Aktualizace 29. května 2018: Účelem tohoto článku je trojí: (1) Ukázat, že vždy budeme potřebovat datový model (ať už jej budou vytvářet lidé, nebo stroje) (2) Ukázat, že fyzické modelování není totéž co logické modelování. Ve skutečnosti je velmi odlišné a závisí na základní technologii. Potřebujeme však obojí. Tento bod jsem ilustroval na příkladu Hadoopu na fyzické vrstvě (3) Ukažte dopad konceptu neměnnosti na modelování dat.
- Je dimenzionální modelování mrtvé?
- Proč potřebujeme modelovat data?
- Proč potřebujeme dimenzionální modely?
- Datové modelování vs. dimenzionální modelování
- Proč tedy někteří lidé tvrdí, že dimenzionální modelování je mrtvé?
- Datový sklad je mrtvý Zmatek
- Schéma na čtení nedorozumění
- Denormalizace revisited. Fyzikální aspekty modelu.
- Dotažení de-normalizace do konce
- Rozdělení dat v distribuované relační databázi (MPP)
- Rozdělení dat v systému Hadoop
- Dimenzionální modely na platformě Hadoop
- Hadoop a pomalu se měnící dimenze
- Vývoj úložiště na platformě Hadoop
- Verdikt. Jsou dimenzionální modely a hvězdicová schémata zastaralé?
- Doplňková četba o dimenzionálním modelování v éře velkých dat
Je dimenzionální modelování mrtvé?
Než vám dám odpověď na tuto otázku, udělejme krok zpět a nejprve se podívejme, co máme na mysli pod pojmem dimenzionální modelování dat.
Proč potřebujeme modelovat data?
Vzdor častému nedorozumění není jediným účelem datových modelů sloužit jako ER diagram pro návrh fyzické databáze. Datové modely představují složitost obchodních procesů v podniku. Dokumentují důležitá obchodní pravidla a koncepty a pomáhají standardizovat klíčovou podnikovou terminologii. Zajišťují přehlednost a pomáhají odhalit nejasné myšlení a nejednoznačnost podnikových procesů. Datové modely lze navíc využít ke komunikaci s ostatními zúčastněnými stranami. Bez plánu byste nepostavili dům ani most. Proč byste tedy stavěli datovou aplikaci, například datový sklad, bez plánu?
Proč potřebujeme dimenzionální modely?
Dimenzionální modelování je speciální přístup k modelování dat. Jako synonyma pro dimenzionální model používáme také slova data mart nebo hvězdicové schéma. Hvězdicová schémata jsou optimalizována pro analýzu dat. Podívejte se na níže uvedený dimenzionální model. Je poměrně intuitivní na pochopení. Okamžitě vidíme, jak můžeme rozřezat data o objednávkách podle zákazníků, produktů nebo data a měřit výkonnost obchodního procesu Objednávky pomocí agregace a porovnávání metrik.
Jednou ze základních myšlenek dimenzionálního modelování je definovat nejnižší úroveň granularity v transakčním obchodním procesu. Když rozřezáváme data na plátky a kostky a vrtáme se v nich, je to listová úroveň, ze které se nemůžeme dostat dále. Jinak řečeno, nejnižší úroveň granularity ve hvězdicovém schématu je spojení faktu se všemi tabulkami dimenzí bez jakýchkoli agregací.
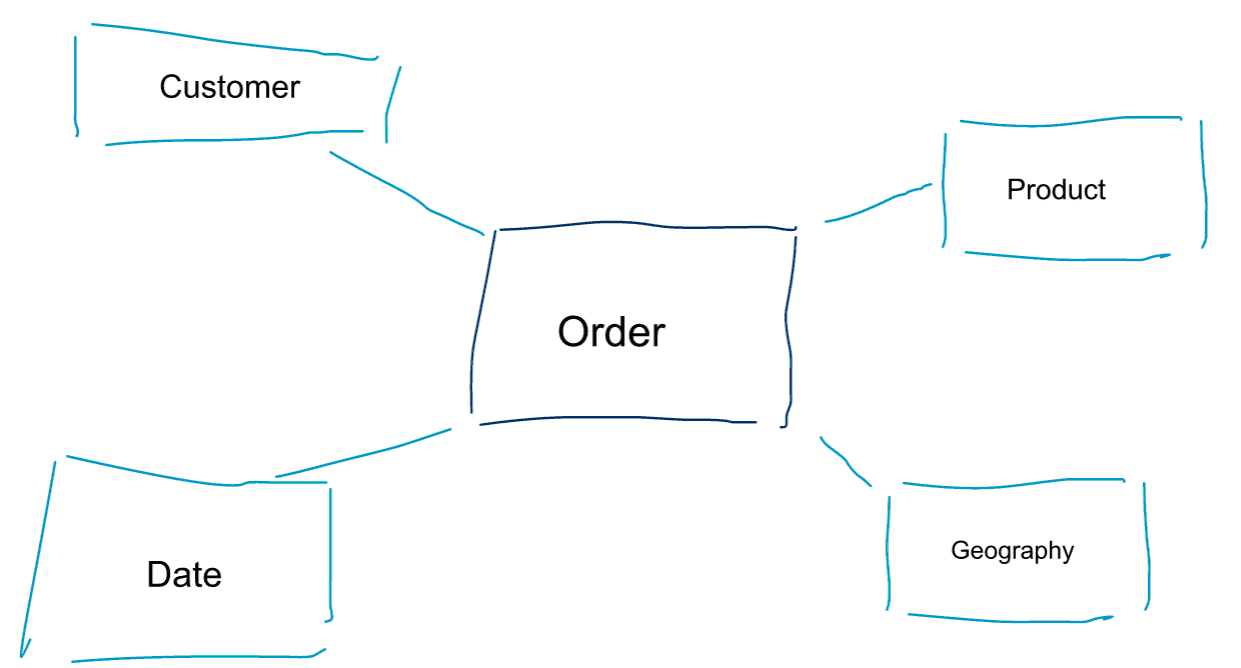
Datové modelování vs. dimenzionální modelování
Ve standardním modelování dat se snažíme eliminovat opakování a redundanci dat. Když dojde ke změně dat, musíme je změnit pouze na jednom místě. To také napomáhá kvalitě dat. Hodnoty se nesynchronizují na více místech. Podívejte se na níže uvedený model. Obsahuje různé tabulky, které reprezentují geografické koncepty. V normalizovaném modelu máme pro každou entitu samostatnou tabulku. V dimenzionálním modelu máme pouze jednu tabulku: geografie. V této tabulce se budou města opakovat vícekrát. Pro každé město jednou. Pokud se změní název země, musíme ji aktualizovat na mnoha místech
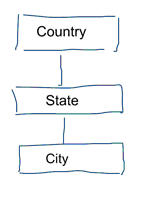
Poznámka: Standardní modelování dat se také označuje jako modelování 3NF.
Standardní přístup k modelování dat není vhodný pro úlohy Business Intelligence. Velké množství tabulek má za následek velké množství spojů. Spojování zpomaluje práci. V datové analytice se jim pokud možno vyhýbáme. V dimenzionálních modelech de-normalizujeme více souvisejících tabulek do jedné tabulky, např. různé tabulky v našem předchozím příkladu lze předem spojit do jediné tabulky: geografie.
Proč tedy někteří lidé tvrdí, že dimenzionální modelování je mrtvé?
Myslím, že budete souhlasit, že modelování dat obecně a dimenzionální modelování zvláště je docela užitečné cvičení. Proč tedy někteří lidé tvrdí, že dimenzionální modelování není v éře velkých dat a systému Hadoop užitečné?
Jak si jistě dokážete představit, existují pro to různé důvody.
Datový sklad je mrtvý Zmatek
V první řadě si někteří lidé pletou dimenzionální modelování s datovým skladem. Tvrdí, že datový sklad je mrtvý, a v důsledku toho lze i dimenzionální modelování poslat na smetiště dějin. To je logicky konzistentní argument. Koncept datového skladu však zdaleka není zastaralý. Vždy potřebujeme integrovaná a spolehlivá data pro naplnění našich informačních panelů BI. Pokud se chcete dozvědět více, doporučuji náš vzdělávací kurz Big Data pro profesionály v oblasti datových skladů. V kurzu se věnuji podrobnostem a vysvětluji, jak je datový sklad stejně aktuální jako kdykoli předtím. Ukážu také, jak jsou nové nástroje a technologie pro big data užitečné pro datové sklady.

Schéma na čtení nedorozumění
Druhý argument, který často slýchám, zní takto. ‚Řídíme se přístupem schématu při čtení a nepotřebujeme již modelovat naše data‘. Podle mého názoru je koncept schema on read jedním z největších nedorozumění v datové analytice. Souhlasím s tím, že je užitečné zpočátku ukládat surová data ve výpisu dat, který je nenáročný na schéma. Tento argument by však neměl sloužit jako výmluva pro to, abyste svá data nemodelovali vůbec. Přístup založený na schématu při čtení je jen odkopnutím plechovky a přenesením odpovědnosti na následné procesy. Někdo stejně musí zatnout zuby a definovat datové typy. Každý proces, který přistupuje k výpisu dat bez schématu, musí sám zjistit, o co jde. Tento typ práce se sčítá, je zcela zbytečný a lze se mu snadno vyhnout definováním datových typů a správného schématu.
Denormalizace revisited. Fyzikální aspekty modelu.
Existují skutečně nějaké platné argumenty pro prohlášení dimenzionálních modelů za zastaralé? Skutečně existují některé lepší argumenty než dva, které jsem uvedl výše. Vyžadují určité pochopení fyzikálního modelování dat a způsobu fungování systému Hadoop. Vydržte se mnou.
Předtím jsem se krátce zmínil o jednom z důvodů, proč modelujeme data dimenzionálně. Je to v souvislosti se způsobem, jakým jsou data fyzicky uložena v našem datovém úložišti. Při standardním modelování dat dostane každá entita reálného světa svou vlastní tabulku. Děláme to proto, abychom se vyhnuli redundanci dat a riziku, že se do našich dat vloudí problémy s kvalitou dat. Čím více tabulek máme, tím více spojů potřebujeme. To je nevýhoda. Spojování tabulek je drahé, zejména pokud spojujeme velké množství záznamů z našich datových sad. Když data modelujeme dimenzionálně, konsolidujeme více tabulek do jedné. Říkáme, že data předem spojíme nebo odnormalizujeme. Nyní máme méně tabulek, méně spojů a v důsledku toho nižší latenci a lepší výkonnost dotazů.
Podílejte se na diskusi k tomuto příspěvku na LinkedIn
Dotažení de-normalizace do konce
Proč nedotáhnout de-normalizaci do konce? Zbavit se všech spojů a mít jen jednu jedinou tabulku faktů? To by skutečně zcela odstranilo potřebu jakéhokoli spojování. Jak si však dokážete představit, má to některé vedlejší účinky. Především se tím zvýší objem potřebného úložiště. Nyní musíme ukládat spoustu nadbytečných dat. S nástupem sloupcových formátů pro ukládání analytických dat je to v dnešní době menší problém. Větším problémem de-normalizace je skutečnost, že pokaždé, když se změní hodnota některého z atributů, musíme tuto hodnotu aktualizovat na více místech – možná tisíce nebo miliony aktualizací. Jedním ze způsobů, jak tento problém obejít, je kompletní noční načítání našich modelů. Často to bude mnohem rychlejší a jednodušší než použití velkého počtu aktualizací. Sloupcové databáze obvykle používají následující přístup. Nejprve ukládají aktualizace dat do paměti a asynchronně je zapisují na disk.
Rozdělení dat v distribuované relační databázi (MPP)
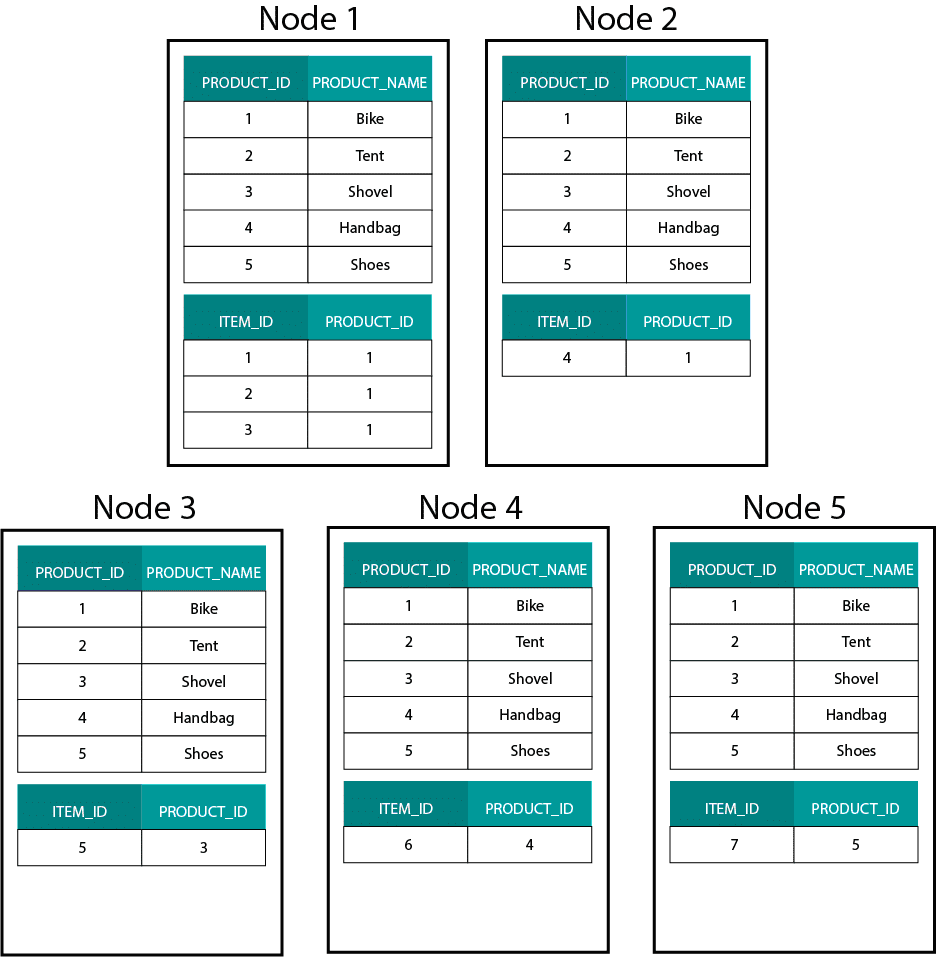
Při vytváření dimenzionálních modelů v systému Hadoop, např. v Hive, SparkSQL atd. musíme lépe porozumět jedné základní vlastnosti této technologie, která ji odlišuje od distribuované relační databáze (MPP), jako je Teradata atd. Při distribuci dat mezi uzly v MPP máme kontrolu nad umístěním záznamů. Na základě naší strategie dělení, např. hash, seznam, rozsah atd. můžeme klíče jednotlivých záznamů umístit společně na různé karty v jednom uzlu. Díky zaručené kolokaci dat je naše spojování superrychlé, protože nemusíme posílat žádná data po síti. Podívejte se na příklad níže. Záznamy se stejným ORDER_ID z tabulek ORDER a ORDER_ITEM skončí ve stejném uzlu.
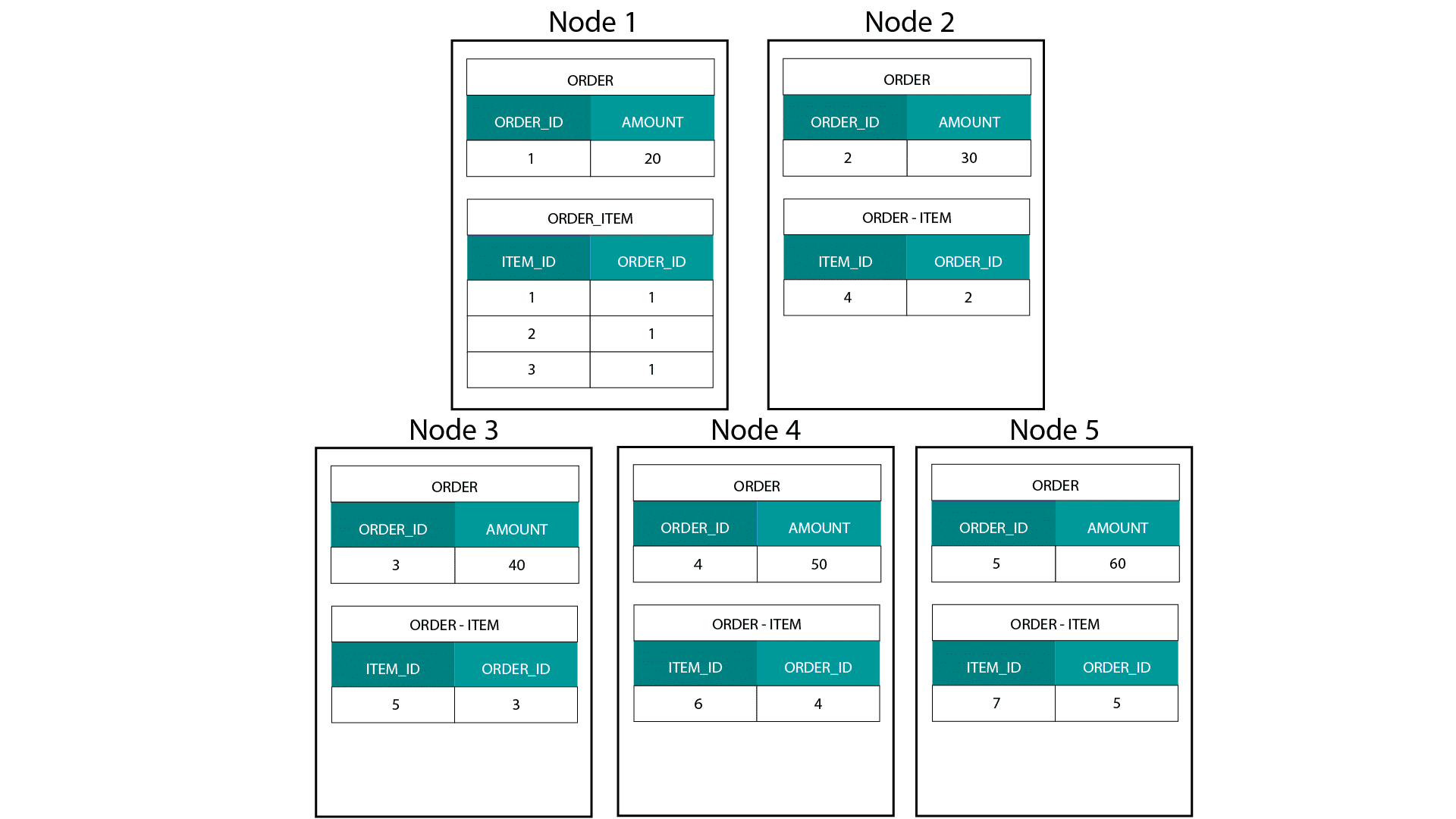
Klíče pro order_id tabulky order a order_item jsou kolokačně umístěny ve stejných uzlech.
Rozdělení dat v systému Hadoop
Toto je velmi odlišné od systémů založených na Hadoop. Tam rozdělujeme naše data na velké kusy a distribuujeme a replikujeme je mezi uzly na distribuovaném souborovém systému Hadoop (HDFS). Při této strategii distribuce dat nemůžeme zaručit jejich kolokabilitu. Podívejte se na příklad níže. Záznamy pro klíč ORDER_ID končí v různých uzlech.
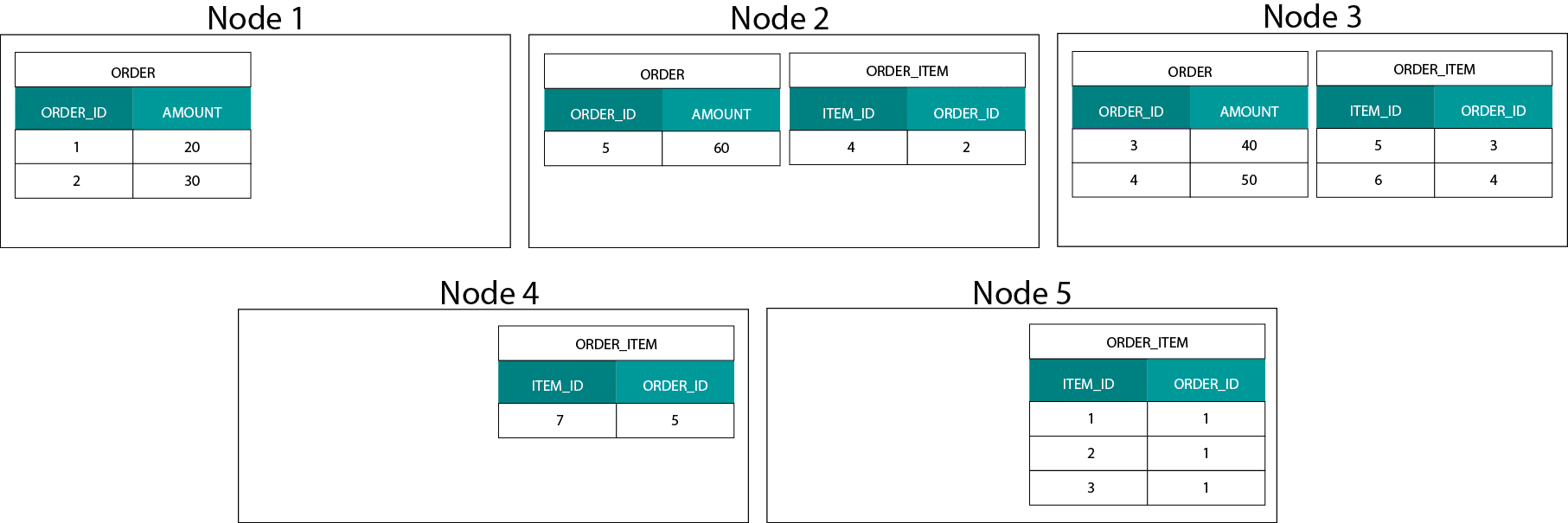
Pro spojování musíme posílat data po síti, což má vliv na výkon.
Jednou strategií, jak se s tímto problémem vypořádat, je replikovat jednu ze spojovacích tabulek napříč všemi uzly v clusteru. Tomuto postupu se říká broadcast join a stejnou strategii používáme i v MPP. Jak si dokážete představit, funguje to pouze pro malé tabulky vyhledávání nebo dimenzí.
Co tedy uděláme, když máme velkou tabulku faktů a velkou tabulku dimenzí, např. zákazníka nebo produkt? Nebo dokonce když máme dvě velké tabulky faktů.
Dimenzionální modely na platformě Hadoop
Abychom tento výkonnostní problém obešli, můžeme velké tabulky dimenzí de-normalizovat do naší tabulky faktů, abychom zaručili, že data budou umístěna společně. Menší dimenzionální tabulky můžeme vysílat přes všechny naše uzly.
Pro spojení dvou velkých tabulek faktů můžeme vnořit tabulku s nižší granularitou do tabulky s vyšší granularitou, např. velkou tabulku ORDER_ITEM vnořit do tabulky ORDER. Moderní dotazovací enginy, jako je Impala nebo Drill, nám umožňují tato data zploštit

Tato strategie vnořování dat je také užitečná pro bolestivé Kimballovy koncepty, jako jsou bridge tables pro reprezentaci vztahů M:N v dimenzionálním modelu.
Hadoop a pomalu se měnící dimenze
Úložiště v souborovém systému Hadoop je neměnné. Jinými slovy můžete pouze vkládat a přidávat záznamy. Data nelze měnit. Pokud přicházíte z prostředí relačního datového skladu, může vám to zpočátku připadat trochu zvláštní. Pod kapotou však databáze fungují podobným způsobem. Všechny změny dat ukládají do neměnného protokolu s předstihem zápisu (v Oracle známého jako redo log) před tím, než proces asynchronně aktualizuje data v datových souborech.
Jaký dopad má neměnnost na naše dimenzionální modely? Možná si z kurzu dimenzionálního modelování pamatujete koncept pomalu se měnících dimenzí (SCD). SCD volitelně uchovávají historii změn atributů. Umožňují nám vykazovat metriky podle hodnoty atributu v určitém časovém okamžiku. Nejedná se však o výchozí chování. Ve výchozím nastavení aktualizujeme tabulky dimenzí s nejnovějšími hodnotami. Jaké jsou tedy naše možnosti v systému Hadoop? Nezapomeňte! Data nemůžeme aktualizovat. Můžeme jednoduše nastavit výchozí chování SCD a kontrolovat veškeré změny. Pokud chceme spouštět sestavy proti aktuálním hodnotám, můžeme nad SCD vytvořit Pohled, který načte pouze nejnovější hodnotu. To lze snadno provést pomocí okenních funkcí. Případně můžeme spustit tzv. službu kompakce, která fyzicky vytvoří samostatnou verzi tabulky dimenzí pouze s nejnovějšími hodnotami.
Vývoj úložiště na platformě Hadoop
Tato omezení platformy Hadoop nezůstala bez povšimnutí dodavatelů platformy Hadoop. V Hive nyní máme transakce ACID a aktualizovatelné tabulky. Na základě množství otevřených závažných problémů a mých vlastních zkušeností se však zdá, že tato funkce ještě není připravena k produkci . Společnost Cloudera zvolila jiný přístup. S Kudu vytvořili nový formát aktualizovatelného úložiště, které není umístěno na HDFS, ale na lokálním souborovém systému operačního systému. Zcela se tak zbavuje omezení Hadoopu a je podobný tradiční úložné vrstvě ve sloupcovém MPP. Obecně je pravděpodobně lepší provozovat všechny případy použití BI a dashboardů na MPP, např. Impala + Kudu, než na Hadoopu. Jak již bylo řečeno, MPP mají svá vlastní omezení, pokud jde o odolnost, souběžnost a škálovatelnost. Pokud narazíte na tato omezení, jsou Hadoop a jeho blízký příbuzný Spark dobrou volbou pro pracovní zátěže BI. V našem školení Big Data for Data Warehouse Professionals se všemi těmito omezeními zabýváme a uvádíme doporučení, kdy použít RDBMS a kdy SQL na Hadoop/Spark.
Verdikt. Jsou dimenzionální modely a hvězdicová schémata zastaralé?
Všichni víme, že Ralph Kimball odešel do důchodu. Ale jeho principiální myšlenky a koncepty jsou stále platné a žijí dál. Musíme je přizpůsobit novým technologiím a typům úložišť, ale stále mají přidanou hodnotu.
Učte mě Big Data, abych postoupil v kariéře
Doplňková četba o dimenzionálním modelování v éře velkých dat
Tom Breur: Minulost a budoucnost dimenzionálního modelování
Edosa Odaro: 5 radikálních tipů pro rychlou integraci velkých dat – vzor antidatového skladu