Výše uvedený obrázek vám možná dal dostatečnou představu o čem je tento příspěvek.
Tento příspěvek se zabývá některými důležitými fuzzy(ne přesně stejnými, ale hrudkovitě stejnými řetězci, řekněme RajKumar & Raj Kumar) algoritmy porovnávání řetězců, které zahrnují:
Hammingova vzdálenost
Levensteinova vzdálenost
Damerauova Levensteinova vzdálenost
Odpovídání řetězců na základě N-Gramu
Strom BK
Algoritmus Bitap
Nejprve bychom však měli vědět, proč je fuzzy porovnávání důležité vzhledem k reálnému scénáři. Kdykoli může uživatel zadat nějaká data, může se to pořádně zamotat, jako v následujícím případě!!!
Nechte,
- Jmenujete se ‚Saurav Kumar Agarwal‘.
- Dostal jste průkaz do knihovny (samozřejmě s jedinečným ID), který platí pro každého člena vaší rodiny.
- Každý týden si chodíte do knihovny vydat nějaké knihy. K tomu však musíte nejprve provést zápis do registru u vchodu do knihovny, kde zadáte své ID & jméno.
Nyní se vedení knihovny rozhodne analyzovat údaje v tomto registru, aby mělo představu o jedinečných čtenářích, kteří knihovnu každý měsíc navštíví. Nyní to může být provedeno z mnoha důvodů (například zda jít do rozšíření pozemku, nebo ne, měl by se zvýšit počet knih? atd.).
Naplánovali to tak, že spočítají (unikátní jména, ID knihovny) dvojice zaregistrované za měsíc. Takže pokud máme
123 Mehul
123 Rajesh
123 Mehul
133 Rajesh
133 Sandesh
To by nám mělo dát 4 unikátní čtenáře.
Zatím to vypadá dobře
Odhadovali, že tento počet bude kolem 10k-10. To znamená, že by se měl zvýšit počet čtenářů.5k, ale po analýze přesnou shodou řetězců jmen se čísla vyšplhala až na ~50k.
wooohhh!!!
Pěkně špatný odhad, musím říct !!!
Nebo jim tady unikl nějaký trik?
Po hlubší analýze se objevil zásadní problém. Vzpomeňte si na své jméno ‚Saurav Agarwal‘. Našli několik záznamů vedoucích k 5 různým uživatelům napříč ID vaší rodinné knihovny:
- Saurav K Aggrawal (všimněte si dvojitého „g“, „ra-ar“, Kumar se stává K)
- Saurav Kumar Agarwal
- Sourav Aggarwal
- SK Agarwal
- Agarwal
Existují určité nejasnosti, protože vedení knihovny neví
- Kolik lidí z vaší rodiny navštěvuje knihovnu? zda těchto 5 jmen představuje jednoho čtenáře, 2 nebo 3 různé čtenáře. Říkejme tomu neřízený problém, kdy máme řetězec reprezentující nestandardizovaná jména, ale jejich standardizovaná jména nejsou známa (např. Saurav Agarwal: Saurav Kumar Agarwal není znám)
- Měli by se všichni sloučit do ‚Saurav Kumar Agarwal‘? nelze říci, protože SK Agarwal může být Shivam Kumar Agarwal (řekněme jméno vašeho otce). Také jediný Agarwal může být kdokoli z rodiny.
Poslední 2 případy (SK Agarwal & Agarwal) by vyžadovaly nějaké další informace (jako pohlaví, datum narození, vydané knihy), které budou podány nějakému ML algoritmu pro určení skutečného jména čtenáře & by se mělo zatím ponechat. Ale jednou věcí jsem si celkem jistý, že 1. 3 jména představují stejnou osobu & Neměl bych potřebovat další informace, abych je sloučil do jednoho čtenáře, tj. do ‚Saurav Kumar Agarwal‘.
Jak to lze udělat?
Přichází na řadu fuzz string matching, což znamená téměř přesnou shodu mezi řetězci, které se od sebe mírně liší (většinou kvůli špatnému hláskování), například ‚Agarwal‘ & ‚Aggarwal‘ & ‚Aggrawal‘. Pokud získáme řetězec s přijatelnou mírou chybovosti (řekněme jedno chybné písmeno ), budeme jej považovat za shodu. Prozkoumejme tedy →
Hammingova vzdálenost je nejzřejmější vzdálenost vypočtená mezi dvěma stejně dlouhými řetězci, která udává počet znaků, které neodpovídají danému indexu. Například: ‚Bat‘ & ‚Bet‘ má hammingovu vzdálenost 1 jako na indexu 1, ‚a‘ se nerovná ‚e‘
Levensteinova vzdálenost/ Edit Distance
Předpokládám, že jste s Levensteinovou vzdáleností & Rekurze spokojeni. Pokud ne, přečtěte si toto. Níže uvedené vysvětlení je spíše souhrnnou verzí Levensteinovy vzdálenosti.
Nechť ‚x’=délka(Str1) & ‚y’=délka(Str2) pro celý tento příspěvek.
Levensteinova vzdálenost počítá minimální počet úprav potřebných k převodu ‚Str1‘ na ‚Str2‘ provedením buď přidání, odebrání, nebo nahrazení znaků. Proto má ‚Cat‘ & ‚Bat‘ editační vzdálenost ‚1‘ (Nahradit ‚C‘ za ‚B‘), zatímco pro ‚Ceat‘ & ‚Bat‘ by byla 2 (Nahradit ‚C‘ za ‚B‘; Odstranit ‚e‘).
Mluvíme-li o algoritmu, má většinou 5 kroků
int LevensteinDistance(string str1, string str2, int x, int y){if (x == len(str1)+1) return len(str2)-y+1;if (y == len(str2)+1) return len(str1)-x+1;if (str1 == str2)
return LevensteinDistance(str1, str2, x+ 1, y+ 1);return 1 + min(LevensteinDistance(str1, str2, x, y+ 1), #insert LevensteinDistance(str1, str2, x+ 1, y), #remove LevensteinDistance(str1, str2, x+ 1, y+ 1) #replace
}
LevenesteinDistance('abcd','abbd',1,1)
To, co děláme, je, že začínáme číst řetězce od 1. znaku
- Pokud se znak na indexu ‚x‘ řetězce str1 shoduje se znakem na indexu ‚y‘ řetězce str2, není nutná žádná úprava & vypočítáme vzdálenost úprav voláním
LevensteinDistance(str1,str2)
- Pokud se neshodují, víme, že je nutná úprava. Přičteme tedy +1 k aktuální editační_vzdálenosti & rekurzivně vypočítá editační_vzdálenost pro 3 podmínky & vybere minimální z těchto tří:
Levenstein(str1,str2) →vložení do str2.
Levenstein(str1,str2) →odstranění ve str2
Levenstein(str1,str2)→výměna ve str2
- Pokud některému z řetězců při rekurzi dojdou znaky, délka zbývajících znaků v druhém řetězci se přičte k editační vzdálenosti (1. dva příkazy if)
Demerau-Levensteinova vzdálenost
Považujte ‚abcd‘ & ‚acbd‘. Pokud bychom se řídili Levensteinovou vzdáleností, bylo by to (replace ‚b‘-‚c‘ & ‚c‘-‚b‘ na indexových pozicích 2 & 3 v str2) Ale pokud se podíváte pozorně, oba znaky se prohodily jako v str1 & pokud zavedeme novou operaci ‚Swap‘ vedle ‚addition‘, ‚ deletion‘ & ‚replace‘, lze tento problém vyřešit. Toto zavedení nám může pomoci vyřešit problémy typu ‚Agarwal‘ & ‚Agrawal‘.
Tuto operaci přidáme pomocí níže uvedeného pseudokódu
1 +
(x - last_matching_index_y - 1 ) +
(y - last_matching_index_x - 1 ) +
LevinsteinDistance(str1, str2)
Provedeme výše uvedenou operaci pro ‚abcd‘ & ‚acbd‘, kde předpokládáme
initial_x=1 & initial_y=1 (Začínáme indexovat od 1 & nikoli od 0 pro oba řetězce).
současné x=3 & y=3 tudíž str1 & str2 na ‚c‘ (abcd) & ‚b‘ (acbd) respektive.
Horní meze zahrnuty do níže uvedené operace slicing. Proto ‚qwerty‘ bude znamenat ‚qwer‘.
- last_matching_index_y bude poslední_index v str2, který se shoduje se str1 tj. 2, protože ‚c‘ v ‚acbd‘ (index 2)se shoduje s ‚c‘ v ‚abcd‘.
- last_matching_index_x bude poslední_index v str1, který se shoduje se str2 tj. 2.e 2, protože ‚b‘ v ‚abcd‘ (index 2)se shoduje s ‚b‘ v ‚acbd‘.
- Takže podle výše uvedeného pseudokódu DemarauLevenstein(‚abc‘,’acb‘)=
1+(4-3-1) + (4-3-1)+LevensteinDistance(‚a‘,’a‘)=1+0+0+0=1. To by bylo 2, kdybychom se řídili Levensteinovou vzdáleností
N-Gram
N-gram není v podstatě nic jiného než množina hodnot vytvořená z řetězce párováním postupně se vyskytujících ‚n‘ znaků/slov. Například: n-gram s n=2 pro ‚abcd‘ bude ‚ab‘,’bc‘,’cd‘.
Nyní lze tyto n-gramy generovat pro řetězce, jejichž podobnost je třeba změřit &, k měření podobnosti lze použít různé metriky.
Nechť ‚abcd‘ & ‚acbd‘ jsou 2 řetězce, které mají být porovnány.
n-gramy s n=2 pro
‚abcd’=ab,bc,cd
‚acbd’=ac,cb,bd
Složka shody (qgramy)
Počet n-gramů shodných přesně pro tyto dva řetězce. Zde by to bylo 0
Kosinová podobnost
Výpočet bodového součinu po převedení n-gramů vygenerovaných pro řetězce na vektory
Shoda komponent (bez ohledu na pořadí)
Shoda komponent n-gramů bez ohledu na pořadí prvků uvnitř, tj. bc=cb.
Existuje mnoho dalších takových metrik jako Jaccardova vzdálenost, Tverského index atd. které zde nebyly diskutovány.
Strom BK
Strom BK patří mezi nejrychlejší algoritmy pro zjištění podobných řetězců (ze souboru řetězců) pro daný řetězec. Strom BK používá
- Levensteinovu vzdálenost
- Trojúhelníkovou nerovnost (budeme se jí zabývat na konci této části)
pro zjištění podobných řetězců(& ne jen jednoho nejlepšího řetězce).
Strom BK se vytváří pomocí fondu slov z dostupného slovníku. Řekněme, že máme slovník D={Kniha, Books, Cake, Boo, Boon, Cook, Cape, Cart}
Strom BK se vytvoří takto
- Vyberte kořenový uzel (může to být libovolné slovo). Nechť je to ‚Books‘
- Projděte každé slovo W ve slovníku D, vypočítejte jeho Levensteinovu vzdálenost s kořenovým uzlem a udělejte ze slova W potomka kořene, pokud pro rodiče neexistuje potomek se stejnou Levensteinovou vzdáleností. Vložení Books & Cake.
Levenstein(Books,Book)=1 & Levenstein(Books,Cake)=4. Protože pro ‚Book‘ nebylo nalezeno žádné dítě se stejnou vzdáleností, vytvořte z nich nové děti pro kořen.
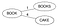
- Pokud pro rodiče P existuje dítě se stejnou Levensteinovou vzdáleností, považujte nyní toto dítě za rodiče P1 pro toto slovo W, vypočítejte Levenstein(rodič, slovo) a pokud pro rodiče P1 neexistuje žádné dítě se stejnou vzdáleností, vytvořte slovo W jako nové dítě pro P1, jinak pokračujte dále po stromě.
Zvažte vložení slova Boo. Levenstein(Book, Boo)=1, ale již existuje dítě se stejnou, tj. Books. Proto nyní vypočítejte Levenstein(Knihy, Boo)=2. Protože pro Books neexistuje žádný potomek se stejnou vzdáleností, udělejte z Boo potomka Books.

Podobně, vložíme všechna slova ze slovníku do BK stromu

Jakmile je BK strom připraven, pro vyhledávání podobných slov pro dané slovo (Query word) musíme nastavit tolerance_threshold řekněme ‚t‘.
- To je maximální editační_vzdálenost, kterou budeme uvažovat pro podobnost mezi libovolným uzlem & dotazového_slova. Cokoli nad tuto hodnotu bude odmítnuto.
- Také budeme pro porovnání s uzlem Query brát v úvahu pouze ty potomky nadřazeného uzlu, u kterých je Levenstein(Child, Parent) uvnitř
proč? o tom bude řeč za chvíli
- Pokud tato podmínka pro dítě platí, pak budeme počítat pouze Levenstein(Child, Query), který bude považován za podobný dotazu, pokud
Levenshtein(Child, Query)≤t.
- Tudíž nebudeme počítat Levensteinovu vzdálenost pro všechny uzly/slova ve Slovníku se slovem dotazu & tudíž ušetříme mnoho času, když je fond slov obrovský
Tudíž, aby Dítě bylo podobné Dotazu, jestliže
- Levenstein(Rodič, Dotaz)-t ≤ Levenstein(Dítě,Rodič) ≤ Levenstein(Rodič,Dotaz)+t
- Levenstein(Dítě,Dotaz)≤t
Projděme si rychle příklad. Nechť ‚t’=1
Nechť slovo, pro které potřebujeme najít podobná slova, je ‚Péče‘ (slovo dotazu)
- Levenstein(Kniha,Péče)=4. Protože 4>1, ‚Kniha‘ je zamítnuto. Nyní budeme uvažovat pouze ty potomky slova ‚Kniha‘, které mají LevisteinDistance(Dítě,’Kniha‘) mezi 3(4-1) & 5(4+1). Proto bychom odmítli ‚Knihy‘ & všechny její děti, protože 1 neleží v množině mezí
- Jako Levenstein(Dort, Kniha)=4, která leží mezi 3 & 5, budeme kontrolovat Levenstein(Dort, Péče)=1, což je ≤1 tedy podobné slovo.
- Přepočteme-li hranice, pro Cakeovy děti se stanou 0(1-1) & 2(1+1)
- Jelikož oba Cape & Cart má Levenstein(Child, Parent)=1 & respektive 2, oba jsou způsobilé k tomu, aby byly testovány pomocí ‚Care‘.
- Jelikož Levenstein(Cape,Care)=1 ≤1& Levenstein(Cart,Care)=2>1, pouze Cape je považováno za podobné slovo k ‚Care‘.
Zjistili jsme tedy 2 slova podobná slovu ‚Care‘, která jsou: Dort & Mys
Ale na základě čeho se rozhodujeme nad hranicemi
Levenstein(Rodič,Dotaz)-t, Levenstein(Rodič,Dotaz)+t.
pro jakýkoli podřízený uzel?
To vyplývá z nerovnosti trojúhelníku, která říká
Vzdálenost (A,B) + Vzdálenost(B,C)≥Vzdálenost(A,C), kde A,B,C jsou strany trojúhelníku.
Jak nám tato myšlenka pomůže dostat se k těmto mezím, si ukážeme:
Nechť Query,=Q Parent=P & Child=C tvoří trojúhelník s Levensteinovou vzdáleností jako délkou hrany. Nechť ‚t‘ je toleranční_prahová hodnota. Pak podle výše uvedené nerovnosti
Levenstein(P,C) + Levenstein(P,Q)≥Levenstein(C,Q)as Levenstein(C, Q) can't exceed 't'(threshold set earlier for C to be similar to Q), HenceLevenstein(P,C) + Levenstein(P,Q)≥ t
OrLevenstein(P,C)≥|Levenstein(P,Q)-t| i.e the lower limit is set
Podle trojúhelníkové nerovnosti,
Levenstein(P,Q) + Levenstein(C,Q) ≥ Levenstein(P,C) or
Levenstein(P,Q) + t ≥ Levenstein(P,C) or the upper limit is set
Algoritmus Bitap
Je to také velmi rychlý algoritmus, který lze poměrně efektivně použít pro fuzzy porovnávání řetězců. Je to proto, že používá bitové operace &, protože jsou poměrně rychlé, algoritmus je známý svou rychlostí. Bez zbytečných řečí začněme:
Nechť S0=’ababc‘ je vzor, který má být porovnán s řetězcem S1=’abdabababc‘.
Nejprve
- Zjistěte všechny jedinečné znaky v S1 & S0, které jsou a,b,c,d
- Vytvořte bitové vzory pro každý znak. Jak?“

- Převraťte hledaný vzor S0
- Pro bitový vzor pro znak x umístěte 0 tam, kde se vyskytuje ve vzoru, jinak 1. V T se ‚a‘ vyskytuje na 3. & 5. místě, na tyto pozice jsme umístili 0 & zbytek 1.
Podobně vytvoříme všechny ostatní bitové vzory pro různé znaky ve slovníku.
S0=abababc S1=abdabababc
- Přijmeme počáteční stav bitového vzoru délky(S0) se všemi 1. V našem případě by to bylo 11111 (stav S).
- Když začneme hledat v S1 a projdeme libovolný znak,
přesuneme 0 na nejspodnější bit, tj. 5. bit zprava v S &
OR operace na S s T.
Jakmile se tedy v S1 setkáme s 1. znakem ‚a‘, provedeme
- levý posun 0 v S na nejspodnějším bitu a vytvoříme 11111 →11110
- 11010 | 11110=11110
Nyní, jakmile přejdeme na 2. znak ‚b‘
- posun 0 do S i.e do tvaru 11110 →11100
- S |T=11100 | 10101=11101
Jakmile narazíme na ‚d‘
- Přesuňte 0 na S do tvaru 11101 →11010
- S |T=11010 |11111=11111
Všimněte si, že jelikož ‚d‘ není v S0, stav S se vynuluje. Po projití celého S1 se u každého znaku zobrazí následující stavy

Jak poznám, zda jsem našel nějakou fuzz/plnou shodu?
- Pokud 0 dosáhne nejvyššího bitu v bitovém vzoru stavu S (jako v posledním znaku „c“), máte úplnou shodu
- Pro fuzz shodu pozorujte 0 na různých pozicích stavu S. Pokud je 0 na 4. místě, našli jsme 4/5 znaků ve stejném pořadí jako v S0. Podobně pro 0 na dalších místech.
Jednu věc jste si mohli všimnout, že všechny tyto algoritmy pracují s hláskovou podobností řetězců. Může existovat nějaké jiné kritérium pro fuzzy shodu? Ano,
Fonetika
Příště se budeme zabývat fonetickými (zvukově založenými, jako Saurav & Sourav, měl by mít přesnou shodu ve fonetice) algoritmy fuzzy shody !!!
- Zmenšování rozměrů (3 díly)
- Algoritmy NLP(5 dílů)
- Základy učení s posilováním (5 dílů)
- Začínáme časem.řadami (7 dílů)
- Detekce objektů pomocí YOLO (3 díly)
- Tensorflow pro začátečníky (koncepty + příklady) (4 díly)
- Předzpracování časových řad (s kódy)
- Datová analýza pro začátečníky
- Statistika pro začátečníky (4 díly)