- Úvod
- Cíl
- A. Filtrační metody
- Chi-kvadrát test
- Fisherovo skóre
- Korelační koeficient
- Prah rozptylu
- Střední absolutní rozdíl (MAD)
- Poměr rozptylu
- B. Obalové metody:
- Přímý výběr funkcí
- Zpětná eliminace vlastností
- Vyčerpávající výběr prvků
- Rekurzivní eliminace funkcí
- C. Vložené metody:
- LASSO Regularizace (L1)
- Význam náhodného lesa
- Závěr
Úvod
Při sestavování modelu strojového učení v reálném životě je téměř vzácné, aby všechny proměnné v souboru dat byly užitečné pro sestavení modelu. Přidání nadbytečných proměnných snižuje zobecňovací schopnost modelu a může také snížit celkovou přesnost klasifikátoru. Navíc přidávání dalších a dalších proměnných do modelu zvyšuje celkovou složitost modelu.
Podle zákona parsimonie „Occamovy břitvy“ je nejlepší vysvětlení problému to, které zahrnuje co nejméně předpokladů. Výběr příznaků se tak stává nepostradatelnou součástí sestavování modelů strojového učení.
Cíl
Cílem výběru příznaků ve strojovém učení je najít nejlepší sadu příznaků, která umožní sestavit užitečné modely studovaných jevů.
Techniky výběru příznaků ve strojovém učení lze obecně rozdělit do následujících kategorií:
Supervised Techniques:
Tyto techniky lze použít pro označená data a slouží k identifikaci relevantních rysů pro zvýšení účinnosti modelů pod dohledem, jako je klasifikace a regrese.
Techniky bez dohledu:
Z taxonomického hlediska jsou tyto techniky klasifikovány takto:
A. Metody filtrování
B. Obalové metody
C. Vložené metody
D. Hybridní metody
V tomto článku se budeme zabývat některými oblíbenými technikami výběru příznaků ve strojovém učení.
A. Filtrační metody
Filtrační metody vybírají vnitřní vlastnosti rysů měřené pomocí jednorozměrné statistiky namísto křížové validace výkonu. Tyto metody jsou rychlejší a méně výpočetně náročné než obalové metody. Při práci s vysokodimenzionálními daty je výpočetně levnější použít filtrační metody.
Podívejme se, na některé z těchto technik:
Informační zisk
Informační zisk vypočítává snížení entropie z transformace souboru dat. Lze jej použít pro výběr prvků vyhodnocením informačního zisku každé proměnné v kontextu cílové proměnné.
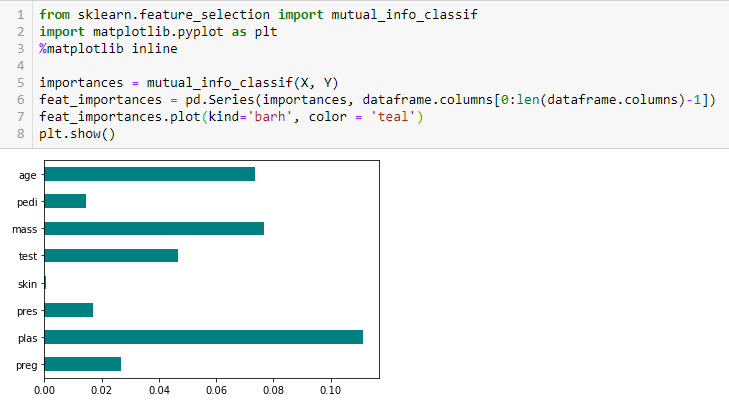
Chi-kvadrát test
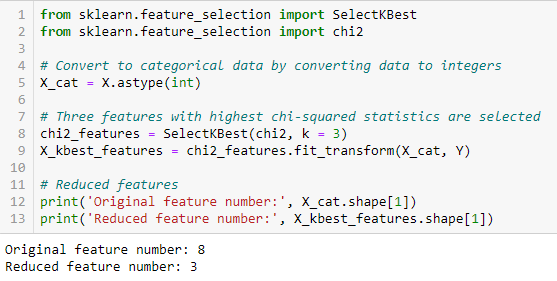
Chi-kvadrát test se používá pro kategoriální prvky v souboru dat. Vypočítáme Chi-kvadrát mezi každým rysem a cílem a vybereme požadovaný počet rysů s nejlepšími výsledky Chi-kvadrátu. Aby bylo možné chí-kvadrát správně použít k testování vztahu mezi různými prvky v souboru dat a cílovou proměnnou, musí být splněny následující podmínky: proměnné musí být kategoriální, musí být vybrány nezávisle a hodnoty by měly mít očekávanou četnost větší než 5.
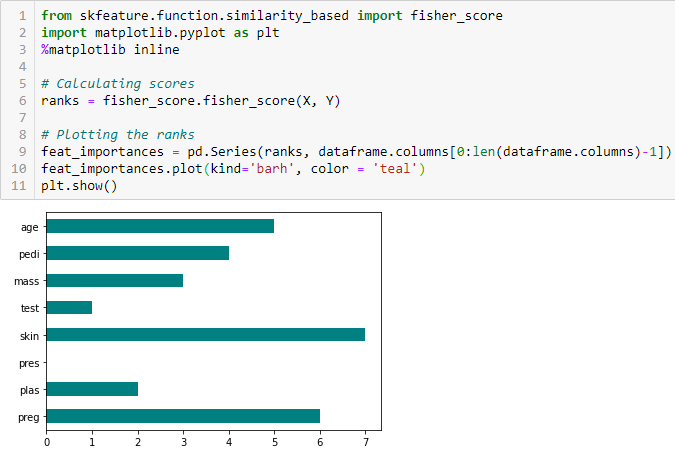
Fisherovo skóre
Fisherovo skóre je jednou z nejpoužívanějších metod výběru prvků pod dohledem. Algoritmus, který použijeme, vrací pořadí proměnných na základě Fisherova skóre v sestupném pořadí. Můžeme pak vybrat proměnné podle daného případu.
Korelační koeficient
Korelace je míra lineárního vztahu 2 nebo více proměnných. Prostřednictvím korelace můžeme předpovídat jednu proměnnou z druhé. Logika použití korelace pro výběr prvků spočívá v tom, že dobré proměnné jsou vysoce korelované s cílem. Kromě toho by proměnné měly být korelované s cílem, ale neměly by být korelované mezi sebou.
Jsou-li dvě proměnné korelované, můžeme jednu předpovídat z druhé. Pokud jsou tedy dva znaky korelované, model skutečně potřebuje pouze jeden z nich, protože druhý nepřidává další informace. Zde použijeme Pearsonovu korelaci.
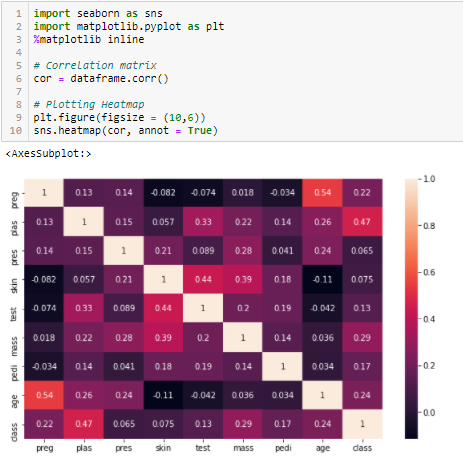
Je třeba nastavit absolutní hodnotu, například 0,5 jako práh pro výběr proměnných. Pokud zjistíme, že predikční proměnné jsou mezi sebou korelované, můžeme vypustit proměnnou, která má nižší hodnotu korelačního koeficientu s cílovou proměnnou. Můžeme také vypočítat vícenásobné korelační koeficienty a ověřit, zda spolu nekorelují více než dvě proměnné. Tento jev je znám jako multikolinearita.
Prah rozptylu
Prah rozptylu je jednoduchý základní přístup k výběru prvků. Odstraňuje všechny rysy, jejichž variance nesplňuje určitý práh. Ve výchozím nastavení odstraňuje všechny rysy s nulovou variancí, tj. rysy, které mají ve všech vzorcích stejnou hodnotu. Předpokládáme, že rysy s vyšším rozptylem mohou obsahovat více užitečných informací, ale uvědomme si, že nezohledňujeme vztah mezi proměnnými rysů nebo rysů a cílových proměnných, což je jedna z nevýhod filtračních metod.

Příkaz get_support vrací logický vektor, kde True znamená, že proměnná nemá nulový rozptyl.
Střední absolutní rozdíl (MAD)
‚Střední absolutní rozdíl (MAD) počítá absolutní rozdíl od střední hodnoty. Hlavním rozdílem mezi mírou rozptylu a mírou MAD je absence čtverce v této druhé míře. Stejně jako rozptyl je i MAD škálovou variantou. To znamená, že vyšší MAD, vyšší rozlišovací schopnost.
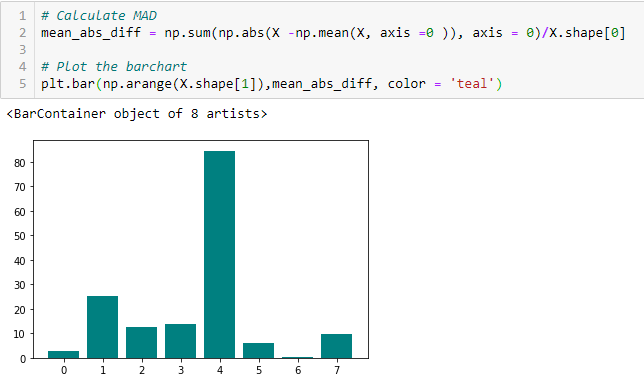
Poměr rozptylu
„Další míra rozptylu uplatňuje aritmetický průměr (AM) a geometrický průměr (GM). Pro daný (kladný) rys Xi na n vzorech jsou AM a GM dány vztahy
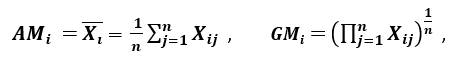
respektive; protože AMi ≥ GMi, přičemž rovnost platí tehdy a jen tehdy, když Xi1 = Xi2 = …. = Xin, pak lze jako míru rozptylu použít poměr
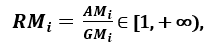
. Vyšší rozptyl znamená vyšší hodnotu Ri, tedy relevantnější vlastnost. Naopak, pokud mají všechny vzorky prvků (přibližně) stejnou hodnotu, Ri se blíží 1, což znamená málo relevantní prvek.

 ‚
‚
B. Obalové metody:
Obalovací metody vyžadují nějakou metodu, která prohledá prostor všech možných podmnožin rysů a posoudí jejich kvalitu naučením a vyhodnocením klasifikátoru s touto podmnožinou rysů. Proces výběru příznaků je založen na konkrétním algoritmu strojového učení, který se snažíme napasovat na danou množinu dat. Řídí se přístupem chamtivého vyhledávání, kdy vyhodnocuje všechny možné kombinace rysů podle hodnotícího kritéria. Obalové metody obvykle vedou k lepší přesnosti predikce než filtrační metody.
Podívejme se, na některé z těchto technik:
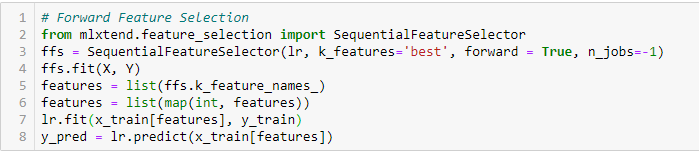
Přímý výběr funkcí
Jedná se o iterativní metodu, při které začínáme s nejvýkonnější proměnnou vůči cíli. Dále vybereme další proměnnou, která podává nejlepší výkon v kombinaci s první vybranou proměnnou. Tento proces pokračuje, dokud není dosaženo předem nastaveného kritéria.
Zpětná eliminace vlastností
Tato metoda funguje přesně opačně než metoda dopředného výběru vlastností. Zde začínáme se všemi dostupnými funkcemi a sestavujeme model. Poté z modelu vybereme proměnnou, která dává nejlepší hodnotu míry hodnocení. Tento proces pokračuje, dokud není dosaženo předem nastaveného kritéria.
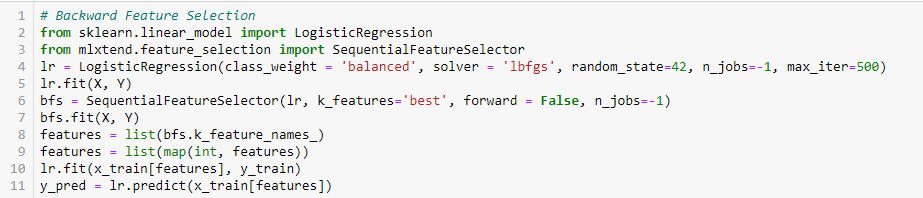
Tato metoda se spolu s výše popsanou metodou nazývá také metoda sekvenčního výběru prvků.
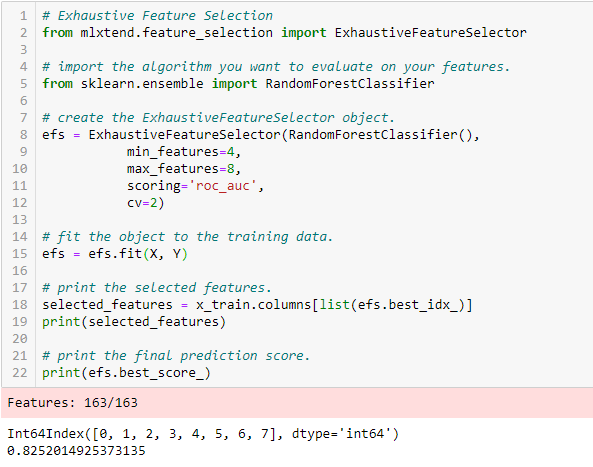
Vyčerpávající výběr prvků
Jedná se o nejrobustnější metodu výběru prvků, o které jsme se dosud zmiňovali. Jedná se o hrubé vyhodnocení každé podmnožiny prvků. To znamená, že se vyzkouší všechny možné kombinace proměnných a vrátí se nejvýkonnější podmnožina.
Rekurzivní eliminace funkcí
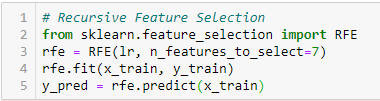
‚Při daném externím odhadu, který přiřazuje funkcím váhy (např. koeficientům lineárního modelu), je cílem rekurzivní eliminace funkcí (RFE) vybrat funkce rekurzivním zvažováním stále menších a menších množin funkcí. Nejprve je estimátor natrénován na počáteční sadě rysů a důležitost každého rysu je získána buď prostřednictvím atributu coef_, nebo prostřednictvím atributu feature_importances_.
Poté se z aktuální množiny rysů vyřadí nejméně důležité rysy. Tento postup se rekurzivně opakuje na ořezané množině, dokud se nakonec nedosáhne požadovaného počtu prvků k výběru.“
C. Vložené metody:
Tyto metody zahrnují výhody obalových i filtračních metod tím, že zahrnují interakce rysů, ale zároveň zachovávají rozumné výpočetní náklady. Vložené metody jsou iterativní v tom smyslu, že se stará o každou iteraci procesu trénování modelu a pečlivě vybírá ty rysy, které nejvíce přispívají k trénování pro danou iteraci.
Pokračujme, probereme některé z těchto technik kliknutím zde:
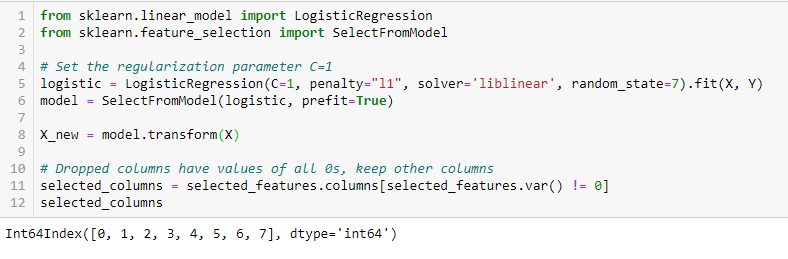
LASSO Regularizace (L1)
Regularizace spočívá v přidání trestu k různým parametrům modelu strojového učení, aby se snížila volnost modelu, tj. aby se zabránilo přílišnému přizpůsobení. Při regularizaci lineárního modelu se penalizace aplikuje nad koeficienty, které násobí každý z prediktorů. Z různých typů regularizace má Lasso neboli L1 tu vlastnost, že dokáže některé koeficienty zmenšit na nulu. Proto lze tuto vlastnost z modelu odstranit.
Význam náhodného lesa
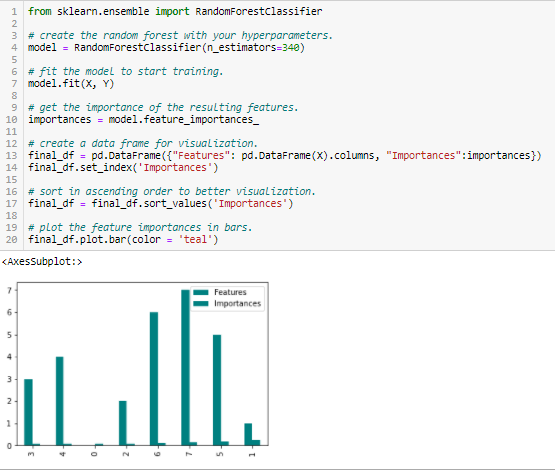
Náhodný les je druh algoritmu Bagging, který agreguje určitý počet rozhodovacích stromů. Strategie založené na stromech, které náhodné lesy používají, se přirozeně řadí podle toho, jak dobře zlepšují čistotu uzlu, nebo jinými slovy snížení nečistoty (Giniho nečistoty) oproti všem stromům. Uzly s největším poklesem nečistoty se vyskytují na začátku stromů, zatímco poznámky s nejmenším poklesem nečistoty se vyskytují na konci stromů. Ořezáním stromů pod určitým uzlem tedy můžeme vytvořit podmnožinu nejdůležitějších rysů.
Závěr
Probrali jsme několik technik výběru rysů. Záměrně jsme ponechali techniky výběru příznaků, jako je analýza hlavních komponent, rozklad singulární hodnoty, lineární diskriminační analýza atd. Tyto metody pomáhají snížit dimenzionalitu dat nebo snížit počet proměnných při zachování rozptylu dat.
Kromě výše diskutovaných metod existuje mnoho dalších metod výběru příznaků. Existují také hybridní metody, které využívají jak techniky filtrování, tak obalování. Pokud chcete prozkoumat více o technikách výběru příznaků, skvělou komplexní četbou by podle mého názoru byla kniha „Feature Selection for Data and Pattern Recognition“ od Urszuly Stańczyk a Lakhmi C. Jain.