Kdykoli diskutujeme o predikci modelu, je důležité pochopit chyby predikce (zkreslení a rozptyl). Mezi schopností modelu minimalizovat bias a rozptyl existuje kompromis. Správné pochopení těchto chyb by nám pomohlo nejen vytvořit přesné modely, ale také se vyhnout chybám typu overfitting a underfitting.
Začněme tedy se základy a podívejme se, jaký mají význam pro naše modely strojového učení.
Co je to bias?
Bias je rozdíl mezi průměrnou předpovědí našeho modelu a správnou hodnotou, kterou se snažíme předpovědět. Model s vysokým biasem věnuje velmi málo pozornosti trénovacím datům a příliš zjednodušuje model. Vždy vede k vysoké chybě na trénovacích i testovacích datech.
Co je to variance?
Variance je variabilita předpovědi modelu pro daný datový bod nebo hodnota, která nám říká rozptyl našich dat. Model s vysokou variance věnuje velkou pozornost tréninkovým datům a nezobecňuje na datech, se kterými se ještě nesetkal. Výsledkem je, že takové modely fungují velmi dobře na trénovacích datech, ale mají vysokou chybovost na testovacích datech.
Matematicky
Nechť je proměnná, kterou se snažíme předpovídat, označena jako Y a ostatní kovariáty jako X. Předpokládáme, že mezi nimi existuje vztah takový, že
Y=f(X) + e
Kde e je chybový člen a je normálně rozdělený se střední hodnotou 0.
Sestavíme model f^(X) z f(X) pomocí lineární regrese nebo jiné modelovací techniky.
Takže očekávaná kvadratická chyba v bodě x je
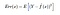
Tedy Err(x) lze dále rozložit jako

Err(x) je součet Bias², rozptylu a neredukovatelné chyby.
Iredukovatelná chyba je chyba, kterou nelze snížit vytvořením dobrých modelů. Je to míra množství šumu v našich datech. Zde je důležité si uvědomit, že bez ohledu na to, jak dobrý model vytvoříme, budou naše data obsahovat určité množství šumu nebo neredukovatelné chyby, kterou nelze odstranit.
Zkreslení a rozptyl pomocí diagramu býčího oka

V uvedeném diagramu je středem terče model, který dokonale předpovídá správné hodnoty. Jak se vzdalujeme od terče, jsou naše předpovědi stále horší a horší. Můžeme opakovat náš proces sestavování modelu, abychom získali jednotlivé zásahy do cíle.
Při učení pod dohledem dochází k nedostatečnému přizpůsobení, když model není schopen zachytit základní vzorec dat. Tyto modely mají obvykle vysoké zkreslení a nízký rozptyl. Stává se to, když máme k dispozici velmi malé množství dat pro sestavení přesného modelu nebo když se snažíme sestavit lineární model s nelineárními daty. Tento druh modelů je také velmi jednoduchý pro zachycení složitých vzorů v datech, jako je lineární a logistická regrese.
Při učení pod dohledem dochází k nadměrnému přizpůsobení, když náš model zachycuje šum spolu se základním vzorem v datech. K tomu dochází, když náš model hodně trénujeme nad zašuměnou sadou dat. Tyto modely mají nízké zkreslení a vysoký rozptyl. Tyto modely jsou velmi složité, například rozhodovací stromy, které jsou náchylné k overfittingu.

Proč je Bias Variance Tradeoff?
Pokud je náš model příliš jednoduchý a má velmi málo parametrů, pak může mít vysoké zkreslení a nízký rozptyl. Na druhou stranu, pokud má náš model velký počet parametrů, pak bude mít vysoký rozptyl a nízký bias. Musíme tedy najít správnou/dobrou rovnováhu, aniž bychom data příliš přizpůsobili a podhodnotili.
Tento kompromis ve složitosti je důvodem, proč existuje kompromis mezi zkreslením a rozptylem. Algoritmus nemůže být složitější a zároveň méně složitý.
Celková chyba
Chceme-li sestavit dobrý model, musíme najít dobrou rovnováhu mezi zkreslením a rozptylem tak, aby minimalizoval celkovou chybu.


Optimální rovnováha mezi zkreslením a rozptylem by nikdy nevedla k nadhodnocení nebo podhodnocení modelu.
Pro pochopení chování predikčních modelů je proto zásadní porozumět zkreslení a rozptylu.
Děkujeme za přečtení!