Úvod Tento výukový program ukazuje, jak vyhledat a případně odstranit podobné nebo duplicitní stránky ve stejném dokumentu PDF pomocí modulu plug-in AutoSplit™ pro Adobe® Acrobat®. Tato operace zjistí podobné stránky a předloží je uživateli k posouzení. Uživatel si může prohlédnout výsledky a vybrat/nevybrat jednotlivé stránky ze seznamu duplicit pro případné odstranění nebo vyjmutí. Můžete provádět následující operace:
- Vyhledat duplicitní a téměř duplicitní stránky
- Označit duplicitní stránky
- Vyjmout duplicitní stránky do samostatného dokumentu PDF
- Odstranit duplicitní stránky z dokumentu
- Uložit zprávu o podobnosti stránek
Zásuvný modul poskytuje dvě různé metody detekce duplicitních nebo téměř duplicitních stránek: Tuto metodu použijte k porovnání textu stránky bez ohledu na její vizuální vzhled. Vypočítává podobnost stránek pouze na základě textového obsahu a zcela ignoruje vzhled textu, rozvržení, obrázky a grafiku, které mohou být na stránce přítomny. Je to nejlepší metoda pro odhalení duplicit ve většině typů dokumentů. Porovnání vizuálního vzhledu stránek Tato metoda porovnává stránky „jako obrázky“ a detekuje stránky, které vypadají úplně stejně. Tato metoda neporovnává žádný neviditelný text, který může být na stránce přítomen. Tuto metodu se nedoporučuje používat u naskenovaných papírových dokumentů. Použití naskenovaných papírových dokumentů Poměrně často se tato operace používá k nalezení duplicitních stránek v naskenovaných papírových dokumentech. Naskenované dokumenty je třeba před použitím pro jakékoli zpracování textu OCR. OCR je proces rozpoznávání textu v naskenovaných dokumentech a umožňuje jejich prohledávání. Je nutné si uvědomit, že rozpoznávání textu v naskenovaných dokumentech je náchylné k chybám a málokdy je stoprocentně přesné. Počet chyb závisí na rozlišení skenování a kvalitě původního dokumentu. Ve většině běžných případů může naskenovaná stránka obsahovat 1 až 10 chyb rozpoznávání, kdy jsou některá písmena nesprávně identifikována. Například malé písmeno l může v závislosti na písmu vypadat přesně jako číslice 1 . Velké písmeno O je často chybně identifikováno jako číslice 0 nebo velké písmeno S jako číslice 5 atd. Vzhledem k tomu, že mnoho alfanumerických symbolů má podobné nebo stejné fyzické vlastnosti, představuje rozlišování často problém. Proto přichází vhod porovnávání na základě podobnosti, které umožňuje odhalit drobné rozdíly mezi stránkami vzniklými v procesu rozpoznávání textu. Naskenované dokumenty nízké kvality mohou obsahovat velké množství chyb, což je činí nepoužitelnými pro jakékoli spolehlivé porovnávání textu. Podívejte se na následující návod, jak rozpoznat OCR naskenovaných dokumentů a posoudit jejich vhodnost pro zpracování na základě textu. . Předpoklady K použití tohoto návodu potřebujete mít v počítači nainstalovanou kopii aplikace Adobe® Acrobat® spolu s doplňkem AutoSplit™. Můžete si stáhnout zkušební verze Adobe® Acrobat® i modulu plug-in AutoSplit™. Obsah
- Pouze porovnání textu stránky
- Pouze porovnání vizuálního vzhledu
- Pouze porovnání více dokumentů
Metoda 1 – Přehled porovnání pouze textu stránky Tato metoda porovnává podobnost stránek pouze na základě jejich obsahu. Vizuální vzhled, pozice a pořadí textu jsou irelevantní. Tato metoda také ignoruje případné obrázky a grafiku přítomné na stránkách. K výpočtu toho, jak jsou si dvě stránky podobné na základě jejich textového obsahu, se používá modifikovaná kosinová metrika podobnosti. Krok 1 – Otevření souboru PDF Spusťte aplikaci Adobe® Acrobat® a otevřete soubor PDF pomocí nabídky „File > Open…“..PNG) Krok 2 – Otevřete dialogové okno „Najít duplicitní stránky“ Výběrem možnosti „Plug-Ins > Split Documents > Find and Delete Duplicate Pages…“ otevřete dialogové okno „Find Duplicate Pages“.
Krok 2 – Otevřete dialogové okno „Najít duplicitní stránky“ Výběrem možnosti „Plug-Ins > Split Documents > Find and Delete Duplicate Pages…“ otevřete dialogové okno „Find Duplicate Pages“..PNG) Krok 3 – Určení nastavení Zaškrtněte možnost „Porovnávat pouze text stránek (ignorovat vizuální vzhled stránek)“.
Krok 3 – Určení nastavení Zaškrtněte možnost „Porovnávat pouze text stránek (ignorovat vizuální vzhled stránek)“..PNG) Použití předdefinovaných nastavení Metoda založená na textu poskytuje řadu předdefinovaných sad parametrů, které jsou vhodné pro porovnávání různých druhů dokumentů s různým množstvím chyb rozpoznávání. Každá předdefinovaná sada parametrů poskytuje různé podmínky pro výpočet podobnosti:
Použití předdefinovaných nastavení Metoda založená na textu poskytuje řadu předdefinovaných sad parametrů, které jsou vhodné pro porovnávání různých druhů dokumentů s různým množstvím chyb rozpoznávání. Každá předdefinovaná sada parametrů poskytuje různé podmínky pro výpočet podobnosti:
- Vlastní nastavení – všechna nastavení určuje uživatel
- Skenovaný papírový dokument: Vysoká kvalita
- Skenovaný papírový dokument: Střední kvalita
- Faxový dokument: Nízká kvalita
- Neskenovaný PDF: přesná shoda
- Neskenovaný PDF: fuzzy shoda
- Přesná shoda (s pořadím textu)- tato metoda nepoužívá kosinovou podobnost
.PNG) Nastavení se zobrazí pod nabídkou po výběru předdefinované sady parametrů.
Nastavení se zobrazí pod nabídkou po výběru předdefinované sady parametrů..PNG) Zde jsou uvedena nastavení používaná předdefinovanými sadami:
Zde jsou uvedena nastavení používaná předdefinovanými sadami:.PNG) Kliknutím na „Upravit…“ upravíte nastavení podobnosti stránek:
Kliknutím na „Upravit…“ upravíte nastavení podobnosti stránek:.PNG) Metoda porovnávání textů používá 3 parametry k omezení toho, jak rozdílné mohou být dvě „podobné“ stránky. Změnou těchto parametrů je možné odhalit stránky, které mají různý stupeň podobnosti.
Metoda porovnávání textů používá 3 parametry k omezení toho, jak rozdílné mohou být dvě „podobné“ stránky. Změnou těchto parametrů je možné odhalit stránky, které mají různý stupeň podobnosti.
- Minimální povolená podobnost textu stránky (v procentech) – jedná se o hodnotu metriky kosinové podobnosti vyjádřenou v procentech. Zadejte minimální povolenou podobnost textu stránky mezi 70 a 100 (v procentech).
- Maximální povolený rozdíl délky stránky (ve znacích).
- Maximální povolený rozdíl textu stránky (ve slovech).
Tato nastavení slouží k experimentování s nastavením zpracování, pokud je nutné upravit algoritmus zpracování pro konkrétní dokument..PNG) Použít vzorové stránky Volitelně můžete kliknutím na „Nastavit ze vzorové stránky…“ zadat nastavení podobnosti stránek na základě dvou vzorových stránek:
Použít vzorové stránky Volitelně můžete kliknutím na „Nastavit ze vzorové stránky…“ zadat nastavení podobnosti stránek na základě dvou vzorových stránek:
.PNG) Vyberte dvě stránky, které lze považovat za identické. Program automaticky vypočítá podobnost stránek a statistika se zobrazí v levém dolním rohu dialogového okna. Kliknutím na tlačítko „OK“ uložte aktuální nastavení podobnosti.
Vyberte dvě stránky, které lze považovat za identické. Program automaticky vypočítá podobnost stránek a statistika se zobrazí v levém dolním rohu dialogového okna. Kliknutím na tlačítko „OK“ uložte aktuální nastavení podobnosti..PNG) Zadejte možnosti filtrování textu Existuje několik parametrů, které řídí obsah stránky, který je analyzován algoritmem porovnávání textu. Tyto možnosti použijte při porovnávání naskenovaných papírových dokumentů, které mohou obsahovat různé chyby při rozpoznávání textu. Tyto volby vylučují ze zpracování určitý druh znaků. V mnoha případech mohou pomoci vypočítat přesnější metriku podobnosti.
Zadejte možnosti filtrování textu Existuje několik parametrů, které řídí obsah stránky, který je analyzován algoritmem porovnávání textu. Tyto možnosti použijte při porovnávání naskenovaných papírových dokumentů, které mohou obsahovat různé chyby při rozpoznávání textu. Tyto volby vylučují ze zpracování určitý druh znaků. V mnoha případech mohou pomoci vypočítat přesnější metriku podobnosti.
- Ignorovat velikost písmen textu – tato volba při porovnávání textu ignoruje velikost písmen.
- Ignorovat interpunkci (,.!?-) – tato volba vylučuje z porovnávání všechny interpunkční znaky.
- Ignorovat nealfanumerické znaky – tato volba ignoruje všechny znaky kromě písmen a číslic.
Kliknutím na tlačítko „OK“ uložíte nastavení podobnosti stránek..PNG) Kliknutím na „OK“ zahájíte vyhledávání duplicitních stránek v aktuálním dokumentu PDF:
Kliknutím na „OK“ zahájíte vyhledávání duplicitních stránek v aktuálním dokumentu PDF:.PNG) Krok 4 – Kontrola duplicitních stránek Dialogové okno „Odstranit duplicitní stránky“ zobrazí seznam duplicitních nebo téměř duplicitních stránek. Klepnutím na záznam stránky zobrazíte odpovídající stránku v prohlížeči. Prohlédněte si stránky a vyberte/nevyberte stránky k odstranění. Volitelně můžete kliknutím na tlačítko „Uložit zprávu…“ vytvořit zprávu o podobnosti stránek ve formátu HTML. Nebo klikněte na „Bookmark Pages“ (Záložky stránek) pro vytvoření záložek ve formátu PDF pro vybrané duplicitní stránky.
Krok 4 – Kontrola duplicitních stránek Dialogové okno „Odstranit duplicitní stránky“ zobrazí seznam duplicitních nebo téměř duplicitních stránek. Klepnutím na záznam stránky zobrazíte odpovídající stránku v prohlížeči. Prohlédněte si stránky a vyberte/nevyberte stránky k odstranění. Volitelně můžete kliknutím na tlačítko „Uložit zprávu…“ vytvořit zprávu o podobnosti stránek ve formátu HTML. Nebo klikněte na „Bookmark Pages“ (Záložky stránek) pro vytvoření záložek ve formátu PDF pro vybrané duplicitní stránky..PNG) Zásuvný modul umožňuje zobrazit náhled/porovnat nalezené duplicitní nebo téměř duplicitní stránky. Pro každou dvojici stránek se zobrazí podobnost stránek (v %) a počet neshodných slov. Zde jsou příklady vypočtené pro dvojici naskenovaných papírových dokumentů:
Zásuvný modul umožňuje zobrazit náhled/porovnat nalezené duplicitní nebo téměř duplicitní stránky. Pro každou dvojici stránek se zobrazí podobnost stránek (v %) a počet neshodných slov. Zde jsou příklady vypočtené pro dvojici naskenovaných papírových dokumentů:.PNG)
.PNG) Všimněte si, že vzhled a umístění textu nemají na výsledky vliv. Tyto dvě stránky jsou považovány za identické i přes rozdíl v barvě textu:
Všimněte si, že vzhled a umístění textu nemají na výsledky vliv. Tyto dvě stránky jsou považovány za identické i přes rozdíl v barvě textu:.PNG) Tyto dvě stránky jsou považovány za identické i přes rozdíl v uspořádání obsahu:
Tyto dvě stránky jsou považovány za identické i přes rozdíl v uspořádání obsahu:.PNG) Tyto dvě stránky jsou považovány za 94% podobné i přes rozdíl v pořadí textu, rozložení a absenci obrázku:
Tyto dvě stránky jsou považovány za 94% podobné i přes rozdíl v pořadí textu, rozložení a absenci obrázku:.PNG) Krok 5 – Výpis nebo záložka Duplicitní stránky Volitelně můžete použít tlačítko „Záložka stránek“ pro záložkování všech označených stránek. To je užitečné, pokud neplánujete nalezené duplicitní stránky z dokumentu odstranit. Pomocí zaškrtávacích políček před stránkami je můžete vybrat/odebrat ze sady pro zpracování. Pomocí tlačítka „Extrahovat stránky….“ extrahujte všechny označené stránky do samostatného dokumentu PDF. Tato operace neodstraní stránky z aktuálního dokumentu.
Krok 5 – Výpis nebo záložka Duplicitní stránky Volitelně můžete použít tlačítko „Záložka stránek“ pro záložkování všech označených stránek. To je užitečné, pokud neplánujete nalezené duplicitní stránky z dokumentu odstranit. Pomocí zaškrtávacích políček před stránkami je můžete vybrat/odebrat ze sady pro zpracování. Pomocí tlačítka „Extrahovat stránky….“ extrahujte všechny označené stránky do samostatného dokumentu PDF. Tato operace neodstraní stránky z aktuálního dokumentu.
.PNG) Pomocí tlačítka „Uložit zprávu…“ uložíte zprávu o výpočtu podobnosti stránek do souboru HTML. Obsahuje podrobnosti o podobnosti stránek, zobrazuje rozdíly mezi stránkami a seznam chybějících slov. Může být velmi užitečná pro hloubkovou analýzu.
Pomocí tlačítka „Uložit zprávu…“ uložíte zprávu o výpočtu podobnosti stránek do souboru HTML. Obsahuje podrobnosti o podobnosti stránek, zobrazuje rozdíly mezi stránkami a seznam chybějících slov. Může být velmi užitečná pro hloubkovou analýzu.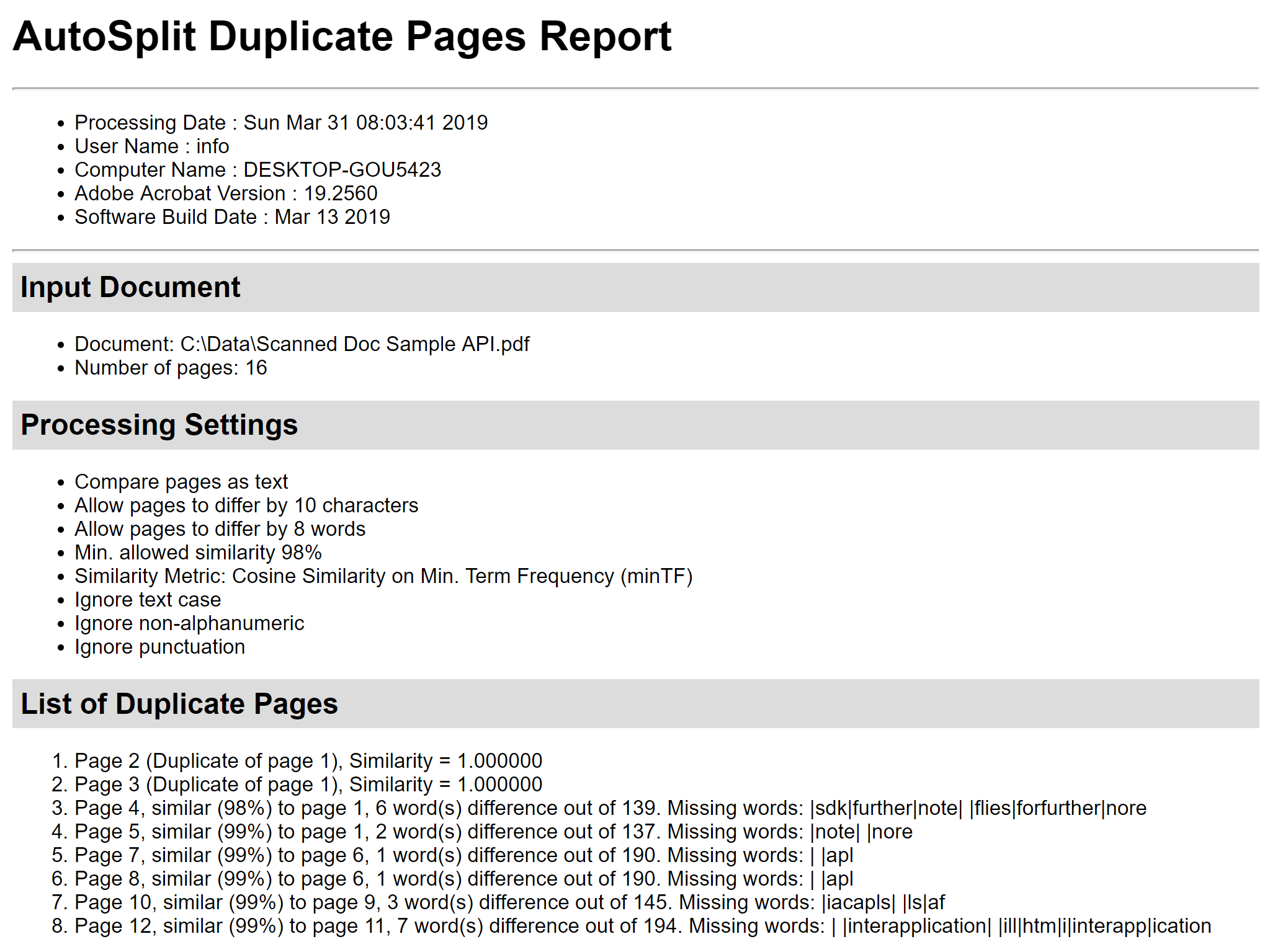 Krok 6 – Odstranění duplicitních stránek Pomocí zaškrtávacích políček před stránkami vyberte/nevyberte stránky, které mají být odstraněny. Stisknutím tlačítka „Odstranit stránky“ v dialogovém okně „Odstranit duplicitní stránky“ odstraníte všechny zaškrtnuté stránky z aktuálního dokumentu PDF:
Krok 6 – Odstranění duplicitních stránek Pomocí zaškrtávacích políček před stránkami vyberte/nevyberte stránky, které mají být odstraněny. Stisknutím tlačítka „Odstranit stránky“ v dialogovém okně „Odstranit duplicitní stránky“ odstraníte všechny zaškrtnuté stránky z aktuálního dokumentu PDF:.PNG) Potvrďte kliknutím na tlačítko „OK“. Stránky budou trvale odstraněny.
Potvrďte kliknutím na tlačítko „OK“. Stránky budou trvale odstraněny..PNG) Metoda 2 – Porovnání pouze vizuálního vzhledu přehled Tato metoda porovnává stránky „jako obrázky“ a detekuje stránky, které vypadají úplně stejně. Tato metoda neporovnává žádný neviditelný text, který může být na stránce přítomen. Tuto metodu se nedoporučuje používat u naskenovaných papírových dokumentů. Krok 1 – Otevření souboru PDF Spusťte aplikaci Adobe® Acrobat® a otevřete soubor PDF pomocí nabídky „File > Open…“.Krok 2 – Otevřete dialogové okno „Najít duplicitní stránky“ Výběrem možnosti „Plug-Ins > Split Documents > Find and Delete Duplicate Pages…“ otevřete dialogové okno „Najít duplicitní stránky“.Krok 3 – Určení nastavení Zaškrtněte možnost „Porovnat vizuální vzhled pro přesnou shodu (lze použít pro porovnání obrázků)“.
Metoda 2 – Porovnání pouze vizuálního vzhledu přehled Tato metoda porovnává stránky „jako obrázky“ a detekuje stránky, které vypadají úplně stejně. Tato metoda neporovnává žádný neviditelný text, který může být na stránce přítomen. Tuto metodu se nedoporučuje používat u naskenovaných papírových dokumentů. Krok 1 – Otevření souboru PDF Spusťte aplikaci Adobe® Acrobat® a otevřete soubor PDF pomocí nabídky „File > Open…“.Krok 2 – Otevřete dialogové okno „Najít duplicitní stránky“ Výběrem možnosti „Plug-Ins > Split Documents > Find and Delete Duplicate Pages…“ otevřete dialogové okno „Najít duplicitní stránky“.Krok 3 – Určení nastavení Zaškrtněte možnost „Porovnat vizuální vzhled pro přesnou shodu (lze použít pro porovnání obrázků)“..PNG) Kliknutím na „OK“ zahájíte vyhledávání duplicitních stránek. Krok 4 – Kontrola duplicitních stránek V dialogovém okně „Odstranit duplicitní stránky“ se zobrazí seznam duplicitních nebo téměř duplicitních stránek. Kliknutím na záznam stránky zobrazíte odpovídající stránku v zobrazení vedle sebe. Prohlédněte si stránky a vyberte/nevyberte stránky pro případné odstranění.
Kliknutím na „OK“ zahájíte vyhledávání duplicitních stránek. Krok 4 – Kontrola duplicitních stránek V dialogovém okně „Odstranit duplicitní stránky“ se zobrazí seznam duplicitních nebo téměř duplicitních stránek. Kliknutím na záznam stránky zobrazíte odpovídající stránku v zobrazení vedle sebe. Prohlédněte si stránky a vyberte/nevyberte stránky pro případné odstranění..PNG) Volitelně můžete kliknutím na tlačítko „Uložit zprávu…“ vytvořit zprávu o podobnosti stránek ve formátu HTML. Nebo klikněte na „Záložky stránek“ pro vytvoření záložek ve formátu PDF pro vybrané duplicitní stránky. Tato metoda je založena na vytvoření menších (výběrových) kopií stránek a jejich porovnání „jako obrázků“. Následující příklad ukazuje dvě identické stránky, které obsahují pouze grafiku a žádný text, v němž lze vyhledávat:
Volitelně můžete kliknutím na tlačítko „Uložit zprávu…“ vytvořit zprávu o podobnosti stránek ve formátu HTML. Nebo klikněte na „Záložky stránek“ pro vytvoření záložek ve formátu PDF pro vybrané duplicitní stránky. Tato metoda je založena na vytvoření menších (výběrových) kopií stránek a jejich porovnání „jako obrázků“. Následující příklad ukazuje dvě identické stránky, které obsahují pouze grafiku a žádný text, v němž lze vyhledávat:.PNG) Pokud jsou stránky vizuálně totožné, software je rozpozná jako duplikáty:
Pokud jsou stránky vizuálně totožné, software je rozpozná jako duplikáty:.PNG) Tyto dvě stránky jsou považovány za odlišné díky razítku „Schváleno“ na jedné ze stránek:
Tyto dvě stránky jsou považovány za odlišné díky razítku „Schváleno“ na jedné ze stránek:.PNG) Tyto dvě stránky jsou podle této metody považovány za totožné:
Tyto dvě stránky jsou podle této metody považovány za totožné:.PNG) Na rozdíl od metody porovnávání na základě textu, pokud se barva nebo styl textu liší, nejsou stránky považovány za totožné:
Na rozdíl od metody porovnávání na základě textu, pokud se barva nebo styl textu liší, nejsou stránky považovány za totožné:
.PNG) Krok 5 – Odstranění duplicitních stránek Pro pokračování klikněte na „Odstranit stránky“ v dialogovém okně „Odstranit duplicitní stránky“. Kliknutím na tlačítko „OK“ odstraníte stránky z aktuálních dokumentů PDF. Stránky budou trvale odstraněny.Porovnání více dokumentů PDF Tuto operaci lze použít k nalezení a odstranění duplicitních stránek z více dokumentů PDF. Postup spočívá ve spojení jednoho nebo více dokumentů do jednoho souboru PDF a spuštění operace „Najít a odstranit duplicitní stránky“ na výsledném souboru. Tím v podstatě vznikne jediný dokument bez duplicit. Volitelně je možné všechny zjištěné duplicitní stránky vyjmout do samostatného dokumentu PDF. Krok 1 – Spojení více dokumentů PDF přehled Spusťte aplikaci Adobe® Acrobat® a v nabídce vyberte „Nástroje“. V seznamu Nástroje vyberte ikonu „Spojit soubory“.
Krok 5 – Odstranění duplicitních stránek Pro pokračování klikněte na „Odstranit stránky“ v dialogovém okně „Odstranit duplicitní stránky“. Kliknutím na tlačítko „OK“ odstraníte stránky z aktuálních dokumentů PDF. Stránky budou trvale odstraněny.Porovnání více dokumentů PDF Tuto operaci lze použít k nalezení a odstranění duplicitních stránek z více dokumentů PDF. Postup spočívá ve spojení jednoho nebo více dokumentů do jednoho souboru PDF a spuštění operace „Najít a odstranit duplicitní stránky“ na výsledném souboru. Tím v podstatě vznikne jediný dokument bez duplicit. Volitelně je možné všechny zjištěné duplicitní stránky vyjmout do samostatného dokumentu PDF. Krok 1 – Spojení více dokumentů PDF přehled Spusťte aplikaci Adobe® Acrobat® a v nabídce vyberte „Nástroje“. V seznamu Nástroje vyberte ikonu „Spojit soubory“..PNG) V nabídce „Combine Files“ (Sloučit soubory) klikněte na „Add Files…“ (Přidat soubory…) a vyberte soubory PDF ke sloučení za účelem porovnání.
V nabídce „Combine Files“ (Sloučit soubory) klikněte na „Add Files…“ (Přidat soubory…) a vyberte soubory PDF ke sloučení za účelem porovnání..PNG) Klikněte na tlačítko „Combine“ (Sloučit) v nabídce pro sloučení vybraných souborů PDF.
Klikněte na tlačítko „Combine“ (Sloučit) v nabídce pro sloučení vybraných souborů PDF..PNG) Krok 2 – Vyhledání duplicitních stránek Na obrazovce by se objevil sloučený výstupní soubor PDF. Pokud tomu tak není, otevřete kombinovaný soubor PDF. Výběrem možnosti „Plug-Ins > Split Documents > Find and Delete Duplicate Pages…“ otevřete dialogové okno „Find Duplicate Pages“.Zaškrtněte možnost „Porovnat vizuální vzhled pro přesnou shodu (lze použít pro porovnání obrázků)“. Klepnutím na tlačítko „OK“ zahájíte vyhledávání duplicitních stránek.
Krok 2 – Vyhledání duplicitních stránek Na obrazovce by se objevil sloučený výstupní soubor PDF. Pokud tomu tak není, otevřete kombinovaný soubor PDF. Výběrem možnosti „Plug-Ins > Split Documents > Find and Delete Duplicate Pages…“ otevřete dialogové okno „Find Duplicate Pages“.Zaškrtněte možnost „Porovnat vizuální vzhled pro přesnou shodu (lze použít pro porovnání obrázků)“. Klepnutím na tlačítko „OK“ zahájíte vyhledávání duplicitních stránek..PNG) Krok 3 – Výběr duplicitních stránek V dialogovém okně „Odstranit duplicitní stránky“ se zobrazí seznam duplicitních nebo téměř duplicitních stránek. Kliknutím na záznam stránky zobrazíte odpovídající stránku v prohlížeči. Prohlížejte stránky a vybírejte/odebírejte stránky. Klepnutím na tlačítko „Extrahovat stránky…“ extrahujete vybrané duplicitní stránky do nového dokumentu PDF.
Krok 3 – Výběr duplicitních stránek V dialogovém okně „Odstranit duplicitní stránky“ se zobrazí seznam duplicitních nebo téměř duplicitních stránek. Kliknutím na záznam stránky zobrazíte odpovídající stránku v prohlížeči. Prohlížejte stránky a vybírejte/odebírejte stránky. Klepnutím na tlačítko „Extrahovat stránky…“ extrahujete vybrané duplicitní stránky do nového dokumentu PDF..PNG) Zadejte výstupní složku a název souboru. Po dokončení klikněte na tlačítko „Uložit“.
Zadejte výstupní složku a název souboru. Po dokončení klikněte na tlačítko „Uložit“..PNG) Zobrazí se dialogové okno s počtem stránek, které byly extrahovány do samostatného dokumentu. Nyní jste uložili všechny duplicitní stránky do samostatného souboru PDF před jejich odstraněním. Tyto stránky můžete prozkoumat a v případě potřeby použít později. Klepnutím na tlačítko „OK“ zavřete dialogové okno.
Zobrazí se dialogové okno s počtem stránek, které byly extrahovány do samostatného dokumentu. Nyní jste uložili všechny duplicitní stránky do samostatného souboru PDF před jejich odstraněním. Tyto stránky můžete prozkoumat a v případě potřeby použít později. Klepnutím na tlačítko „OK“ zavřete dialogové okno..png) Krok 4 – Odstranění duplicitních stránek Pro pokračování klikněte na „Odstranit stránky“ v dialogovém okně „Odstranit duplicitní stránky“.
Krok 4 – Odstranění duplicitních stránek Pro pokračování klikněte na „Odstranit stránky“ v dialogovém okně „Odstranit duplicitní stránky“..PNG) Kliknutím na „OK“ v dialogovém okně odstraníte vybrané duplicitní stránky z aktuálního PDF dokumentu.
Kliknutím na „OK“ v dialogovém okně odstraníte vybrané duplicitní stránky z aktuálního PDF dokumentu..PNG) Vybrané duplicitní stránky by byly z dokumentu PDF trvale odstraněny. Pro uložení upraveného dokumentu na disk byste museli použít nabídku „Soubor > Uložit“. Kliknutím sem získáte seznam všech dostupných návodů krok za krokem.
Vybrané duplicitní stránky by byly z dokumentu PDF trvale odstraněny. Pro uložení upraveného dokumentu na disk byste museli použít nabídku „Soubor > Uložit“. Kliknutím sem získáte seznam všech dostupných návodů krok za krokem.