Introdução Este tutorial mostra como encontrar e, opcionalmente, excluir páginas semelhantes ou duplicadas dentro do mesmo documento PDF usando o plug-in AutoSplit™ para o Adobe® Acrobat®. Esta operação detecta páginas semelhantes e as apresenta ao usuário para uma revisão. O usuário pode rever os resultados e selecionar/desselecionar páginas individuais da lista de duplicatas para uma possível exclusão ou extração. O usuário pode realizar as seguintes operações:
- Localizar páginas duplicadas e quase-duplicadas
- Bookmark duplicate pages
- Extrair páginas duplicadas em um documento PDF separado
- Eliminar páginas duplicadas do documento
- Guardar relatório de similaridade de páginas
O plug-in fornece dois métodos diferentes para detectar páginas duplicadas ou quase-duplicadas: Comparar apenas o texto da página Use este método para comparar o texto da página, independentemente da sua aparência visual. Ele calcula a similaridade da página com base apenas no conteúdo do texto e ignora completamente a aparência do texto, layout, imagens e gráficos que possam estar presentes na página. É o melhor método para detectar duplicatas na maioria dos tipos de documentos. Compare a aparência visual das páginas Este método compara páginas “como imagens” e detecta páginas que parecem exatamente iguais. Este método não compara nenhum texto invisível que possa estar presente na página. Não é aconselhável usar este método em documentos digitalizados em papel. Uso de documentos em papel digitalizados Muitas vezes essa operação é usada para encontrar páginas duplicadas nos documentos em papel digitalizados. Os documentos digitalizados precisam ser OCR antes de usá-los para qualquer processamento baseado em texto. O OCR é um processo de reconhecimento de texto em documentos digitalizados e torna-os pesquisáveis. É essencial entender que o reconhecimento de texto em documentos digitalizados é propenso a erros e raramente é 100% preciso. O número de erros depende da resolução de digitalização e da qualidade do documento original. Na maioria dos casos comuns, uma página digitalizada pode conter entre 1 a 10 erros de reconhecimento onde certas letras são incorrectamente identificadas. Por exemplo, dependendo da fonte, a letra minúscula l pode se parecer exatamente com o numeral 1 . A letra maiúscula O é frequentemente mal identificada como o algarismo 0, ou a letra maiúscula S como o algarismo 5 e etc. Uma vez que muitos símbolos alfanuméricos partilham características físicas semelhantes ou idênticas, a diferenciação coloca muitas vezes um desafio. É por isso que uma comparação baseada na similaridade é útil para detectar pequenas diferenças entre páginas que são produzidas pelo processo de reconhecimento de texto. Documentos digitalizados de baixa qualidade podem conter um grande número de erros, tornando-os inutilizáveis para qualquer comparação baseada em texto confiável. Consulte o seguinte tutorial sobre como fazer OCR em documentos digitalizados e avalie sua adequação para o processamento baseado em texto. . Pré-requisitos Você precisa de uma cópia do Adobe® Acrobat® junto com o plug-in AutoSplit™ instalado no seu computador para usar este tutorial. Você pode baixar versões de teste do Adobe® Acrobat® e do plug-in AutoSplit™. Conteúdo
- Comparando Apenas o Texto da Página
- Comparar Apenas a Aparência Visual
- Comparando Vários Documentos
Método 1 – Comparando Apenas o Texto da Página Este método compara a semelhança da página apenas com base no conteúdo da página. A aparência visual, posição e ordem do texto é irrelevante. Este método também ignora quaisquer imagens e gráficos presentes nas páginas. A métrica de semelhança cosseno modificada é usada para calcular a semelhança entre duas páginas com base no seu conteúdo de texto. Passo 1 – Abrir um arquivo PDF Iniciar o aplicativo Adobe® Acrobat® e abrir um arquivo PDF usando o menu “Arquivo > Abrir…”..PNG) Passo 2 – Abra a caixa de diálogo “Encontrar páginas duplicadas” Seleccione “Plug-Ins > Dividir documentos > Encontrar e eliminar páginas duplicadas…” para abrir a caixa de diálogo “Encontrar páginas duplicadas”.
Passo 2 – Abra a caixa de diálogo “Encontrar páginas duplicadas” Seleccione “Plug-Ins > Dividir documentos > Encontrar e eliminar páginas duplicadas…” para abrir a caixa de diálogo “Encontrar páginas duplicadas”..PNG) Passo 3 – Especificar configurações Marque a opção “Comparar apenas texto da página (ignorar a aparência visual das páginas)”.
Passo 3 – Especificar configurações Marque a opção “Comparar apenas texto da página (ignorar a aparência visual das páginas)”..PNG) Usando Configurações Predefinidas O método baseado em texto fornece uma série de conjuntos de parâmetros predefinidos que são adequados para comparar diferentes tipos de documentos com uma quantidade diferente de erros de reconhecimento. Cada conjunto de parâmetros predefinidos fornece condições diferentes para cálculos de similaridade:
Usando Configurações Predefinidas O método baseado em texto fornece uma série de conjuntos de parâmetros predefinidos que são adequados para comparar diferentes tipos de documentos com uma quantidade diferente de erros de reconhecimento. Cada conjunto de parâmetros predefinidos fornece condições diferentes para cálculos de similaridade:
- Configurações Personalizadas – todas as definições são especificadas pelo utilizador
- Documento em Papel Digitalizado: Alta qualidade
- Documento de papel digitalizado: Qualidade média
- Documento de fax: Baixa Qualidade
- PDF não digitalizado: correspondência exacta
- PDF não digitalizado: correspondência fuzzy
- Casamento exacto (com ordem de texto)- este método não usa semelhança cosseno
.PNG) As definições aparecem abaixo do menu depois de seleccionar um conjunto de parâmetros predefinidos.
As definições aparecem abaixo do menu depois de seleccionar um conjunto de parâmetros predefinidos..PNG) Aqui estão as configurações usadas pelos conjuntos predefinidos:
Aqui estão as configurações usadas pelos conjuntos predefinidos:.PNG) Clique em “Editar…” para personalizar as definições de similaridade de página:
Clique em “Editar…” para personalizar as definições de similaridade de página:.PNG) O método de comparação de texto usa 3 parâmetros para limitar o quão diferentes podem ser duas páginas “semelhantes”. Ao variar estes parâmetros, é possível detectar páginas que têm um grau diferente de similaridade.
O método de comparação de texto usa 3 parâmetros para limitar o quão diferentes podem ser duas páginas “semelhantes”. Ao variar estes parâmetros, é possível detectar páginas que têm um grau diferente de similaridade.
- Mínima similaridade de texto de página permitida (em percentagem) – este é o valor da métrica de similaridade de cosseno expresso em percentagem. Especifique a similaridade mínima permitida de texto da página entre 70 e 100 (em porcentagem).
- Máxima diferença de comprimento de página permitida (em caracteres).
- Máxima diferença de texto da página permitida (em palavras).
Use estas configurações para experimentar as configurações de processamento quando for necessário ajustar o algoritmo de processamento para um documento específico..PNG) Use Páginas Amostra Opcionalmente, clique em “Set From Page Sample…” para especificar as configurações de semelhança de página com base nas duas páginas de amostra:
Use Páginas Amostra Opcionalmente, clique em “Set From Page Sample…” para especificar as configurações de semelhança de página com base nas duas páginas de amostra:.PNG) Seleccione duas páginas que possam ser consideradas idênticas. O software irá auto-calcular a semelhança de páginas e as estatísticas aparecerão no canto inferior esquerdo do diálogo. Clique em “OK” para salvar as configurações de similaridade atuais.
Seleccione duas páginas que possam ser consideradas idênticas. O software irá auto-calcular a semelhança de páginas e as estatísticas aparecerão no canto inferior esquerdo do diálogo. Clique em “OK” para salvar as configurações de similaridade atuais..PNG) Especificar Opções de Filtragem de Texto Existem vários parâmetros que controlam o conteúdo da página que está sendo analisado pelo algoritmo de comparação de texto. Use estas opções ao comparar documentos digitalizados em papel que podem conter vários erros de reconhecimento de texto. Essas opções excluem certos tipos de caracteres do processamento. Em muitos casos, isso pode ajudar a calcular uma métrica de similaridade mais precisa.
Especificar Opções de Filtragem de Texto Existem vários parâmetros que controlam o conteúdo da página que está sendo analisado pelo algoritmo de comparação de texto. Use estas opções ao comparar documentos digitalizados em papel que podem conter vários erros de reconhecimento de texto. Essas opções excluem certos tipos de caracteres do processamento. Em muitos casos, isso pode ajudar a calcular uma métrica de similaridade mais precisa.
- Ignorar caso de texto – esta opção ignora caso de texto ao comparar texto.
- Ignorar pontuação (,…!?-) – esta opção exclui todos os caracteres de pontuação da comparação.
- Ignorar caracteres não alfanuméricos – esta opção ignora todos os caracteres excepto letras e dígitos.
Clique em “OK” para guardar as definições de semelhança de página..PNG) Clique em “OK” para começar a procurar as páginas duplicadas no documento PDF atual:
Clique em “OK” para começar a procurar as páginas duplicadas no documento PDF atual:.PNG) Passo 4 – Inspeccionar páginas duplicadas O diálogo “Eliminar páginas duplicadas” mostra uma lista de páginas duplicadas ou quase duplicadas. Clique em um registro de página para exibir uma página correspondente no visualizador. Examine as páginas e selecione/desselecione as páginas para excluir. Opcionalmente, clique em “Salvar relatório…” para criar um relatório de similaridade de página em formato HTML. Ou clique em “Marcar páginas” para criar marcadores em PDF para páginas duplicadas selecionadas.
Passo 4 – Inspeccionar páginas duplicadas O diálogo “Eliminar páginas duplicadas” mostra uma lista de páginas duplicadas ou quase duplicadas. Clique em um registro de página para exibir uma página correspondente no visualizador. Examine as páginas e selecione/desselecione as páginas para excluir. Opcionalmente, clique em “Salvar relatório…” para criar um relatório de similaridade de página em formato HTML. Ou clique em “Marcar páginas” para criar marcadores em PDF para páginas duplicadas selecionadas..PNG) O plug-in permite pré-visualizar/comparar as páginas duplicadas ou quase-duplicadas encontradas. A semelhança da página (em %) e o número de palavras não correspondidas é exibida para cada par de páginas. Aqui estão os exemplos computados para o par dos documentos em papel digitalizados:
O plug-in permite pré-visualizar/comparar as páginas duplicadas ou quase-duplicadas encontradas. A semelhança da página (em %) e o número de palavras não correspondidas é exibida para cada par de páginas. Aqui estão os exemplos computados para o par dos documentos em papel digitalizados:.PNG)
.PNG) Note que a aparição e localização do texto não afectam os resultados. Estas duas páginas são consideradas idênticas apesar da diferença na cor do texto:
Note que a aparição e localização do texto não afectam os resultados. Estas duas páginas são consideradas idênticas apesar da diferença na cor do texto:.PNG) Estas duas páginas são consideradas idênticas apesar da diferença no layout do conteúdo:
Estas duas páginas são consideradas idênticas apesar da diferença no layout do conteúdo:
.PNG) Estas duas páginas são consideradas 94% semelhantes apesar da diferença na ordem do texto, layout e ausência da imagem:
Estas duas páginas são consideradas 94% semelhantes apesar da diferença na ordem do texto, layout e ausência da imagem:.PNG) Passo 5 – Extrair ou Adicionar aos Favoritos Páginas Duplicadas Opcionalmente, use o botão “Adicionar aos Favoritos” para adicionar aos favoritos todas as páginas verificadas. Isto é útil se você não está planejando excluir do documento as páginas duplicadas encontradas. Use as caixas de seleção na frente das páginas para selecioná-las/desselecioná-las do conjunto de processamento. Use o botão “Extract Pages….” para extrair todas as páginas marcadas em um documento PDF separado. Esta operação não removerá páginas do documento atual.
Passo 5 – Extrair ou Adicionar aos Favoritos Páginas Duplicadas Opcionalmente, use o botão “Adicionar aos Favoritos” para adicionar aos favoritos todas as páginas verificadas. Isto é útil se você não está planejando excluir do documento as páginas duplicadas encontradas. Use as caixas de seleção na frente das páginas para selecioná-las/desselecioná-las do conjunto de processamento. Use o botão “Extract Pages….” para extrair todas as páginas marcadas em um documento PDF separado. Esta operação não removerá páginas do documento atual..PNG) Use o botão “Save Report…” para salvar o relatório de cálculo de similaridade de páginas em um arquivo HTML. Ele contém detalhes de similaridade de páginas, mostra diferenças entre páginas e lista as palavras em falta. Pode ser muito útil para uma análise em profundidade.
Use o botão “Save Report…” para salvar o relatório de cálculo de similaridade de páginas em um arquivo HTML. Ele contém detalhes de similaridade de páginas, mostra diferenças entre páginas e lista as palavras em falta. Pode ser muito útil para uma análise em profundidade.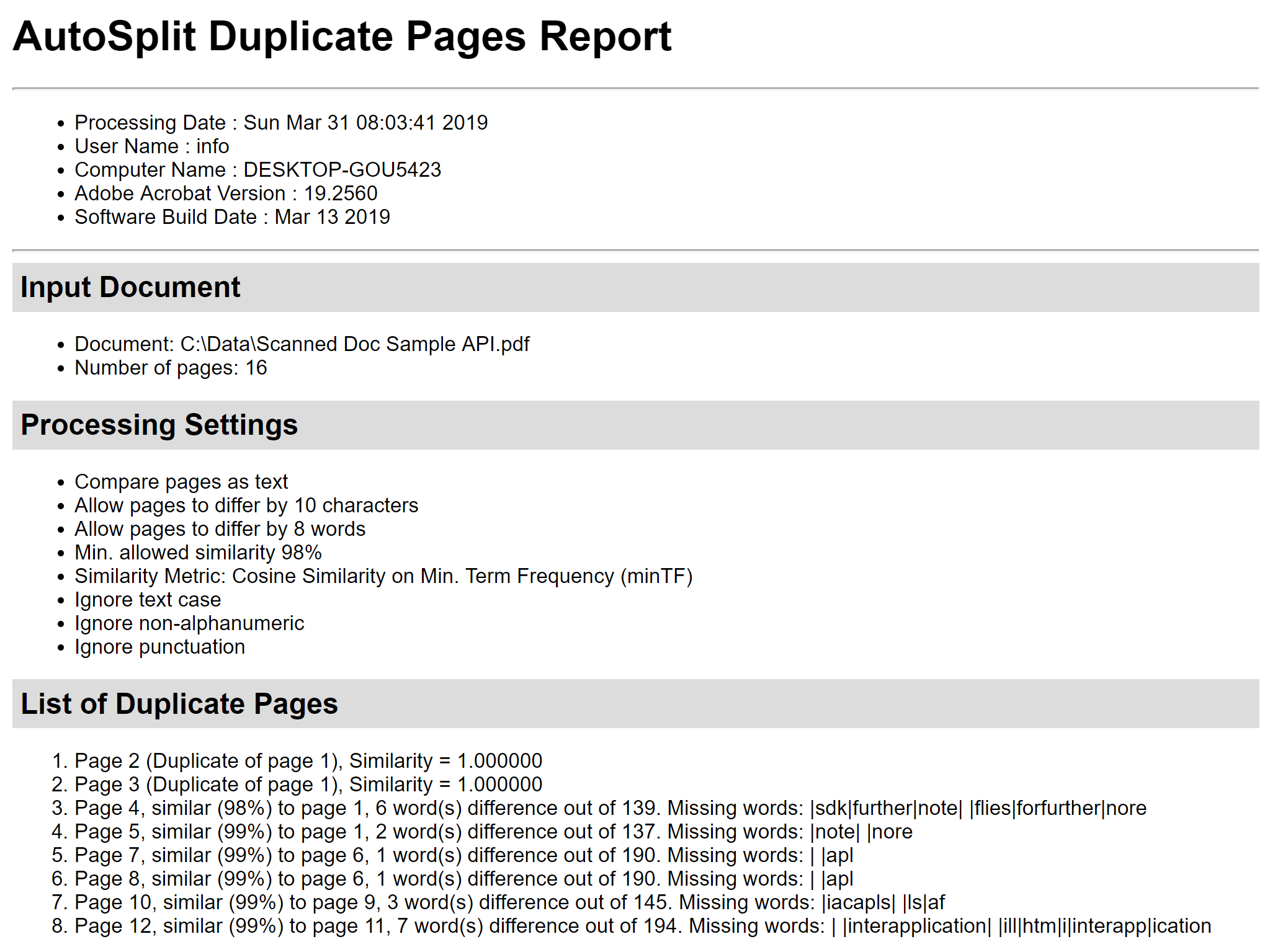 Passo 6 – Apagar páginas duplicadas Use caixas de seleção na frente das páginas para selecionar/anular a seleção de páginas a serem apagadas. Pressione o botão “Delete Pages” no diálogo “Delete Duplicate Pages” para remover todas as páginas marcadas do documento PDF atual:
Passo 6 – Apagar páginas duplicadas Use caixas de seleção na frente das páginas para selecionar/anular a seleção de páginas a serem apagadas. Pressione o botão “Delete Pages” no diálogo “Delete Duplicate Pages” para remover todas as páginas marcadas do documento PDF atual:.PNG) Clique no botão “OK” para confirmar. As páginas serão removidas permanentemente.
Clique no botão “OK” para confirmar. As páginas serão removidas permanentemente..PNG) Método 2 – Comparar apenas a aparência visual Este método compara páginas “como imagens” e detecta páginas que parecem exactamente iguais. Este método não compara nenhum texto invisível que possa estar presente na página. Não é aconselhável usar este método em documentos digitalizados em papel. Passo 1 – Abra um arquivo PDF Inicie o aplicativo Adobe® Acrobat® e abra um arquivo PDF usando o menu “Arquivo > Abrir…”.Passo 2 – Abra a caixa de diálogo “Encontrar páginas duplicadas” Seleccione “Plug-Ins > Dividir documentos > Encontrar e eliminar páginas duplicadas…” para abrir a caixa de diálogo “Encontrar páginas duplicadas”.Passo 3 – Especificar configurações Verifique a opção “Comparar aparência visual para correspondência exata (pode ser usada para comparar imagens)”.
Método 2 – Comparar apenas a aparência visual Este método compara páginas “como imagens” e detecta páginas que parecem exactamente iguais. Este método não compara nenhum texto invisível que possa estar presente na página. Não é aconselhável usar este método em documentos digitalizados em papel. Passo 1 – Abra um arquivo PDF Inicie o aplicativo Adobe® Acrobat® e abra um arquivo PDF usando o menu “Arquivo > Abrir…”.Passo 2 – Abra a caixa de diálogo “Encontrar páginas duplicadas” Seleccione “Plug-Ins > Dividir documentos > Encontrar e eliminar páginas duplicadas…” para abrir a caixa de diálogo “Encontrar páginas duplicadas”.Passo 3 – Especificar configurações Verifique a opção “Comparar aparência visual para correspondência exata (pode ser usada para comparar imagens)”..PNG) Clique em “OK” para iniciar a busca por páginas duplicadas. Passo 4 – Inspeccionar páginas duplicadas O diálogo “Eliminar páginas duplicadas” mostra uma lista de páginas duplicadas ou quase duplicadas. Clique em um registro de página para exibir a página correspondente na visualização lado a lado. Examine as páginas e seleccione/desmarque as páginas para uma possível eliminação.
Clique em “OK” para iniciar a busca por páginas duplicadas. Passo 4 – Inspeccionar páginas duplicadas O diálogo “Eliminar páginas duplicadas” mostra uma lista de páginas duplicadas ou quase duplicadas. Clique em um registro de página para exibir a página correspondente na visualização lado a lado. Examine as páginas e seleccione/desmarque as páginas para uma possível eliminação..PNG) Opcionalmente, clique em “Salvar relatório…” para criar um relatório de similaridade de página em formato HTML. Ou clique em “Marcar páginas” para criar marcadores em PDF para páginas duplicadas selecionadas. Este método é baseado em criar uma cópia menor (sampled) das páginas e compará-las “como imagens”. O exemplo seguinte mostra duas páginas idênticas que contêm apenas gráficos e nenhum texto pesquisável:
Opcionalmente, clique em “Salvar relatório…” para criar um relatório de similaridade de página em formato HTML. Ou clique em “Marcar páginas” para criar marcadores em PDF para páginas duplicadas selecionadas. Este método é baseado em criar uma cópia menor (sampled) das páginas e compará-las “como imagens”. O exemplo seguinte mostra duas páginas idênticas que contêm apenas gráficos e nenhum texto pesquisável:
.PNG) Se as páginas são visualmente idênticas, então o software as detecta como duplicatas:
Se as páginas são visualmente idênticas, então o software as detecta como duplicatas:.PNG) Estas duas páginas são consideradas diferentes devido ao carimbo “Aprovado” numa das páginas:
Estas duas páginas são consideradas diferentes devido ao carimbo “Aprovado” numa das páginas:.PNG) Estas duas páginas são consideradas idênticas por este método:
Estas duas páginas são consideradas idênticas por este método:.PNG) Ao contrário do método de comparação baseado em texto, se a cor ou estilo do texto for diferente, então as páginas não são consideradas idênticas:
Ao contrário do método de comparação baseado em texto, se a cor ou estilo do texto for diferente, então as páginas não são consideradas idênticas:.PNG) Passo 5 – Apagar Páginas Duplicadas Clique em “Apagar Páginas” no diálogo “Apagar Páginas Duplicadas” para prosseguir. Clique no botão “OK” para excluir páginas dos documentos PDF atuais. As páginas serão removidas permanentemente.Comparar vários documentos PDF Esta operação pode ser usada para encontrar e remover páginas duplicadas dos múltiplos documentos PDF. A abordagem é combinar um ou mais documentos em um único arquivo PDF e executar a operação “Encontrar e excluir páginas duplicadas” no arquivo resultante. Isto irá essencialmente produzir um único documento sem duplicatas. Opcionalmente, é possível extrair todas as páginas duplicadas detectadas em um documento PDF separado. Etapa 1 – Visão geral de vários documentos PDF Inicie o aplicativo Adobe® Acrobat® e selecione “Ferramentas” no menu. Selecione o ícone “Combinar arquivos” na lista Ferramentas.
Passo 5 – Apagar Páginas Duplicadas Clique em “Apagar Páginas” no diálogo “Apagar Páginas Duplicadas” para prosseguir. Clique no botão “OK” para excluir páginas dos documentos PDF atuais. As páginas serão removidas permanentemente.Comparar vários documentos PDF Esta operação pode ser usada para encontrar e remover páginas duplicadas dos múltiplos documentos PDF. A abordagem é combinar um ou mais documentos em um único arquivo PDF e executar a operação “Encontrar e excluir páginas duplicadas” no arquivo resultante. Isto irá essencialmente produzir um único documento sem duplicatas. Opcionalmente, é possível extrair todas as páginas duplicadas detectadas em um documento PDF separado. Etapa 1 – Visão geral de vários documentos PDF Inicie o aplicativo Adobe® Acrobat® e selecione “Ferramentas” no menu. Selecione o ícone “Combinar arquivos” na lista Ferramentas..PNG) Clique em “Adicionar arquivos…” no menu “Combinar arquivos” e selecione arquivos PDF para fundir para comparação.
Clique em “Adicionar arquivos…” no menu “Combinar arquivos” e selecione arquivos PDF para fundir para comparação..PNG) Clique no botão “Combinar” no menu para fundir os ficheiros PDF seleccionados.
Clique no botão “Combinar” no menu para fundir os ficheiros PDF seleccionados..PNG) Passo 2 – Encontrar Páginas Duplicadas O ficheiro PDF de saída combinada aparecerá no ecrã. Se não, abra o arquivo PDF combinado. Seleccione “Plug-Ins > Split Documents > Find and Delete Duplicate Pages…” para abrir o diálogo “Find Duplicate Pages”.Marque a opção “Comparar aparência visual para uma correspondência exata (pode ser usada para comparar imagens)”. Clique em “OK” para começar a procurar por páginas duplicadas.
Passo 2 – Encontrar Páginas Duplicadas O ficheiro PDF de saída combinada aparecerá no ecrã. Se não, abra o arquivo PDF combinado. Seleccione “Plug-Ins > Split Documents > Find and Delete Duplicate Pages…” para abrir o diálogo “Find Duplicate Pages”.Marque a opção “Comparar aparência visual para uma correspondência exata (pode ser usada para comparar imagens)”. Clique em “OK” para começar a procurar por páginas duplicadas..PNG) Passo 3 – Extrair Páginas Duplicadas O diálogo “Delete Duplicate Pages” mostrará uma lista de páginas duplicadas ou quase duplicadas. Clique em um registro de página para exibir uma página correspondente no visualizador. Examine as páginas e selecione/desselecione as páginas. Clique em “Extrair Páginas…” para extrair as páginas duplicadas selecionadas para um novo documento PDF.
Passo 3 – Extrair Páginas Duplicadas O diálogo “Delete Duplicate Pages” mostrará uma lista de páginas duplicadas ou quase duplicadas. Clique em um registro de página para exibir uma página correspondente no visualizador. Examine as páginas e selecione/desselecione as páginas. Clique em “Extrair Páginas…” para extrair as páginas duplicadas selecionadas para um novo documento PDF..PNG) Especifique uma pasta de saída e um nome de arquivo. Clique em “Salvar” uma vez feito.
Especifique uma pasta de saída e um nome de arquivo. Clique em “Salvar” uma vez feito..PNG) O diálogo aparecerá mostrando o número de páginas que foram extraídas em um documento separado. Agora você salvou todas as páginas duplicadas em um arquivo PDF separado antes de excluí-las. Você pode examinar estas páginas e usá-las mais tarde, se necessário. Clique em “OK” para fechar a caixa de diálogo.
O diálogo aparecerá mostrando o número de páginas que foram extraídas em um documento separado. Agora você salvou todas as páginas duplicadas em um arquivo PDF separado antes de excluí-las. Você pode examinar estas páginas e usá-las mais tarde, se necessário. Clique em “OK” para fechar a caixa de diálogo..png) Passo 4 – Apagar páginas duplicadas Clique em “Apagar páginas” na caixa de diálogo “Apagar páginas duplicadas” para prosseguir.
Passo 4 – Apagar páginas duplicadas Clique em “Apagar páginas” na caixa de diálogo “Apagar páginas duplicadas” para prosseguir..PNG) Clique em “OK” no diálogo para excluir as páginas duplicadas selecionadas do documento PDF atual.
Clique em “OK” no diálogo para excluir as páginas duplicadas selecionadas do documento PDF atual..PNG) As páginas duplicadas selecionadas seriam removidas permanentemente do documento PDF. Você precisaria usar o menu “Arquivo > Salvar” para salvar o documento modificado no disco. Clique aqui para uma lista de todos os tutoriais passo-a-passo disponíveis.
As páginas duplicadas selecionadas seriam removidas permanentemente do documento PDF. Você precisaria usar o menu “Arquivo > Salvar” para salvar o documento modificado no disco. Clique aqui para uma lista de todos os tutoriais passo-a-passo disponíveis.