- Introdução
- Goal
- A. Métodos de filtragem
- Teste Qui-quadrado
- Pescador Pontuação
- Coeficiente de correlação
- Limite de Variância
- Mean Absolute Difference (MAD)
- Rácio de dispersão
- B. Métodos de embalagem:
- Selecção de Característica Avançada
- Eliminação de Característica para Frente
- Seleção Exaustiva de Característica
- Eliminação recursiva de características
- C. Métodos incorporados:
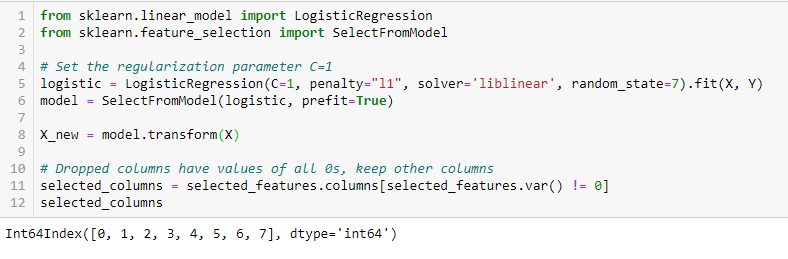
- LASSO Regularização (L1)
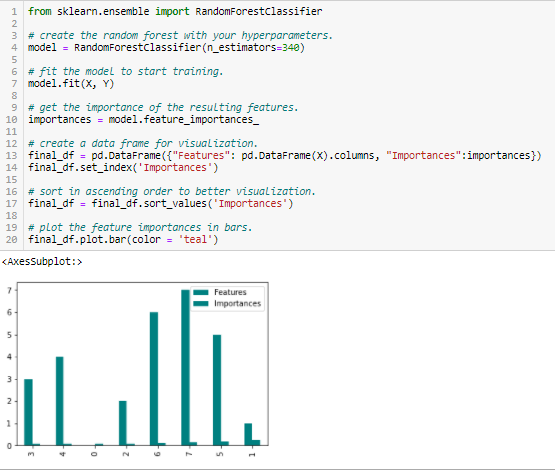
- Importância Florestal Aleatória
- Conclusão
Introdução
Quando se constrói um modelo de aprendizagem de máquina na vida real, é quase raro que todas as variáveis do conjunto de dados sejam úteis para construir um modelo. Adicionar variáveis redundantes reduz a capacidade de generalização do modelo e pode também reduzir a precisão geral de um classificador. Além disso, adicionar mais e mais variáveis a um modelo aumenta a complexidade geral do modelo.
Como pela Lei de Parsimonia de ‘Occam’s Razor’, a melhor explicação para um problema é aquela que envolve o menor número possível de suposições. Assim, a seleção de características torna-se uma parte indispensável na construção de modelos de aprendizagem de máquinas.
Goal
O objetivo da seleção de características na aprendizagem de máquinas é encontrar o melhor conjunto de características que permita construir modelos úteis de fenômenos estudados.
As técnicas de seleção de características na aprendizagem de máquinas podem ser amplamente classificadas nas seguintes categorias:
Técnicas Supervisionadas: Estas técnicas podem ser usadas para dados rotulados, e são usadas para identificar as características relevantes para aumentar a eficiência dos modelos supervisionados como classificação e regressão.
Técnicas não supervisionadas: Estas técnicas podem ser usadas para dados não rotulados.
Do ponto de vista taxonômico, estas técnicas são classificadas como:
A. Métodos de filtragem
B. Métodos de embalamento
C. Métodos incorporados
D. Métodos híbridos
Neste artigo, vamos discutir algumas técnicas populares de selecção de características na aprendizagem de máquinas.
A. Métodos de filtragem
Métodos de filtragem captam as propriedades intrínsecas das características medidas através de estatísticas univariadas, em vez de desempenho de validação cruzada. Estes métodos são mais rápidos e menos caros computacionalmente do que os métodos de invólucro. Ao lidar com dados de alta dimensão, é computacionalmente mais barato usar métodos de filtragem.
Vamos discutir algumas dessas técnicas:
Ganho de informação
Ganho de informação calcula a redução da entropia a partir da transformação de um conjunto de dados. Ele pode ser usado para seleção de características avaliando o ganho de informação de cada variável no contexto da variável alvo.
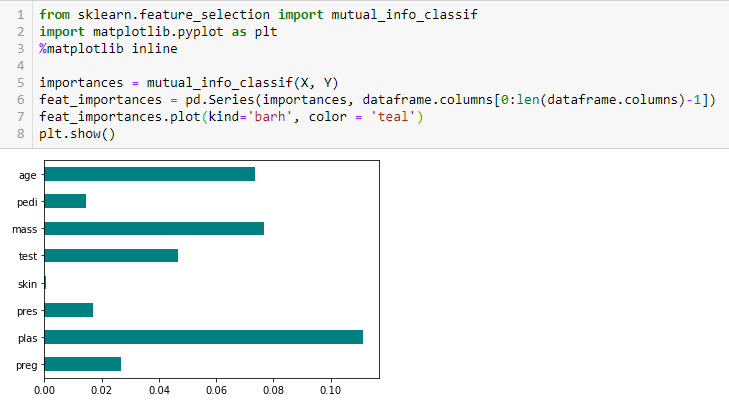
Teste Qui-quadrado
O teste Qui-quadrado é usado para características categóricas em um conjunto de dados. Nós calculamos o Qui-quadrado entre cada característica e o alvo e selecionamos o número desejado de características com as melhores pontuações do Qui-quadrado. A fim de aplicar corretamente o qui-quadrado para testar a relação entre várias características no conjunto de dados e a variável alvo, as seguintes condições têm de ser cumpridas: as variáveis têm de ser categóricas, amostradas independentemente e os valores devem ter uma frequência esperada superior a 5,
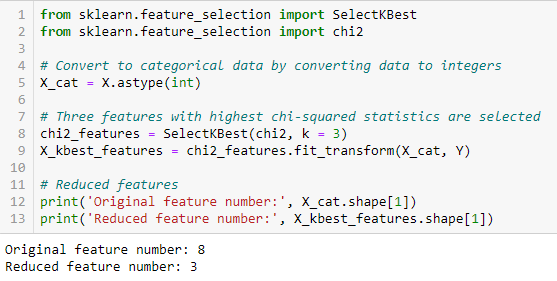
Pescador Pontuação
Pescador Pontuação é um dos métodos supervisionados de seleção de características mais amplamente utilizados. O algoritmo que vamos usar retorna as classificações das variáveis baseadas na pontuação do pescador em ordem decrescente. Podemos então selecionar as variáveis conforme o caso.
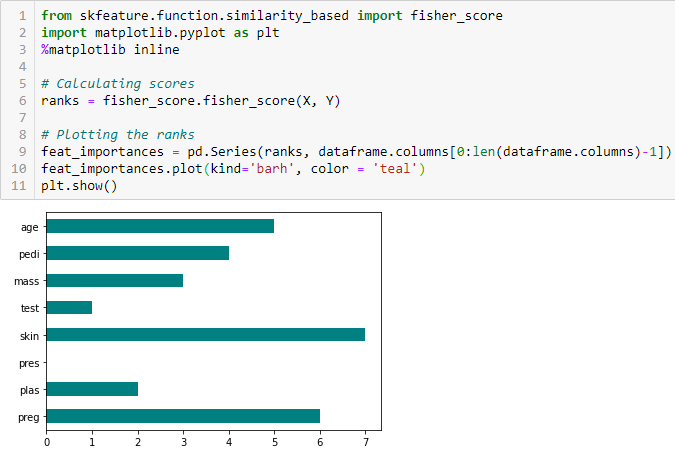
Coeficiente de correlação
Correlação é uma medida da relação linear de 2 ou mais variáveis. Através da correlação, podemos prever uma variável a partir da outra. A lógica por trás do uso da correlação para seleção de características é que as boas variáveis estão altamente correlacionadas com o alvo. Além disso, as variáveis devem estar correlacionadas com o alvo, mas não devem estar relacionadas entre si.
Se duas variáveis estiverem correlacionadas, podemos prever uma a partir da outra. Portanto, se duas características estiverem correlacionadas, o modelo só precisa realmente de uma delas, já que a segunda não adiciona informações adicionais. Vamos usar a Correlação Pearson aqui.
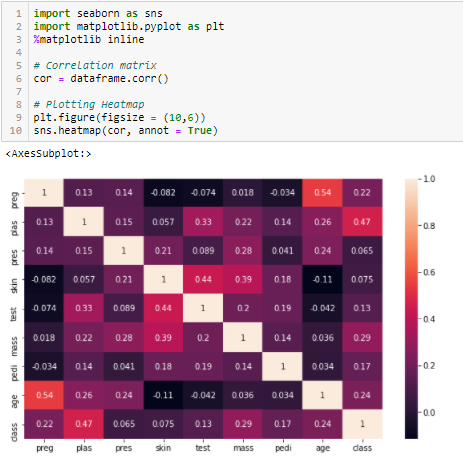
Precisamos definir um valor absoluto, digamos 0,5 como limiar para a seleção das variáveis. Se acharmos que as variáveis preditoras estão correlacionadas entre si, podemos deixar cair a variável que tem um valor de coeficiente de correlação menor com a variável alvo. Podemos também calcular múltiplos coeficientes de correlação para verificar se mais de duas variáveis estão correlacionadas uma com a outra. Este fenômeno é conhecido como multicolinearidade.
Limite de Variância
O limiar de variância é uma simples abordagem de linha de base para seleção de características. Ela remove todas as características cuja variância não atinge algum limiar. Por padrão, ele remove todas as características de variação zero, ou seja, características que têm o mesmo valor em todas as amostras. Assumimos que características com uma variância maior podem conter informações mais úteis, mas note que não estamos levando em conta a relação entre variáveis de características ou características e variáveis alvo, o que é uma das desvantagens dos métodos de filtragem.

O get_support retorna um vetor booleano onde True significa que a variável não tem variância zero.
Mean Absolute Difference (MAD)
‘A diferença média absoluta (MAD) calcula a diferença absoluta a partir do valor médio. A principal diferença entre a variância e as medidas do DMA é a ausência do quadrado no último. O DMA, assim como a variância, também é uma variante de escala’. Isto significa que maior o DMA, maior o poder discriminatório.
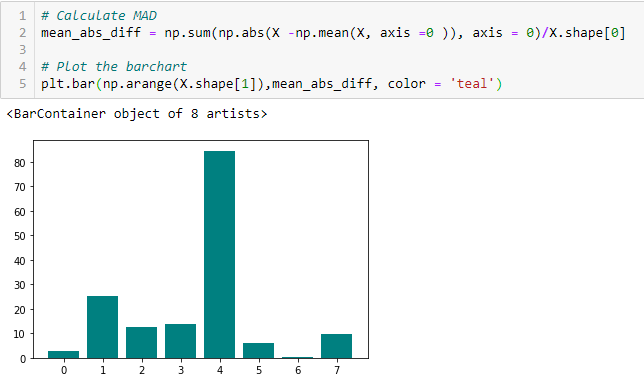
Rácio de dispersão
‘Outra medida de dispersão aplica a média aritmética (AM) e a média geométrica (GM). Para uma dada característica (positiva) Xi em n padrões, a AM e GM são dadas por
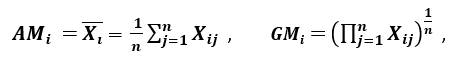
>respectivamente; desde AMi ≥ GMi, com manutenção de igualdade se e somente se Xi1 = Xi2 = …. = Xin, então a razão
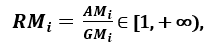
> pode ser usada como medida de dispersão. Uma maior dispersão implica um maior valor de Ri, portanto, uma característica mais relevante. Por outro lado, quando todas as amostras de característica têm (aproximadamente) o mesmo valor, Ri está próximo de 1, indicando uma característica de baixa relevância’.

 ‘
‘
B. Métodos de embalagem:
Embrulhadores requerem algum método para pesquisar o espaço de todos os subconjuntos possíveis de características, avaliando a sua qualidade através da aprendizagem e avaliação de um classificador com esse subconjunto de características. O processo de selecção de características é baseado num algoritmo específico de aprendizagem da máquina que estamos a tentar encaixar num dado conjunto de dados. Ele segue uma abordagem de busca gananciosa, avaliando todas as combinações possíveis de características em relação ao critério de avaliação. Os métodos de wrapper geralmente resultam em melhor precisão preditiva do que os métodos de filtragem.
Vamos discutir algumas destas técnicas:
Selecção de Característica Avançada
Este é um método iterativo em que começamos com a variável de melhor desempenho contra o alvo. Em seguida, selecionamos outra variável que dá o melhor desempenho em combinação com a primeira variável selecionada. Este processo continua até que o critério predefinido seja alcançado.
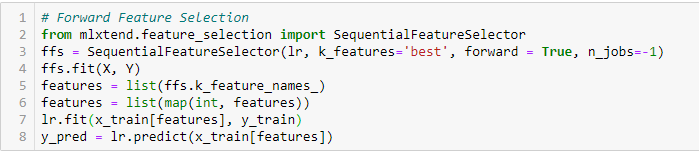
Eliminação de Característica para Frente
Este método funciona exatamente oposto ao método de Seleção de Característica para Frente. Aqui, começamos com todos os recursos disponíveis e construímos um modelo. Em seguida, nós a variável do modelo que dá o melhor valor de medida de avaliação. Este processo continua até que o critério predefinido seja alcançado.
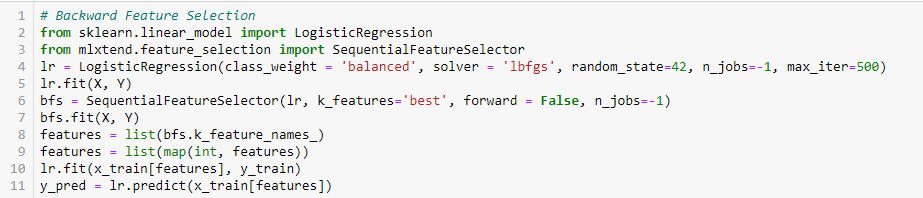
Este método, juntamente com o discutido acima, também é conhecido como método de Seleção Sequencial de Característica.
Seleção Exaustiva de Característica
Este é o método de seleção de característica mais robusto coberto até agora. Esta é uma avaliação da força bruta de cada subconjunto de características. Isto significa que ele tenta cada combinação possível das variáveis e retorna o subconjunto de melhor desempenho.
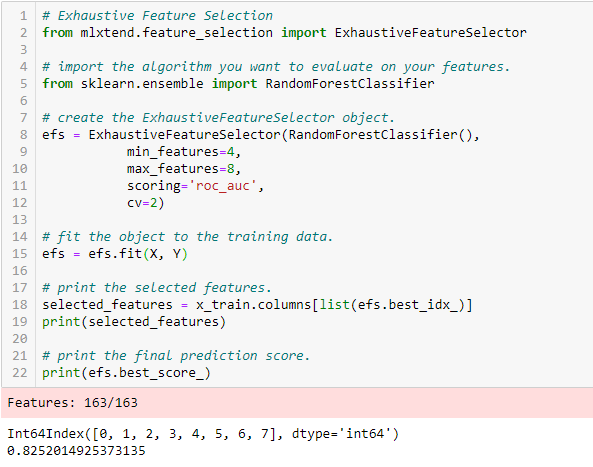
Eliminação recursiva de características
‘Dado um estimador externo que atribui pesos às características (por exemplo, os coeficientes de um modelo linear), o objetivo da eliminação recursiva de características (RFE) é selecionar características considerando recursivamente conjuntos cada vez menores de características. Primeiro, o estimador é treinado sobre o conjunto inicial de características e a importância de cada característica é obtida por meio de um atributo coef_de_característica ou por meio de um atributo_importâncias_de_característica.
Então, as características menos importantes são podadas a partir do conjunto actual de características. Este procedimento é repetido recursivamente no conjunto de características podadas até que o número desejado de características a seleccionar seja eventualmente atingido.’
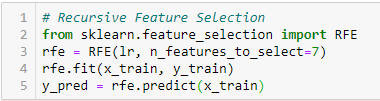
C. Métodos incorporados:
Estes métodos englobam os benefícios dos métodos de invólucro e de filtro, incluindo interacções de características mas mantendo também um custo computacional razoável. Os métodos incorporados são iterativos no sentido em que cuidam de cada iteração do processo de treinamento do modelo e extraem cuidadosamente as características que mais contribuem para o treinamento de uma determinada iteração.
Vamos discutir algumas destas técnicas clique aqui:
LASSO Regularização (L1)
Regularização consiste em adicionar uma penalidade aos diferentes parâmetros do modelo de aprendizagem da máquina para reduzir a liberdade do modelo, ou seja, para evitar o excesso de ajustes. Na regularização do modelo linear, a penalidade é aplicada sobre os coeficientes que multiplicam cada um dos preditores. A partir dos diferentes tipos de regularização, Lasso ou L1 tem a propriedade que é capaz de reduzir alguns dos coeficientes a zero. Portanto, essa característica pode ser removida do modelo.
Importância Florestal Aleatória
Florestas Aleatórias é uma espécie de Algoritmo de Ensacamento que agrega um número especificado de árvores de decisão. As estratégias baseadas em árvores utilizadas pelas florestas aleatórias classificam-se naturalmente pelo quão bem elas melhoram a pureza do nó, ou seja, uma diminuição da impureza (impureza Gini) em todas as árvores. Os nós com maior diminuição da impureza ocorrem no início das árvores, enquanto as notas com menor diminuição da impureza ocorrem no final das árvores. Assim, podando árvores abaixo de um determinado nó, podemos criar um subconjunto das características mais importantes.
Conclusão
Discutimos algumas técnicas para seleção de características. Deixamos de propósito as técnicas de extração de características como Análise de Componentes Principais, Decomposição de Valores Singulares, Análise Linear Discriminatória, etc. Estes métodos ajudam a reduzir a dimensionalidade dos dados ou reduzir o número de variáveis, preservando a variância dos dados.
Partindo dos métodos discutidos acima, existem muitos outros métodos de seleção de características. Existem também métodos híbridos que utilizam tanto técnicas de filtragem como de acondicionamento. Se você deseja explorar mais sobre as técnicas de seleção de características, um grande material de leitura abrangente na minha opinião seria “Seleção de Características para Reconhecimento de Dados e Padrões” por Urszula Stańczyk e Lakhmi C. Jain.