Das obige Bild hat Ihnen vielleicht eine Vorstellung davon gegeben, worum es in diesem Beitrag geht.
Dieser Beitrag deckt einige der wichtigsten Fuzzy (nicht genau gleich, aber pauschal die gleichen Strings, sagen wir RajKumar & Raj Kumar) String-Matching-Algorithmen, die umfasst:
Hamming-Distanz
Levenstein-Distanz
Damerau-Levenstein-Distanz
N-Gram-basiertes String-Matching
BK-Baum
Bitap-Algorithmus
Aber wir sollten zunächst wissen, warum Fuzzy-Matching in einem realen Szenario wichtig ist. Wenn ein Benutzer Daten eingeben darf, können die Dinge wirklich chaotisch werden, wie im folgenden Fall!!!
Lassen Sie,
- Ihr Name ist ‚Saurav Kumar Agarwal‘.
- Sie haben einen Bibliotheksausweis erhalten (natürlich mit einer eindeutigen ID), der für jedes Mitglied Ihrer Familie gültig ist.
- Sie gehen jede Woche in eine Bibliothek, um einige Bücher auszugeben. Dafür müssen Sie sich zunächst in ein Register am Eingang der Bibliothek eintragen, in das Sie Ihren & Namen eintragen.
Die Bibliotheksverwaltung beschließt nun, die Daten in diesem Bibliotheksregister zu analysieren, um eine Vorstellung von den einzelnen Lesern zu erhalten, die jeden Monat kommen. Dies kann aus vielen Gründen geschehen (z. B. ob die Fläche erweitert werden soll oder nicht, ob die Anzahl der Bücher erhöht werden soll usw.).
Sie planen, dies zu tun, indem sie die für einen Monat registrierten Paare (eindeutige Namen, Bibliotheks-ID) zählen. Wenn wir also
123 Mehul
123 Rajesh
123 Mehul
133 Rajesh
133 Sandesh
Das sollte uns 4 eindeutige Leser geben.
So weit so gut
Sie schätzten diese Zahl auf etwa 10k-10.5k, aber die Zahlen stiegen auf ~50k nach der Analyse durch exakte Übereinstimmung der Namen.
wooohhh!!!
Eine ziemlich schlechte Schätzung muss ich sagen!!!
Oder haben sie hier einen Trick übersehen?
Nach einer tieferen Analyse kam ein großes Problem auf. Erinnern Sie sich an Ihren Namen, ‚Saurav Agarwal‘. Es wurden einige Einträge gefunden, die zu 5 verschiedenen Benutzern in Ihrer Familienbibliothek-ID führen:
- Saurav K Aggrawal (beachten Sie das doppelte ‚g‘, ‚ra-ar‘, Kumar wird zu K)
- Saurav Kumar Agarwal
- Sourav Aggarwal
- SK Agarwal
- Agarwal
Es gibt einige Unklarheiten, da die Bibliotheksbehörden nicht wissen
- Wie viele Personen aus Ihrer Familie besuchen die Bibliothek? ob diese 5 Namen einen einzigen Leser, 2 oder 3 verschiedene Leser repräsentieren. Nennen wir es ein unüberwachtes Problem, bei dem wir eine Zeichenkette haben, die nicht standardisierte Namen repräsentiert, deren standardisierte Namen aber nicht bekannt sind (z.B. Saurav Agarwal: Saurav Kumar Agarwal ist nicht bekannt)
- Sollten sie alle zu ‚Saurav Kumar Agarwal‘ verschmelzen? kann ich nicht sagen, da SK Agarwal Shivam Kumar Agarwal sein kann (z.B. der Name Ihres Vaters). Außerdem kann der einzige Agarwal jeder aus der Familie sein.
Die letzten beiden Fälle (SK Agarwal & Agarwal) würden einige zusätzliche Informationen erfordern (wie Geschlecht, Geburtsdatum, ausgestellte Bücher), die in einen ML-Algorithmus eingespeist werden, um den tatsächlichen Namen des Lesers zu bestimmen & sollte vorerst beibehalten werden. Aber ich bin mir ziemlich sicher, dass die ersten drei Namen dieselbe Person repräsentieren & Ich sollte keine zusätzlichen Informationen benötigen, um sie zu einem einzigen Leser, z.B. ‚Saurav Kumar Agarwal‘, zusammenzuführen.
Wie kann das gemacht werden?
Hier kommt das Fuzz-String-Matching ins Spiel, d.h. eine fast exakte Übereinstimmung zwischen Strings, die sich geringfügig voneinander unterscheiden (meist aufgrund falscher Schreibweisen) wie ‚Agarwal‘ & ‚Aggarwal‘ & ‚Aggrawal‘. Wenn wir eine Zeichenkette mit einer akzeptablen Fehlerquote (z. B. ein falscher Buchstabe) erhalten, würden wir sie als Übereinstimmung betrachten. Untersuchen wir also →
Die Hamming-Distanz ist die offensichtlichste Distanz, die zwischen zwei gleich langen Zeichenfolgen berechnet wird und die Anzahl der Zeichen angibt, die bei einem bestimmten Index nicht übereinstimmen. Zum Beispiel: ‚Bat‘ & ‚Bet‘ hat die Hamming-Distanz 1 bei Index 1, ‚a‘ ist nicht gleich ‚e‘
Levenstein-Distanz/ Editier-Distanz
Ich nehme an, dass Sie mit der Levenstein-Distanz & Rekursion vertraut sind. Wenn nicht, lesen Sie dies. Die folgende Erklärung ist eher eine zusammengefasste Version der Levenstein-Distanz.
Lassen Sie ‚x’=Länge(Str1) & ‚y’=Länge(Str2) für diesen gesamten Beitrag gelten.
Die Levenstein-Distanz berechnet die minimale Anzahl von Bearbeitungen, die erforderlich sind, um ‚Str1‘ in ‚Str2‘ umzuwandeln, indem entweder Zeichen hinzugefügt, entfernt oder ersetzt werden. Daher hat ‚Katze‘ & ‚Fledermaus‘ die Editierdistanz ‚1‘ (Ersetzen von ‚C‘ durch ‚B‘), während sie für ‚Ceat‘ & ‚Fledermaus‘ 2 wäre (Ersetzen von ‚C‘ durch ‚B‘; Löschen von ‚e‘).
Der Algorithmus besteht im Wesentlichen aus 5 Schritten
int LevensteinDistance(string str1, string str2, int x, int y){if (x == len(str1)+1) return len(str2)-y+1;if (y == len(str2)+1) return len(str1)-x+1;if (str1 == str2)
return LevensteinDistance(str1, str2, x+ 1, y+ 1);return 1 + min(LevensteinDistance(str1, str2, x, y+ 1), #insert LevensteinDistance(str1, str2, x+ 1, y), #remove LevensteinDistance(str1, str2, x+ 1, y+ 1) #replace
}
LevenesteinDistance('abcd','abbd',1,1)
Was wir tun, ist das Lesen von Zeichenketten ab dem ersten Zeichen
- Wenn das Zeichen bei Index ‚x‘ von str1 mit dem Zeichen bei Index ‚y‘ von str2 übereinstimmt, keine Bearbeitung erforderlich & Berechne die Bearbeitungsdistanz durch Aufruf von
LevensteinDistance(str1,str2)
- Wenn sie nicht übereinstimmen, wissen wir, dass eine Bearbeitung erforderlich ist. Also addieren wir +1 zum aktuellen edit_distance & rekursiv berechnet edit_distance für 3 Bedingungen & nimmt das Minimum aus den dreien:
Levenstein(str1,str2) →Einfügung in str2.
Levenstein(str1,str2) →Löschung in str2
Levenstein(str1,str2)→Ersetzung in str2
- Wenn einer der Strings während der Rekursion keine Zeichen mehr hat, wird die Länge der verbleibenden Zeichen in der anderen Zeichenkette zur Editierdistanz addiert (die ersten beiden if-Anweisungen)
Demerau-Levenstein-Distanz
Betrachte ‚abcd‘ & ‚acbd‘. Wenn wir nach der Levenstein-Distanz gehen, wäre dies (ersetze ‚b‘-‚c‘ & ‚c‘-‚b‘ an den Indexpositionen 2 & 3 in str2). Aber wenn man genau hinsieht, wurden beide Zeichen wie in str1 vertauscht & Wenn wir eine neue Operation ‚Swap‘ neben ‚addition‘, ‚ deletion‘ & ‚replace‘ einführen, kann dieses Problem gelöst werden. Diese Einführung kann uns helfen, Probleme wie ‚Agarwal‘ & ‚Agrawal‘ zu lösen.
Diese Operation wird durch den folgenden Pseudocode hinzugefügt
1 +
(x - last_matching_index_y - 1 ) +
(y - last_matching_index_x - 1 ) +
LevinsteinDistance(str1, str2)
Lassen Sie uns die obige Operation für ‚abcd‘ & ‚acbd‘ ausführen, wobei angenommen wird
initial_x=1 & initial_y=1 (Beginn der Indizierung von 1 & nicht von 0 für beide Strings).
aktuell x=3 & y=3 also str1 & str2 jeweils bei ‚c‘ (abcd) & ‚b‘ (acbd).
Obergrenzen, die in der unten erwähnten Zerlegungsoperation enthalten sind. Daher bedeutet ‚qwerty‘ ‚qwer‘.
- last_matching_index_y ist der letzte_Index in str2, der mit str1 übereinstimmt, d. h. 2 als ‚c‘ in ‚acbd‘ (Index 2) mit ‚c‘ in ‚abcd‘.
- last_matching_index_x ist der letzte_Index in str1, der mit str2 übereinstimmt, d. h.e 2, da ‚b‘ in ‚abcd‘ (Index 2) mit ‚b‘ in ‚acbd‘ übereinstimmt.
- Nach dem obigen Pseudocode ist DemarauLevenstein(‚abc‘,’acb‘)=
1+(4-3-1) + (4-3-1)+LevensteinDistance(‚a‘,’a‘)=1+0+0+0=1. Dies wäre 2, wenn wir die Levenstein-Distanz
N-Gramm
N-Gramm ist im Grunde nichts anderes als eine Menge von Werten, die aus einer Zeichenkette durch Paarung von nacheinander auftretenden ’n‘ Zeichen/Wörtern erzeugt werden. Zum Beispiel: n-gram mit n=2 für ‚abcd‘ wird ‚ab‘,’bc‘,’cd‘.
Nun können diese n-grams für Strings generiert werden, deren Ähnlichkeit gemessen werden muss & verschiedene Metriken können zur Messung der Ähnlichkeit verwendet werden.
Lassen Sie ‚abcd‘ &’acbd‘ 2 zu vergleichende Zeichenketten sein.
n-Gramme mit n=2 für
‚abcd’=ab,bc,cd
‚acbd’=ac,cb,bd
Komponentenübereinstimmung (q-Gramme)
Anzahl der n-Gramme, die genau für die beiden Zeichenketten übereinstimmen. Hier wäre es 0
Cosinusähnlichkeit
Berechnung des Punktprodukts nach der Umwandlung der für die Zeichenketten erzeugten n-Gramme in Vektoren
Komponentenübereinstimmung (ohne Berücksichtigung der Reihenfolge)
Übereinstimmung der Komponenten der n-Gramme ohne Berücksichtigung der Reihenfolge der Elemente innerhalb, d.h. bc=cb.
Es gibt noch viele andere Metriken wie Jaccard-Distanz, Tversky-Index usw., die hier nicht besprochen werden.
BK-Baum
BK-Baum gehört zu den schnellsten Algorithmen, um ähnliche Zeichenfolgen (aus einem Pool von Zeichenfolgen) für eine gegebene Zeichenfolge herauszufinden. BK-Baum verwendet eine
- Levenstein-Distanz
- Dreiecksungleichung (wird am Ende dieses Abschnitts behandelt)
um ähnliche Zeichenketten (& nicht nur eine beste Zeichenkette) herauszufinden.
Ein BK-Baum wird mit einem Pool von Wörtern aus einem verfügbaren Wörterbuch erstellt. Nehmen wir an, wir haben ein Wörterbuch D={Book, Books, Cake, Boo, Boon, Cook, Cape, Cart}
Ein BK-Baum wird erstellt durch
- Wählen Sie einen Wurzelknoten (kann ein beliebiges Wort sein). Sei es ‚Bücher‘
- Gehen Sie jedes Wort W im Wörterbuch D durch, berechnen Sie seine Levenstein-Distanz zum Wurzelknoten und machen Sie das Wort W zum Kind des Wurzelknotens, wenn kein Kind mit der gleichen Levenstein-Distanz für den Elternteil existiert. Einfügen von Bücher & Torte.
Levenstein(Bücher,Buch)=1 & Levenstein(Bücher,Torte)=4. Da kein Kind mit dem gleichen Abstand für ‚Buch‘ gefunden wurde, mache sie zu neuen Kindern für Wurzel.
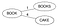
- Wenn ein Kind mit der gleichen Levenstein-Distanz für den Elternteil P existiert, betrachte nun dieses Kind als Elternteil P1 für das Wort W, berechne Levenstein(Elternteil, Wort) und wenn kein Kind mit dem gleichen Abstand für das Elternteil P1 existiert, mache das Wort W zu einem neuen Kind für P1, ansonsten fahre fort, den Baum hinunterzugehen.
Betrachte das Einfügen von Boo. Levenstein(Book, Boo)=1, aber es gibt bereits ein Kind mit demselben Wort, nämlich Books. Berechne daher nun Levenstein(Bücher, Boo)=2. Da es für Books kein Kind mit dem gleichen Abstand gibt, mache Boo zum Kind von Books.

Analog, alle Wörter aus dem Wörterbuch in den BK-Baum einfügen

Wenn der BK-Baum vorbereitet ist, müssen wir für die Suche nach ähnlichen Wörtern für ein bestimmtes Wort (Abfragewort) eine Toleranzschwelle festlegen, z. B. ‚t‘.
- Dies ist die maximale edit_distance, die wir für die Ähnlichkeit zwischen einem beliebigen Knoten & query_word berücksichtigen. Alles, was darüber liegt, wird abgelehnt.
- Auch werden wir nur die Kinder eines Elternknotens für den Vergleich mit Abfrage berücksichtigen, bei denen der Levenstein(Kind, Eltern) innerhalb
warum? werden wir in Kürze erörtern
- Wenn diese Bedingung für ein Kind erfüllt ist, dann werden wir nur Levenstein(Kind, Abfrage) berechnen, das als ähnlich zu Abfrage betrachtet wird, wenn
Levenshtein(Kind, Abfrage)≤t.
- Daher wird die Levenstein-Distanz nicht für alle Knoten/Wörter im Wörterbuch mit dem Abfragewort & berechnet, wodurch viel Zeit gespart wird, wenn der Wortpool groß ist
Daher, ein Kind ist der Abfrage ähnlich, wenn
- Levenstein(Elternteil, Abfrage)-t ≤ Levenstein(Kind,Elternteil) ≤ Levenstein(Elternteil,Abfrage)+t
- Levenstein(Kind,Abfrage)≤t
Lassen Sie uns schnell ein Beispiel durchgehen. Es sei ‚t’=1
Das Wort, für das wir ähnliche Wörter finden müssen, ist ‚Pflege‘ (Suchwort)
- Levenstein(Buch,Pflege)=4. Da 4>1 ist, wird ‚Buch‘ abgelehnt. Nun werden nur die Kinder von ‚Buch‘ berücksichtigt, die eine LevisteinDistance(Kind,’Buch‘) zwischen 3(4-1) & 5(4+1) haben. Folglich würden wir ‚Buch‘ & alle seine Kinder ablehnen, da 1 nicht in den gesetzten Grenzen liegt
- Da Levenstein(Kuchen, Buch)=4 zwischen 3 & 5 liegt, werden wir Levenstein(Kuchen, Pflege)=1 prüfen, was ≤1 ist, also ein ähnliches Wort.
- Werden die Grenzen für die Kinder von Cake angepasst, wird 0(1-1) & 2(1+1)
- Da beide Cape & Cart jeweils Levenstein(Kind, Elternteil)=1 & 2 haben, können beide mit ‚Care‘ geprüft werden.
- Da Levenstein(Cape,Care)=1 ≤1& Levenstein(Cart,Care)=2>1, wird nur Cape als ähnliches Wort zu ‚Care‘ betrachtet.
Daher haben wir 2 Wörter gefunden, die ähnlich zu ‚Care‘ sind: Kuchen & Umhang
Aber auf welcher Grundlage entscheiden wir über die Grenzen
Levenstein(Parent,Query)-t, Levenstein(Parent,Query)+t.
für jeden Kindknoten?
Dies folgt aus der Dreiecksungleichung, die besagt, dass
Distanz (A,B) + Distanz(B,C)≥Distanz(A,C), wobei A,B,C die Seiten eines Dreiecks sind.
Wie diese Idee uns hilft, diese Grenzen zu erreichen, sehen wir uns an:
Lassen wir Query,=Q Parent=P & Child=C ein Dreieck mit Levenstein-Distanz als Kantenlänge bilden. Lass ‚t‘ die Toleranzschwelle sein. Dann ist durch die obige Ungleichung
Levenstein(P,C) + Levenstein(P,Q)≥Levenstein(C,Q)as Levenstein(C, Q) can't exceed 't'(threshold set earlier for C to be similar to Q), HenceLevenstein(P,C) + Levenstein(P,Q)≥ t
OrLevenstein(P,C)≥|Levenstein(P,Q)-t| i.e the lower limit is set
wiederum durch die Dreiecksungleichung,
Levenstein(P,Q) + Levenstein(C,Q) ≥ Levenstein(P,C) or
Levenstein(P,Q) + t ≥ Levenstein(P,C) or the upper limit is set
Bitap-Algorithmus
Es ist auch ein sehr schneller Algorithmus, der für Fuzzy-String-Matching ziemlich effizient verwendet werden kann. Das liegt daran, dass er bitweise Operationen & verwendet, da diese sehr schnell sind und der Algorithmus für seine Schnelligkeit bekannt ist. Ohne viel Zeit zu verschwenden, fangen wir an:
S0=’ababc‘ sei das Muster, das mit der Zeichenkette S1=’abdabababc‘ abgeglichen werden soll.
Zuerst einmal,
- Finde alle eindeutigen Zeichen in S1 & S0 heraus, die a,b,c,d sind
- Bilde Bitmuster für jedes Zeichen. Wie?

- Das zu suchende Muster S0 umkehren
- Für das Bitmuster für das Zeichen x eine 0 setzen, wo es im Muster vorkommt, sonst eine 1. In T kommt ‚a‘ an der 3. & 5. Stelle vor, wir setzen 0 an diese Stellen & Rest 1.
Auf ähnliche Weise alle anderen Bitmuster für verschiedene Zeichen im Wörterbuch bilden.
S0=ababc S1=abdabababc
- Nehmen Sie einen Anfangszustand eines Bitmusters der Länge (S0) mit allen 1en. In unserem Fall wäre das 11111 (Zustand S).
- Wenn wir mit der Suche in S1 beginnen und ein beliebiges Zeichen durchlaufen,
schiebe eine 0 an das unterste Bit, d.h. das 5. Bit von rechts in S &
OR-Operation auf S mit T.
Da wir also auf das 1. ‚a‘ in S1 stoßen, werden wir
- eine 0 in S am untersten Bit nach links schieben, um 11111 →11110
- 11010 | 11110=11110
Nun, da wir auf das 2. Zeichen ‚b‘
- eine 0 in S i.e zu 11110 →11100
- S |T=11100 | 10101=11101
Wenn man auf ‚d‘ stößt
- Schiebe 0 nach S zu 11101 →11010
- S |T=11010 |11111=11111
Beachte, dass, da ‚d‘ nicht in S0 ist, der Zustand S zurückgesetzt wird. Wenn Sie das gesamte S1 durchlaufen, erhalten Sie bei jedem Zeichen die folgenden Zustände

Woher weiß ich, ob ich eine unscharfe/vollständige Übereinstimmung gefunden habe?
- Wenn eine 0 das oberste Bit im Bitmuster des Zustands S erreicht (wie im letzten Zeichen ‚c‘), haben Sie eine vollständige Übereinstimmung
- Für eine unscharfe Übereinstimmung beobachten Sie 0 an verschiedenen Positionen des Zustands S. Wenn 0 an 4. Stelle steht, haben wir 4/5 Zeichen in der gleichen Reihenfolge wie in S0 gefunden. Ähnlich verhält es sich mit 0 an anderen Stellen.
Eine Sache, die Sie vielleicht bemerkt haben, ist, dass alle diese Algorithmen auf der Ähnlichkeit der Schreibweise von Zeichenketten beruhen. Kann es noch andere Kriterien für Fuzzy Matching geben? Ja,
Phonetik
Wird als nächstes auf phonetische (lautbasierte, wie Saurav & Sourav, sollte eine exakte Übereinstimmung in der Phonetik haben) basierende Fuzz-Match-Algorithmen eingehen!
- Dimensionsreduktion (3 Teile)
- NLP Algorithmen(5 Teile)
- Grundlagen des Reinforcement Learning (5 Teile)
- Beginnend mit Time-.Serien (7 Teile)
- Objekterkennung mit YOLO (3 Teile)
- Tensorflow für Anfänger (Konzepte + Beispiele) (4 Teile)
- Vorverarbeitung von Zeitreihen (mit Codes)
- Datenanalyse für Anfänger
- Statistik für Anfänger (4 Teile)