- Die Funktion und ihre Ableitung sind beide monoton
- Ausgang ist null „zentriert“
- Optimierung ist einfacher
- Ableitung /Differenzial der Tanh-Funktion (f'(x)) liegt zwischen 0 und 1.
Nachteile:
- Die Ableitung der Tanh-Funktion leidet unter dem „Problem des verschwindenden Gradienten und des explodierenden Gradienten“.
- Langsame Konvergenz- da rechenaufwendig.(Grund für die Verwendung der mathematischen Exponentialfunktion)
„Die Tanh-Funktion ist der Sigmoidfunktion vorzuziehen, da sie nullzentriert ist und die Gradienten nicht auf eine bestimmte Richtung beschränkt sind“
3. ReLu-Aktivierungsfunktion (ReLu – Rectified Linear Units):


ReLU ist die nichtlineare Aktivierungsfunktion, die in der KI an Popularität gewonnen hat. Die ReLu-Funktion wird auch als f(x) = max(0,x) dargestellt.
- Die Funktion und ihre Ableitung sind beide monoton.
- Hauptvorteil der ReLU-Funktion- Sie aktiviert nicht alle Neuronen zur gleichen Zeit.
- Rechnerisch effizient
- Ableitung /Differenzial der Tanh-Funktion (f'(x)) wird 1, wenn f(x) > 0, sonst 0.
- Konvergiert sehr schnell
Nachteile:
- ReLu-Funktion ist nicht „null-zentrisch“, was dazu führt, dass die Gradientenaktualisierungen zu weit in verschiedene Richtungen gehen. 0 < Ausgabe < 1, und es macht die Optimierung schwieriger.
- Dead neuron is the biggest problem.This is due to Non-differentiable at zero.
„Problem of Dying neuron/Dead neuron : As the ReLu derivative f'(x) is not 0 for the positive values of the neuron (f'(x)=1 for x ≥ 0), ReLu does not saturate (exploid) and no dead neurons (Vanishing neuron)are reported. Sättigung und verschwindender Gradient treten nur für negative Werte auf, die, wenn sie ReLu gegeben werden, in 0 umgewandelt werden – dies wird das Problem des sterbenden Neurons genannt.“
4. undichte ReLu-Aktivierungsfunktion:
Die undichte ReLU-Funktion ist nichts anderes als eine verbesserte Version der ReLU-Funktion mit Einführung einer „konstanten Steigung“


- Leaky ReLU wird definiert, um das Problem des sterbenden Neurons/des toten Neurons anzugehen.
- Das Problem des absterbenden Neurons/des toten Neurons wird durch die Einführung einer kleinen Steigung angegangen, wobei die negativen Werte um α skaliert sind, was es den entsprechenden Neuronen ermöglicht, „am Leben zu bleiben“.
- Die Funktion und ihre Ableitung sind beide monoton
- Sie erlaubt negative Werte während der Rückvermehrung
- Sie ist effizient und einfach zu berechnen.
- Die Ableitung von Leaky ist 1, wenn f(x) > 0 und liegt zwischen 0 und 1, wenn f(x) < 0.
Nachteile:
- Leaky ReLU liefert keine konsistenten Vorhersagen für negative Eingangswerte.
5. ELU (Exponential Linear Units) Aktivierungsfunktion:

- ELU wird auch vorgeschlagen, um das Problem des sterbenden Neurons zu lösen.
- Keine Probleme mit toten ReLU
- Nullpunktzentriert
Nachteile:
- Rechenintensiv.
- Ähnlich wie bei Leaky ReLU ist ELU zwar theoretisch besser als ReLU, aber in der Praxis gibt es derzeit keine guten Beweise dafür, dass ELU immer besser ist als ReLU.
- f(x) ist nur monoton, wenn alpha größer oder gleich 0 ist.
- f'(x) Ableitung von ELU ist nur monoton, wenn alpha zwischen 0 und 1 liegt.
- langsame Konvergenz aufgrund der Exponentialfunktion.
6. P ReLu (Parametrische ReLU) Aktivierungsfunktion:

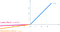
- Die Idee der leaky ReLU kann noch weiter ausgebaut werden.
- Anstatt x mit einem konstanten Term zu multiplizieren, können wir es mit einem „Hyperparameter (a-trainierbarer Parameter)“ multiplizieren, was bei der leaky ReLU besser zu funktionieren scheint. Diese Erweiterung von Leaky ReLU ist als Parametric ReLU bekannt.
- Der Parameter α ist im Allgemeinen eine Zahl zwischen 0 und 1, und er ist im Allgemeinen relativ klein.
- Hat einen leichten Vorteil gegenüber Leaky Relu aufgrund des trainierbaren Parameters.
- Handhabt das Problem des sterbenden Neurons.
Nachteile:
- Gleich wie Leaky Relu.
- f(x) ist monoton, wenn a> oder =0 und f'(x) ist monoton, wenn a =1
7. Swish (A Self-Gated) Activation Function:(Sigmoid Linear Unit)

- Google Brain Team hat eine neue Aktivierungsfunktion mit dem Namen Swish vorgeschlagen, die einfach f(x) = x – sigmoid(x) ist.
- Ihre Experimente zeigen, dass Swish bei tieferen Modellen in einer Reihe anspruchsvoller Datensätze tendenziell besser funktioniert als ReLU.
- Die Kurve der Swish-Funktion ist glatt und die Funktion ist an allen Punkten differenzierbar. Dies ist während des Modelloptimierungsprozesses hilfreich und wird als einer der Gründe dafür angesehen, dass Swish besser abschneidet als ReLU.
- Die Swish-Funktion ist „nicht monoton“. Das bedeutet, dass der Wert der Funktion auch dann sinken kann, wenn die Eingabewerte steigen.
- Funktion ist nach oben unbeschränkt und nach unten begrenzt.
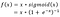
„Swish neigt dazu, kontinuierlich mit der ReLu übereinzustimmen oder sie zu übertreffen“
Beachten Sie, dass die Ausgabe der Swish-Funktion auch dann sinken kann, wenn die Eingabe steigt. Dies ist ein interessantes und Swish-spezifisches Merkmal.(Aufgrund des nicht-monotonen Charakters)
f(x)=2x*sigmoid(beta*x)
Wenn wir davon ausgehen, dass beta=0 eine einfache Version von Swish ist, die ein lernbarer Parameter ist, dann ist der sigmoide Teil immer 1/2 und f (x) ist linear. Ist beta hingegen ein sehr großer Wert, wird das Sigmoid zu einer fast zweistelligen Funktion (0 für x<0, 1 für x>0). Somit konvergiert f (x) gegen die ReLU-Funktion. Daher wird die Swish-Standardfunktion als beta = 1 gewählt. Auf diese Weise wird eine weiche Interpolation (Verknüpfung der variablen Wertemengen mit einer Funktion im gegebenen Bereich und der gewünschten Genauigkeit) bereitgestellt. Ausgezeichnet! Eine Lösung für das Problem des Verschwindens der Gradienten ist gefunden.
8.Softplus
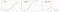
Die Softplus-Funktion ähnelt der ReLU-Funktion, ist aber relativ glatter.Funktion von Softplus oder SmoothRelu f(x) = ln(1+exp x).
Ableitung der Softplus-Funktion ist f'(x) ist logistische Funktion (1/(1+exp x)).
Funktionswert reicht von (0, + inf).Sowohl f(x) als auch f'(x) sind monoton.
9.Softmax oder normalisierte Exponentialfunktion:

Die „Softmax“-Funktion ist auch eine Art von Sigmoidfunktion, aber sie ist sehr nützlich, um Mehrklassen-Klassifikationsprobleme zu behandeln.
„Softmax kann als die Kombination mehrerer Sigmoidfunktionen beschrieben werden.“
„Die Softmax-Funktion liefert die Wahrscheinlichkeit für die Zugehörigkeit eines Datenpunktes zu jeder einzelnen Klasse.“
Beim Aufbau eines Netzwerks für ein Mehrklassenproblem würde die Ausgabeschicht so viele Neuronen wie die Anzahl der Klassen im Ziel haben.
Wenn man zum Beispiel drei Klassen hat, würde es drei Neuronen in der Ausgabeschicht geben. Angenommen, man erhält die Ausgabe der Neuronen als .Wendet man die Softmax-Funktion auf diese Werte an, erhält man das folgende Ergebnis – . Diese Werte stellen die Wahrscheinlichkeit dar, dass der Datenpunkt zu jeder Klasse gehört. Aus dem Ergebnis können wir schließen, dass die Eingabe zur Klasse A gehört.
„Beachten Sie, dass die Summe aller Werte 1 ist.“
Welche ist besser zu verwenden? Wie wählt man die richtige aus?
Um ehrlich zu sein, gibt es keine harte und schnelle Regel, um die Aktivierungsfunktion zu wählen.Wir können nicht zwischen Aktivierungsfunktionen unterscheiden.Jede Aktivierungsfunktion hat ihre eigenen Vor- und Nachteile.All das Gute und Schlechte wird auf der Grundlage der Spur entschieden werden.
Aber basierend auf den Eigenschaften des Problems könnten wir in der Lage sein, eine bessere Wahl für eine einfache und schnellere Konvergenz des Netzwerks zu treffen.
- Sigmoide Funktionen und ihre Kombinationen funktionieren im Allgemeinen besser bei Klassifizierungsproblemen
- Sigmoide und tanh-Funktionen werden manchmal aufgrund des Problems des verschwindenden Gradienten vermieden
- Die ReLU-Aktivierungsfunktion wird in der modernen Zeit häufig verwendet.
- Wenn in unseren Netzen aufgrund von ReLu tote Neuronen auftreten, ist die leaky ReLU-Funktion die beste Wahl
- Die ReLU-Funktion sollte nur in den versteckten Schichten verwendet werden
„Als Faustregel kann man mit der ReLU-Funktion beginnen und dann zu anderen Aktivierungsfunktionen übergehen, falls ReLU keine optimalen Ergebnisse liefert“