Einführung Dieses Tutorial zeigt, wie man mit dem AutoSplit™-Plug-in für Adobe® Acrobat® ähnliche oder doppelte Seiten innerhalb desselben PDF-Dokuments findet und optional löscht. Dieser Vorgang erkennt ähnliche Seiten und präsentiert sie dem Benutzer zur Überprüfung. Der Benutzer kann die Ergebnisse überprüfen und einzelne Seiten aus der Liste der Duplikate für eine mögliche Löschung oder Extraktion auswählen bzw. die Auswahl aufheben. Sie können die folgenden Operationen durchführen:
- Suchen von doppelten und nahezu doppelten Seiten
- Markieren von doppelten Seiten
- Extrahieren von doppelten Seiten in ein separates PDF-Dokument
- Löschen von doppelten Seiten aus dem Dokument
- Speichern eines Seitenähnlichkeitsberichts
Das Plug-in bietet zwei verschiedene Methoden zum Erkennen von doppelten oder nahezu doppelten Seiten: Nur Seitentext vergleichen Verwenden Sie diese Methode, um den Seitentext unabhängig von seinem visuellen Erscheinungsbild zu vergleichen. Sie berechnet die Ähnlichkeit der Seite nur auf der Grundlage des Textinhalts und ignoriert das Aussehen des Textes, des Layouts, der Bilder und der Grafiken, die möglicherweise auf der Seite vorhanden sind, vollständig. Dies ist die beste Methode zur Erkennung von Duplikaten in den meisten Dokumenttypen. Visuelles Erscheinungsbild der Seiten vergleichen Diese Methode vergleicht Seiten „als Bilder“ und erkennt Seiten, die genau gleich aussehen. Diese Methode vergleicht keinen unsichtbaren Text, der auf der Seite vorhanden sein könnte. Es wird nicht empfohlen, diese Methode bei gescannten Papierdokumenten anzuwenden. Gescannte Papierdokumente verwenden Häufig wird dieser Vorgang verwendet, um doppelte Seiten in den gescannten Papierdokumenten zu finden. Die gescannten Dokumente müssen vor der Verwendung für eine textbasierte Verarbeitung mit OCR bearbeitet werden. Die OCR ist ein Prozess, bei dem Text in gescannten Dokumenten erkannt und durchsuchbar gemacht wird. Es ist wichtig zu verstehen, dass die Texterkennung in gescannten Dokumenten fehleranfällig ist und selten zu 100 % korrekt ist. Die Anzahl der Fehler hängt von der Scanauflösung und der Qualität des Originaldokuments ab. In den meisten Fällen kann eine gescannte Seite zwischen 1 und 10 Erkennungsfehler enthalten, bei denen bestimmte Buchstaben falsch erkannt werden. So kann beispielsweise der Kleinbuchstabe l je nach Schriftart genau wie die Zahl 1 aussehen. Der Großbuchstabe O wird oft fälschlicherweise für die Ziffer 0 gehalten, der Großbuchstabe S für die Ziffer 5 usw. Da viele alphanumerische Symbole ähnliche oder identische physische Merkmale aufweisen, stellt die Unterscheidung oft eine Herausforderung dar. Aus diesem Grund ist ein ähnlichkeitsbasierter Vergleich nützlich, um kleine Unterschiede zwischen den Seiten zu erkennen, die durch den Texterkennungsprozess entstehen. Geringe Qualität gescannter Dokumente kann eine große Anzahl von Fehlern enthalten, die sie für einen zuverlässigen textbasierten Vergleich unbrauchbar machen. In der folgenden Anleitung erfahren Sie, wie Sie gescannte Dokumente mit OCR erfassen und auf ihre Eignung für die textbasierte Verarbeitung prüfen. . Voraussetzungen Sie benötigen eine Kopie von Adobe® Acrobat® zusammen mit dem AutoSplit™-Plug-in auf Ihrem Computer, um diese Anleitung zu verwenden. Sie können Testversionen von Adobe® Acrobat® und dem AutoSplit™-Plug-in herunterladen. Inhalt
- Nur Seitentext vergleichen
- Nur visuelles Erscheinungsbild vergleichen
- Mehrere Dokumente vergleichen
Methode 1 – Nur Seitentext vergleichen Überblick Diese Methode vergleicht die Ähnlichkeit von Seiten nur auf der Grundlage ihres Inhalts. Das visuelle Erscheinungsbild, die Textposition und die Reihenfolge sind irrelevant. Bei dieser Methode werden auch Bilder und Grafiken auf den Seiten ignoriert. Die modifizierte Cosinus-Ähnlichkeitsmetrik wird verwendet, um zu berechnen, wie ähnlich sich zwei Seiten auf der Grundlage ihres Textinhalts sind. Schritt 1 – Öffnen einer PDF-Datei Starten Sie die Anwendung Adobe® Acrobat® und öffnen Sie eine PDF-Datei über das Menü „Datei > Öffnen…“..PNG) Schritt 2 – Öffnen Sie den Dialog „Doppelte Seiten suchen“ Wählen Sie „Plug-Ins > Dokumente teilen > Doppelte Seiten suchen und löschen…“, um den Dialog „Doppelte Seiten suchen“ zu öffnen.
Schritt 2 – Öffnen Sie den Dialog „Doppelte Seiten suchen“ Wählen Sie „Plug-Ins > Dokumente teilen > Doppelte Seiten suchen und löschen…“, um den Dialog „Doppelte Seiten suchen“ zu öffnen..PNG) Schritt 3 – Einstellungen festlegen Aktivieren Sie die Option „Nur Seitentext vergleichen (visuelle Darstellung der Seiten ignorieren)“.
Schritt 3 – Einstellungen festlegen Aktivieren Sie die Option „Nur Seitentext vergleichen (visuelle Darstellung der Seiten ignorieren)“..PNG) Vordefinierte Einstellungen verwenden Die textbasierte Methode bietet eine Reihe von vordefinierten Parametersätzen, die sich für den Vergleich verschiedener Arten von Dokumenten mit einer unterschiedlichen Anzahl von Erkennungsfehlern eignen. Jeder vordefinierte Parametersatz bietet unterschiedliche Bedingungen für Ähnlichkeitsberechnungen:
Vordefinierte Einstellungen verwenden Die textbasierte Methode bietet eine Reihe von vordefinierten Parametersätzen, die sich für den Vergleich verschiedener Arten von Dokumenten mit einer unterschiedlichen Anzahl von Erkennungsfehlern eignen. Jeder vordefinierte Parametersatz bietet unterschiedliche Bedingungen für Ähnlichkeitsberechnungen:
- Benutzerdefinierte Einstellungen – alle Einstellungen werden vom Benutzer festgelegt
- Gescanntes Papierdokument: Hohe Qualität
- Gescanntes Papierdokument: Mittlere Qualität
- Faxdokument: Niedrige Qualität
- Nicht gescanntes PDF: Exakte Übereinstimmung
- Nicht gescanntes PDF: Unscharfe Übereinstimmung
- Exakte Übereinstimmung (mit Textreihenfolge)- diese Methode verwendet keine Kosinusähnlichkeit
.PNG) Die Einstellungen werden nach der Auswahl eines vordefinierten Parametersatzes unterhalb des Menüs angezeigt.
Die Einstellungen werden nach der Auswahl eines vordefinierten Parametersatzes unterhalb des Menüs angezeigt..PNG) Hier sind die Einstellungen, die von den vordefinierten Sets verwendet werden:
Hier sind die Einstellungen, die von den vordefinierten Sets verwendet werden:.PNG) Klicken Sie auf „Bearbeiten…“, um die Einstellungen für die Seitenähnlichkeit anzupassen:
Klicken Sie auf „Bearbeiten…“, um die Einstellungen für die Seitenähnlichkeit anzupassen:.PNG) Die Textvergleichsmethode verwendet 3 Parameter, um zu begrenzen, wie unterschiedlich zwei „ähnliche“ Seiten sein können. Durch Variieren dieser Parameter ist es möglich, Seiten zu erkennen, die einen unterschiedlichen Ähnlichkeitsgrad aufweisen.
Die Textvergleichsmethode verwendet 3 Parameter, um zu begrenzen, wie unterschiedlich zwei „ähnliche“ Seiten sein können. Durch Variieren dieser Parameter ist es möglich, Seiten zu erkennen, die einen unterschiedlichen Ähnlichkeitsgrad aufweisen.
- Minimal zulässige Seitentextähnlichkeit (in Prozent) – dies ist der Wert der Cosinus-Ähnlichkeitsmetrik, ausgedrückt in Prozent. Geben Sie die minimal zulässige Seitentextähnlichkeit zwischen 70 und 100 (in Prozent) an.
- Maximal zulässiger Seitenlängenunterschied (in Zeichen).
- Maximal zulässiger Seitentextunterschied (in Wörtern).
Verwenden Sie diese Einstellungen, um mit den Verarbeitungseinstellungen zu experimentieren, wenn es erforderlich ist, den Verarbeitungsalgorithmus für ein bestimmtes Dokument anzupassen..PNG) Musterseiten verwenden Klicken Sie optional auf „Aus Musterseite einstellen…“, um die Einstellungen für die Seitenähnlichkeit auf der Grundlage von zwei Musterseiten festzulegen:
Musterseiten verwenden Klicken Sie optional auf „Aus Musterseite einstellen…“, um die Einstellungen für die Seitenähnlichkeit auf der Grundlage von zwei Musterseiten festzulegen:.PNG) Wählen Sie zwei Seiten aus, die als identisch angesehen werden können. Die Software berechnet automatisch die Seitenähnlichkeit und die Statistik wird in der linken unteren Ecke des Dialogfelds angezeigt. Klicken Sie auf „OK“, um die aktuellen Ähnlichkeitseinstellungen zu speichern.
Wählen Sie zwei Seiten aus, die als identisch angesehen werden können. Die Software berechnet automatisch die Seitenähnlichkeit und die Statistik wird in der linken unteren Ecke des Dialogfelds angezeigt. Klicken Sie auf „OK“, um die aktuellen Ähnlichkeitseinstellungen zu speichern..PNG) Festlegen von Textfilteroptionen Es gibt mehrere Parameter, die den Seiteninhalt steuern, der vom Textvergleichsalgorithmus analysiert wird. Verwenden Sie diese Optionen beim Vergleich gescannter Papierdokumente, die verschiedene Texterkennungsfehler enthalten können. Diese Optionen schließen bestimmte Arten von Zeichen von der Verarbeitung aus. In vielen Fällen kann dies helfen, eine genauere Ähnlichkeitsmetrik zu berechnen.
Festlegen von Textfilteroptionen Es gibt mehrere Parameter, die den Seiteninhalt steuern, der vom Textvergleichsalgorithmus analysiert wird. Verwenden Sie diese Optionen beim Vergleich gescannter Papierdokumente, die verschiedene Texterkennungsfehler enthalten können. Diese Optionen schließen bestimmte Arten von Zeichen von der Verarbeitung aus. In vielen Fällen kann dies helfen, eine genauere Ähnlichkeitsmetrik zu berechnen.
- Groß- und Kleinschreibung ignorieren – diese Option ignoriert die Groß- und Kleinschreibung beim Textvergleich.
- Satzzeichen ignorieren (,.!?-) – diese Option schließt alle Satzzeichen vom Vergleich aus.
- Nicht-alphanumerische Zeichen ignorieren – diese Option ignoriert alle Zeichen außer Buchstaben und Ziffern.
Klicken Sie auf „OK“, um die Einstellungen für die Seitenähnlichkeit zu speichern..PNG) Klicken Sie auf „OK“, um das aktuelle PDF-Dokument nach den doppelten Seiten zu durchsuchen:
Klicken Sie auf „OK“, um das aktuelle PDF-Dokument nach den doppelten Seiten zu durchsuchen:.PNG) Schritt 4 – Überprüfen der doppelten Seiten Das Dialogfeld „Doppelte Seiten löschen“ zeigt eine Liste der doppelten oder fast doppelten Seiten an. Klicken Sie auf einen Seitendatensatz, um eine entsprechende Seite im Viewer anzuzeigen. Prüfen Sie die Seiten und wählen Sie die zu löschenden Seiten aus bzw. heben Sie die Auswahl auf. Klicken Sie optional auf „Bericht speichern…“, um einen Seitenähnlichkeitsbericht im HTML-Format zu erstellen. Oder klicken Sie auf „Lesezeichen für Seiten“, um Lesezeichen in PDF für ausgewählte doppelte Seiten zu erstellen.
Schritt 4 – Überprüfen der doppelten Seiten Das Dialogfeld „Doppelte Seiten löschen“ zeigt eine Liste der doppelten oder fast doppelten Seiten an. Klicken Sie auf einen Seitendatensatz, um eine entsprechende Seite im Viewer anzuzeigen. Prüfen Sie die Seiten und wählen Sie die zu löschenden Seiten aus bzw. heben Sie die Auswahl auf. Klicken Sie optional auf „Bericht speichern…“, um einen Seitenähnlichkeitsbericht im HTML-Format zu erstellen. Oder klicken Sie auf „Lesezeichen für Seiten“, um Lesezeichen in PDF für ausgewählte doppelte Seiten zu erstellen..PNG) Das Plug-in ermöglicht eine Vorschau/Vergleich der gefundenen doppelten oder nahezu doppelten Seiten. Die Ähnlichkeit der Seiten (in %) und die Anzahl der nicht übereinstimmenden Wörter werden für jedes Seitenpaar angezeigt. Hier sind die Beispiele, die für das Paar der gescannten Papierdokumente berechnet wurden:
Das Plug-in ermöglicht eine Vorschau/Vergleich der gefundenen doppelten oder nahezu doppelten Seiten. Die Ähnlichkeit der Seiten (in %) und die Anzahl der nicht übereinstimmenden Wörter werden für jedes Seitenpaar angezeigt. Hier sind die Beispiele, die für das Paar der gescannten Papierdokumente berechnet wurden:.PNG)
.PNG) Beachten Sie, dass das Erscheinungsbild und die Position des Textes keinen Einfluss auf die Ergebnisse haben. Diese beiden Seiten werden trotz des Unterschieds in der Textfarbe als identisch angesehen:
Beachten Sie, dass das Erscheinungsbild und die Position des Textes keinen Einfluss auf die Ergebnisse haben. Diese beiden Seiten werden trotz des Unterschieds in der Textfarbe als identisch angesehen:
.PNG) Diese beiden Seiten werden trotz des Unterschieds im Layout des Inhalts als identisch angesehen:
Diese beiden Seiten werden trotz des Unterschieds im Layout des Inhalts als identisch angesehen:.PNG) Diese beiden Seiten werden trotz der Unterschiede in der Textreihenfolge, dem Layout und dem Fehlen des Bildes als zu 94 % ähnlich angesehen:
Diese beiden Seiten werden trotz der Unterschiede in der Textreihenfolge, dem Layout und dem Fehlen des Bildes als zu 94 % ähnlich angesehen:.PNG) Schritt 5 – Doppelte Seiten extrahieren oder mit Lesezeichen versehen Optional können Sie mit der Schaltfläche „Seiten mit Lesezeichen versehen“ alle markierten Seiten mit Lesezeichen versehen. Dies ist nützlich, wenn Sie nicht vorhaben, die gefundenen doppelten Seiten aus dem Dokument zu löschen. Verwenden Sie die Kontrollkästchen vor den Seiten, um sie aus dem Verarbeitungssatz auszuwählen bzw. ihre Auswahl aufzuheben. Verwenden Sie die Schaltfläche „Seiten extrahieren….“, um alle markierten Seiten in ein separates PDF-Dokument zu extrahieren. Bei diesem Vorgang werden keine Seiten aus dem aktuellen Dokument entfernt.
Schritt 5 – Doppelte Seiten extrahieren oder mit Lesezeichen versehen Optional können Sie mit der Schaltfläche „Seiten mit Lesezeichen versehen“ alle markierten Seiten mit Lesezeichen versehen. Dies ist nützlich, wenn Sie nicht vorhaben, die gefundenen doppelten Seiten aus dem Dokument zu löschen. Verwenden Sie die Kontrollkästchen vor den Seiten, um sie aus dem Verarbeitungssatz auszuwählen bzw. ihre Auswahl aufzuheben. Verwenden Sie die Schaltfläche „Seiten extrahieren….“, um alle markierten Seiten in ein separates PDF-Dokument zu extrahieren. Bei diesem Vorgang werden keine Seiten aus dem aktuellen Dokument entfernt..PNG) Verwenden Sie die Schaltfläche „Bericht speichern…“, um den Bericht zur Berechnung der Seitenähnlichkeit in einer HTML-Datei zu speichern. Er enthält Details zur Seitenähnlichkeit, zeigt Unterschiede zwischen den Seiten und listet fehlende Wörter auf. Dieser Bericht kann für eine eingehende Analyse sehr nützlich sein.
Verwenden Sie die Schaltfläche „Bericht speichern…“, um den Bericht zur Berechnung der Seitenähnlichkeit in einer HTML-Datei zu speichern. Er enthält Details zur Seitenähnlichkeit, zeigt Unterschiede zwischen den Seiten und listet fehlende Wörter auf. Dieser Bericht kann für eine eingehende Analyse sehr nützlich sein.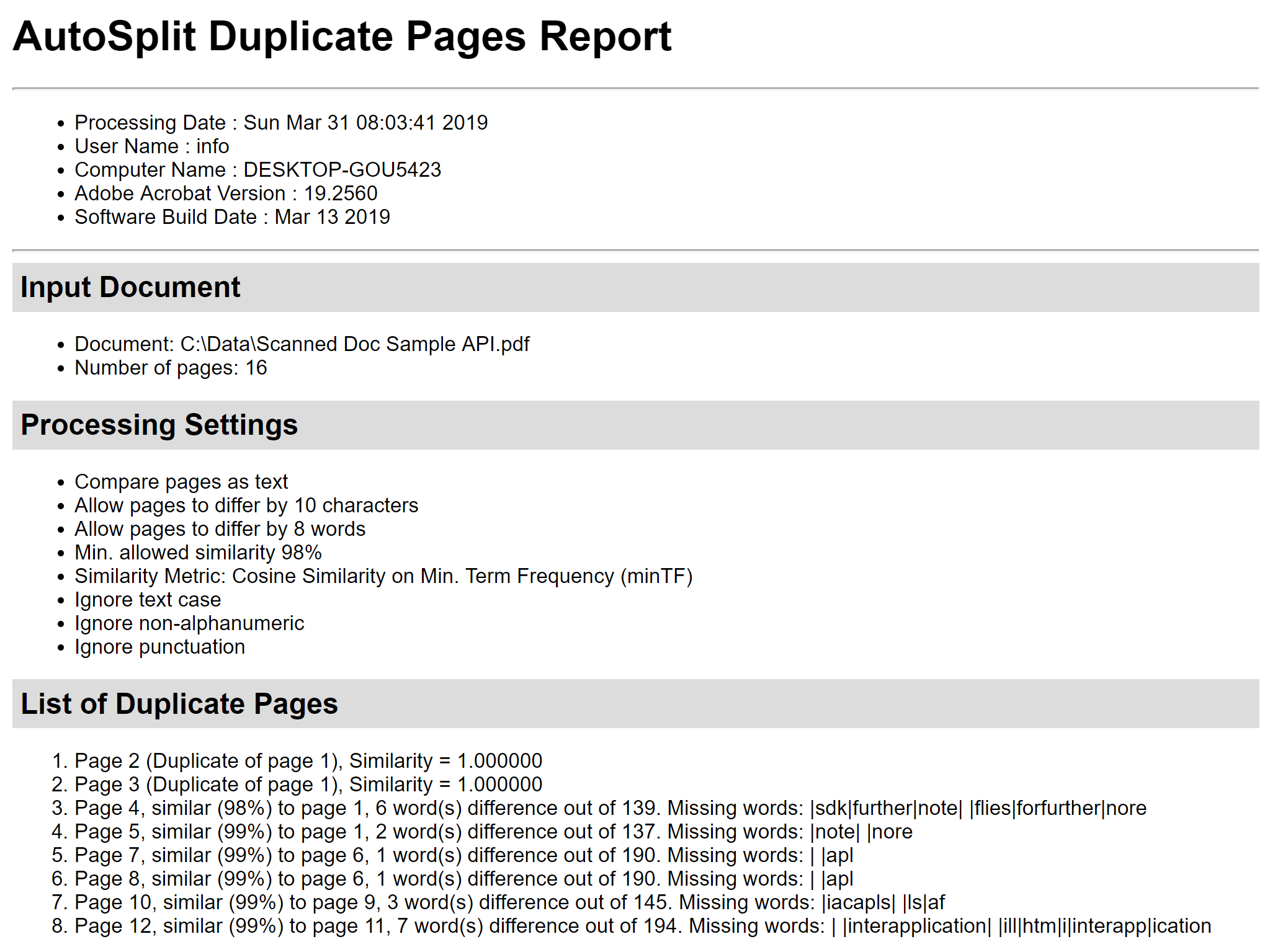 Schritt 6 – Doppelte Seiten löschen Verwenden Sie die Kontrollkästchen vor den Seiten, um Seiten zum Löschen auszuwählen bzw. nicht auszuwählen. Drücken Sie die Schaltfläche „Seiten löschen“ im Dialogfeld „Doppelte Seiten löschen“, um alle markierten Seiten aus dem aktuellen PDF-Dokument zu entfernen:
Schritt 6 – Doppelte Seiten löschen Verwenden Sie die Kontrollkästchen vor den Seiten, um Seiten zum Löschen auszuwählen bzw. nicht auszuwählen. Drücken Sie die Schaltfläche „Seiten löschen“ im Dialogfeld „Doppelte Seiten löschen“, um alle markierten Seiten aus dem aktuellen PDF-Dokument zu entfernen:.PNG) Klicken Sie zur Bestätigung auf die Schaltfläche „OK“. Die Seiten werden dauerhaft entfernt.
Klicken Sie zur Bestätigung auf die Schaltfläche „OK“. Die Seiten werden dauerhaft entfernt..PNG) Methode 2 – Überblick über das visuelle Erscheinungsbild Diese Methode vergleicht Seiten „als Bilder“ und erkennt Seiten, die genau gleich aussehen. Diese Methode vergleicht keinen unsichtbaren Text, der auf der Seite vorhanden sein könnte. Es wird nicht empfohlen, diese Methode bei gescannten Papierdokumenten anzuwenden. Schritt 1 – Öffnen einer PDF-Datei Starten Sie die Anwendung Adobe® Acrobat® und öffnen Sie eine PDF-Datei über das Menü „Datei > Öffnen…“.Schritt 2 – Öffnen Sie den Dialog „Doppelte Seiten suchen“ Wählen Sie „Plug-Ins > Dokumente teilen > Doppelte Seiten suchen und löschen…“, um den Dialog „Doppelte Seiten suchen“ zu öffnen.Schritt 3 – Einstellungen festlegen Aktivieren Sie die Option „Visuelles Erscheinungsbild für exakte Übereinstimmung vergleichen (kann für den Vergleich von Bildern verwendet werden)“
Methode 2 – Überblick über das visuelle Erscheinungsbild Diese Methode vergleicht Seiten „als Bilder“ und erkennt Seiten, die genau gleich aussehen. Diese Methode vergleicht keinen unsichtbaren Text, der auf der Seite vorhanden sein könnte. Es wird nicht empfohlen, diese Methode bei gescannten Papierdokumenten anzuwenden. Schritt 1 – Öffnen einer PDF-Datei Starten Sie die Anwendung Adobe® Acrobat® und öffnen Sie eine PDF-Datei über das Menü „Datei > Öffnen…“.Schritt 2 – Öffnen Sie den Dialog „Doppelte Seiten suchen“ Wählen Sie „Plug-Ins > Dokumente teilen > Doppelte Seiten suchen und löschen…“, um den Dialog „Doppelte Seiten suchen“ zu öffnen.Schritt 3 – Einstellungen festlegen Aktivieren Sie die Option „Visuelles Erscheinungsbild für exakte Übereinstimmung vergleichen (kann für den Vergleich von Bildern verwendet werden)“.PNG) Klicken Sie auf „OK“, um die Suche nach doppelten Seiten zu starten. Schritt 4 – Doppelte Seiten prüfen Das Dialogfeld „Doppelte Seiten löschen“ zeigt eine Liste der doppelten oder fast doppelten Seiten an. Klicken Sie auf einen Seitendatensatz, um die entsprechende Seite in der Side-by-Side-Ansicht anzuzeigen. Untersuchen Sie die Seiten und wählen Sie Seiten für eine mögliche Löschung aus bzw. heben Sie die Auswahl auf.
Klicken Sie auf „OK“, um die Suche nach doppelten Seiten zu starten. Schritt 4 – Doppelte Seiten prüfen Das Dialogfeld „Doppelte Seiten löschen“ zeigt eine Liste der doppelten oder fast doppelten Seiten an. Klicken Sie auf einen Seitendatensatz, um die entsprechende Seite in der Side-by-Side-Ansicht anzuzeigen. Untersuchen Sie die Seiten und wählen Sie Seiten für eine mögliche Löschung aus bzw. heben Sie die Auswahl auf.
.PNG) Klicken Sie optional auf „Bericht speichern…“, um einen Seitenähnlichkeitsbericht im HTML-Format zu erstellen. Oder klicken Sie auf „Lesezeichen für Seiten“, um Lesezeichen in PDF für ausgewählte doppelte Seiten zu erstellen. Bei dieser Methode werden kleinere Kopien (Stichproben) der Seiten erstellt und „als Bilder“ miteinander verglichen. Das folgende Beispiel zeigt zwei identische Seiten, die nur Grafiken und keinen durchsuchbaren Text enthalten:
Klicken Sie optional auf „Bericht speichern…“, um einen Seitenähnlichkeitsbericht im HTML-Format zu erstellen. Oder klicken Sie auf „Lesezeichen für Seiten“, um Lesezeichen in PDF für ausgewählte doppelte Seiten zu erstellen. Bei dieser Methode werden kleinere Kopien (Stichproben) der Seiten erstellt und „als Bilder“ miteinander verglichen. Das folgende Beispiel zeigt zwei identische Seiten, die nur Grafiken und keinen durchsuchbaren Text enthalten:.PNG) Wenn die Seiten visuell identisch sind, erkennt die Software sie als Duplikate:
Wenn die Seiten visuell identisch sind, erkennt die Software sie als Duplikate:.PNG) Diese beiden Seiten werden aufgrund des Stempels „Genehmigt“ auf einer der Seiten als unterschiedlich betrachtet:
Diese beiden Seiten werden aufgrund des Stempels „Genehmigt“ auf einer der Seiten als unterschiedlich betrachtet:.PNG) Diese beiden Seiten werden bei dieser Methode als identisch angesehen:
Diese beiden Seiten werden bei dieser Methode als identisch angesehen:.PNG) Im Gegensatz zur textbasierten Vergleichsmethode werden die Seiten nicht als identisch betrachtet, wenn die Farbe oder der Stil des Textes unterschiedlich ist:
Im Gegensatz zur textbasierten Vergleichsmethode werden die Seiten nicht als identisch betrachtet, wenn die Farbe oder der Stil des Textes unterschiedlich ist:.PNG) Schritt 5 – Doppelte Seiten löschen Klicken Sie auf „Seiten löschen“ im Dialog „Doppelte Seiten löschen“, um fortzufahren. Klicken Sie auf die Schaltfläche „OK“, um die Seiten aus den aktuellen PDF-Dokumenten zu löschen. Die Seiten werden dauerhaft entfernt.Vergleich mehrerer PDF-Dokumente Mit dieser Funktion können Sie doppelte Seiten in mehreren PDF-Dokumenten finden und entfernen. Der Ansatz besteht darin, ein oder mehrere Dokumente in einer einzigen PDF-Datei zu kombinieren und die Operation „Doppelte Seiten suchen und löschen“ auf die resultierende Datei anzuwenden. Dadurch wird ein einziges Dokument ohne Duplikate erstellt. Optional ist es möglich, alle gefundenen doppelten Seiten in ein separates PDF-Dokument zu extrahieren. Schritt 1 – Kombinieren mehrerer PDF-Dokumente Übersicht Starten Sie die Anwendung Adobe® Acrobat® und wählen Sie im Menü „Werkzeuge“. Wählen Sie das Symbol „Dateien kombinieren“ aus der Liste „Werkzeuge“.
Schritt 5 – Doppelte Seiten löschen Klicken Sie auf „Seiten löschen“ im Dialog „Doppelte Seiten löschen“, um fortzufahren. Klicken Sie auf die Schaltfläche „OK“, um die Seiten aus den aktuellen PDF-Dokumenten zu löschen. Die Seiten werden dauerhaft entfernt.Vergleich mehrerer PDF-Dokumente Mit dieser Funktion können Sie doppelte Seiten in mehreren PDF-Dokumenten finden und entfernen. Der Ansatz besteht darin, ein oder mehrere Dokumente in einer einzigen PDF-Datei zu kombinieren und die Operation „Doppelte Seiten suchen und löschen“ auf die resultierende Datei anzuwenden. Dadurch wird ein einziges Dokument ohne Duplikate erstellt. Optional ist es möglich, alle gefundenen doppelten Seiten in ein separates PDF-Dokument zu extrahieren. Schritt 1 – Kombinieren mehrerer PDF-Dokumente Übersicht Starten Sie die Anwendung Adobe® Acrobat® und wählen Sie im Menü „Werkzeuge“. Wählen Sie das Symbol „Dateien kombinieren“ aus der Liste „Werkzeuge“..PNG) Klicken Sie im Menü „Dateien kombinieren“ auf „Dateien hinzufügen…“ und wählen Sie die PDF-Dateien aus, die Sie zum Vergleich zusammenführen möchten.
Klicken Sie im Menü „Dateien kombinieren“ auf „Dateien hinzufügen…“ und wählen Sie die PDF-Dateien aus, die Sie zum Vergleich zusammenführen möchten..PNG) Klicken Sie auf die Schaltfläche „Kombinieren“ im Menü, um die ausgewählten PDF-Dateien zusammenzuführen.
Klicken Sie auf die Schaltfläche „Kombinieren“ im Menü, um die ausgewählten PDF-Dateien zusammenzuführen..PNG) Schritt 2 – Doppelte Seiten finden Die kombinierte PDF-Ausgabedatei wird auf dem Bildschirm angezeigt. Falls nicht, öffnen Sie die kombinierte PDF-Datei. Wählen Sie „Plug-Ins > Dokumente teilen > Doppelte Seiten suchen und löschen…“, um den Dialog „Doppelte Seiten suchen“ zu öffnen.Aktivieren Sie die Option „Visuelles Erscheinungsbild für exakte Übereinstimmung vergleichen (kann für den Vergleich von Bildern verwendet werden)“. Klicken Sie auf „OK“, um die Suche nach doppelten Seiten zu starten.
Schritt 2 – Doppelte Seiten finden Die kombinierte PDF-Ausgabedatei wird auf dem Bildschirm angezeigt. Falls nicht, öffnen Sie die kombinierte PDF-Datei. Wählen Sie „Plug-Ins > Dokumente teilen > Doppelte Seiten suchen und löschen…“, um den Dialog „Doppelte Seiten suchen“ zu öffnen.Aktivieren Sie die Option „Visuelles Erscheinungsbild für exakte Übereinstimmung vergleichen (kann für den Vergleich von Bildern verwendet werden)“. Klicken Sie auf „OK“, um die Suche nach doppelten Seiten zu starten..PNG) Schritt 3 – Doppelte Seiten extrahieren Das Dialogfeld „Doppelte Seiten löschen“ zeigt eine Liste doppelter oder nahezu doppelter Seiten an. Klicken Sie auf einen Seitendatensatz, um eine entsprechende Seite im Viewer anzuzeigen. Untersuchen Sie die Seiten und wählen Sie die Seiten aus bzw. heben Sie die Auswahl auf. Klicken Sie auf „Seiten extrahieren…“, um ausgewählte doppelte Seiten in ein neues PDF-Dokument zu extrahieren.
Schritt 3 – Doppelte Seiten extrahieren Das Dialogfeld „Doppelte Seiten löschen“ zeigt eine Liste doppelter oder nahezu doppelter Seiten an. Klicken Sie auf einen Seitendatensatz, um eine entsprechende Seite im Viewer anzuzeigen. Untersuchen Sie die Seiten und wählen Sie die Seiten aus bzw. heben Sie die Auswahl auf. Klicken Sie auf „Seiten extrahieren…“, um ausgewählte doppelte Seiten in ein neues PDF-Dokument zu extrahieren..PNG) Geben Sie einen Ausgabeordner und einen Dateinamen an. Klicken Sie auf „Speichern“, wenn Sie fertig sind.
Geben Sie einen Ausgabeordner und einen Dateinamen an. Klicken Sie auf „Speichern“, wenn Sie fertig sind..PNG) Das Dialogfeld erscheint und zeigt die Anzahl der Seiten an, die in ein separates Dokument extrahiert wurden. Jetzt haben Sie alle doppelten Seiten in einer separaten PDF-Datei gespeichert, bevor Sie sie löschen. Sie können diese Seiten prüfen und bei Bedarf später wieder verwenden. Klicken Sie auf „OK“, um den Dialog zu schließen.
Das Dialogfeld erscheint und zeigt die Anzahl der Seiten an, die in ein separates Dokument extrahiert wurden. Jetzt haben Sie alle doppelten Seiten in einer separaten PDF-Datei gespeichert, bevor Sie sie löschen. Sie können diese Seiten prüfen und bei Bedarf später wieder verwenden. Klicken Sie auf „OK“, um den Dialog zu schließen..png) Schritt 4 – Doppelte Seiten löschen Klicken Sie auf „Seiten löschen“ im Dialog „Doppelte Seiten löschen“, um fortzufahren.
Schritt 4 – Doppelte Seiten löschen Klicken Sie auf „Seiten löschen“ im Dialog „Doppelte Seiten löschen“, um fortzufahren..PNG) Klicken Sie im Dialogfeld auf „OK“, um die ausgewählten doppelten Seiten aus dem aktuellen PDF-Dokument zu löschen.
Klicken Sie im Dialogfeld auf „OK“, um die ausgewählten doppelten Seiten aus dem aktuellen PDF-Dokument zu löschen..PNG) Die ausgewählten doppelten Seiten werden dauerhaft aus dem PDF-Dokument entfernt. Sie müssen das Menü „Datei > Speichern“ verwenden, um das geänderte Dokument auf der Festplatte zu speichern. Klicken Sie hier, um eine Liste aller verfügbaren Schritt-für-Schritt-Tutorials zu erhalten.
Die ausgewählten doppelten Seiten werden dauerhaft aus dem PDF-Dokument entfernt. Sie müssen das Menü „Datei > Speichern“ verwenden, um das geänderte Dokument auf der Festplatte zu speichern. Klicken Sie hier, um eine Liste aller verfügbaren Schritt-für-Schritt-Tutorials zu erhalten.