Update 29-May-2018: O propósito deste artigo é triplo (1) Mostrar que sempre precisaremos de um modelo de dados (seja feito por humanos ou máquinas) (2) Mostrar que modelagem física não é o mesmo que modelagem lógica. Na verdade, é muito diferente e depende da tecnologia subjacente. Mas precisamos de ambos. Eu ilustrei este ponto usando Hadoop na camada física (3) Mostrar o impacto do conceito de imutabilidade na modelagem de dados.
- É a modelagem dimensional morta?
- Por que precisamos modelar nossos dados?
- Por que precisamos de modelos dimensionais?
- Modelação de Dados vs Modelação Dimensional
- Então por que algumas pessoas afirmam que a modelagem dimensional está morta?
- O Data Warehouse está morto Confusão
- O Esquema de leitura de mal-entendidos
- Denormalização revisitada. Os aspectos físicos do modelo.
- Desnormalização até sua conclusão completa
- Distribuição de dados numa base de dados relacional distribuída (MPP)
- Data Distribution on Hadoop
- Modelos dimensionais no Hadoop
- Hadoop e Dimensões de Mudança Lenta
- Solução de armazenamento no Hadoop
- O veredicto. São modelos dimensionais e esquemas estelares obsoletos?
- Leitura Complementar sobre Modelagem Dimensional na Era dos Grandes Dados
É a modelagem dimensional morta?
Antes de eu dar uma resposta a esta pergunta vamos dar um passo atrás e primeiro dar uma olhada no que queremos dizer por modelagem de dados dimensionais.
Por que precisamos modelar nossos dados?
Contrário a um mal-entendido comum, não é o único propósito dos modelos de dados para servir como um diagrama ER para projetar uma base de dados física. Os modelos de dados representam a complexidade dos processos de negócios em uma empresa. Eles documentam importantes regras e conceitos de negócio e ajudam a padronizar a terminologia chave da empresa. Eles fornecem clareza e ajudam a desvendar pensamentos confusos e ambigüidades sobre os processos de negócios. Além disso, você pode usar modelos de dados para se comunicar com outras partes interessadas. Você não construiria uma casa ou uma ponte sem um projeto. Então por que você construiria uma aplicação de dados como um data warehouse sem um plano?
Por que precisamos de modelos dimensionais?
A modelagem dimensional é uma abordagem especial para modelagem de dados. Também usamos as palavras data mart ou star schema como sinônimos para um modelo dimensional. Esquemas estelares são otimizados para análise de dados. Dê uma olhada no modelo dimensional abaixo. É bastante intuitivo de entender. Vemos imediatamente como podemos fatiar e cortar os dados das nossas encomendas por cliente, produto ou data e medir o desempenho do processo de negócio das encomendas agregando e comparando métricas.
Uma das ideias centrais sobre modelação dimensional é definir o nível mais baixo de granularidade num processo de negócio transaccional. Quando nós cortamos e cortamos dados e perfuramos os dados, este é o nível de folha a partir do qual não podemos perfurar mais. Colocando de outra forma, o nível mais baixo de granularidade num esquema em estrela é uma junção do facto a todas as tabelas dimensionais sem quaisquer agregações.
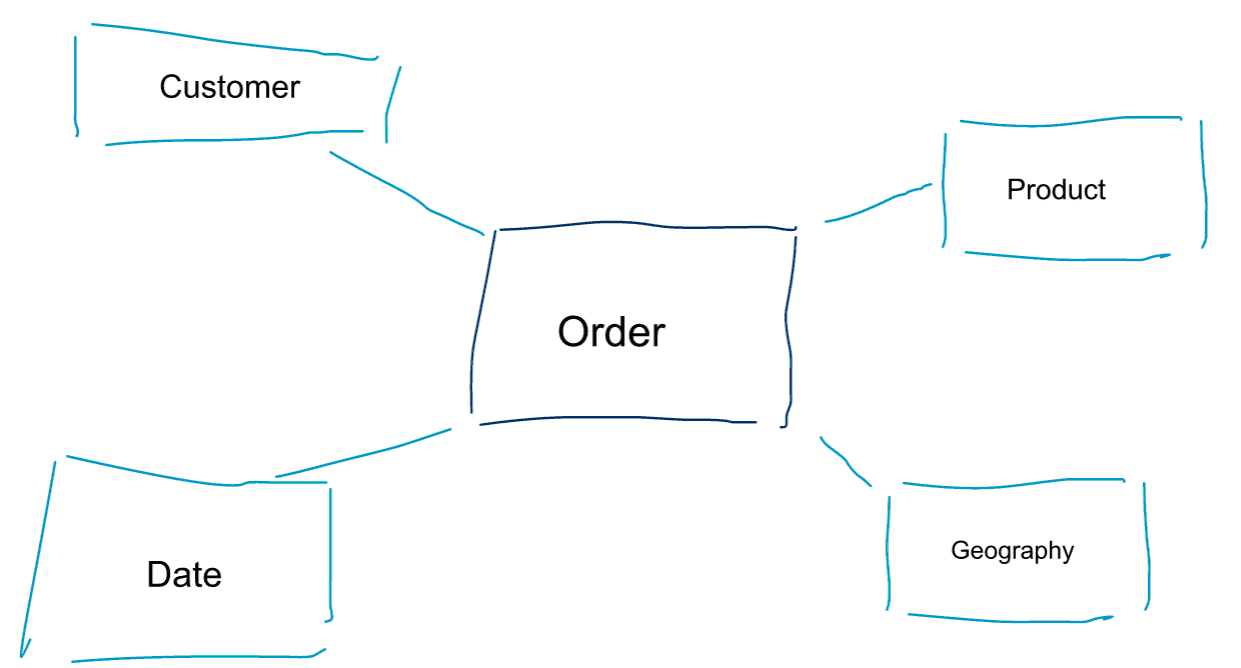
Modelação de Dados vs Modelação Dimensional
Na modelação de dados standard pretendemos eliminar a repetição e redundância de dados. Quando acontece uma mudança nos dados, só precisamos mudá-los em um lugar. Isto também ajuda na qualidade dos dados. Os valores não ficam fora de sincronia em vários lugares. Dê uma olhada no modelo abaixo. Ele contém várias tabelas que representam conceitos geográficos. Em um modelo normalizado, temos uma tabela separada para cada entidade. Em um modelo dimensional temos apenas uma tabela: a de geografia. Nesta tabela, as cidades serão repetidas várias vezes. Uma vez para cada cidade. Se o país muda de nome temos que atualizar o país em muitos lugares
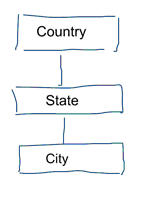
Note: A modelagem de dados padrão também é referida como modelagem 3NF.
A abordagem padrão para modelagem de dados não é adequada para fins de cargas de trabalho de Business Intelligence. Muitas tabelas resultam em muitas junções. As junções tornam as coisas mais lentas. Na análise de dados evitamo-las sempre que possível. Em modelos dimensionais nós desnormalizamos várias tabelas relacionadas em uma tabela, por exemplo, as várias tabelas do nosso exemplo anterior podem ser pré-unidas em apenas uma tabela: geography.
Então por que algumas pessoas afirmam que a modelagem dimensional está morta?
Eu acho que você concordaria que a modelagem de dados em geral e a modelagem dimensional em particular é um exercício bastante útil. Então porque é que algumas pessoas afirmam que a modelação dimensional não é útil na era dos grandes dados e Hadoop?
Como pode imaginar existem várias razões para isto.
O Data Warehouse está morto Confusão
Primeiro de tudo, algumas pessoas confundem a modelação dimensional com o data warehousing. Eles alegam que o Data Warehousing está morto e como resultado a modelagem dimensional pode ser consignada para o caixote do lixo da história também. Este é um argumento logicamente coerente. Contudo, o conceito de armazenamento de dados está longe de ser obsoleto. Precisamos sempre de dados integrados e fiáveis para povoar os nossos dashboards de BI. Se quiser saber mais, recomendo o nosso curso de formação Big Data for Data Warehouse Professionals. No curso vou entrar nos detalhes e explicar como o data warehouse é tão relevante como sempre. Também vou mostrar como as grandes ferramentas e tecnologias emergentes são úteis para o armazenamento de dados.

O Esquema de leitura de mal-entendidos
O segundo argumento que ouço frequentemente é assim. Seguimos um esquema na abordagem de leitura e não precisamos mais modelar nossos dados’. Na minha opinião, o conceito de schema on read é um dos maiores mal-entendidos na análise de dados. Concordo que é útil armazenar inicialmente seus dados brutos em um depósito de dados que é leve no esquema. No entanto, este argumento não deve ser usado como uma desculpa para não modelar os seus dados completamente. O esquema na abordagem de leitura está apenas derrubando a lata e a responsabilidade para os processos posteriores. Alguém ainda tem que morder a bala de definir os tipos de dados. Todo e qualquer processo que acessa o despejo de dados sem esquema precisa descobrir por si mesmo o que está acontecendo. Este tipo de trabalho se soma, é completamente redundante e pode ser facilmente evitado definindo tipos de dados e um esquema apropriado.
Denormalização revisitada. Os aspectos físicos do modelo.
Existem realmente alguns argumentos válidos para declarar os modelos dimensionais obsoletos? Existem de facto alguns argumentos melhores do que os dois que enumerei acima. Eles requerem algum entendimento da modelagem de dados físicos e da forma como o Hadoop funciona. Bear with me.
Earlier on I briefly mentioned one of the reasons why we model our data dimensionally. É em relação à forma como os dados são armazenados fisicamente no nosso armazém de dados. Na modelagem de dados padrão, cada entidade do mundo real recebe sua própria tabela. Fazemos isso para evitar redundância de dados e o risco de problemas de qualidade de dados se infiltrarem em nossos dados. Quantas mais tabelas tivermos, mais associações precisamos. Essa é a desvantagem. As uniões de tabelas são caras, especialmente quando juntamos um grande número de registros de nossos conjuntos de dados. Quando modelamos os dados dimensionalmente, consolidamos várias tabelas em uma só. Dizemos que pré-inserimos ou desnormalizamos os dados. Agora temos menos tabelas, menos uniões, e como resultado, menor latência e melhor desempenho da consulta.
Participar na discussão deste post no LinkedIn
Desnormalização até sua conclusão completa
Por que não levar a desnormalização até sua conclusão completa? Livrar-se de todas as adesões e ter apenas uma única tabela de fatos? De facto, isto eliminaria a necessidade de qualquer adesão. Contudo, como você pode imaginar, tem alguns efeitos colaterais. Primeiro de tudo, aumenta a quantidade de armazenamento necessária. Agora precisamos de armazenar uma grande quantidade de dados redundantes. Com o advento dos formatos de armazenamento colunar para análise de dados, isso é menos preocupante hoje em dia. O maior problema da desnormalização é o fato de que cada vez que um valor de um dos atributos muda, temos que atualizar o valor em vários lugares – possivelmente milhares ou milhões de atualizações. Uma forma de contornar este problema é recarregar completamente os nossos modelos numa base nocturna. Muitas vezes isso será muito mais rápido e fácil do que aplicar um grande número de atualizações. Os bancos de dados colunares normalmente adotam a seguinte abordagem. Primeiro armazenam as actualizações dos dados na memória e assincronamente escrevem-nos no disco.
Distribuição de dados numa base de dados relacional distribuída (MPP)
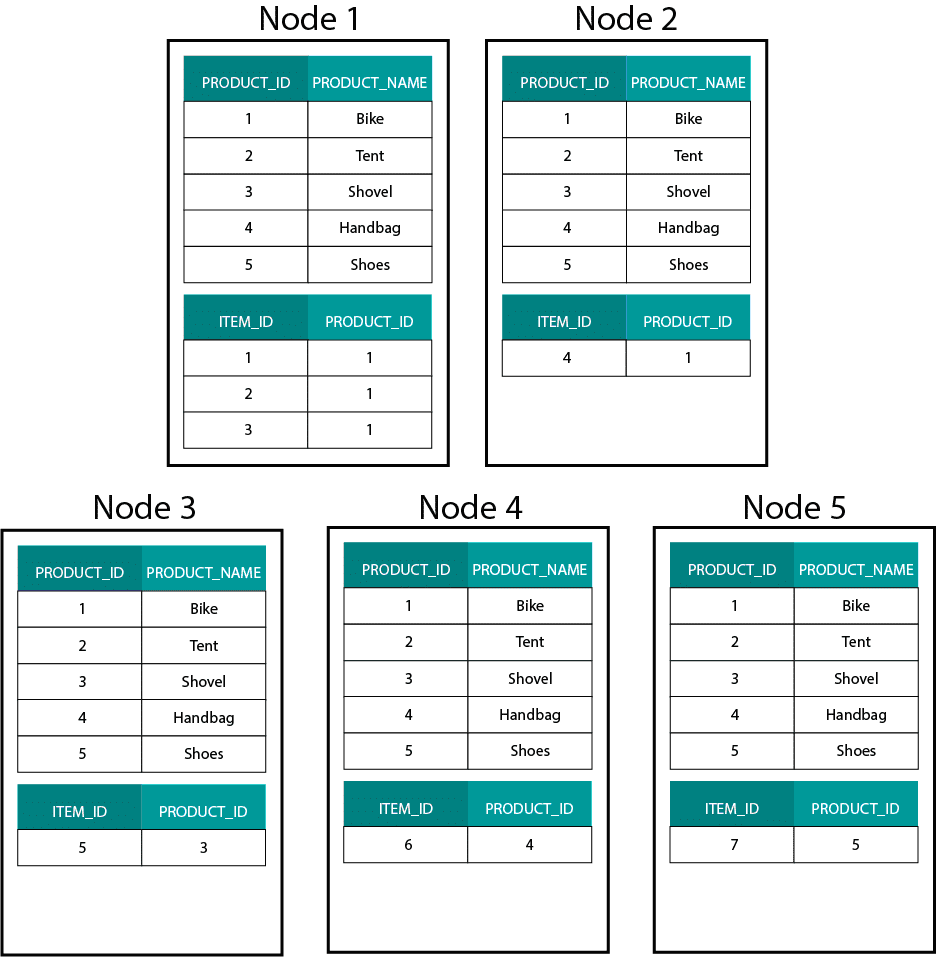
Ao criar modelos dimensionais no Hadoop, e.g. Hive, SparkSQL etc. precisamos de compreender melhor uma característica central da tecnologia que a distingue de uma base de dados relacional distribuída (MPP) tal como Teradata etc. Ao distribuir dados entre os nós de uma MPP temos o controlo sobre a colocação de registos. Com base em nossa estratégia de particionamento, por exemplo, hash, lista, intervalo, etc. podemos co-localizar as chaves de registros individuais através de abas no mesmo nó. Com a co-localidade de dados garantida, nossas junções são super-rápidas, pois não precisamos enviar nenhum dado através da rede. Dê uma olhada no exemplo abaixo. Registros com o mesmo ORDER_ID das tabelas ORDER_ID e ORDER_ITEM acabam no mesmo nó.
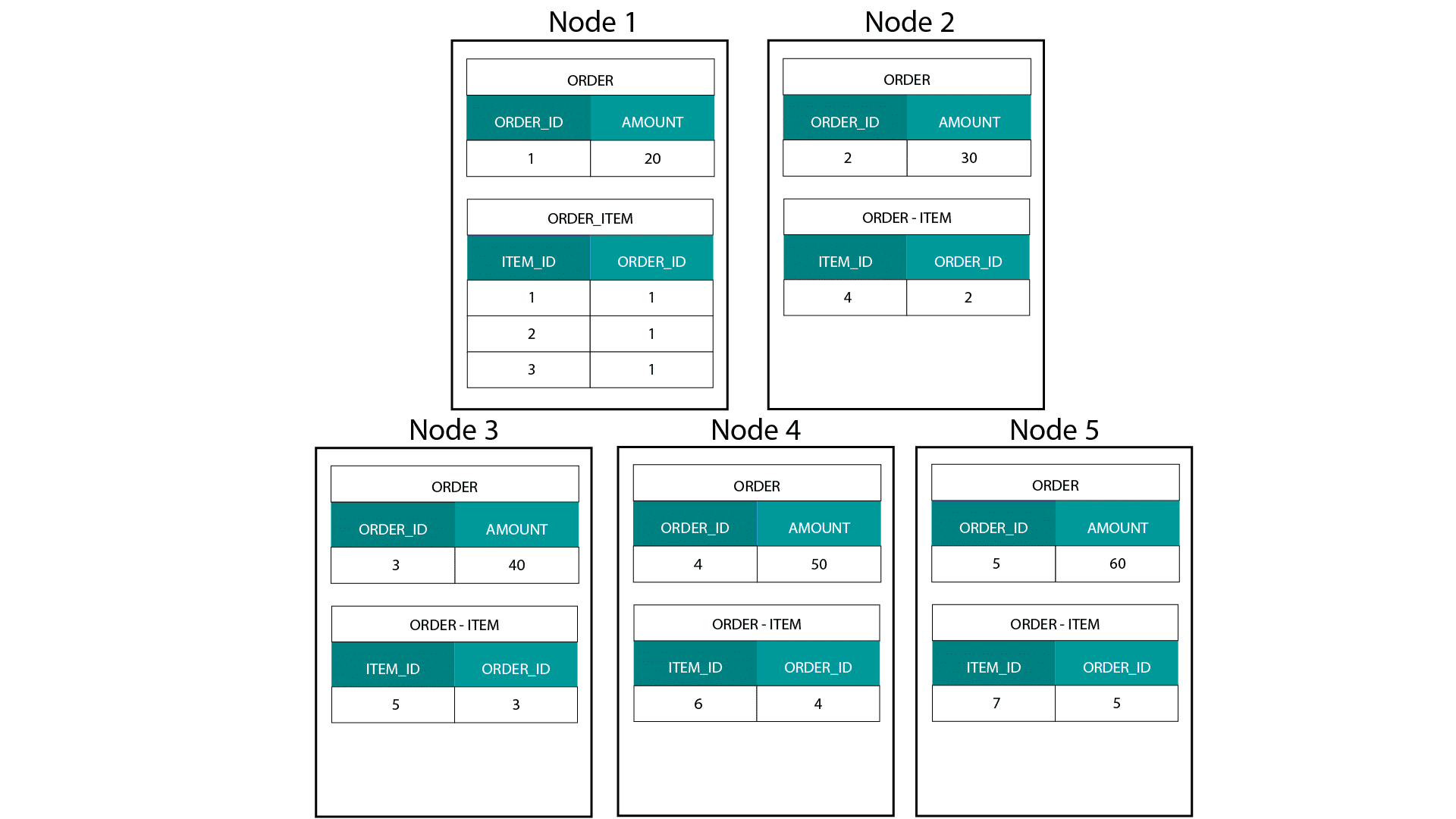
Keys for order_id of order e order_item table are co-located on the same nodes.
Data Distribution on Hadoop
This is very different from Hadoop based systems. Lá nós dividimos nossos dados em pedaços grandes e os distribuímos e replicamos através de nossos nós no Hadoop Distributed File System (HDFS). Com esta estratégia de distribuição de dados, não podemos garantir a co-localidade dos dados. Dê uma olhada no exemplo abaixo. Os registros para a chave ORDER_ID acabam em diferentes nós.
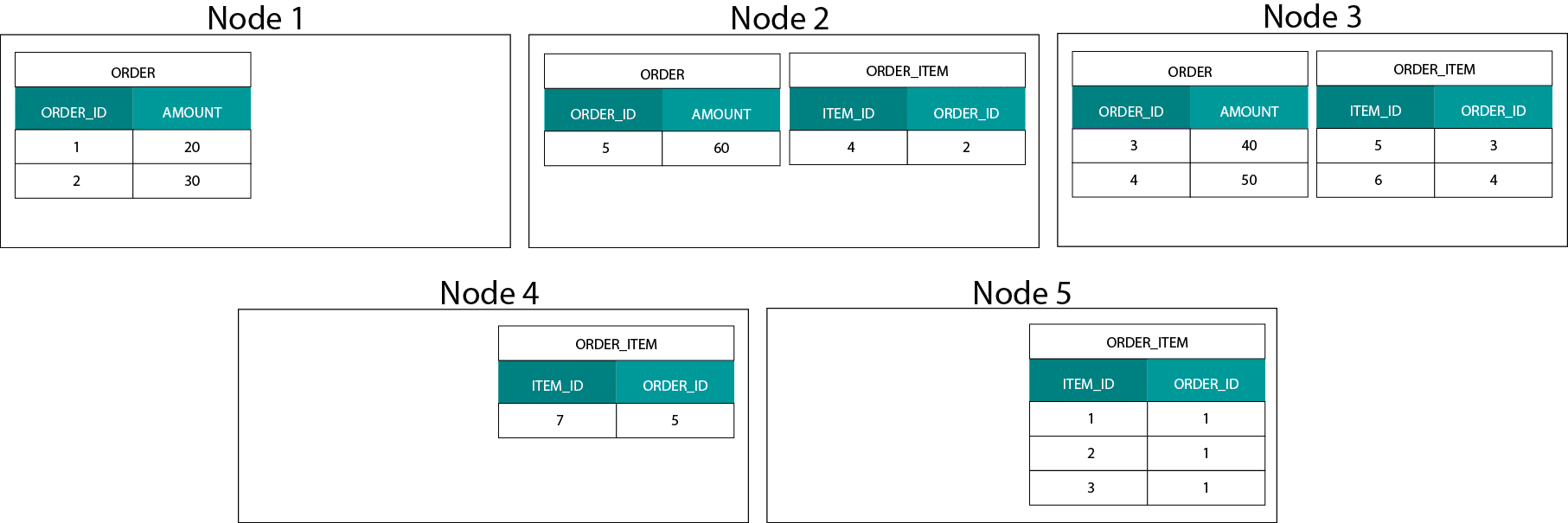
Para aderir, precisamos enviar dados através da rede, o que impacta o desempenho.
Uma estratégia de lidar com este problema é replicar uma das tabelas de adesão em todos os nós do cluster. Isto é chamado de broadcast join e nós usamos a mesma estratégia em um MPP. Como você pode imaginar, ele só funciona para tabelas de pequenas dimensões ou de busca.
> Então o que fazemos quando temos uma tabela de fatos grande e uma tabela de grandes dimensões, por exemplo, cliente ou produto? Ou de fato quando temos duas tabelas de grandes dimensões.
Modelos dimensionais no Hadoop
A fim de contornar este problema de desempenho, podemos desnormalizar tabelas de grandes dimensões em nossa tabela de fatos para garantir que os dados sejam co-localizados. Podemos transmitir as tabelas de dimensões menores através de todos os nossos nós.
Para unir duas tabelas de fatos grandes podemos aninhar a tabela com a menor granularidade dentro da tabela com a maior granularidade, por exemplo, uma tabela grande ORDER_ITEM aninhada dentro da tabela ORDER. Motores de consulta modernos como Impala ou Drill nos permitem aplanar estes dados

Esta estratégia de aninhar dados também é útil para dolorosos conceitos Kimball como tabelas de ponte para representar relações M:N em um modelo dimensional.
Hadoop e Dimensões de Mudança Lenta
Armazenamento no Sistema de Arquivos Hadoop é imutável. Em outras palavras, você só pode inserir e anexar registros. Você não pode modificar os dados. Se você está vindo de um fundo de armazenamento de dados relacional isto pode parecer um pouco estranho no início. No entanto, por baixo das bases de dados do hood funcionam de forma semelhante. Eles armazenam todas as alterações aos dados em um imutável log de escrita prévia (conhecido no Oracle como o log de refazer) antes de um processo atualizar os dados nos arquivos de dados de forma assíncrona.
Que impacto a imutabilidade tem sobre os nossos modelos dimensionais? Você pode se lembrar do conceito de Dimensões de Mudança Lenta (SCDs) do seu curso de modelagem dimensional. Opcionalmente, os SCDs preservam o histórico de alterações de atributos. Eles nos permitem relatar métricas em relação ao valor de um atributo em um determinado momento. Mas este não é o comportamento padrão. Por defeito actualizamos as tabelas de dimensões com os valores mais recentes. Então quais são as nossas opções no Hadoop? Lembre-se! Não podemos actualizar os dados. Podemos simplesmente fazer do SCD o comportamento padrão e auditar quaisquer alterações. Se quisermos executar relatórios contra os valores atuais, podemos criar uma View em cima do SCD que só recupera o valor mais recente. Isto pode ser feito facilmente usando as funções de janela. Alternativamente, podemos executar o chamado serviço de compactação que cria fisicamente uma versão separada da tabela de dimensões com apenas os últimos valores.
Solução de armazenamento no Hadoop
Estas limitações do Hadoop não passaram despercebidas pelos fornecedores das plataformas Hadoop. No Hadoop temos agora transacções ACID e tabelas actualizáveis. Com base no número de grandes questões em aberto e na minha própria experiência, esta funcionalidade parece ainda não estar pronta para produção, embora . A Cloudera adoptou uma abordagem diferente. Com o Kudu criaram um novo formato de armazenamento actualizável que não se encontra no HDFS mas sim no sistema de ficheiros do SO local. Ele se livra completamente das limitações do Hadoop e é similar à camada de armazenamento tradicional em um MPP colunar. Geralmente falando, é provavelmente melhor correr qualquer BI e dashboard num MPP, por exemplo, Impala + Kudu do que no Hadoop. Tendo dito que os MPPs têm limitações próprias quando se trata de resiliência, concomitância e escalabilidade. Quando você se depara com essas limitações, o Hadoop e seu primo próximo Spark são boas opções para cargas de trabalho de BI. Cobrimos todas estas limitações no nosso curso de formação Big Data for Data Warehouse Professionals e fazemos recomendações quando usar um RDBMS e quando usar SQL no Hadoop/Spark.
O veredicto. São modelos dimensionais e esquemas estelares obsoletos?
Todos nós sabemos que Ralph Kimball se aposentou. Mas as suas principais ideias e conceitos ainda são válidos e continuam vivos. Temos que adaptá-los para novas tecnologias e tipos de armazenamento, mas eles ainda acrescentam valor.
Diz-me Grandes Dados para Avançar na Minha Carreira
Leitura Complementar sobre Modelagem Dimensional na Era dos Grandes Dados
Tom Breur: O Passado e o Futuro da Modelagem Dimensional
Edosa Odaro: 5 Dicas Radicais para uma Integração Rápida de Grandes Dados – O Padrão de Anti Data Warehouse