Revidiert: 11. Dezember 2020
Sagen die Probanden die Wahrheit?
Die Zuverlässigkeit von Selbstauskunftsdaten ist eine Achillesferse der Umfrageforschung. So haben Meinungsumfragen ergeben, dass mehr als 40 % der Amerikaner jede Woche in die Kirche gehen. Hadaway und Marlar (2005) kamen jedoch bei der Untersuchung von Kirchenbesuchslisten zu dem Schluss, dass die tatsächliche Anwesenheit bei weniger als 22 Prozent liegt. In seinem bahnbrechenden Werk „Everybody lies“ fand Seth Stephens-Davidowitz (2017) reichlich Beweise dafür, dass die meisten Menschen nicht tun, was sie sagen, und nicht sagen, was sie tun. Zum Beispiel erklärten die meisten Wähler in Umfragen, dass die ethnische Zugehörigkeit des Kandidaten unwichtig sei. Bei der Überprüfung von Suchbegriffen in Google stellte Sephens-Davidowitz jedoch das Gegenteil fest: Wenn Google-Nutzer das Wort „Obama“ eingaben, assoziierten sie seinen Namen immer mit einigen Wörtern, die mit Rasse zu tun hatten.
Für Forschungszwecke im Bereich des webbasierten Unterrichts können Webnutzungsdaten durch Analysieren des Benutzerzugriffsprotokolls, Setzen von Cookies oder Hochladen des Cache gewonnen werden. Diese Optionen sind jedoch möglicherweise nur begrenzt anwendbar. Beispielsweise kann das Benutzerzugriffsprotokoll keine Benutzer verfolgen, die Links zu anderen Websites folgen. Außerdem können Cookies oder Caches Probleme mit dem Datenschutz aufwerfen. In diesen Fällen werden durch Umfragen erhobene Selbstauskünfte verwendet. Dies wirft die Frage auf: Wie genau sind die selbstberichteten Daten? Cook und Campbell (1979) haben darauf hingewiesen, dass die Probanden (a) dazu neigen, das zu berichten, was sie glauben, dass der Forscher es zu sehen erwartet, oder (b) das zu berichten, was ihre eigenen Fähigkeiten, ihr Wissen, ihren Glauben oder ihre Meinung positiv widerspiegelt. Ein weiteres Problem bei solchen Daten ist die Frage, ob die Probanden in der Lage sind, sich genau an vergangene Verhaltensweisen zu erinnern. Psychologen haben davor gewarnt, dass das menschliche Gedächtnis fehlerhaft ist (Loftus, 2016; Schacter, 1999). Manchmal „erinnern“ sich Menschen an Ereignisse, die nie stattgefunden haben. Daher ist die Zuverlässigkeit selbstberichteter Daten zweifelhaft.Obwohl statistische Softwarepakete in der Lage sind, Zahlen bis zu 16-32 Dezimalstellen zu berechnen, ist diese Präzision bedeutungslos, wenn die Daten nicht einmal auf der Ebene ganzer Zahlen genau sein können. Einige Wissenschaftler haben die Forscher davor gewarnt, dass Messfehler die statistische Analyse beeinträchtigen können (Blalock, 1974), und haben vorgeschlagen, dass eine gute Forschungspraxis die Überprüfung der Qualität der erhobenen Daten erfordert (Fetter, Stowe, & Owings, 1984).
Vorspannung und Varianz
Messfehler umfassen zwei Komponenten, nämlich Vorspannung und variabler Fehler.Vorspannung ist ein systematischer Fehler, der dazu neigt, das gemeldete Ergebnis an ein extremes Ende zu drücken. So wurde beispielsweise festgestellt, dass mehrere Versionen von IQ-Tests eine Verzerrung gegenüber Nicht-Weißen aufweisen. Das bedeutet, dass Schwarze und Hispanoamerikaner unabhängig von ihrer tatsächlichen Intelligenz tendenziell niedrigere Werte erhalten. Ein variabler Fehler, auch als Varianz bezeichnet, ist in der Regel zufällig. Mit anderen Worten, die berichteten Werte können entweder über oder unter den tatsächlichen Werten liegen (Salvucci, Walter, Conley, Fink, & Saba, 1997).
Die Ergebnisse dieser beiden Arten von Messfehlern haben unterschiedliche Auswirkungen. So wurde beispielsweise in einer Studie, in der Selbstangaben zu Größe und Gewicht mit direkt gemessenen Daten verglichen wurden (Hart & Tomazic, 1999), festgestellt, dass die Probanden dazu neigen, ihre Größe zu hoch, ihr Gewicht jedoch zu niedrig anzugeben. Offensichtlich handelt es sich bei dieser Art von Fehlermuster um eine Verzerrung und nicht um Varianz. Eine mögliche Erklärung für diese Verzerrung ist, dass die meisten Menschen nach außen hin ein besseres körperliches Bild abgeben wollen. Wenn es sich jedoch um einen zufälligen Messfehler handelt, kann die Erklärung komplizierter sein.
Man könnte argumentieren, dass variable Fehler, die zufällig sind, sich gegenseitig auslöschen würden und somit keine Gefahr für die Studie darstellen. Zum Beispiel könnte der erste Nutzer seine Internet-Aktivitäten um 10 % überschätzen, während der zweite Nutzer seine Aktivitäten um 10 % unterschätzt. In diesem Fall könnte der Mittelwert immer noch korrekt sein. Über- und Unterschätzungen erhöhen jedoch die Variabilität der Verteilung. Bei vielen parametrischen Tests wird die gruppeninterne Variabilität als Fehlerterm verwendet. Eine überhöhte Variabilität würde die Signifikanz des Tests definitiv beeinträchtigen. In einigen Texten wird die oben beschriebene Fehleinschätzung möglicherweise noch verstärkt. Zum Beispiel sagt Deese (1972),
Die statistische Theorie besagt, dass die Wahrscheinlichkeit von Beobachtungen proportional zur Quadratwurzel ihrer Anzahl ist. Je mehr Beobachtungen es gibt, desto mehr Zufallseinflüsse gibt es. Und die statistische Theorie besagt, dass je mehr zufällige Fehler es gibt, desto wahrscheinlicher ist es, dass sie sich gegenseitig aufheben und eine Normalverteilung ergeben (S.55).
Erstens stimmt es, dass mit zunehmendem Stichprobenumfang die Varianz der Verteilung abnimmt, aber das ist keine Garantie dafür, dass sich die Form der Verteilung der Normalität annähert. Zweitens sollte die Zuverlässigkeit (die Qualität der Daten) an die Messung und nicht an die Bestimmung des Stichprobenumfangs gebunden sein. Ein großer Stichprobenumfang mit vielen Messfehlern, selbst Zufallsfehlern, würde den Fehlerterm für parametrische Tests aufblähen.
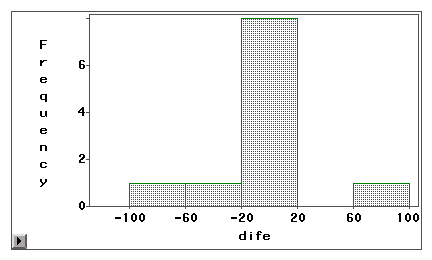
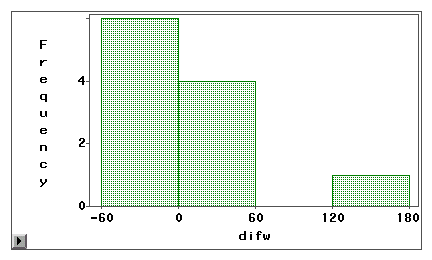
Mit Hilfe eines Stamm-Blatt-Diagramms oder eines Histogramms kann visuell untersucht werden, ob ein Messfehler auf eine systematische Verzerrung oder eine Zufallsvarianz zurückzuführen ist. Im folgenden Beispiel werden zwei Arten des Internetzugangs (Web-Browsing und E-Mail) sowohl durch eine Selbstauskunft als auch durch ein Logbuch gemessen. Die Differenzwerte (Messung 1 – Messung 2) werden in den folgenden Histogrammen aufgetragen.
Das erste Diagramm zeigt, dass die meisten Differenzwerte um Null herum liegen. Zu niedrige und zu hohe Werte in der Nähe beider Enden deuten darauf hin, dass es sich bei dem Messfehler eher um einen Zufallsfehler als um eine systematische Verzerrung handelt.
Das zweite Diagramm zeigt deutlich, dass ein hohes Maß an Messfehlern vorliegt, da nur sehr wenige Differenzwerte um Null herum zentriert sind. Außerdem ist die Verteilung negativ schief, so dass der Fehler eher eine Verzerrung als eine Varianz ist.
Wie zuverlässig ist unser Gedächtnis?
Schacter (1999) warnte, dass das menschliche Gedächtnis fehlbar ist. Es gibt sieben Schwachstellen unseres Gedächtnisses:
- Vergänglichkeit: Abnehmende Zugänglichkeit von Informationen im Laufe der Zeit.
- Zerstreutheit: Unaufmerksame oder oberflächliche Verarbeitung, die zu schwachen Erinnerungen beiträgt.
- Blockierung: Die vorübergehende Unzugänglichkeit von Informationen, die im Gedächtnis gespeichert sind.
- Fehlattribution: Die Zuschreibung einer Erinnerung oder Idee an die falsche Quelle.
- Suggestibilität: Erinnerungen, die aufgrund von Suggestivfragen oder -erwartungen implantiert werden.
- Voreingenommenheit: Retrospektive Verzerrungen und unbewusste Einflüsse, die mit aktuellem Wissen und Überzeugungen verbunden sind.
- Persistenz: Pathologische Erinnerungen – Informationen oder Ereignisse, die wir nicht vergessen können, obwohl wir wünschten, wir könnten es.
 |
„Ich habe keine Erinnerung daran. Ich kann mich nicht daran erinnern, dass ich das Dokument für Whitewater unterzeichnet habe. Ich kann mich nicht erinnern, warum das Dokument verschwunden ist, aber später wieder aufgetaucht ist. Ich erinnere mich an nichts.“ „Ich erinnere mich an die Landung (in Bosnien) unter Scharfschützenfeuer. Es sollte eine Art Begrüßungszeremonie am Flughafen geben, aber stattdessen rannten wir einfach mit gesenktem Kopf in die Fahrzeuge, um zu unserer Basis zu gelangen.“ Während der Ermittlungen zum Versand von Verschlusssachen über einen persönlichen E-Mail-Server sagte Clinton dem FBI, dass sie sich 39 Mal an nichts „erinnern“ oder „erinnern“ könne. Vorsicht: Ein neuer Computervirus namens „Clinton“ wurde entdeckt. Wenn der Computer infiziert ist, erscheint häufig die Meldung „kein Speicherplatz“, auch wenn er über ausreichend RAM verfügt. |
| F: „Wenn Vernon Jordon uns gesagt hat, dass Sie ein außergewöhnliches Gedächtnis haben, eines der besten Gedächtnisse, das er je bei einem Politiker gesehen hat, würden Sie das bestreiten wollen?“
A: „Ich habe ein gutes Gedächtnis…Aber ich kann mich nicht erinnern, ob ich mit Monica Lewinsky allein war oder nicht. Wie sollte ich bei so vielen Frauen in meinem Leben den Überblick behalten?“ Q: Warum hat Clinton Lewinsky für einen Job bei Revlon empfohlen? A: Er wusste, dass sie gut darin sein würde, Dinge zu erfinden. |
 |
Es ist wichtig zu beachten, dass die Zuverlässigkeit unserer Erinnerung manchmal mit der Erwünschtheit des Ergebnisses zusammenhängt. Wenn zum Beispiel ein medizinischer Forscher versucht, relevante Daten von Müttern zu sammeln, deren Babys gesund sind, und von Müttern, deren Kinder missgebildet sind, sind die Daten der letzteren normalerweise genauer als die der ersteren. Das liegt daran, dass die Mütter von missgebildeten Kindern jede Krankheit, die während der Schwangerschaft aufgetreten ist, jedes eingenommene Medikament und jedes Detail, das direkt oder indirekt mit der Tragödie zu tun hat, sorgfältig überprüft haben, um eine Erklärung zu finden. Im Gegensatz dazu schenken Mütter gesunder Säuglinge den vorangegangenen Informationen nicht viel Aufmerksamkeit (Aschengrau & SeageIII, 2008). Die Aufblähung des GPA ist ein weiteres Beispiel dafür, wie sich die Erwünschtheit auf die Genauigkeit des Gedächtnisses und die Datenintegrität auswirkt. In einigen Fällen gibt es einen geschlechtsspezifischen Unterschied bei der Inflationierung des GPA. Eine Studie von Caskie etal. (2014) fand heraus, dass innerhalb der Gruppe der Studenten mit niedrigerem GPA Frauen eher einen höheren als den tatsächlichen GPA angaben als Männer.
Um dem Problem von Erinnerungsfehlern entgegenzuwirken, schlugen einige Forscher vor, Daten zu erheben, die sich auf den momentanen Gedanken oder das Gefühl des Teilnehmers beziehen, anstatt ihn oder sie zu bitten, sich an weit zurückliegende Ereignisse zu erinnern (Csikszentmihalyi & Larson, 1987; Finnigan & Vazire,2018). Bei den folgenden Beispielen handelt es sich um Erhebungselemente des Programme forInternational Student Assessment 2018: „Wurden Sie gestern den ganzen Tag mit Respekt behandelt?“ „Hast du gestern viel gelächelt oder gelacht?“ „Hast du gestern etwas Interessantes gelernt oder getan?“ (Organisation für wirtschaftliche Zusammenarbeit und Entwicklung, 2017). Die Antwort hängt jedoch davon ab, was dem Teilnehmer in diesem bestimmten Moment widerfahren ist, was möglicherweise nicht typisch ist. Selbst wenn der Befragte gestern nicht viel gelächelt oder gelacht hat, bedeutet das nicht zwangsläufig, dass er immer unglücklich ist.
Was sollen wir tun?
Einige Forscher lehnen die Verwendung von Selbstauskünften aufgrund ihrer angeblich schlechten Qualität ab. Als zum Beispiel eine Gruppe von Forschern untersuchte, ob eine hohe Religiosität zu einer geringeren Befolgung der Anweisungen für die Unterbringung in Notunterkünften in den USA während der COVID19-Pandemie führte, verwendeten sie die Anzahl der Kirchengemeinden pro 10.000 Einwohner als Ersatzmaß für die Religiosität der Region anstelle der selbstberichteten Religiosität, die tendenziell soziale Erwünschtheit widerspiegelt (DeFranza, Lindow, Harrison, Mishra, &Mishra, 2020).
Chan (2009) argumentierte jedoch, dass die angeblich schlechte Qualität der selbstberichteten Daten nichts weiter als eine urbane Legende ist. Aus Gründen der sozialen Erwünschtheit könnten die Befragten den Forschern gelegentlich ungenaue Daten liefern, was aber nicht immer der Fall ist. So ist es zum Beispiel unwahrscheinlich, dass die Befragten bei ihren demografischen Angaben wie Geschlecht und ethnischer Zugehörigkeit lügen würden. Zweitens ist es zwar richtig, dass die Befragten in experimentellen Studien dazu neigen, ihre Antworten zu fälschen, doch ist dieses Problem bei Messungen, die in Feldstudien und in einem natürlichen Umfeld durchgeführt werden, weniger gravierend. Darüber hinaus gibt es zahlreiche etablierte Selbsteinschätzungen zu verschiedenen psychologischen Konstrukten, deren Konstruktvalidität sowohl durch konvergente als auch durch diskriminante Validierung nachgewiesen werden konnte. Zum Beispiel die Big-Five-Persönlichkeitsmerkmale, die proaktive Persönlichkeit, die Affektivität, die Selbstwirksamkeit, die Zielorientierung, die wahrgenommene organisatorische Unterstützung und viele andere.Im Bereich der Epidemiologie behaupteten Khoury, James und Erickson (1994), dass die Auswirkung des Recall Bias überbewertet wird. Trotz der Gefahr der Ungenauigkeit der Daten ist es für den Forscher unmöglich, jede Versuchsperson mit einer Videokamera zu verfolgen und alles aufzuzeichnen, was sie tut. Nichtsdestotrotz kann der Forscher eine Teilmenge der Versuchspersonen verwenden, um Beobachtungsdaten zu erhalten, wie z. B. Benutzerprotokolle oder tägliche Papierprotokolle von Webzugriffen. Die Ergebnisse würden dann mit den Ergebnissen der selbstberichteten Daten aller Versuchspersonen verglichen, um den Messfehler abzuschätzen.
- Wenn dem Forscher das Benutzerzugriffsprotokoll zur Verfügung steht, kann er die Versuchspersonen bitten, die Häufigkeit ihres Zugriffs auf den Webserver zu melden.
- Die Versuchspersonen sollten nicht darüber informiert werden, dass ihre Internetaktivitäten vom Webmaster protokolliert wurden, da dies das Verhalten der Teilnehmer beeinflussen könnte.
- Der Forscher kann eine Untergruppe von Nutzern bitten, einen Monat lang ein Logbuch über ihre Internetaktivitäten zu führen. Danach werden dieselben Benutzer gebeten, eine Umfrage über ihre Internetnutzung auszufüllen.
Manch einer mag einwenden, dass die Logbuchmethode zu anspruchsvoll ist. Tatsächlich werden die Probanden in vielen wissenschaftlichen Forschungsstudien um viel mehr gebeten als das. Als Wissenschaftler beispielsweise untersuchten, wie sich der Tiefschlaf während einer Langstrecken-Weltraumreise auf die menschliche Gesundheit auswirkt, wurden die Teilnehmer gebeten, einen Monat lang im Bett zu liegen. In einer Studie über die Auswirkungen einer geschlossenen Umgebung auf die menschliche Psyche während der Raumfahrt wurden die Probanden ebenfalls einen Monat lang einzeln in einem Raum eingeschlossen. Die Suche nach wissenschaftlichen Wahrheiten ist mit hohen Kosten verbunden.
Nachdem verschiedene Datenquellen gesammelt wurden, kann die Diskrepanz zwischen den protokollierten und den selbstberichteten Daten analysiert werden, um die Zuverlässigkeit der Daten abzuschätzen. Auf den ersten Blick sieht dieser Ansatz wie eine Test-Retest-Reliabilität aus, aber das ist er nicht. Erstens sollte bei der Test-Retest-Reliabilität das in zwei oder mehr Situationen verwendete Instrument dasselbe sein. Zweitens, wenn die Test-Retest-Zuverlässigkeit niedrig ist, liegt die Fehlerquelle innerhalb des Instruments. Wenn die Fehlerquelle jedoch außerhalb des Instruments liegt, wie z. B. menschliche Fehler, ist die Inter-Rater-Reliabilität besser geeignet.
Das oben vorgeschlagene Verfahren kann als Messung der Inter-Data-Reliabilität konzipiert werden, die der Inter-Rater-Reliabilität und der Messwiederholung ähnelt. Es gibt vier Möglichkeiten zur Schätzung der Inter-Rater-Reliabilität, nämlich den Kappa-Koeffizienten, den Index der Inkonsistenz, die ANOVA mit wiederholten Messungen und die Regressionsanalyse. Im folgenden Abschnitt wird beschrieben, wie diese Inter-Rater-Reliabilitätsmessungen als Inter-Data-Reliabilitätsmessungen verwendet werden können.
Kappa-Koeffizient
In der psychologischen und pädagogischen Forschung ist es nicht unüblich, zwei oder mehr Bewerter in den Messprozess einzubeziehen, wenn die Bewertung subjektive Urteile beinhaltet (z.B. bei der Benotung von Aufsätzen). Die Inter-Rater-Reliabilität, die mit dem Kappa-Koeffizienten gemessen wird, wird verwendet, um die Zuverlässigkeit der Daten anzugeben. Beispielsweise werden die Leistungen der Teilnehmer von zwei oder mehr Beurteilern als „Meister“ oder „Nicht-Meister“ (1 oder 0) eingestuft. Daher wird diese Messung in der Regel in kategorialen Datenanalyseverfahren wie PROC FREQ in SAS, „Messung der Übereinstimmung“ in SPSS oder einem Online-Kappa-Rechner berechnet (Lowry, 2016). Die folgende Abbildung ist ein Screenshot des Online-Rechners von Vassarstats.
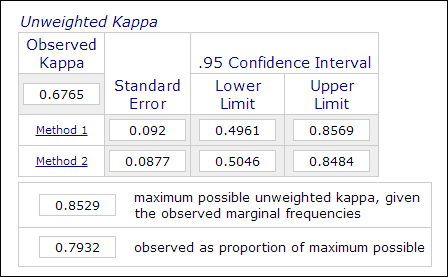
Es ist wichtig zu beachten, dass selbst wenn 60 Prozent zweier Datensätze übereinstimmen, dies nicht bedeutet, dass die Messungen zuverlässig sind.Da das Ergebnis dichotom ist, besteht eine 50-prozentige Chance, dass die beiden Messungen übereinstimmen. Der Kappa-Koeffizient berücksichtigt dies und verlangt einen höheren Grad an Übereinstimmung, um Konsistenz zu erreichen.
Im Kontext des webbasierten Unterrichts kann jede Kategorie der selbstberichteten Website-Nutzung als binäre Variable umcodiert werden. Wenn die erste Frage lautet: „Wie oft benutzen Sie Telnet?“, sind die möglichen kategorialen Antworten „a: täglich“, „b: drei- bis fünfmal pro Woche“, „c: drei- bis fünfmal pro Monat“, „d: selten“ und „e: nie“. In diesem Fall können die fünf Kategorien in fünf Variablen umkodiert werden: Q1A, Q1B, Q1C, Q1D und Q1E. Mit dieser Datenstruktur können die Antworten als „1“ oder „0“ kodiert werden, so dass eine Messung der Klassifikationsübereinstimmung möglich ist. Die Übereinstimmung kann mit Hilfe des Kappa-Koeffizienten berechnet werden, wodurch die Zuverlässigkeit der Daten geschätzt werden kann.
Fächer Buchdaten Selbst-Berichtsdaten Betreff 1 1 1 Betreff 2 0 0 Subjekt 3 1 0 Fach 4 0 1 Index der Inkonsistenz
Eine weitere Möglichkeit zur Berechnung der oben genannten kategorialen Daten ist der Index der Inkonsistenz (IOI). Da es im obigen Beispiel zwei Messungen (Protokoll und Selbstauskunft) und fünf Antwortmöglichkeiten gibt, wird eine 4 x 4-Tabelle gebildet. Der erste Schritt zur Berechnung des IOI besteht darin, die RXC-Tabelle in mehrere 2X2-Teiltabellen zu unterteilen. Zum Beispiel wird die letzte Option „nie“ als eine Kategorie behandelt und alle anderen werden in einer anderen Kategorie als „nicht nie“ zusammengefasst, wie in der folgenden Tabelle dargestellt.
Selbst-gemeldete Daten Log Nie Nicht nie Gesamt Nie a b a+b Nicht nie c d c+d Gesamt a+c b+d n=Summe(a-d) Der prozentuale Anteil der IOI wird nach der folgenden Formel berechnet:
IOI% = 100*(b+c)/ wobei p = (a+c)/n
Nachdem der IOI für jede 2X2-Teiltabelle berechnet wurde, wird ein Durchschnitt aller Indizes als Indikator für die Inkonsistenz der Maßnahme verwendet. Das Kriterium zur Beurteilung, ob die Daten konsistent sind, lautet wie folgt:
- Ein IOI von weniger als 20 ist eine geringe Varianz
- Ein IOI zwischen 20 und 50 ist eine mittlere Varianz
- Ein IOI über 50 ist eine hohe Varianz
Die Zuverlässigkeit der Daten wird in dieser Gleichung ausgedrückt: r = 1 – IOI
Intraklassen-Korrelationskoeffizient
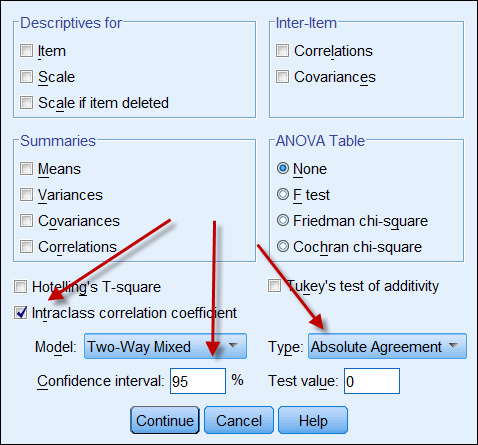
Wenn beide Datenquellen kontinuierliche Daten liefern, dann kann man den Intraklassen-Korrelationskoeffizienten berechnen, um die Zuverlässigkeit der Daten anzugeben. Im Folgenden finden Sie einen Screenshot der ICC-Optionen von SPSS. Unter Typ gibt es zwei Optionen: „Konsistenz“ und „absolute Übereinstimmung“. Wenn „Konsistenz“ gewählt wird, bedeutet eine starke Korrelation selbst dann, dass die Daten übereinstimmen, wenn eine Reihe von Zahlen eine hohe Konsistenz aufweist (z. B. 9, 8, 9, 8, 7…) und die andere eine niedrige Konsistenz (z. B. 4, 3, 4, 3, 2…). Daher ist es ratsam, „absolute Übereinstimmung“ zu wählen.
Wiederholte Messungen
Die Messung der Zuverlässigkeit zwischen den Daten kann auch als ANOVA mit wiederholten Messungen konzeptualisiert und durchgeführt werden. Bei einer ANOVA mit wiederholten Messungen werden dieselben Versuchspersonen mehrmals gemessen, z. B. bei einem Vortest, einer Zwischenprüfung und einer Nachprüfung. In diesem Zusammenhang werden die Probanden auch wiederholt durch das Web-Benutzerprotokoll, das Logbuch und die selbstberichtete Umfrage gemessen. Nachfolgend der SAS-Code für eine ANOVA mit wiederholten Messungen:
data one; input user $ web_log log_book self_report;
cards;
1 215 260 200
2 178 200 150
3 100 111 120
4 135 172 100
5 139 150 140
6 198 200 230
7 135 150 180
8 120 110 100
9 289 276 300
proc glm;
classes user;
model web_log log_book self_report = user;
repeated time 3;
run;
Im obigen Programm wird die Anzahl der besuchten Websites von neun Freiwilligen im Benutzerzugriffsprotokoll, im persönlichen Logbuch und in der selbstberichteten Umfrage aufgezeichnet. Die Nutzer werden als Faktor zwischen den Probanden behandelt, während die drei Maßnahmen als Faktor zwischen den Maßnahmen betrachtet werden. Es folgt eine verkürzte Ausgabe:
Variationsquelle DF Mittelwert zum Quadrat Zwischensubjekt (Benutzer) 8 10442.50 Zwischen-Maß (Zeit) 2 488.93 Rest 16 454.80 Auf der Grundlage der obigen Informationen kann der Reliabilitätskoeffizient mit dieser Formel berechnet werden (Fisher, 1946; Horst, 1949):
r = MSZwischenmaß – MSRücklage ————————————————————– MSbetween-measure + (dfbetween-people X MSresidual) Lassen Sie uns die Zahl in die Formel einsetzen:
r = 488.93 – 454.80 ————————————— 488.93 + ( 8 X 454.80) Die Zuverlässigkeit beträgt etwa .0008, was extrem niedrig ist. Wir können also nach Hause gehen und die Daten vergessen. Zum Glück handelt es sich nur um einen hypothetischen Datensatz. Aber was ist, wenn es ein echter Datensatz ist? Man muss hart genug sein, um auf schlechte Daten zu verzichten, anstatt Ergebnisse zu veröffentlichen, die völlig unzuverlässig sind.
Korrelations- und Regressionsanalyse
Die Korrelationsanalyse, bei der der Pearsonsche Produktmomentenkoeffizient verwendet wird, ist sehr einfach und besonders nützlich, wenn die Skalen von zwei Messungen nicht gleich sind. Beispielsweise kann das Webserverprotokoll die Anzahl der Seitenaufrufe erfassen, während die selbstberichteten Daten eine Likert-Skala aufweisen (z. B. Wie oft surfen Sie im Internet? 5=sehr oft, 4=oft, 3=gelegentlich, 2=selten, 5=nie). In diesem Fall können die selbst eingeschätzten Werte als Prädiktor für den Seitenzugriff verwendet werden.
Ein ähnlicher Ansatz ist die Regressionsanalyse, bei der eine Reihe von Werten (z. B. Umfragedaten) als Prädiktor und eine andere Reihe von Werten (z. B. tägliches Nutzerprotokoll) als abhängige Variable betrachtet wird. Wenn mehr als zwei Messgrößen verwendet werden, kann ein multiples Regressionsmodell angewandt werden, d.h. diejenige, die das genauere Ergebnis liefert (z.B. Web Useraccess Log), wird als abhängige Variable betrachtet und alle anderen Messgrößen (z.B. User Daily Log, Umfragedaten) werden als unabhängige Variablen behandelt.
Referenz
- Aschengrau, A., & Seage III, G. (2008). Essentials of epidemiology in public health. Boston, MA: Jones and Bartlett Publishers.
- Blalock, H. M. (1974). (Ed.) Measurement in the social sciences: Theories and strategies. Chicago, Illinois: Aldine Publishing Company.
- Caskie, G. I. L., Sutton, M. C., & Eckhardt, A. G.(2014). Accuracy of self-reported college GPA: Gender-moderateddifferences by achievement level and academic self-efficacy. Journal of College Student Development, 55, 385-390. 10.1353/csd.2014.0038
- Chan, D. (2009). So why ask me? Are self report data really that bad? In Charles E. Lance and Robert J. Vandenberg (Eds.), Statistical and methodological myths and urban legends: Doctrine,verity and fable in the organizational and social sciences (S. 309-335). New York, NY: Routledge.
- Cook, T. D., & Campbell, D. T. (1979). Quasi-experimentation: Design and analysis issues. Boston, MA: Houghton Mifflin Company.
- Csikszentmihalyi, M., & Larson, R. (1987). Validität und Zuverlässigkeit der Methode der Erfahrungsstichprobe. Journal of Nervous and Mental Disease, 175, 526-536. https://doi.org/10.1097/00005053-198709000-00004
- Deese, J. (1972). Psychologie als Wissenschaft und Kunst. New York, NY: Harcourt Brace Jovanovich, Inc.
- DeFranza, D., Lindow, M., Harrison, K., Mishra, A., &Mishra, H. (2020, August 10). Religion und Reaktanz auf COVID-19-Minderungsrichtlinien. American Psychologist. Advance online publication. http://dx.doi.org/10.1037/amp0000717.
- Fetters, W., Stowe, P., & Owings, J. (1984). High School and Beyond. A national longitudinal study for the 1980s, quality of responses of high school students to questionnaire items. (NCES 84-216).Washington, D. C.: U.S. Department of Education. Office of EducationalResearch and Improvement. National center for Education Statistics.
- Finnigan, K. M., & Vazire, S. (2018). The incrementalvalidity of average state self-reports over global self-reports ofpersonality. Journal of Personality and Social Psychology, 115, 321-337. https://doi.org/10.1037/pspp0000136
- Fisher, R. J. (1946). Statistical methods for research workers (10th ed.). Edinburgh, UK: Oliver and Boyd.
- Hadaway, C. K., & Marlar, P. L. (2005). How manyAmericans attend worship each week? An alternative approach tomeasurement? Journal for the Scientific Study of Religion, 44, 307-322. DOI: 10.1111/j.1468-5906.2005.00288.x
- Hart, W.; & Tomazic, T. (1999 August). Vergleich von Perzentilverteilungen für anthropometrische Maße zwischen drei Datensätzen. Paper presented at the Annual Joint Statistical Meeting, Baltimore, MD.
- Horst, P. (1949). A Generalized expression for the reliability of measures. Psychometrika, 14, 21-31.
- Khoury, M., James, L., & Erikson, J. (1994). On the use of affected controls to address recall bias in case-control studies of birth defects. Teratology, 49, 273-281.
- Loftus, E. (2016, April). The fiction of memory. Paper presented at the Western Psychological Association Convention. Long Beach, CA.
- Lowry, R. (2016). Kappa als Maß für die Konkordanz bei kategorialer Sortierung. Abgerufen von http://vassarstats.net/kappa.html
- Organisation für wirtschaftliche Zusammenarbeit und Entwicklung. (2017). Well-being questionnaire for PISA 2018. Paris: Autor. Retrieved from https://www.oecd.org/pisa/data/2018database/CY7_201710_QST_MS_WBQ_NoNotes_final.pdf
- Schacter, D. L. (1999). The seven sins of memory: Insights from psychology and cognitive neuroscience. American Psychology, 54, 182-203.
- Salvucci, S.; Walter, E., Conley, V; Fink, S; & Saba, M. (1997). Messfehlerstudien am National Center for Education Statistics. Washington D. C.: U. S. Department of Education.
- Stephens-Davidowitz, S. (2017). Everybody lies: Big Data, neue Daten und was das Internet uns darüber sagen kann, wer wir wirklich sind. New York, NY: Dey Street Books.
 Zum Hauptmenü
Zum Hauptmenü Andere KurseSuchmaschine
|

Kontakt
|