Você está se perguntando o que são esquemas Postgresql e porque eles são importantes e como você pode usar esquemas para tornar suas implementações de banco de dados mais robustas e de fácil manutenção? Este artigo irá introduzir o básico de esquemas no Postgresql e mostrar-lhe como criá-los com alguns exemplos básicos. Artigos futuros irão mergulhar em exemplos de como assegurar e usar esquemas para aplicações reais.
Primeiro, para esclarecer uma potencial confusão terminológica, vamos entender que no mundo Postgresql, o termo “esquema” é talvez um pouco sobrecarregado, infelizmente. No contexto mais amplo dos sistemas de gestão de bases de dados relacionais (RDBMS), o termo “esquema” pode ser entendido como referindo-se ao desenho geral lógico ou físico da base de dados, ou seja, à definição de todas as tabelas, colunas, vistas e outros objectos que constituem a definição da base de dados. Nesse contexto mais amplo, um esquema pode ser expresso em um diagrama de entidade-relação (ER) ou um script de instruções de linguagem de definição de dados (DDL) usado para instanciar a base de dados da aplicação.
No mundo Postgresql, o termo “esquema” pode ser melhor entendido como um “namespace”. Na verdade, nas tabelas do sistema Postgresql, os esquemas são registrados em colunas de tabelas chamadas “namespace”, o que, IMHO, é uma terminologia mais precisa. Como uma questão prática, sempre que eu vejo “esquema” no contexto do Postgresql eu silenciosamente reinterpreto-o como dizendo “espaço de nomes”.
Mas você pode perguntar: “O que é um espaço de nomes? Geralmente, um espaço de nomes é um meio bastante flexível de organizar e identificar informações por nome. Por exemplo, imagine dois lares vizinhos, os Ferreiros, Alice e Bob, e os Jones, Bob e Cathy (cf. Figura 1). Se usássemos apenas os primeiros nomes, talvez ficasse confuso qual a pessoa a que nos referimos quando falamos de Bob. Mas ao adicionar o sobrenome, Smith ou Jones, identificamos de forma única qual pessoa nos referimos.
Oftentimes, os espaços de nomes são organizados em uma hierarquia aninhada. Isto permite a classificação eficiente de grandes quantidades de informação em estruturas de granulação muito fina, como, por exemplo, o sistema de nomes de domínio da Internet. No nível superior, “.com”, “.net”, “.org”, “.edu”, e etc. definem amplos espaços de nomes dentro dos quais são nomes registrados para entidades específicas, assim, por exemplo, “severalnines.com” e “postgresql.org” são definidos de forma única. Mas sob cada um destes existem vários sub-domínios comuns como “www”, “mail”, e “ftp”, por exemplo, que só por si são duplicados, mas dentro dos respectivos espaços de nomes são únicos.
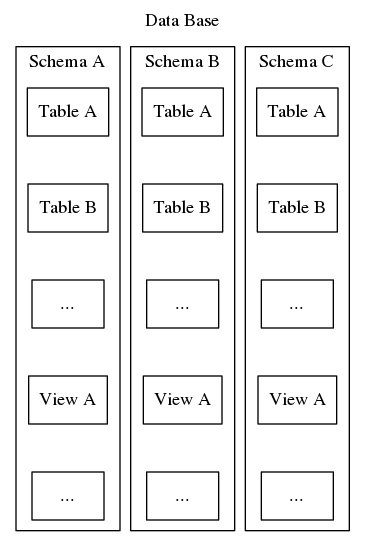
Esquemas Postgresql servem este mesmo propósito de organizar e identificar, no entanto, ao contrário do segundo exemplo acima, esquemas Postgresql não podem ser aninhados numa hierarquia. Enquanto um banco de dados pode conter muitos esquemas, existe apenas um nível e, portanto, dentro de um banco de dados, os nomes dos esquemas devem ser únicos. Além disso, cada banco de dados deve incluir pelo menos um esquema. Sempre que um novo banco de dados é instanciado, um esquema padrão chamado “público” é criado. O conteúdo de um esquema inclui todos os outros objetos do banco de dados, como tabelas, visões, procedimentos armazenados, acionadores, etc. Para visualizar, consulte a Figura 2, que mostra um ninho de bonecos matryoshka mostrando onde os esquemas se encaixam na estrutura de um banco de dados Postgresql.
Besides simplesmente organizando os objetos do banco de dados em grupos lógicos para torná-los mais gerenciáveis, os esquemas servem ao propósito prático de evitar a colisão de nomes. Um paradigma operacional envolve a definição de um esquema para cada usuário da base de dados de modo a proporcionar algum grau de isolamento, um espaço onde os usuários podem definir suas próprias tabelas e vistas sem interferir uns com os outros. Outra abordagem é instalar ferramentas de terceiros ou extensões de bases de dados em esquemas individuais de modo a manter todos os componentes relacionados logicamente juntos. Um artigo posterior nesta série irá detalhar uma nova abordagem ao design robusto de aplicações, empregando esquemas como meio de indireção para limitar a exposição do design físico da base de dados e, em vez disso, apresentar uma interface de usuário que resolve chaves sintéticas e facilita a manutenção e o gerenciamento de configuração a longo prazo à medida que os requisitos do sistema evoluem.
Vamos fazer algum código!
O comando mais simples para criar um esquema dentro de uma base de dados é
CREATE SCHEMA hollywood;Este comando requer privilégios de criação na base de dados, e o esquema recém-criado “hollywoodiano” será propriedade do usuário que invocar o comando. Uma invocação mais complexa pode incluir elementos opcionais especificando um dono diferente, e pode até incluir instruções DDL instanciando objetos de banco de dados dentro do esquema, tudo em um comando!
O formato geral é
CREATE SCHEMA schemaname ]onde “nome de usuário” é quem será o dono do esquema e “esquema_elemento” pode ser um de certos comandos DDL (consulte a documentação do Postgresql para obter informações específicas). Os privilégios de super usuário são necessários para usar a opção AUTHORIZATION.
Então, por exemplo, para criar um esquema chamado “hollywoodiano” contendo uma tabela chamada “filmes” e ver “vencedores” em um comando, você poderia fazer
CREATE SCHEMA hollywood CREATE TABLE films (title text, release date, awards text) CREATE VIEW winners AS SELECT title, release FROM films WHERE awards IS NOT NULL;Objetos adicionais da base de dados podem ser criados diretamente, por exemplo uma tabela adicional seria adicionada ao esquema com
CREATE TABLE hollywood.actors (name text, dob date, gender text);Nota no exemplo acima o prefixo do nome da tabela com o nome do esquema. Isto é necessário porque por padrão, ou seja, sem especificação explícita do esquema, novos objetos de banco de dados são criados dentro de qualquer esquema atual, que iremos cobrir a seguir.
Recall como no primeiro exemplo de espaço de nome acima, tínhamos duas pessoas chamadas Bob, e descrevemos como desconflitá-las ou distingui-las através da inclusão do sobrenome. Mas dentro de cada uma das famílias Smith e Jones separadamente, cada família entende “Bob” para se referir àquela que vai com aquela família em particular. Assim, por exemplo, no contexto de cada família respectiva, Alice não precisa se dirigir a seu marido como Bob Jones, e Cathy não precisa se referir a seu marido como Bob Smith: cada um deles pode apenas dizer “Bob”.
O esquema atual do Postgresql é como o da família no exemplo acima. Objetos no esquema atual podem ser referenciados sem qualificação, mas referindo-se a objetos com nomes semelhantes em outros esquemas requer a qualificação do nome, prefixando o nome do esquema como acima.
O esquema atual é derivado do parâmetro de configuração “search_path”. Esse parâmetro armazena uma lista separada por vírgulas de nomes de esquemas e pode ser examinado com o comando
SHOW search_path;ou definido para um novo valor com
SET search_path TO schema ;O primeiro nome de esquema na lista é o “esquema atual” e é onde novos objetos são criados se especificados sem a qualificação do nome do esquema.
A lista separada por vírgulas de nomes de esquemas também serve para determinar a ordem de pesquisa pela qual o sistema localiza os objetos nomeados não-qualificados existentes. Por exemplo, de volta ao bairro Smith e Jones, uma entrega de pacotes endereçada apenas ao “Bob” exigiria uma visita em cada casa até que o primeiro residente chamado “Bob” fosse encontrado. Note que este pode não ser o destinatário pretendido. A mesma lógica se aplica ao Postgresql. O sistema procura por tabelas, vistas e outros objetos dentro de esquemas na ordem do search_path, e então o primeiro objeto de correspondência de nome encontrado é usado. Objetos com nome qualificado para esquema são usados diretamente sem referência ao search_path.
Na configuração padrão, consultar a variável de configuração search_path revela este valor
SHOW search_path; Search_path-------------- "$user", publicO sistema interpreta o primeiro valor mostrado acima como o nome do usuário atualmente conectado e acomoda o caso de uso mencionado anteriormente, onde cada usuário recebe um esquema com nome de usuário para um espaço de trabalho separado de outros usuários. Se nenhum esquema com nome de usuário foi criado, essa entrada é ignorada e o esquema “público” torna-se o esquema atual onde novos objetos são criados.
Então, voltando ao nosso exemplo anterior de criação da tabela “hollywood.actors”, se não tivéssemos qualificado o nome da tabela com o nome do esquema, então a tabela teria sido criada no esquema público. Se antecipássemos a criação de todos os objectos dentro de um esquema específico, então poderia ser conveniente definir a variável search_path como
SET search_path TO hollywood,public;facilitando a abreviatura de digitar nomes não qualificados para criar ou aceder a objectos de base de dados.
Há também uma função de informação do sistema que retorna o esquema atual com uma consulta
select current_schema();Em caso de engordar a ortografia, o dono de um esquema pode alterar o nome, desde que o usuário também tenha privilégios de criação do banco de dados, com a opção
ALTER SCHEMA old_name RENAME TO new_name;E, por último, para excluir um esquema de um banco de dados, há um comando drop
DROP SCHEMA schema_name;O comando DROP falhará se o esquema contiver algum objeto, então eles devem ser apagados primeiro, ou você pode opcionalmente apagar recursivamente um esquema todo o seu conteúdo com a opção CASCADE
DROP SCHEMA schema_name CASCADE;Estas noções básicas irão ajudá-lo a entender os esquemas!