Update 29-Mai-2018: Der Zweck dieses Artikels ist dreifach: (1) Zeigen, dass wir immer ein Datenmodell brauchen werden (entweder von Menschen oder Maschinen) (2) Zeigen, dass physische Modellierung nicht dasselbe ist wie logische Modellierung. Tatsächlich ist sie sehr unterschiedlich und hängt von der zugrunde liegenden Technologie ab. Wir brauchen jedoch beides. Ich habe diesen Punkt anhand von Hadoop auf der physischen Ebene veranschaulicht. (3) Zeigen Sie die Auswirkungen des Konzepts der Unveränderlichkeit auf die Datenmodellierung.
- Ist die dimensionale Modellierung tot?
- Warum müssen wir unsere Daten modellieren?
- Warum brauchen wir dimensionale Modelle?
- Datenmodellierung vs. dimensionale Modellierung
- Warum behaupten einige Leute, dass die dimensionale Modellierung tot ist?
- Das Data Warehouse ist tot Verwirrung
- Das Schema-on-Read-Missverständnis
- Denormalisierung neu betrachtet. Die physikalischen Aspekte des Modells.
- Den Prozess der De-Normalisierung zu Ende führen
- Datenverteilung auf einer verteilten relationalen Datenbank (MPP)
- Datenverteilung auf Hadoop
- Dimensionale Modelle auf Hadoop
- Hadoop und sich langsam ändernde Dimensionen
- Speicherentwicklung bei Hadoop
- Das Urteil. Sind dimensionale Modelle und Sternschemata veraltet?
- Ergänzende Lektüre zur dimensionalen Modellierung im Zeitalter von Big Data
Ist die dimensionale Modellierung tot?
Bevor ich Ihnen eine Antwort auf diese Frage gebe, lassen Sie uns einen Schritt zurücktreten und zunächst einen Blick darauf werfen, was wir unter dimensionaler Datenmodellierung verstehen.
Warum müssen wir unsere Daten modellieren?
Entgegen einem weit verbreiteten Missverständnis ist es nicht der einzige Zweck von Datenmodellen, als ER-Diagramm für den Entwurf einer physischen Datenbank zu dienen. Datenmodelle bilden die Komplexität der Geschäftsprozesse in einem Unternehmen ab. Sie dokumentieren wichtige Geschäftsregeln und Konzepte und helfen bei der Standardisierung der wichtigsten Unternehmensterminologie. Sie sorgen für Klarheit und helfen dabei, Unklarheiten und Mehrdeutigkeiten über Geschäftsprozesse aufzudecken. Außerdem können Sie Datenmodelle zur Kommunikation mit anderen Beteiligten nutzen. Sie würden kein Haus oder eine Brücke ohne einen Bauplan bauen. Warum also sollten Sie eine Datenanwendung wie ein Data Warehouse ohne einen Plan bauen?
Warum brauchen wir dimensionale Modelle?
Dimensionale Modellierung ist ein spezieller Ansatz zur Modellierung von Daten. Wir verwenden auch die Begriffe Data Mart oder Sternschema als Synonyme für ein dimensionales Modell. Sternschemata sind für die Datenanalyse optimiert. Werfen Sie einen Blick auf das unten stehende dimensionale Modell. Es ist recht intuitiv zu verstehen. Wir sehen sofort, wie wir unsere Bestelldaten nach Kunde, Produkt oder Datum aufschlüsseln und die Leistung des Geschäftsprozesses „Bestellungen“ durch Aggregation und Vergleich von Metriken messen können.
Einer der Kerngedanken der dimensionalen Modellierung ist die Definition der untersten Granularitätsebene in einem transaktionalen Geschäftsprozess. Wenn wir die Daten zerlegen und aufschlüsseln, ist dies die Blattebene, von der aus wir nicht weiter nach unten gehen können. Anders ausgedrückt: Die unterste Granularitätsebene in einem Sternschema ist eine Verknüpfung des Fakts mit allen Dimensionstabellen ohne Aggregationen.
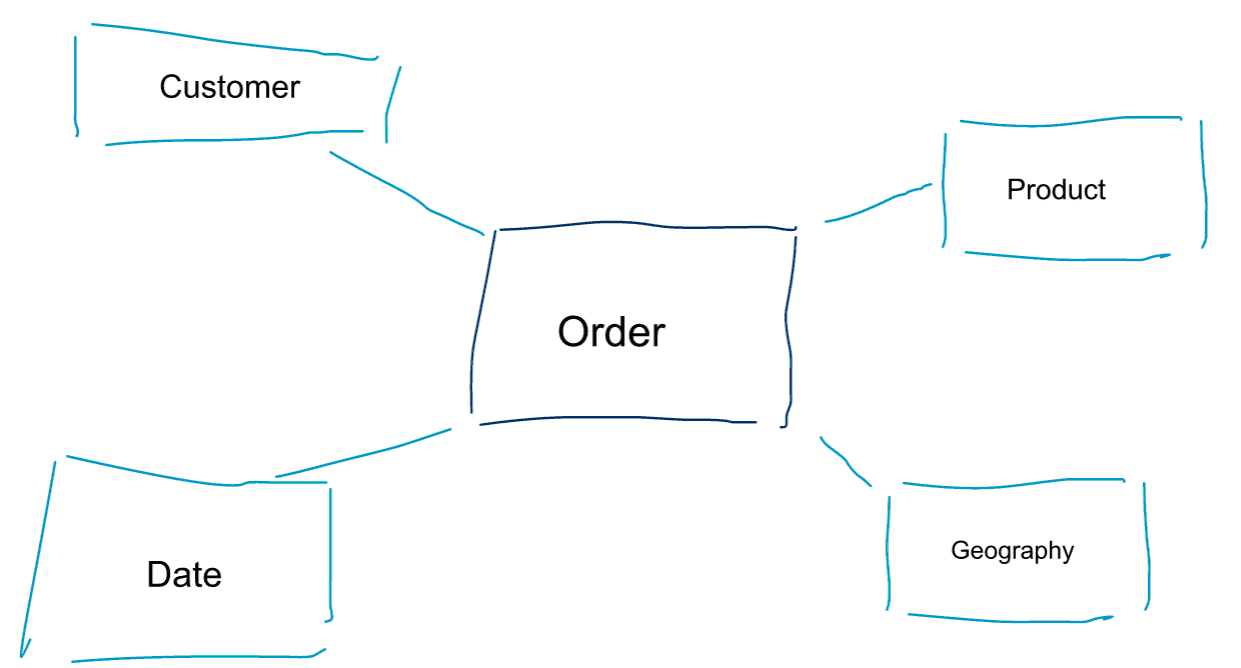
Datenmodellierung vs. dimensionale Modellierung
Bei der Standard-Datenmodellierung wird versucht, Datenwiederholungen und Redundanzen zu beseitigen. Wenn Daten geändert werden, brauchen wir sie nur an einer Stelle zu ändern. Dies hilft auch bei der Datenqualität. Die Werte stimmen nicht an mehreren Stellen nicht mehr überein. Werfen Sie einen Blick auf das folgende Modell. Es enthält verschiedene Tabellen, die geografische Konzepte darstellen. In einem normalisierten Modell haben wir für jede Entität eine eigene Tabelle. In einem dimensionalen Modell haben wir nur eine Tabelle: Geografie. In dieser Tabelle werden die Städte mehrmals wiederholt. Einmal für jede Stadt. Wenn das Land seinen Namen ändert, müssen wir das Land an vielen Stellen aktualisieren
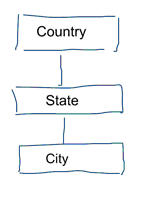
Hinweis: Die Standarddatenmodellierung wird auch als 3NF-Modellierung bezeichnet.
Der Standardansatz zur Datenmodellierung ist für Business Intelligence-Arbeitslasten nicht geeignet. Viele Tabellen führen zu vielen Joins. Joins verlangsamen die Arbeit. In der Datenanalyse werden sie nach Möglichkeit vermieden. In dimensionalen Modellen werden mehrere zusammenhängende Tabellen zu einer Tabelle de-normalisiert, z. B. können die verschiedenen Tabellen in unserem vorherigen Beispiel zu einer einzigen Tabelle vorverknüpft werden: Geografie.
Warum behaupten einige Leute, dass die dimensionale Modellierung tot ist?
Ich denke, Sie werden zustimmen, dass die Datenmodellierung im Allgemeinen und die dimensionale Modellierung im Besonderen eine recht nützliche Übung ist. Warum also behaupten einige Leute, dass die dimensionale Modellierung im Zeitalter von Big Data und Hadoop nicht nützlich ist?
Wie Sie sich vorstellen können, gibt es dafür verschiedene Gründe.
Das Data Warehouse ist tot Verwirrung
Zunächst einmal verwechseln einige Leute die dimensionale Modellierung mit Data Warehousing. Sie behaupten, dass Data Warehousing tot ist und daher auch die dimensionale Modellierung auf den Müllhaufen der Geschichte verbannt werden kann. Dies ist ein logisch schlüssiges Argument. Das Konzept des Data Warehouse ist jedoch keineswegs veraltet. Wir brauchen immer integrierte und zuverlässige Daten, um unsere BI-Dashboards zu füllen. Wenn Sie mehr darüber erfahren möchten, empfehle ich Ihnen unseren Schulungskurs Big Data für Data Warehouse Professionals. In diesem Kurs gehe ich auf die Details ein und erkläre, warum das Data Warehouse nach wie vor relevant ist. Außerdem zeige ich, wie neue Big-Data-Tools und -Technologien für das Data Warehousing nützlich sind.

Das Schema-on-Read-Missverständnis
Das zweite Argument, das ich häufig höre, lautet wie folgt. ‚Wir verfolgen einen Schema-on-Read-Ansatz und brauchen unsere Daten nicht mehr zu modellieren‘. Meiner Meinung nach ist das Konzept des Schema on Read eines der größten Missverständnisse in der Datenanalyse. Ich stimme zu, dass es sinnvoll ist, die Rohdaten zunächst in einem Daten-Dump zu speichern, der kein Schema enthält. Dieses Argument sollte jedoch nicht als Ausrede dafür dienen, Ihre Daten nicht zu modellieren. Der Schema-on-Read-Ansatz schiebt nur die Verantwortung auf nachgelagerte Prozesse ab. Irgendjemand muss immer noch in den sauren Apfel beißen und die Datentypen definieren. Jeder einzelne Prozess, der auf den schemafreien Datendump zugreift, muss selbst herausfinden, was vor sich geht. Diese Art von Arbeit summiert sich, ist völlig überflüssig und kann durch die Definition von Datentypen und eines geeigneten Schemas leicht vermieden werden.
Denormalisierung neu betrachtet. Die physikalischen Aspekte des Modells.
Gibt es tatsächlich stichhaltige Argumente dafür, dimensionale Modelle für obsolet zu erklären? Es gibt in der Tat einige bessere Argumente als die beiden, die ich oben aufgeführt habe. Sie erfordern ein gewisses Verständnis der physikalischen Datenmodellierung und der Funktionsweise von Hadoop. Haben Sie etwas Geduld mit mir.
Vorhin habe ich kurz einen der Gründe erwähnt, warum wir unsere Daten dimensional modellieren. Das hängt mit der Art und Weise zusammen, wie die Daten physisch in unserem Datenspeicher gespeichert werden. Bei der Standard-Datenmodellierung erhält jede Entität der realen Welt ihre eigene Tabelle. Damit wollen wir Datenredundanz und das Risiko vermeiden, dass sich Probleme mit der Datenqualität in unsere Daten einschleichen. Je mehr Tabellen wir haben, desto mehr Joins brauchen wir. Das ist der Nachteil. Tabellen-Joins sind teuer, vor allem, wenn wir eine große Anzahl von Datensätzen aus unseren Datensätzen verbinden. Wenn wir Daten dimensionell modellieren, fassen wir mehrere Tabellen in einer einzigen zusammen. Wir sagen, dass wir die Daten vorverknüpfen oder de-normalisieren. Wir haben jetzt weniger Tabellen, weniger Joins und infolgedessen geringere Latenzzeiten und eine bessere Abfrageleistung.
Beteiligen Sie sich an der Diskussion zu diesem Beitrag auf LinkedIn
Den Prozess der De-Normalisierung zu Ende führen
Warum die De-Normalisierung nicht zu Ende führen? Alle Joins abschaffen und nur noch eine einzige Faktentabelle haben? Dies würde in der Tat die Notwendigkeit von Joins vollständig beseitigen. Wie Sie sich vorstellen können, hat dies jedoch einige Nebeneffekte. Zunächst einmal erhöht sich dadurch der Speicherbedarf. Wir müssen nun eine Menge redundanter Daten speichern. Mit dem Aufkommen spaltenförmiger Speicherformate für die Datenanalyse ist dies heutzutage weniger ein Problem. Das größere Problem bei der De-Normalisierung ist die Tatsache, dass wir jedes Mal, wenn sich ein Wert eines der Attribute ändert, den Wert an mehreren Stellen aktualisieren müssen – möglicherweise Tausende oder Millionen von Aktualisierungen. Eine Möglichkeit, dieses Problem zu umgehen, besteht darin, unsere Modelle jede Nacht vollständig neu zu laden. Dies ist oft viel schneller und einfacher als die Anwendung einer großen Anzahl von Aktualisierungen. Spaltenbasierte Datenbanken verfolgen in der Regel den folgenden Ansatz. Sie speichern Datenaktualisierungen zunächst im Speicher und schreiben sie asynchron auf die Festplatte.
Datenverteilung auf einer verteilten relationalen Datenbank (MPP)
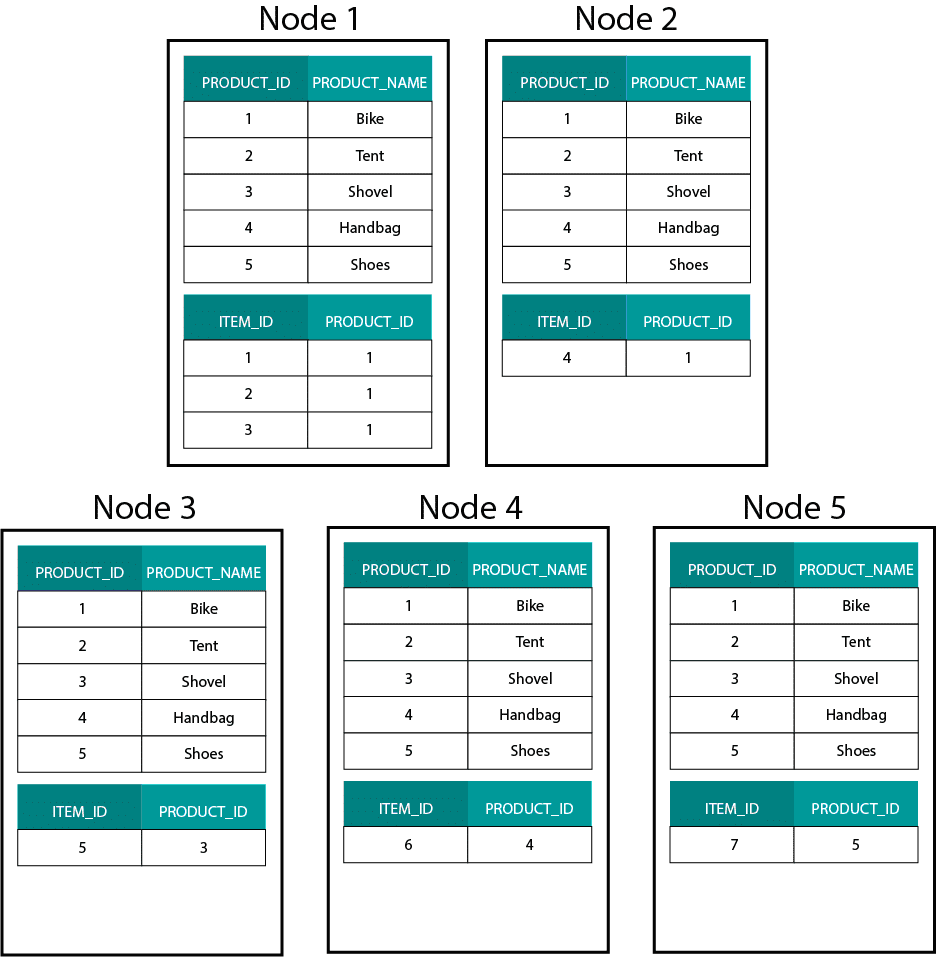
Bei der Erstellung von Dimensionsmodellen auf Hadoop, z. B. Hive, SparkSQL usw., müssen wir ein Kernmerkmal der Technologie besser verstehen, das sie von einer verteilten relationalen Datenbank (MPP) wie Teradata usw. unterscheidet. Bei der Verteilung von Daten auf die Knoten in einer MPP haben wir die Kontrolle über die Platzierung von Datensätzen. Auf der Grundlage unserer Partitionierungsstrategie, z. B. Hash, Liste, Bereich usw., können wir die Schlüssel der einzelnen Datensätze auf verschiedenen Registerkarten desselben Knotens platzieren. Da die Ko-Lokalität der Daten gewährleistet ist, sind unsere Joins superschnell, da wir keine Daten über das Netzwerk senden müssen. Sehen Sie sich das folgende Beispiel an. Datensätze mit derselben ORDER_ID aus den Tabellen ORDER und ORDER_ITEM landen auf demselben Knoten.
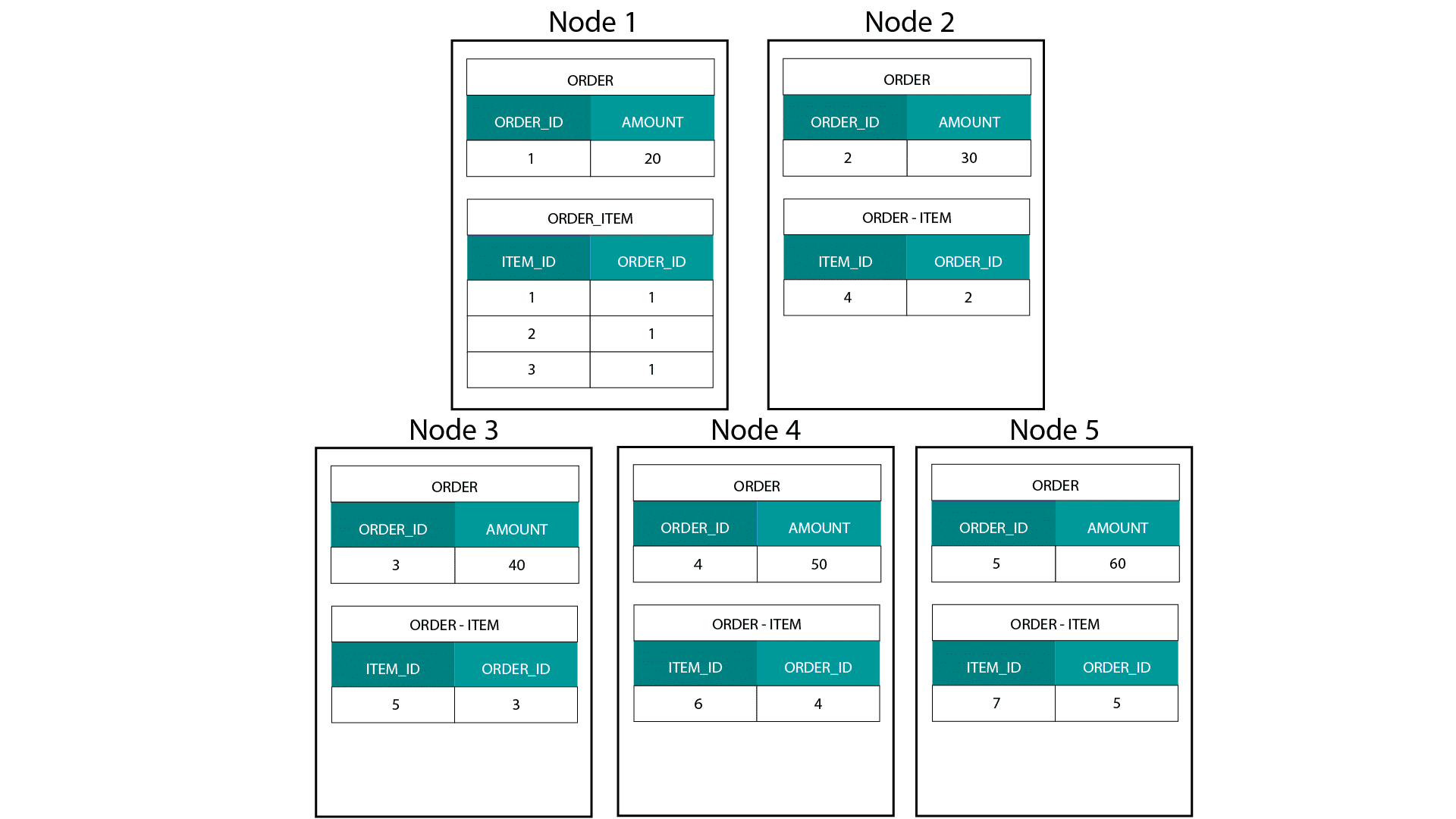
Schlüssel für order_id der Tabellen order und order_item befinden sich auf denselben Knoten.
Datenverteilung auf Hadoop
Dies unterscheidet sich stark von Hadoop-basierten Systemen. Dort teilen wir unsere Daten in große Stücke auf und verteilen und replizieren sie über unsere Knoten auf dem Hadoop Distributed File System (HDFS). Mit dieser Datenverteilungsstrategie können wir keine Datenko-Lokalität garantieren. Schauen Sie sich das folgende Beispiel an. Die Datensätze für den Schlüssel ORDER_ID landen auf verschiedenen Knoten.
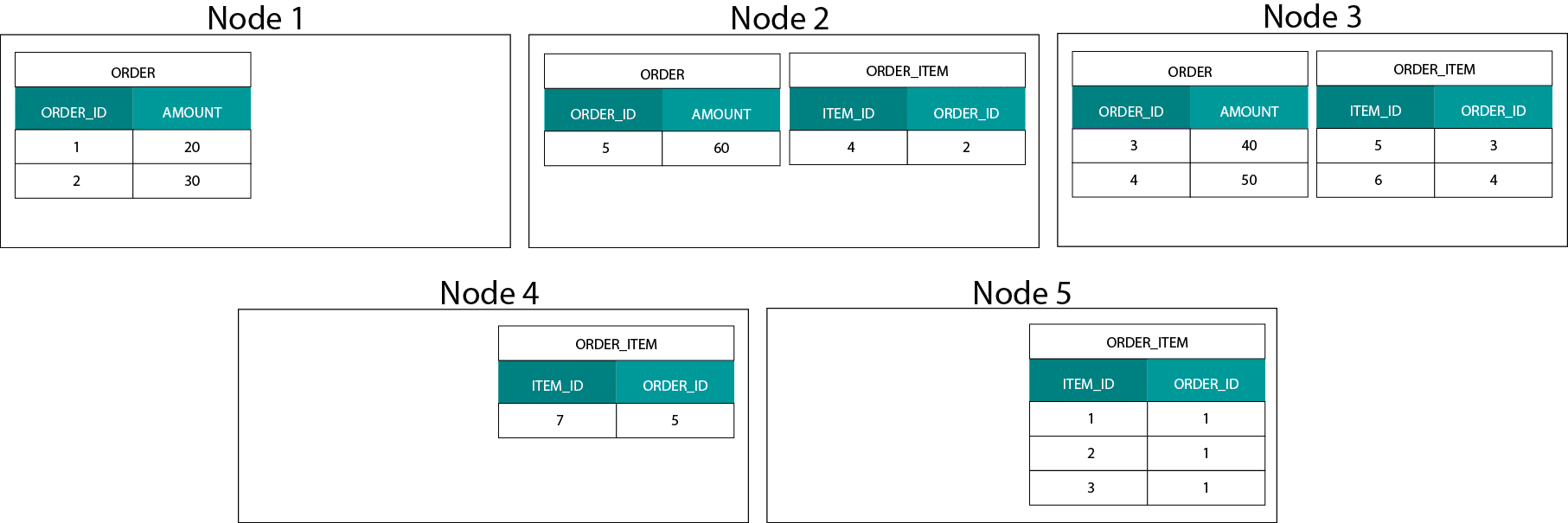
Um einen Join durchzuführen, müssen wir Daten über das Netzwerk senden, was sich auf die Leistung auswirkt.
Eine Strategie zur Lösung dieses Problems besteht darin, eine der Join-Tabellen über alle Knoten im Cluster zu replizieren. Dies wird als Broadcast-Join bezeichnet, und wir verwenden die gleiche Strategie bei einem MPP. Wie Sie sich vorstellen können, funktioniert dies nur für kleine Lookup- oder Dimensionstabellen.
Was tun wir also, wenn wir eine große Faktentabelle und eine große Dimensionstabelle haben, z. B. Kunde oder Produkt? Oder wenn wir zwei große Faktentabellen haben.
Dimensionale Modelle auf Hadoop
Um dieses Leistungsproblem zu umgehen, können wir große Dimensionstabellen in unsere Faktentabelle de-normalisieren, um zu gewährleisten, dass die Daten an einem Ort liegen.
Um zwei große Faktentabellen zu verbinden, können wir die Tabelle mit der niedrigeren Granularität in der Tabelle mit der höheren Granularität verschachteln, z. B. eine große Tabelle ORDER_ITEM in der Tabelle ORDER. Moderne Abfrage-Engines wie Impala oder Drill ermöglichen es uns, diese Daten zu glätten

Diese Strategie der Verschachtelung von Daten ist auch für schmerzhafte Kimball-Konzepte wie Brückentabellen zur Darstellung von M:N-Beziehungen in einem dimensionalen Modell nützlich.
Hadoop und sich langsam ändernde Dimensionen
Die Speicherung im Hadoop-Dateisystem ist unveränderlich. Mit anderen Worten: Sie können nur Datensätze einfügen und anhängen. Sie können die Daten nicht ändern. Wenn Sie aus einem relationalen Data Warehouse kommen, mag Ihnen das zunächst etwas seltsam vorkommen. Unter der Haube funktionieren Datenbanken jedoch auf ähnliche Weise. Sie speichern alle Datenänderungen in einem unveränderlichen Protokoll (in Oracle als Redo-Log bekannt), bevor ein Prozess die Daten in den Datendateien asynchron aktualisiert.
Welche Auswirkungen hat die Unveränderlichkeit auf unsere Dimensionsmodelle? Vielleicht erinnern Sie sich an das Konzept der Slowly Changing Dimensions (SCDs) aus Ihrem Dimensionsmodellierungskurs. SCDs bewahren optional die Historie von Änderungen an Attributen. Sie ermöglichen es uns, Metriken über den Wert eines Attributs zu einem bestimmten Zeitpunkt zu berichten. Dies ist jedoch nicht das Standardverhalten. Standardmäßig aktualisieren wir Dimensionstabellen mit den neuesten Werten. Was sind also unsere Optionen in Hadoop? Zur Erinnerung! Wir können keine Daten aktualisieren. Wir können einfach SCD als Standardverhalten festlegen und alle Änderungen überprüfen. Wenn wir Berichte anhand der aktuellen Werte erstellen wollen, können wir eine Ansicht über der SCD erstellen, die nur den neuesten Wert abruft. Dies ist mit Hilfe von Windowing-Funktionen leicht zu bewerkstelligen. Alternativ können wir einen so genannten Verdichtungsdienst ausführen, der physisch eine separate Version der Dimensionstabelle mit nur den neuesten Werten erstellt.
Speicherentwicklung bei Hadoop
Diese Hadoop-Einschränkungen sind den Anbietern der Hadoop-Plattformen nicht entgangen. In Hive haben wir jetzt ACID-Transaktionen und aktualisierbare Tabellen. Ausgehend von der Anzahl der offenen Probleme und meiner eigenen Erfahrung scheint diese Funktion jedoch noch nicht produktionsreif zu sein. Cloudera hat einen anderen Ansatz gewählt. Mit Kudu haben sie ein neues, aktualisierbares Speicherformat geschaffen, das nicht auf HDFS, sondern auf dem lokalen Dateisystem des Betriebssystems liegt. Es hebt die Hadoop-Beschränkungen vollständig auf und ähnelt der traditionellen Speicherschicht in einem kolumnaren MPP. Im Allgemeinen sind Sie wahrscheinlich besser dran, wenn Sie BI- und Dashboard-Anwendungsfälle auf einer MPP ausführen, z. B. Impala + Kudu, als auf Hadoop. Allerdings haben MPPs ihre eigenen Grenzen, wenn es um Ausfallsicherheit, Gleichzeitigkeit und Skalierbarkeit geht. Wenn Sie auf diese Einschränkungen stoßen, sind Hadoop und sein enger Verwandter Spark gute Optionen für BI-Workloads. In unserem Schulungskurs Big Data für Data Warehouse Professionals gehen wir auf all diese Einschränkungen ein und geben Empfehlungen, wann ein RDBMS und wann SQL auf Hadoop/Spark verwendet werden sollte.
Das Urteil. Sind dimensionale Modelle und Sternschemata veraltet?
Wir alle wissen, dass Ralph Kimball im Ruhestand ist. Aber seine grundsätzlichen Ideen und Konzepte sind immer noch gültig und leben weiter. Wir müssen sie an neue Technologien und Speichertypen anpassen, aber sie bieten immer noch einen Mehrwert.
Lernen Sie mich Big Data, um meine Karriere voranzutreiben
Ergänzende Lektüre zur dimensionalen Modellierung im Zeitalter von Big Data
Tom Breur: Vergangenheit und Zukunft der dimensionalen Modellierung
Edosa Odaro: 5 radikale Tipps für eine schnelle Big-Data-Integration – Das Anti-Data-Warehouse-Muster