Fragen Sie sich, was Postgresql-Schemas sind, warum sie wichtig sind und wie Sie Schemas verwenden können, um Ihre Datenbankimplementierungen robuster und wartbarer zu machen? Dieser Artikel führt Sie in die Grundlagen von Schemata in Postgresql ein und zeigt Ihnen anhand einiger einfacher Beispiele, wie Sie sie erstellen können. Zukünftige Artikel werden sich mit Beispielen für die Sicherung und Verwendung von Schemata für reale Anwendungen befassen.
Zunächst, um mögliche terminologische Verwirrung zu klären, sollten wir verstehen, dass der Begriff „Schema“ in der Postgresql-Welt vielleicht etwas unglücklich überladen ist. Im weiteren Kontext von relationalen Datenbankmanagementsystemen (RDBMS) kann der Begriff „Schema“ so verstanden werden, dass er sich auf das gesamte logische oder physische Design der Datenbank bezieht, d.h. auf die Definition aller Tabellen, Spalten, Ansichten und anderer Objekte, die die Datenbankdefinition ausmachen. In diesem breiteren Kontext kann ein Schema in einem Entity-Relationship (ER)-Diagramm oder einem Skript von Data Definition Language (DDL)-Anweisungen ausgedrückt werden, die zur Instanziierung der Anwendungsdatenbank verwendet werden.
In der Postgresql-Welt kann der Begriff „Schema“ besser als „Namensraum“ verstanden werden. Tatsächlich werden Schemata in den Postgresql-Systemtabellen in Tabellenspalten mit der Bezeichnung „Namensraum“ aufgezeichnet, was, IMHO, die genauere Terminologie ist. Wann immer ich in der Praxis „Schema“ im Zusammenhang mit Postgresql sehe, interpretiere ich es stillschweigend in „Namensraum“ um.
Aber Sie fragen vielleicht: „Was ist ein Namensraum?“ Im Allgemeinen ist ein Namensraum ein ziemlich flexibles Mittel zur Organisation und Identifizierung von Informationen nach Namen. Stellen Sie sich zum Beispiel zwei benachbarte Haushalte vor, die Smiths, Alice und Bob, und die Jones, Bob und Cathy (vgl. Abbildung 1). Wenn wir nur Vornamen verwenden würden, könnte es verwirrend sein, welche Person wir meinen, wenn wir von Bob sprechen. Durch Hinzufügen des Nachnamens, Smith oder Jones, können wir jedoch eindeutig feststellen, welche Person wir meinen.
Oftmals sind Namensräume in einer verschachtelten Hierarchie organisiert. Dies ermöglicht eine effiziente Klassifizierung riesiger Informationsmengen in eine sehr feinkörnige Struktur, wie z.B. das Internet-Domain-Namen-System. Auf der obersten Ebene definieren „.com“, „.net“, „.org“, „.edu“ usw. breite Namensräume, in denen Namen für bestimmte Einheiten registriert sind, so dass beispielsweise „severalnines.com“ und „postgresql.org“ eindeutig definiert sind. Aber unter jeder dieser Domains gibt es eine Reihe von gemeinsamen Subdomains wie z.B. „www“, „mail“ und „ftp“, die für sich genommen doppelt vorkommen, aber innerhalb der jeweiligen Namensräume eindeutig sind.
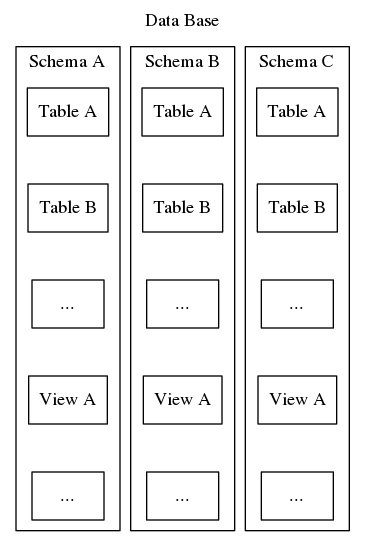
Postgresql-Schemas dienen demselben Zweck der Organisation und Identifizierung, aber im Gegensatz zum zweiten Beispiel oben können Postgresql-Schemas nicht in einer Hierarchie verschachtelt werden. Eine Datenbank kann zwar viele Schemas enthalten, aber es gibt immer nur eine Ebene, so dass die Schemanamen innerhalb einer Datenbank eindeutig sein müssen. Außerdem muss jede Datenbank mindestens ein Schema enthalten. Immer wenn eine neue Datenbank instanziiert wird, wird ein Standardschema namens „public“ erstellt. Der Inhalt eines Schemas umfasst alle anderen Datenbankobjekte wie Tabellen, Ansichten, gespeicherte Prozeduren, Auslöser usw. Zur Veranschaulichung sei auf Abbildung 2 verwiesen, die eine matroschka-puppenartige Verschachtelung zeigt, die verdeutlicht, wo Schemas in die Struktur einer Postgresql-Datenbank passen.
Neben der einfachen Organisation von Datenbankobjekten in logischen Gruppen, um sie besser verwalten zu können, dienen Schemas dem praktischen Zweck, Namenskollisionen zu vermeiden. Ein operatives Paradigma beinhaltet die Definition eines Schemas für jeden Datenbankbenutzer, um ein gewisses Maß an Isolierung zu gewährleisten, einen Raum, in dem die Benutzer ihre eigenen Tabellen und Ansichten definieren können, ohne sich gegenseitig zu behindern. Ein anderer Ansatz besteht darin, Tools von Drittanbietern oder Datenbankerweiterungen in einzelnen Schemata zu installieren, um alle zugehörigen Komponenten logisch zusammenzuhalten. In einem späteren Artikel dieser Reihe wird ein neuartiger Ansatz für ein robustes Anwendungsdesign beschrieben, bei dem Schemas als Mittel der Indirektion eingesetzt werden, um die Offenlegung des physischen Datenbankdesigns zu begrenzen und stattdessen eine Benutzeroberfläche zu präsentieren, die synthetische Schlüssel auflöst und die langfristige Wartung und das Konfigurationsmanagement erleichtert, wenn sich die Systemanforderungen weiterentwickeln.
Lassen Sie uns etwas Code machen!
Der einfachste Befehl zum Erstellen eines Schemas in einer Datenbank ist
CREATE SCHEMA hollywood;Dieser Befehl erfordert create-Rechte in der Datenbank, und das neu erstellte Schema „hollywood“ wird dem Benutzer gehören, der den Befehl aufruft. Ein komplexerer Aufruf kann optionale Elemente enthalten, die einen anderen Eigentümer angeben, und kann sogar DDL-Anweisungen enthalten, die Datenbankobjekte innerhalb des Schemas in einem einzigen Befehl instanziieren!
Das allgemeine Format ist
CREATE SCHEMA schemaname ]wobei „username“ der Eigentümer des Schemas ist und „schema_element“ einer von bestimmten DDL-Befehlen sein kann (siehe Postgresql-Dokumentation für Einzelheiten). Superuser-Privilegien sind erforderlich, um die AUTHORIZATION-Option zu verwenden.
Um zum Beispiel ein Schema namens „hollywood“ zu erstellen, das eine Tabelle namens „films“ und eine Ansicht namens „winners“ enthält, könnte man mit einem einzigen Befehl Folgendes tun
CREATE SCHEMA hollywood CREATE TABLE films (title text, release date, awards text) CREATE VIEW winners AS SELECT title, release FROM films WHERE awards IS NOT NULL;Zusätzliche Datenbankobjekte können anschließend direkt erstellt werden, zum Beispiel würde eine zusätzliche Tabelle dem Schema mit
CREATE TABLE hollywood.actors (name text, dob date, gender text);Hinweis: Im obigen Beispiel wird dem Tabellennamen der Name des Schemas vorangestellt. Dies ist erforderlich, weil neue Datenbankobjekte standardmäßig, d.h. ohne explizite Schemaspezifikation, innerhalb des aktuellen Schemas erstellt werden, das wir im Folgenden behandeln werden.
Erinnern Sie sich, dass wir im ersten Beispiel für einen Namensraum zwei Personen mit dem Namen Bob hatten und beschrieben haben, wie man sie durch Einfügen des Nachnamens auseinanderhalten oder unterscheiden kann. Aber innerhalb der einzelnen Haushalte Smith und Jones versteht jede Familie unter „Bob“ denjenigen, der zu dem jeweiligen Haushalt gehört. So muss beispielsweise Alice ihren Mann im Kontext des jeweiligen Haushalts nicht mit Bob Jones ansprechen und Cathy ihren Mann nicht mit Bob Smith: Sie können beide einfach „Bob“ sagen.
Das aktuelle Schema von Postgresql ist so etwas wie der Haushalt im obigen Beispiel. Objekte im aktuellen Schema können unqualifiziert referenziert werden, aber um auf ähnlich benannte Objekte in anderen Schemas zu verweisen, muss der Name qualifiziert werden, indem der Schemaname wie oben vorangestellt wird.
Das aktuelle Schema wird aus dem Konfigurationsparameter „search_path“ abgeleitet. Dieser Parameter speichert eine kommagetrennte Liste von Schemanamen und kann mit dem Befehl
SHOW search_path;überprüft oder mit
SET search_path TO schema ;auf einen neuen Wert gesetzt werden.
Der erste Schemaname in der Liste ist das „aktuelle Schema“ und ist der Ort, an dem neue Objekte erstellt werden, wenn sie ohne Qualifizierung des Schemanamens angegeben werden.
Die kommagetrennte Liste von Schemanamen dient auch dazu, die Suchreihenfolge zu bestimmen, mit der das System vorhandene unqualifizierte benannte Objekte findet. Um auf die Nachbarschaft von Smith und Jones zurückzukommen: Eine Paketlieferung, die nur an „Bob“ adressiert ist, würde einen Besuch in jedem Haushalt erfordern, bis der erste Bewohner mit dem Namen „Bob“ gefunden wird. Beachten Sie, dass dies möglicherweise nicht der beabsichtigte Empfänger ist. Die gleiche Logik gilt für Postgresql. Das System sucht nach Tabellen, Ansichten und anderen Objekten innerhalb von Schemata in der Reihenfolge des search_path, und dann wird das erste gefundene Objekt mit Namensgleichheit verwendet. Schema-qualifizierte benannte Objekte werden direkt ohne Verweis auf den search_path verwendet.
In der Standardkonfiguration ergibt die Abfrage der search_path-Konfigurationsvariable diesen Wert
SHOW search_path; Search_path-------------- "$user", publicDas System interpretiert den ersten oben gezeigten Wert als den aktuell angemeldeten Benutzernamen und berücksichtigt den bereits erwähnten Anwendungsfall, bei dem jedem Benutzer ein benutzerbenanntes Schema für einen von anderen Benutzern getrennten Arbeitsbereich zugewiesen wird. Wenn kein solches benutzerbenanntes Schema erstellt wurde, wird dieser Eintrag ignoriert und das „öffentliche“ Schema wird zum aktuellen Schema, in dem neue Objekte erstellt werden.
Wenn wir also, um auf unser früheres Beispiel der Erstellung der Tabelle „hollywood.actors“ zurückzukommen, den Tabellennamen nicht mit dem Schemanamen qualifiziert hätten, dann wäre die Tabelle im öffentlichen Schema erstellt worden. Wenn alle Objekte in einem bestimmten Schema erstellt werden sollen, kann es sinnvoll sein, die Variable search_path wie folgt zu setzen:
SET search_path TO hollywood,public;Das erleichtert die Eingabe unqualifizierter Namen, um Datenbankobjekte zu erstellen oder darauf zuzugreifen.
Es gibt auch eine Systeminformationsfunktion, die das aktuelle Schema mit einer Abfrage zurückgibt
select current_schema();Im Falle von Schreibfehlern kann der Besitzer eines Schemas den Namen ändern, vorausgesetzt, der Benutzer hat auch Erstellungsrechte für die Datenbank, mit dem
ALTER SCHEMA old_name RENAME TO new_name;Und schließlich, um ein Schema aus einer Datenbank zu löschen, gibt es einen Drop-Befehl
DROP SCHEMA schema_name;Der DROP-Befehl schlägt fehl, wenn das Schema Objekte enthält, so dass diese zuerst gelöscht werden müssen, oder Sie können optional ein Schema rekursiv mit der CASCADE-Option löschen
DROP SCHEMA schema_name CASCADE;Diese Grundlagen werden Ihnen helfen, Schemas zu verstehen!