beste und umfassendste Lektüre meiner Meinung nach „Feature Selection for Data and Pattern Recognition“ von Urszula Stańczyk und Lakhmi C. Jain.