- Funkce i její derivace jsou monotónní
- Výstup je nulový „centrický“
- Optimalizace je jednodušší
- Derivace /Diferenciál funkce Tanh (f'(x)) bude ležet mezi 0 a 1.
Nevýhody:
- Derivát funkce Tanh trpí „problémem mizejícího gradientu a explodujícího gradientu“.
- Pomalá konvergence – protože je výpočetně náročná.(Důvod použití exponenciální matematické funkce )
„Tanh je výhodnější než sigmoidní funkce, protože je nulově centrovaná a gradienty nejsou omezeny na pohyb v určitém směru“
3. Aktivační funkce ReLu(ReLu – rektifikované lineární jednotky):


ReLU je nelineární aktivační funkce, která si získala oblibu v umělé inteligenci. Funkce ReLu je také reprezentována jako f(x) = max(0,x).
- Funkce i její derivace jsou monotónní.
- Hlavní výhoda použití funkce ReLU- Neaktivuje všechny neurony současně.
- Výpočetně efektivní
- Derivát /Diferenciál funkce Tanh (f'(x)) bude 1, pokud f(x) > 0 jinak 0.
- Konverguje velmi rychle
Nevýhody:
- ReLu funkce v není „nulocentrická“. to způsobuje, že aktualizace gradientu jdou příliš daleko v různých směrech. 0 < výstup < 1, a to ztěžuje optimalizaci.
- Největším problémem je mrtvý neuron, což je způsobeno nediferencovatelností při nule.
„Problém umírajícího neuronu/mrtvého neuronu : Protože derivace ReLu f'(x) není 0 pro kladné hodnoty neuronu (f'(x)=1 pro x ≥ 0), ReLu se nenasytí (exploituje) a nejsou hlášeny žádné mrtvé neurony (Vanishing neuron)
. K nasycení a mizejícímu gradientu dochází pouze pro záporné hodnoty, které se při zadání ReLu změní na 0- To se nazývá problém umírajícího neuronu.“
4. Děravá aktivační funkce ReLu:
Leaky ReLU funkce není nic jiného než vylepšená verze ReLU funkce se zavedením „konstantního sklonu“


- Leaky ReLU je definován tak, aby řešil problém umírajícího neuronu/mrtvého neuronu.
- Problém umírajícího neuronu/mrtvého neuronu se řeší zavedením malého sklonu, který má záporné hodnoty odstupňované podle α, umožňuje jejich příslušným neuronům „zůstat naživu“.
- Funkce i její derivace jsou monotónní
- Povoluje zápornou hodnotu při zpětném šíření
- Je efektivní a snadná pro výpočet.
- Derivát Leaky je 1, když f(x) > 0 a pohybuje se mezi 0 a 1, když f(x) < 0.
Nevýhody:
- Leaky ReLU neposkytuje konzistentní předpovědi pro záporné vstupní hodnoty.
5. Aktivační funkce ELU (Exponenciální lineární jednotky):

- ELU se navrhuje také k řešení problému odumírajícího neuronu.
- Žádné problémy s mrtvým ReLU
- Nulově orientovaný
Nevýhody:
- Výpočetně náročný.
- Podobně jako u Leaky ReLU, ačkoli je teoreticky lepší než ReLU, v současné době neexistuje žádný dobrý důkaz v praxi, že ELU je vždy lepší než ReLU.
- f(x) je monotónní pouze tehdy, pokud alfa je větší nebo rovna 0.
- derivát f'(x) ELU je monotónní pouze tehdy, pokud alfa leží mezi 0 a 1.
- Pomalá konvergence v důsledku exponenciální funkce.
6. P ReLu (Parametrická ReLU) Aktivační funkce:

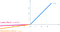
- Představu o leaky ReLU lze ještě rozšířit.
- Místo násobení x konstantním členem jej můžeme násobit „hyperparametrem (a-trénovaným parametrem)“, což zřejmě funguje lépe děravá ReLU. Toto rozšíření děravé ReLU se nazývá parametrická ReLU.
- Parametr α je obvykle číslo mezi 0 a 1 a je obecně relativně malý.
- Má mírnou výhodu oproti děravé ReLU díky trénovatelnému parametru.
- Zvládá problém umírajícího neuronu.
Nevýhody:
- Stejně jako děravé Relu.
- f(x) je monotónní, když a> nebo =0 a f'(x) je monotónní, když a =1
7. Nevýhody:
Stejně jako děravé Relu. Aktivační funkce Swish (A Self-Gated): (Sigmoidní lineární jednotka)

- Google Brain Team navrhl novou aktivační funkci s názvem Swish, která je jednoduše f(x) = x – sigmoid(x).
- Jejich experimenty ukazují, že Swish má tendenci fungovat lépe než ReLU na hlubších modelech v řadě náročných datových sad.
- Křivka funkce Swish je hladká a funkce je diferencovatelná ve všech bodech. To je užitečné během procesu optimalizace modelu a je to považováno za jeden z důvodů, proč Swish překonává ReLU.
- Funkce Swish není „monotónní“. To znamená, že hodnota funkce může klesat, i když vstupní hodnoty rostou.
- Funkce je shora neohraničená a zdola ohraničená.
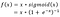
„Swish má tendenci se neustále vyrovnávat nebo překonávat ReLu“
Všimněte si, že výstup funkce swish může klesat, i když vstupní hodnoty rostou. To je zajímavá a pro swish specifická vlastnost (kvůli nemonotónnímu charakteru)
f(x)=2x*sigmoid(beta*x)
Pokud si myslíme, že beta=0 je jednoduchá verze Swishe, což je naučitelný parametr, pak sigmoidní část je vždy 1/2 a f (x) je lineární. Na druhou stranu, pokud je beta velmi velká hodnota, sigmoida se stává téměř dvojcifernou funkcí (0 pro x<0,1 pro x>0). Funkce f (x) tedy konverguje k funkci ReLU. Proto je zvolena standardní Swishova funkce beta = 1. Tímto způsobem je zajištěna měkká interpolace (přiřazení množin hodnot proměnných funkci v daném rozsahu a požadované přesnosti). Výborně! Bylo nalezeno řešení problému mizivosti gradientů.
8 Řešení problému mizivosti gradientů bylo nalezeno.Softplus
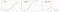
Funkce softplus je podobná funkci ReLU, ale je relativně plynulejší.Funkce Softplus neboli SmoothRelu f(x) = ln(1+exp x).
Derivát funkce Softplus je f'(x) je logistická funkce (1/(1+exp x)).
Hodnota funkce se pohybuje v rozmezí (0, + inf).f(x) i f'(x) jsou monotónní.
9. Funkce Softplus je funkce, která se pohybuje v rozmezí (0, + inf).Softmax neboli normalizovaná exponenciální funkce:

Funkce „softmax“ je také typ sigmoidální funkce, ale je velmi užitečná pro řešení klasifikačních problémů více tříd.
„Softmax lze popsat jako kombinaci více sigmoidálních funkcí.“
„Funkce Softmax vrací pravděpodobnost příslušnosti datového bodu ke každé jednotlivé třídě.“
Při sestavování sítě pro problém více tříd by výstupní vrstva měla tolik neuronů, kolik je tříd v cíli.
Například pokud máte tři třídy, ve výstupní vrstvě by byly tři neurony. Předpokládejme, že jste dostali výstup z neuronů jako . při použití funkce softmax nad těmito hodnotami dostanete následující výsledek – . Ty představují pravděpodobnost příslušnosti datového bodu k jednotlivým třídám. Z výsledku vyplývá, že vstup patří do třídy A.
„Všimněte si, že součet všech hodnot je 1.“
Kterou z nich je lepší použít ? Jak vybrat tu správnou?
Pravdu řečeno, neexistuje žádné pevné pravidlo pro výběr aktivační funkce. nemůžeme rozlišovat mezi aktivačními funkcemi. každá aktivační funkce má svá pro a proti. o všech dobrých a špatných se rozhodneme na základě stop.
Ale na základě vlastností problému bychom mohli být schopni provést lepší výběr pro snadnější a rychlejší konvergenci sítě.
- Sigmoidní funkce a jejich kombinace obecně fungují lépe v případě klasifikačních problémů
- Sigmoidům a tanh funkcím se někdy vyhýbáme kvůli problému mizejícího gradientu
- V moderní době se hojně používá aktivační funkce ReLU.
- V případě mrtvých neuronů v našich sítích kvůli ReLu je pak nejlepší volbou děravá funkce ReLU
- Funkce ReLU by se měla používat pouze ve skrytých vrstvách
„Zpravidla lze začít s použitím funkce ReLU a poté přejít na jiné aktivační funkce v případě, že ReLU neposkytuje optimální výsledky“
.