Revidováno:
Mluví subjekty pravdu?
Spolehlivost údajů ze sebehodnocení je Achillovou patou dotazníkového výzkumu. Například průzkumy veřejného mínění ukázaly, že více než 40procent Američanů chodí každý týden do kostela. Zkoumánímzáznamů o návštěvnosti kostelů však Hadaway a Marlar (2005) dospěli k závěru, že skutečná návštěvnost je méně než 22 procent. Seth Stephens-Davidowitz (2017) ve své zásadní práci „Všichni lžou“ našel dostatek důkazů, které ukazují, že většina lidí nedělá to, co říká, a neříká to, co dělá. Například v reakci na průzkumy většina voličů prohlásila, že etnický původ kandidáta není důležitý. Nicméně kontrolouvyhledávaných výrazů v Googlu Sephens-Davidowitz zjistil opak. konkrétně, když uživatelé Googlu zadali slovo „Obama“, vždy si jeho jméno spojili s některými slovy souvisejícími s rasou.
Pro výzkum výuky na webu lze údaje o používání webu získat rozborem protokolu o přístupu uživatele, nastavením souborů cookie nebo nahráním mezipaměti. Tyto možnosti však mohou mít omezenou použitelnost. Například protokol o přístupu uživatele nemůže sledovat uživatele, kteří sledují odkazy na jiné webové stránky. Dále mohou přístupy založené na souborech cookie nebo mezipaměti vyvolat problémy s ochranou soukromí. V těchto situacích se používají vlastní údaje shromážděné pomocí průzkumů. To vede k otázce: Jak přesné jsou údaje uváděné samotnými respondenty? Cook a Campbell (1979) poukázali na to, že subjekty (a) mají tendenci uvádět to, co podle nich výzkumník očekává, nebo (b) uvádějí to, co pozitivně odráží jejich vlastní schopnosti, znalosti, přesvědčení nebo názory. Další obava týkající se těchto údajů spočívá v tom, zda jsou subjekty schopny přesně si vzpomenout na minulé chování. Psychologové upozorňují, že lidská paměť je omylná(Loftus, 2016; Schacter, 1999). Někdy si lidé „pamatují“ události, které se nikdy nestaly. Spolehlivost údajů, které sami uvádějí, je tedy pochybná.Ačkoli jsou statistické softwarové balíky schopny vypočítatčísla až na 16-32 desetinných míst, tato přesnost nemá smysl, pokud údajenemohou být přesné ani na úrovni celých čísel. Poměrně dost vědců varovalo výzkumníky, jak může chyba měření ochromit statistickou analýzu (Blalock, 1974), a navrhovalo, aby dobrá výzkumná praxevyžadovala zkoumání kvality shromážděných dat (Fetter,Stowe, & Owings, 1984).
Předpojatost a rozptyl
Chyby měření zahrnují dvě složky, a to předpojatost a variační chybu.Předpojatost je systematická chyba, která má tendenci tlačit vykazované výsledky k jednomu krajnímu konci. Například u několika verzí testů IQ bylo zjištěno zkreslení v neprospěch osob jiné než bílé pleti. To znamená, že černoši a Hispánci mají tendenci získávat nižší skóre bez ohledu na svou skutečnou inteligenci. Variabilní chyba, známá také jako rozptyl, bývá náhodná. Jinými slovy, uváděné skóre může být buď vyšší, nebo nižší než skutečné skóre (Salvucci, Walter, Conley, Fink, & Saba, 1997).
Zjištění těchto dvou typů chyb měření mají různé důsledky. Například ve studii, která srovnávala údaje o výšce a hmotnosti, které subjekty samy uváděly, s údaji přímo naměřenými (Hart & Tomazic, 1999),bylo zjištěno, že subjekty mají tendenci nadhodnocovat svou výšku, ale podhodnocovat svou hmotnost. Je zřejmé, že tento druh chyb je spíše odchylkou než rozptylem. Možným vysvětlením tohoto zkreslení je, že většina lidí chce před ostatními prezentovat lepší fyzický obraz. Pokud je však chyba měření náhodná, může být vysvětlení složitější.
Někdo může namítnout, že proměnné chyby, které mají náhodný charakter, by se navzájem vyrušily, a proto nemusí být pro studii hrozbou. Například první uživatel může nadhodnotit své internetové aktivity o10 %, ale druhý uživatel může podhodnotit své o 10 %. V tomto případě může být průměr stále správný. Nadhodnocení a podhodnocení však zvyšuje variabilitu rozdělení. V mnoha parametrických testech se variabilita uvnitř skupiny používá jako chybový člen. Nadhodnocená variabilita by rozhodně ovlivnila významnost testu. Některé texty mohou posilovat výše uvedenou mylnou představu. Například Deese (1972) říká,
Statistická teorie nám říká, že spolehlivost pozorování je úměrná druhé odmocnině jejich počtu. Čím více je pozorování, tím větší bude náhodný vliv. A statistická teorie tvrdí, že čím více je náhodných chyb, tím větší je pravděpodobnost, že se vzájemně vyruší a vytvoří normální rozdělení (str. 55).
Předně je pravda, že s rostoucí velikostí vzorku klesá rozptyl rozdělení, to však nezaručuje, že by se tvar rozdělení blížil normalitě. Za druhé, spolehlivost (kvalitaúdajů) by měla být vázána spíše na měření než na stanovení velikosti vzorku. Velký vzorek s velkým množstvím chyb měření,dokonce i náhodných chyb, by nafoukl chybový člen parametrických testů.
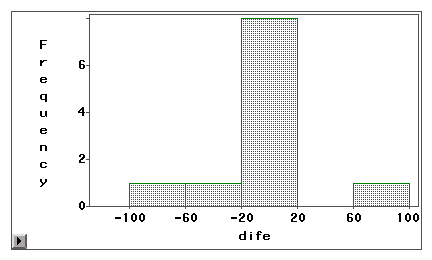
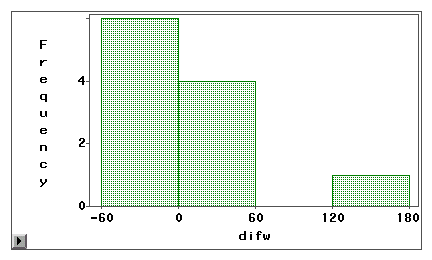
K vizuálnímu zkoumání, zda je chyba měření způsobena systematickým zkreslením nebo náhodným rozptylem, lze použít graf kmene a listu nebo histogram. V následujícím příkladu jsou dva typy přístupu k internetu (prohlížení webu a e-mail) měřeny jak pomocí vlastního šetření, tak pomocí logbooku. Rozdílové skóre (měření 1 – měření 2) jsou vyneseny do následujících histogramů.
První graf ukazuje, že většina rozdílových skóre je soustředěna kolem nuly. Podhodnocení a nadhodnocení se objevuje u obou konců, což naznačuje, že chyba měření je spíše náhodná než systematická chyba.
Druhý graf jasně ukazuje, že existuje vysoká míra chyb měření, protože velmi málo rozdílových skóre je soustředěno kolem nuly. Navíc je rozdělení záporně zkosené, a proto je chyba zkreslením místo rozptylu.
Jak spolehlivá je naše paměť?“
Schacter (1999) upozornil, že lidská paměť je omylná. Existuje sedm vad naší paměti:
- Pomíjivost: Snižující se dostupnost informací v průběhu času.
- Nepřítomné myšlení: Nepozornost nebo povrchní zpracování, které přispívá ke slabým vzpomínkám.
- Blokování: Dočasná nedostupnost informací, které jsou uloženy v paměti.
- Chybná atribuce Přisuzování vzpomínky nebo myšlenky nesprávnému zdroji.
- Sugestibilita: Vzpomínky, které jsou implantovány v důsledku naváděcích otázek nebo očekávání.
- Předpojatost: Retrospektivní zkreslení a nevědomé vlivy, které souvisejí s aktuálními znalostmi a přesvědčeními.
- Trvalost: Patologické vzpomínky – informace nebo události, které nemůžeme zapomenout, i když bychom si to přáli.
 |
„Nemám na ně vzpomínky. Nevzpomínám si, že bych podepsal dokument proWhitewater. Nepamatuji si, proč dokument zmizel, aleobjevil se později. Na nic si nevzpomínám.“ „Vzpomínám si, že jsem přistál (v Bosně) pod palbou odstřelovačů. Na letišti měl být nějaký uvítací ceremoniál, ale místo toho jsme jen běželi se sklopenými hlavami do vozidel, abychom se dostali na naši základnu.“ Při vyšetřování odesílání utajovaných informací přes osobní e-mailový server Clintonová 39krát řekla FBI, že si nic „nevybavuje“ nebo „nepamatuje“. Pozor: Byl objeven nový počítačový virus s názvem „Clinton“. Pokud je počítač infikován, budečasto vyskakovat tato zpráva „došla paměť“, i když má dostatečnou paměťRAM. |
| Otázka: „Jestliže nám Vernon Jordon řekl, že máte mimořádnou paměť,jednu z nejlepších pamětí, jakou kdy u politika viděl, chtěl byste to popřít?“
O: „Mám dobrou paměť… Ale nepamatuji si, jestli jsem byl s Monikou Lewinskou sám, nebo ne. Jakjsem mohl mít přehled o tolika ženách ve svém životě?“ V: Proč Clinton doporučil Lewinskou pro práci v Revlonu? O: Věděl, že si bude umět dobře vymýšlet. |
 |
Je důležité si uvědomit, že někdy je spolehlivost naší paměti vázána na žádoucí výsledek. Například když se lékařskývýzkumník snaží shromáždit relevantní údaje od matek, jejichž děti jsouzdravé, a matek, jejichž děti jsou malformované, údaje od těch druhýchjsou obvykle přesnější než od těch prvních. Je tomu tak proto, že matky malformovaných dětí pečlivě přezkoumávají každou nemoc, která se během těhotenství vyskytla, každý užívaný lék, každý detail přímo nebo vzdáleně související s tragédií ve snaze najít vysvětlení. Naopak matky zdravých dětí předchozím informacím příliš pozornosti nevěnují (Aschengrau & SeageIII, 2008). Nafukování GPA je dalším příkladem toho, jak desirabilitaovlivňuje přesnost paměti a integritu dat. V některých situacích je v inflaci GPA rozdíl mezi pohlavími. Studie provedená Caskie etal. (2014) zjistila, že ve skupině vysokoškolských studentů s nižším GPA ženy častěji uváděly vyšší než skutečný GPA než muži.
Aby se čelilo problému paměťových chyb, někteří výzkumníci navrhovali sbírat údaje týkající se momentální myšlenky nebo pocitu účastníka, spíše než ho žádat, aby si vybavil vzdálené události (Csikszentmihalyi & Larson, 1987; Finnigan & Vazire,2018). Následující příklady jsou položky dotazníku v Programu pro mezinárodní hodnocení žáků 2018: „Bylo s vámi včera po celý den zacházeno s respektem?“ „Usmíval/a jste se včera hodně nebo smál/a jste se hodně?“ „Naučili jste se nebo dělali jste včera něco zajímavého?“ (Organizace pro hospodářskou spolupráci a rozvoj, 2017). Odpověď však závisí na tom, co se účastníkovi v daném okamžiku přihodilo, což nemusí být typické. Konkrétně, i když se včera respondent příliš neusmíval nebo nesmál, nemusí to nutně znamenat, že je vždy nešťastný.
Co máme dělat?“
Někteří výzkumníci odmítají používání údajů, které sami uvádějí, kvůli jejich údajně nízké kvalitě. Například když skupina výzkumníků zkoumala, zda vysoká religiozita vedla v USA během pandemie COVID19 k menšímu dodržování pokynů k ukrytí, použila jako zástupný ukazatel religiozity regionu počet kongregací na 10 000 obyvatel namísto religiozity podle vlastních údajů, která má tendenci odrážet sociální desirabilitu (DeFranza, Lindow, Harrison, Mishra, &Mishra, 2020).
Chan (2009) však tvrdí, že tzv. špatná kvalita self-reported dat není nic jiného než městská legenda. Vedeni sociální žádoucností mohou respondenti v některých případech poskytnout výzkumníkům nepřesné údaje, ale neděje se tak vždy. Je například nepravděpodobné, že by respondenti lhali o svých demografických údajích, jako je pohlaví a etnický původ. Za druhé, i když je pravda, že respondenti mají tendenci falšovat své odpovědi v experimentálních studiích, tento problém je méně závažný u opatření používaných v terénních studiích a v naturalistickém prostředí. Dále existuje řada dobře zavedených sebeposuzovacích měření různých psychologických konstruktů, která získala důkazy o konstruktové validitě prostřednictvím konvergentní i diskriminační validace. Například osobnostní rysy Velké pětky, proaktivní osobnost, afektivní dispozice, sebeúčinnost, orientace na cíl, vnímaná organizační podpora a mnoho dalších.V oblasti epidemiologie Khoury, James a Erickson (1994) tvrdili, že vliv zkreslení vzpomínek je přeceňován. Jejich závěr však nelze dobře aplikovat na jiné obory, jako je vzdělávání a psychologie. navzdory hrozbě nepřesnosti údajů není možné, aby výzkumník sledoval každý subjekt s videokamerou a zaznamenával vše, co dělá. Výzkumník nicméně může využít podskupinu subjektů k získání pozorovaných dat, jako jsou přístupy do uživatelských logů nebo denní záznamy o přístupu na web v tištěné podobě. Výsledky by pak byly porovnány s výsledkem všechsubjektů¹ s údaji, které sami uvedli, pro odhad chyby měření.například
- Když má výzkumník k dispozici uživatelský log přístupů, může požádat subjekty, aby uvedly frekvenci svých přístupů na webový server.subjekty by neměly být informovány o tom, že jejich internetové aktivity byly zaznamenány webmasterem, protože to může ovlivnit chování účastníků.
- Výzkumník může požádat podskupinu uživatelů, aby si po dobu jednoho měsíce vedli deník svých internetových aktivit. Poté jsou ti samí uživatelé požádáni, aby vyplnili dotazník týkající se jejich používání webu.
Někdo může namítnout, že přístup založený na vedení deníku je příliš náročný. Vskutku,v mnoha vědeckých výzkumných studiích jsou subjekty žádány o mnohem víc. Například když vědci zkoumali, jaký vliv bude mít hluboký spánek během cest do vesmíru na dlouhou vzdálenost na lidské zdraví, byli účastníci požádáni, aby měsíc leželi v posteli. Ve studii, která se týkala vlivu uzavřeného prostředí na lidskou psychiku během cestování vesmírem, byli účastníci také měsíc zavřeni v místnosti. Hledání vědeckých pravd vyžaduje vysoké náklady.
Po shromáždění údajů z různých zdrojů lze analyzovat rozpor mezi záznamem a vlastními údaji a odhadnout tak spolehlivost údajů. Na první pohled tento přístup vypadá jako test-retestspolehlivosti, ale není tomu tak. Za prvé, při spolehlivosti test-retest by měl být nástroj použitý ve dvou nebo více situacích stejný. Za druhé, pokud je spolehlivost test-retest nízká, zdroj chyb je uvnitř přístroje. Když je však zdroj chyb vně nástroje, například lidské chyby, je vhodnější inter-rater reliabilita.
Výše navržený postup lze koncipovat jako měření inter-rater reliability, která se podobá inter-rater reliabilitě a opakovaným měřením. Existují čtyři způsoby odhadu spolehlivosti mezi posuzovateli, a to koeficient Kappa, index nekonzistence,ANOVA opakovaných měření a regresní analýza. V následující části je popsáno, jak lze tato měření spolehlivosti mezi hodnotiteli použít jako měření spolehlivosti mezidat.
Kappa koeficient
V psychologickém a pedagogickémvýzkumu není neobvyklé, že v procesu měření jsou zapojeni dva nebo více hodnotitelů, pokud hodnocení zahrnuje subjektivní úsudky(např. hodnocení esejí). Spolehlivost mezi hodnotiteli, která se měří pomocí koeficientu Kappa, se používá k vyjádření spolehlivosti údajů. například výkony účastníků jsou hodnoceny dvěma nebo více hodnotiteli jako „mistrovské“ nebo „nemistrovské“ (1 nebo 0). Proto se toto měření obvykle počítá v kategoriálních postupech analýzy dat, jako je PROC FREQ v SAS, „měření shody“ v SPSS nebo online kalkulačka Kappa (Lowry, 2016). Na obrázku níže je snímek obrazovky online kalkulačky Vassarstats.
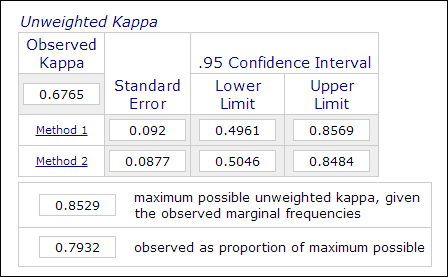
Je důležité si uvědomit, že i když se 60 procent dvou datových souborů navzájem shoduje, neznamená to, že měření jsou spolehlivá. protože výsledek je dichotomický, existuje 50procentní šance, že se dvě měření shodují. Koeficient kappa tuto skutečnost zohledňuje avyžaduje vyšší míru shody, aby bylo dosaženo shody.
V kontextu výuky na webu lze každou kategorii sebehodnocení používání webových stránek překódovat jako binární proměnnou. Například, když první otázka zní „jak často používáte telnet“, možné kategoriální odpovědi jsou „a: denně“, „b: třikrát až pětkrát za týden“, „c: třikrát až pětkrát za měsíc“, „d: zřídka“ a „e:nikdy“. V tomto případě lze pět kategorií překódovat do pěti proměnných: Q1A, Q1B, Q1C, Q1D a Q1E. Pak lze všechny tyto binární proměnné připojit a vytvořit tabulku R X 2, jak ukazuje následující tabulka. s touto strukturou dat lze odpovědi kódovat jako „1“ nebo „0“, a tak je možné měřit klasifikační shodu. Shodu lze vypočítat pomocí koeficientu Kappa, a tím odhadnout spolehlivost dat.
Subjekty Údaje ze záznamové knihy Samostatně.data hlášení Předmět 1 1 1 Předmět 2 0 0 Subjekt 3 1 0 Subjekt 4 0 1 Index nesouladu
Dalším způsobem výpočtu výše uvedených kategoriálních údajů je Index nesouladu (IOI). Ve výše uvedeném příkladu, protože existují dvě měření (logaritmické údaje a údaje o sobě) a pět možností odpovědi, je vytvořena tabulka 4 X 4. Prvním krokem k výpočtu IOI je rozdělení tabulky RXC na několik dílčích tabulek 2X2. Například poslednímožnost „nikdy“ je považována za jednu kategorii a všechny ostatní jsousloženy do další kategorie jako „ne nikdy“, jak ukazuje následující tabulka.
Samostatně-vykázané údaje Log Nikdy Nikdy Součet Nikdy a .
b a+b Nikdy c d c+d Celkem a+c b+d n=Sum(a-d) Procento IOI se vypočítá podle následujícího vzorce:
IOI% = 100*(b+c)/ kde p = (a+c)/n
Po výpočtu IOI pro každou dílčí tabulku 2×2 se použije průměr všech indexů jako ukazatel nekonzistence opatření. Kritérium pro posouzení, zda jsou údaje konzistentní, je následující:
- Index IOI menší než 20 znamená nízkou rozptylnost
- Index IOI mezi 20 a 50 znamená střední rozptylnost
- Index IOI nad 50 znamená vysokou rozptylnost
Spolehlivost údajů je vyjádřena touto rovnicí: r = 1 – IOI
Koeficient mezitřídní korelace
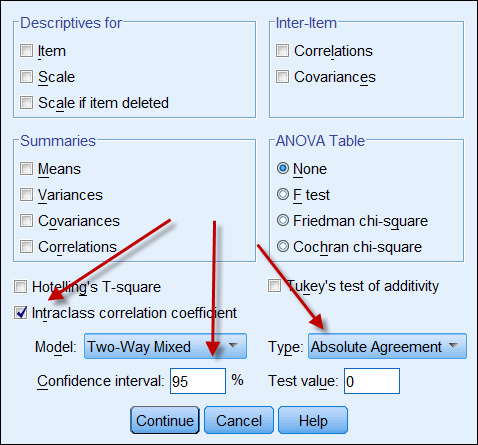
Pokud oba zdroje dat poskytují spojitá data, pak lze vypočítat koeficient mezitřídní korelace, který udává spolehlivost dat. Níže je uveden snímek obrazovky s možnostmi ICC programu SPSS. V části Typjsou dvě možnosti: „konzistence“ a „absolutní shoda“. Pokud je zvolena možnost „konzistence“, pak i když je u jedné sady čísel konzistencevysoká (např. 9, 8, 9, 8, 7…) a u druhé konzistence nízká (např. 4,3, 4, 3, 2…), jejich silná korelace chybně naznačuje, že data jsou ve vzájemné shodě. Proto je vhodné zvolit „absolutní shodu“.
Opakovaná měření
Měření spolehlivosti mezi daty lze také koncipovat a procedurálně provést jako opakovaná měřeníANOVA. Při ANOVA s opakovanými měřeními se měření provádí u stejnýchsubjektů několikrát, např. pretest, midterm a posttest. V tomtokontextu jsou subjekty také opakovaně měřeny pomocí webového uživatelského deníku,deníku a vlastního průzkumu. Následuje kód SAS pro opakovaná měření ANOVA:
data one; input user $ web_log log_book self_report;
cards;
1 215 260 200
2 178 200 150
3 100 111 120
4 135 172 100
5 139 150 140
6 198 200 230
7 135 150 180
8 120 110 100
9 289 276 300
proc glm;
classes user;
model web_log log_book self_report = user;
repeated time 3;
run;
Ve výše uvedeném programu je počet navštívených webových stránek devíti dobrovolníky zaznamenáván do logu uživatelských přístupů, osobní logovací knihy a dotazníku s vlastními údaji. Uživatelé jsou považováni za faktor mezi subjekty, zatímco tři měření jsou považována za faktor mezi měřeními. Následuje zkrácený výstup:
Zdroj variability DF Mean Square Mezisubjekt (uživatel) 8 10442.50 Meziprostředí (čas) 2 488,93 Ostatní 16 454.80 Na základě výše uvedených informací lze koeficient spolehlivosti vypočítat podle tohoto vzorce (Fisher, 1946; Horst, 1949):
r = MSmeziměření – MSreziduální ————————————————————– MSbetween-measure + (dfbetween-people X MSresidual) Posuneme číslo do vzorce:
r = 488.93 – 454,80 ————————————— 488,93 + ( 8 X 454,80) Spolehlivost je asi 0,0008, což je extrémně málo. Proto můžeme jít domů a na data zapomenout. Naštěstí se jedná pouze ohypotetický soubor dat. Ale co když se jedná o skutečný soubor dat? Musítebýt dost tvrdí na to, abyste se raději vzdali špatných dat, než abyste publikovali nějakázjištění, která jsou naprosto nespolehlivá.
Korelační a regresní analýza
Korelační analýza, která využívá Pearsonův koeficient Product Moment, je velmi jednoduchá a užitečná zejména tehdy, když váhy dvou měření nejsou stejné. Například protokol webového serveru může sledovat počet přístupů na stránky, zatímco údaje z vlastního hodnocení jsouLikertové škály (např. Jak často prohlížíte internet? 5=velmi často, 4=často, 3=občas, 2=zřídka, 5=nikdy). V tomto případě lze skóre uváděné samotným uživatelem použít jako prediktor pro regresi s přístupem na stránky.
Podobným přístupem je regresní analýza, při níž je jedna sada skóre(např. údaje z průzkumu) považována za prediktor, zatímco jiná sada skóre (např. denní záznam uživatele) je považována za závislou proměnnou. Pokud je použito více než dvě měření, lze použít vícenásobný regresní model, tj. to, které dává přesnější výsledek (např. log přístupů uživatelů na web), je považováno za závislou proměnnou a všechna ostatní měření (např. denní log uživatelů, údaje z průzkumu) jsou považována za nezávislé proměnné.
Reference
- Aschengrau, A., & Seage III, G. (2008). Základy epidemiologie ve veřejném zdravotnictví. Boston, MA: Jones and Bartlett Publishers.
- Blalock, H. M. (1974). (Ed.) Measurement in the social sciences (Měření ve společenských vědách): Theories and strategies. Chicago, Illinois: Aldine Publishing Company.
- Caskie, G. I. L., Sutton, M. C., & Eckhardt, A. G.(2014). Accuracy of self-reported college GPA [Přesnost sebehodnocení vysokoškolského průměru]: Studijní sebehodnocení: genderově podmíněné rozdíly podle úrovně dosaženého vzdělání a akademické sebeúčinnosti. Journal of College Student Development, 55, 385-390. 10.1353/csd.2014.0038
- Chan, D. (2009). Tak proč se mě ptáte? Jsou údaje ze sebehodnocení opravdu tak špatné? In Charles E. Lance a Robert J. Vandenberg (Eds.), Statistické a metodologické mýty a městské legendy: Doctrine,verity and fable in organizational and social sciences (s. 309-335). New York, NY: Routledge.
- Cook, T. D., & Campbell, D. T. (1979). Quasi-experimentation: Design and analysis issues (Otázky designu a analýzy). Boston, MA: Houghton Mifflin Company.
- Csikszentmihalyi, M., & Larson, R. (1987). Platnost a spolehlivost metody výběru zkušeností. Journal of Nervous and Mental Disease, 175, 526-536. https://doi.org/10.1097/00005053-198709000-00004
- Deese, J. (1972). Psychologie jako věda a umění. New York, NY: Harcourt Brace Jovanovich, Inc
- DeFranza, D., Lindow, M., Harrison, K., Mishra, A., &Mishra, H. (2020, August 10). Náboženství a reakce na směrnice COVID-19mitigation. American Psychologist. Advance online publication. http://dx.doi.org/10.1037/amp0000717.
- Fetters, W., Stowe, P., & Owings, J. (1984). High School and Beyond (Střední škola a dál). A national longitudinal study for the 1980s, quality of responses of high school students to questionnaire items. (NCES 84-216).Washington, D. C.: U.S. Department of Education. Office of EducationalResearch and Improvement. National center for Education Statistics.
- Finnigan, K. M., & Vazire, S. (2018). The incrementalvalidity of average state self-reports over global self-reports ofpersonality [Přírůstková validita průměrných stavových sebehodnocení oproti globálním sebehodnocením osobnosti]. Journal of Personality and Social Psychology, 115, 321-337. https://doi.org/10.1037/pspp0000136
- Fisher, R. J. (1946). Statistické metody pro výzkumné pracovníky (10. vydání). Edinburgh, UK: Oliver and Boyd.
- Hadaway, C. K., & Marlar, P. L. (2005). KolikAmeričanů se každý týden účastní bohoslužeb? Alternativní přístup k měření? Journal for the Scientific Study of Religion, 44, 307-322. DOI: 10.1111/j.1468-5906.2005.00288.x
- Hart, W.; & Tomazic, T. (1999 August). Porovnánípercentilových rozdělení pro antropometrické míry mezi třemi soubory dat. Příspěvek přednesený na výročním společném statistickém setkání, Baltimore, MD.
- Horst, P. (1949). A Generalized expression for the reliability of measures (Zobecněné vyjádření spolehlivosti měr). Psychometrika, 14, 21-31.
- Khoury, M., James, L., & Erikson, J. (1994). On theuse of affected controls to address recall bias in case-control studiesof birth defects [O použití postižených kontrol k řešení zkreslení vzpomínek ve studiích vrozených vad]. Teratology, 49, 273-281.
- Loftus, E. (2016, duben). Fikce paměti. Příspěvek přednesený na sjezdu Západní psychologické asociace. Long Beach, Kalifornie.
- Lowry, R. (2016). Kappa jako míra shody v kategoriálním třídění. Převzato z http://vassarstats.net/kappa.html
- Organizace pro hospodářskou spolupráci a rozvoj. (2017). Dotazník blahobytu pro šetření PISA 2018. Paříž: Autor. Získáno z https://www.oecd.org/pisa/data/2018database/CY7_201710_QST_MS_WBQ_NoNotes_final.pdf
- Schacter, D. L. (1999). Sedm hříchů paměti: Postřehy z psychologie a kognitivní neurovědy. Americká psychologie, 54, 182-203.
- Salvucci, S.; Walter, E., Conley, V; Fink, S; & Saba, M. (1997). Studie chyb měření v Národním centru pro statistiku vzdělávání. Washington D. C.: U. S. Department of Education.
- Stephens-Davidowitz, S. (2017). Všichni lžou: Velká data, nová data a co nám internet může říct o tom, kdo skutečně jsme. New York, NY: Dey Street Books.
 Přejděte do hlavní nabídky
Přejděte do hlavní nabídky Ostatní kurzyVyhledávač
|

Kontakt
|