Způsob 1, špatný:
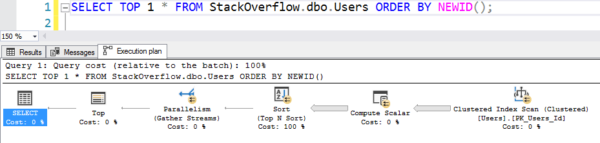
Plán se skenováním
Plán se skenováním
To na mém stroji trvalo 6 sekund, paralelně přes více vláken, což spotřebovalo desítky sekund CPU na všechny ty výpočty a třídění. (A tabulka Users nemá ani 1 GB.)
Metoda 2, lepší, ale divná: TABLESAMPLE
Tato metoda vyšla v roce 2005 a má spoustu háčků. Je to něco jako výběr náhodné stránky a pak vrácení několika řádků z této stránky. První řádek je tak trochu náhodný, ale ostatní ne.
Transact-SQL
|
1
|
SELECT * FROM StackOverflow.dbo.Users TABLESAMPLE (.01 PERCENT);
|
Plán vypadá, jako by prováděl skenování tabulky, ale provádí pouze 7 logických čtení:
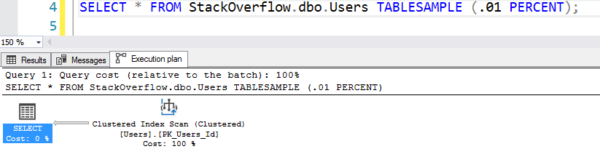
Plán s falešným skenováním
Ale zde jsou výsledky – je vidět, že skočí na náhodnou 8K stránku a pak začne postupně vyčítat řádky. Ve skutečnosti to nejsou náhodné řádky.
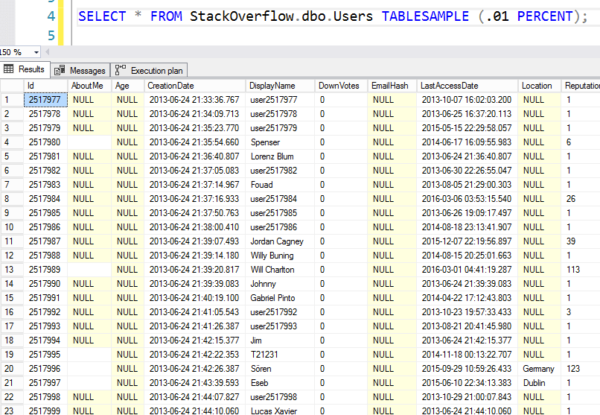
Náhodné jako čísla mafiánské loterie
Můžete místo toho použít velikost vzorku ROWS, ale to má poněkud zvláštní výsledky. Například v tabulce Stack Overflow Users, když jsem řekl TABLESAMPLE (50 ROWS), jsem ve skutečnosti dostal zpět 75 řádků. To proto, že SQL Server místo toho převádí velikost řádků na procenta.
Metoda 3, nejlepší, ale vyžaduje kód: Náhodný primární klíč
Zjistěte nejvyšší pole ID v tabulce, vygenerujte náhodné číslo a vyhledejte toto ID. Zde řadíme podle ID, protože chceme najít nejvyšší záznam, který skutečně existuje (zatímco náhodné číslo mohlo být smazáno.) Docela rychlé, ale hodí se jen pro jeden náhodný řádek. Pokud byste chtěli 10 řádků, museli byste takový kód zavolat 10krát (nebo vygenerovat 10 náhodných čísel a použít klauzuli IN.)
Plán provádění ukazuje shlukové prohledávání indexů, ale chytá pouze jeden řádek – mluvíme pouze o 6 logických čteních pro vše, co zde vidíte, a skončí téměř okamžitě:

Plán, který může
Je tu jeden háček: pokud má Id záporná čísla, nebude to fungovat podle očekávání. (Například řekněme, že začínáte pole identity na -1 a krok -1 směřuje stále dolů, jako moje morálka.)
Metoda 4, OFFSET-FETCH (2012+)
Daniel Hutmacher v komentářích přidal toto:
A řekl: „Ale správně to funguje jen se shlukovým indexem. Hádám, že je to proto, že to prohledá (@řádky) řádků v hromadě, místo aby provedl vyhledávání v indexu.“
Bonusová stopa č. 1: Sledujte, jak o tom diskutujeme
Přemýšleli jste někdy, jaké to je být v chatovací místnosti naší společnosti? Tato desetiminutová diskuse na Slacku vám poskytne docela dobrou představu:
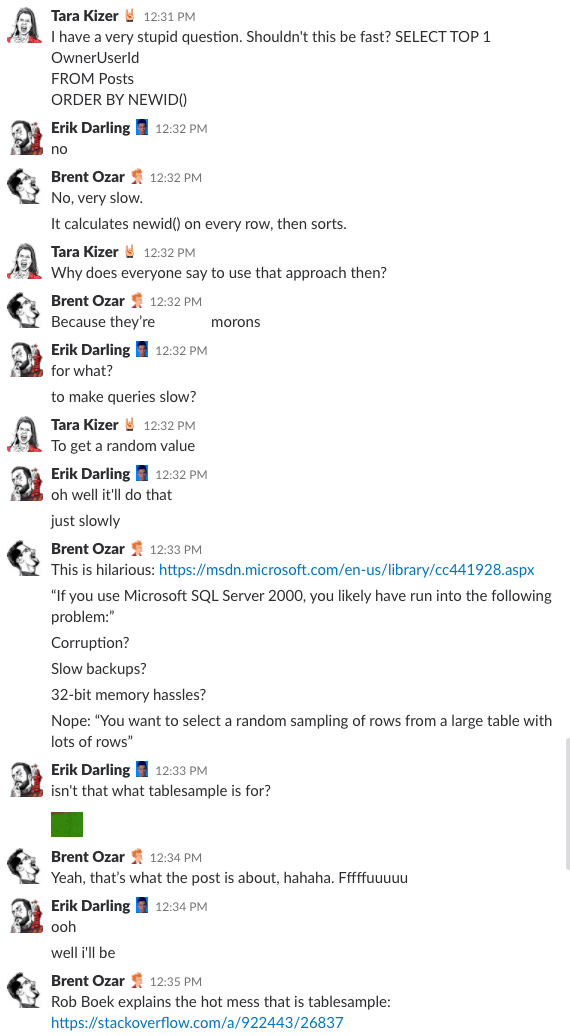
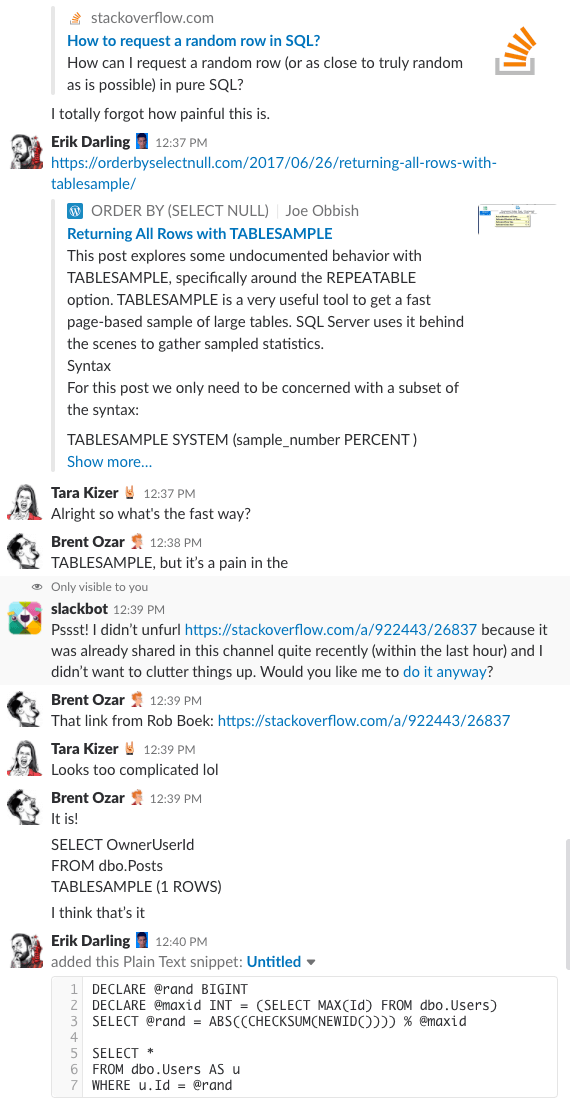
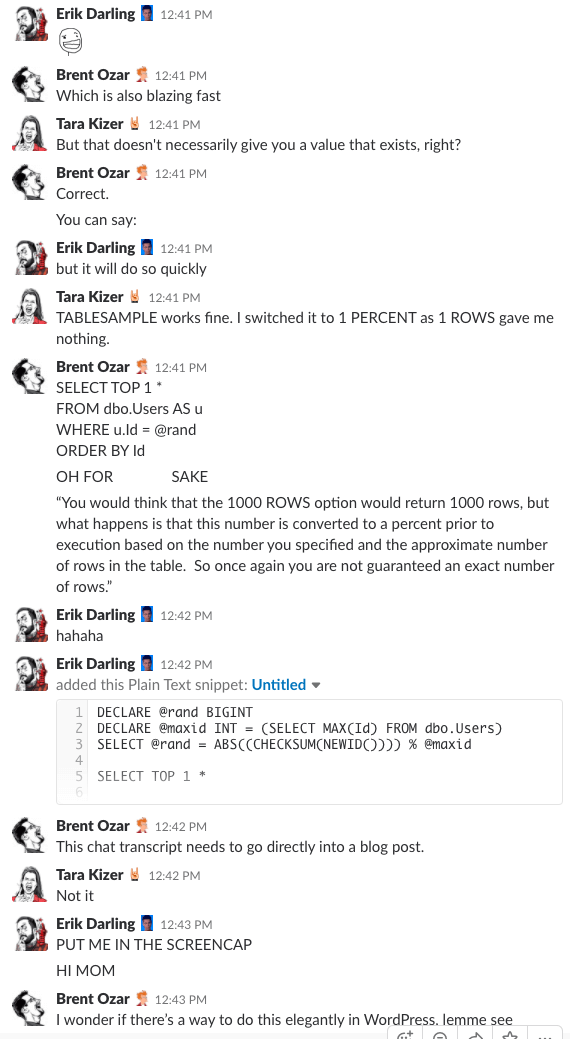
Spoiler alert: nebyla. Jen jsem pořídil screenshoty.
Bonusová skladba č. 2: Mitch Wheat kope hlouběji
Chcete hloubkovou analýzu náhodnosti několika různých technik? Mitch Wheat se ponoří opravdu hluboko a doplní to grafy!