Update 29-May-2018: この記事の目的は3つあります(1)データモデルが必ず必要であることを示す(人間か機械が行うか)(2)物理モデリングは論理モデリングと同じではないことを示す。 実際、それは非常に異なっており、基礎となる技術に依存します。 しかし、私たちは両方を必要としています。 (3) データモデリングにおける不変性の概念の影響を示す。
次元モデリングは死んだのか?
この質問への答えを出す前に、一歩下がって、まず次元データモデリングとは何かを見てみましょう。
なぜデータをモデル化する必要があるのでしょうか。
よくある誤解に反して、データモデルの唯一の目的は、物理データベースを設計するための ER 図として機能することではありません。 データ モデルは、企業におけるビジネス プロセスの複雑さを表現するものです。 データモデルは、重要なビジネスルールや概念を文書化し、重要な企業用語の標準化を支援します。 データモデルは、ビジネスプロセスに関する思考や曖昧さを明らかにし、明確化するのに役立ちます。 さらに、データモデルを利用して、他の利害関係者とコミュニケーションをとることもできます。 設計図がなければ、家や橋は建てられないでしょう。
なぜ次元モデルが必要なのか?
次元モデリングは、データをモデリングするための特別なアプローチである。 また、データマートやスタースキーマという言葉も、ディメンションモデルの同義語として使われています。 スタースキーマは、データ分析に最適化されています。 下のディメンションモデルを見てください。 非常に直感的に理解できます。 顧客、製品、または日付ごとに注文データをスライスして切り出し、メトリックを集約して比較することにより、注文ビジネス プロセスのパフォーマンスを測定する方法がすぐにわかります。
次元モデルに関する中核的な考えの 1 つは、取引ビジネス プロセスの最小レベルの粒度を定義することです。 データを切り刻み、掘り下げるとき、これはそれ以上掘り下げることができないリーフレベルです。 別の言い方をすると、スタースキーマの最小粒度は、ファクトとすべてのディメンションテーブルを集約なしで結合したものです。
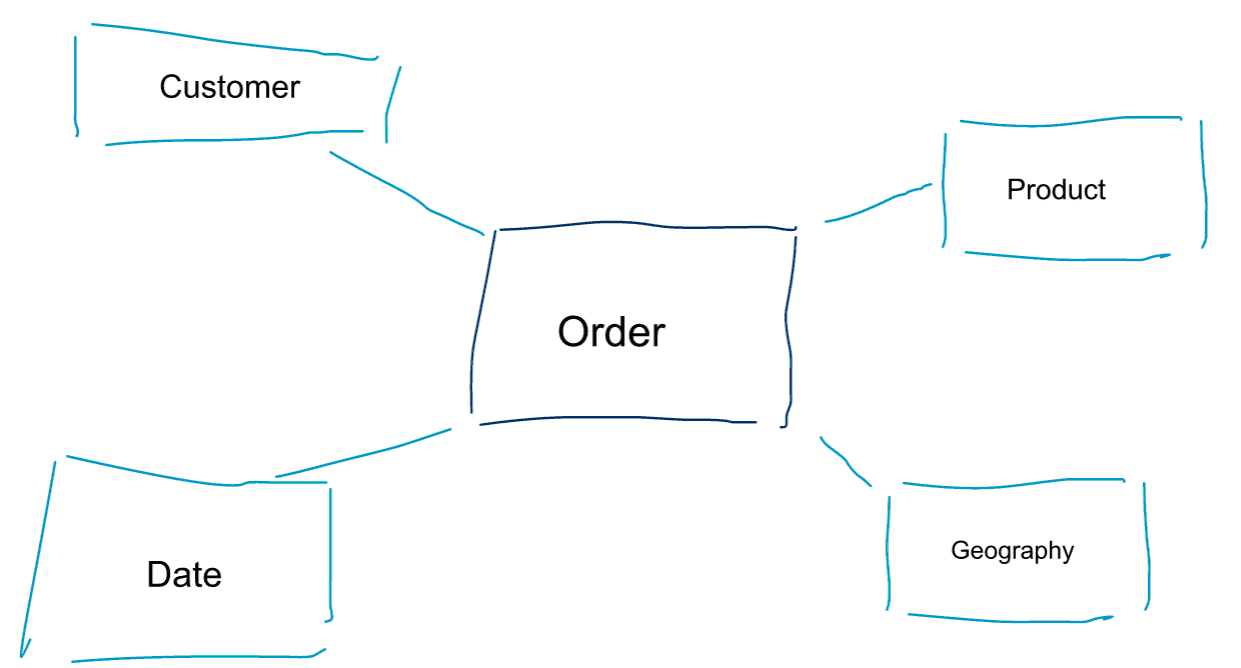
Data Modelling vs Dimensional Modelling
標準データモデリングでは、データの繰り返しと冗長性を排除することを目標としています。 データに変更があった場合、1か所だけ変更する必要があります。 これは、データ品質にも役立ちます。 値が複数の場所で同期されなくなることはありません。 下のモデルを見てください。 地理的な概念を表す様々なテーブルが含まれています。 正規化モデルでは、各エンティティに個別のテーブルがあります。 ディメンジョンモデルでは、geographyという1つのテーブルがあるだけです。 このテーブルでは、都市が複数回繰り返されます。 各都市に一度ずつです。 国名が変更されると、多くの場所で国を更新しなければなりません。
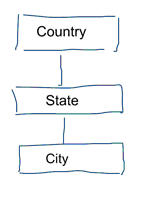
注意:標準データ モデリングは、3NF モデリングとも呼ばれます。 多くのテーブルがあるため、多くの結合が発生します。 結合は物事を遅くします。 データ分析では、可能な限りそれを回避します。 たとえば、前の例のさまざまなテーブルは、geographyという1つのテーブルに事前結合できます。
では、なぜ一部の人々は、ディメンションモデリングは死んだと主張するのでしょうか。
想像できるように、これにはさまざまな理由があります。
データウェアハウスは死んだという誤解
まず第一に、一部の人々はディメンションモデリングとデータウェアハウスを混同していることです。 彼らは、データウェアハウスは死んだと主張し、その結果、ディメンションモデリングも歴史のゴミ箱に追いやられることになります。 これは論理的に首尾一貫した主張です。 しかし、データウェアハウスのコンセプトは決して時代遅れではありません。 BIダッシュボードを作成するためには、統合された信頼性の高いデータが常に必要なのです。 もっと詳しく知りたい方は、当社のトレーニングコース「Big Data for Data Warehouse Professionals」をお勧めします。 このコースでは、データウェアハウスがこれまでと同様に重要であることを詳しく説明します。 また、新しいビッグ データ ツールや技術がデータ ウェアハウスにどのように役立つかを説明します。

The Schema on Read Misunderstanding
私がよく聞く2番目の議論は、次のようなものです。 「私たちはスキーマ オン リードのアプローチに従っているので、データをモデル化する必要はもうない」。 私の意見では、スキーマ オン リードの概念は、データ分析における最大の誤解の 1 つです。 私は、スキーマをあまり使わないデータ・ダンプに生データを保存することが有効であることに同意します。 しかし、この議論は、データを完全にモデル化しないという言い訳に使ってはいけません。 スキーマ・オン・リード・アプローチは、下流プロセスへの責任と缶を蹴落とすだけです。 誰かがデータ型を定義するという弾丸を食らわなければならないのだ。 スキーマフリーのデータダンプにアクセスする各プロセスは、何が起こっているのかを自分で把握する必要があります。 この種の作業は積み重なり、完全に冗長になり、データ型と適切なスキーマを定義することで簡単に回避することができます。 8515>
Dimensional モデルを時代遅れと宣言するための有効な議論が実際にあるのでしょうか。 私が上に挙げた 2 つよりも、もっと良い議論が実際にあります。 それには、物理データ モデリングと Hadoop の動作方法について、いくらか理解する必要があります。
先に、私たちがデータを次元的にモデル化する理由の 1 つについて簡単に触れました。 それは、データがデータ ストアに物理的に格納される方法と関連しています。 標準的なデータ モデリングでは、各実世界エンティティはそれ自身のテーブルを取得します。 これは、データの冗長性とデータ品質の問題がデータに忍び込むリスクを回避するためです。 テーブルが増えれば増えるほど、必要な結合も増える。 これが欠点である。 特にデータセットから大量のレコードを結合する場合、テーブル結合は高価になる。 データを次元的にモデル化する場合、複数のテーブルを1つに統合する。 これを「プレジョイン」あるいは「デノーマライズ」と呼んでいる。 LinkedInでこの投稿の議論に参加する
正規化解除の完全な結論
正規化解除を完全な結論にするのはどうだろうか。 すべての結合を削除し、単一のファクト・テーブルを持つだけでよいのです。 確かに、これによって結合は完全に不要になります。 しかし、ご想像のとおり、これにはいくつかの副作用があります。 まず第一に、必要なストレージの量が増えます。 冗長なデータを大量に保存する必要が出てきます。 データ分析用のカラムナー・ストレージフォーマットの出現により、最近ではこの懸念は少なくなっている。 正規化解除の大きな問題は、属性の1つの値が変わるたびに、複数の場所で値を更新しなければならないことです(おそらく数千から数百万回の更新)。 この問題を回避する一つの方法は、毎晩、モデルを完全にリロードすることです。 多くの場合、この方法は、大量の更新を行うよりもずっと速く、簡単です。 カラムナーデータベースは通常、次のようなアプローチを取ります。 Hadoop、たとえば Hive、SparkSQL などで次元モデルを作成する場合、Teradata などの分散リレーショナル データベース (MPP) と異なる、このテクノロジの 1 つの中核機能をよりよく理解する必要があります。 MPPのノードにデータを分散させる場合、レコードの配置を制御することができます。 ハッシュ、リスト、レンジなどのパーティショニング戦略に基づいて、個々のレコードのキーを同一ノード上のタブに配置することができるのです。 データのコロシティーが保証されているため、ネットワーク上にデータを送信する必要がなく、結合は超高速になります。 以下の例を見てください。 ORDER テーブルと ORDER_ITEM テーブルの同じ ORDER_ID を持つレコードは、同じノード上にあります。
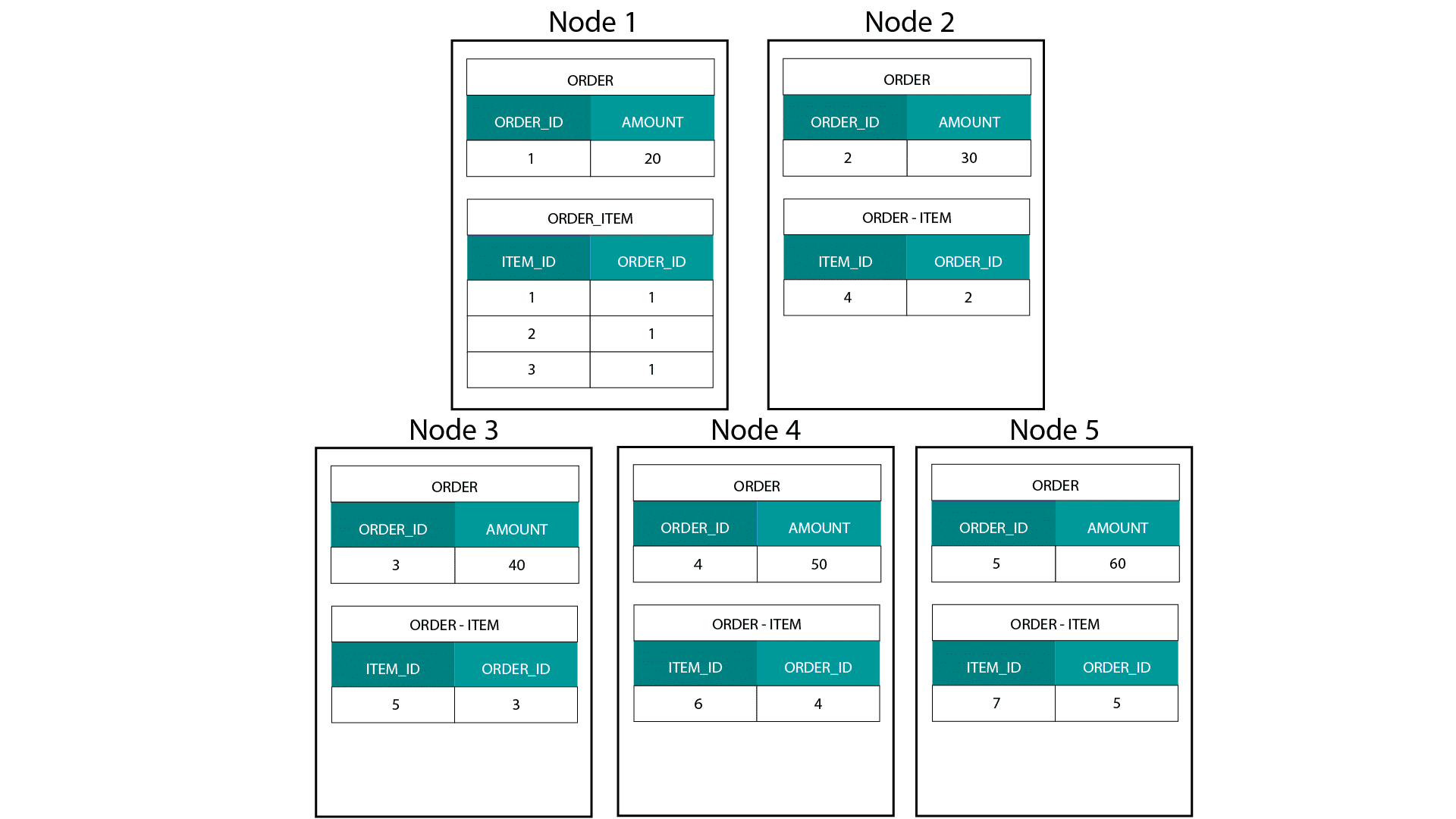
order および order_item テーブルの order_id のキーは同じノードに配置されます。 Hadoop では、データを大きなチャンクに分割し、Hadoop 分散ファイル システム (HDFS) 上のノードに分散して複製します。 このようなデータ分散戦略では、データの定位は保証されません。 以下の例を見てください。 ORDER_ID キーのレコードは異なるノードにあります。
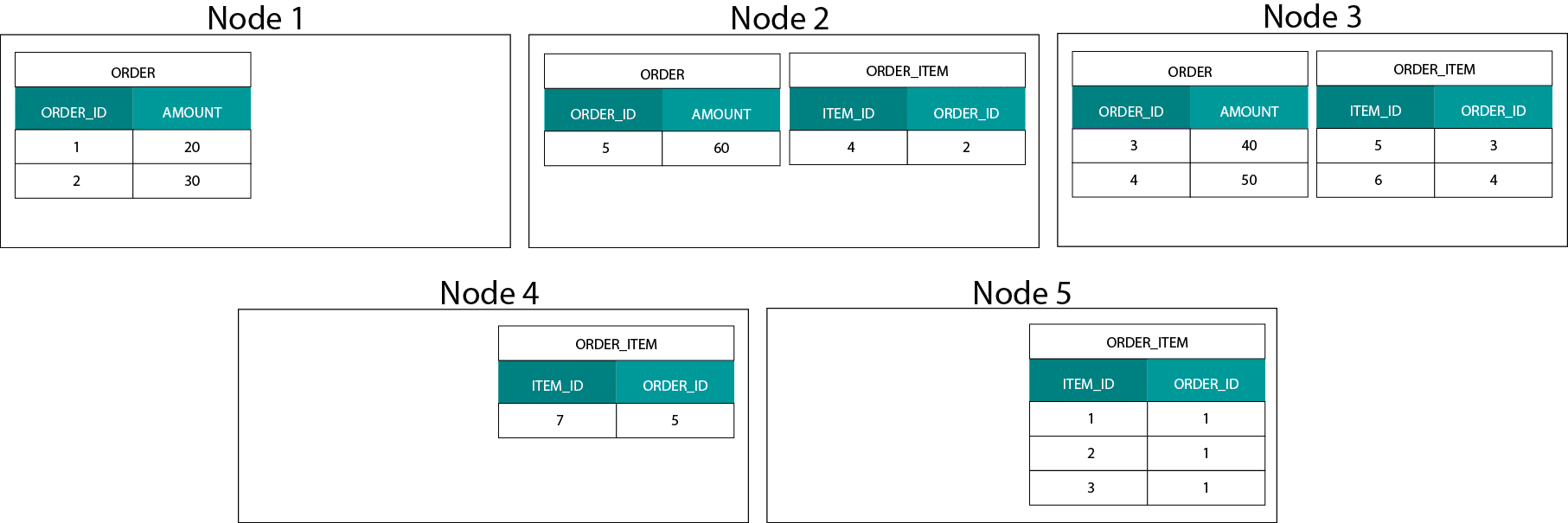
結合するには、データをネットワーク経由で送信する必要があり、パフォーマンスに影響を与えます。 これはブロードキャストジョインと呼ばれ、MPPで同じ戦略を使用します。
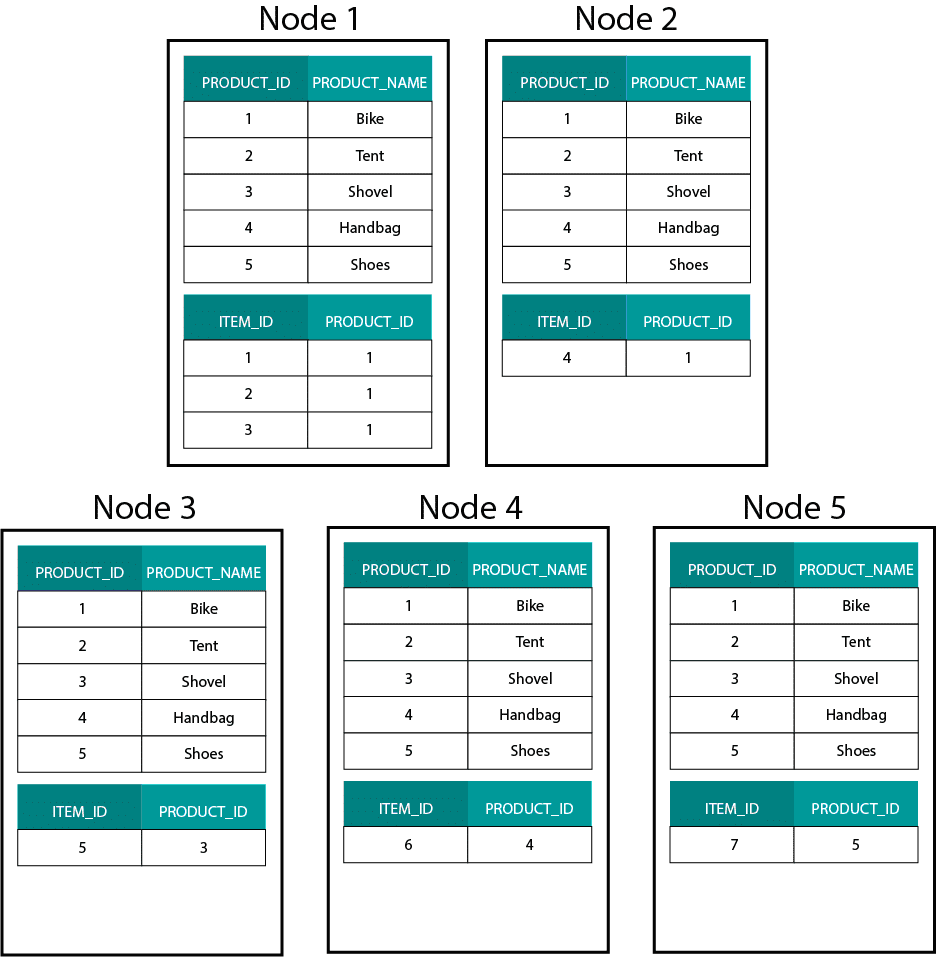
では、たとえば顧客や製品など、大きなファクト テーブルと大きなディメンション テーブルがある場合はどうすればよいのでしょうか。 4651>
Dimensional Models on Hadoop
このパフォーマンスの問題を回避するには、データが同じ場所にあることを保証するために、大きなディメンション テーブルをファクト テーブルに正規化しないようにすることが可能です。 たとえば、大きな ORDER_ITEM テーブルを ORDER テーブルの中に入れ子にすることができます。 Impala や Drill などの最新のクエリ エンジンでは、このデータを平坦化することができます。 言い換えれば、レコードの挿入と追加のみが可能です。 データを変更することはできません。 リレーショナル データ ウェアハウスのバックグラウンドから来た場合、これは最初は少し奇妙に思えるかもしれません。 しかし、データベースの内部では、同じような仕組みで動いています。 プロセスによってデータ ファイル内のデータが非同期に更新される前に、データに対するすべての変更を不変の書き込みログ (Oracle では redo ログとして知られている) に保存します。 ディメンジョン モデリング コースで学んだ Slowly Changing Dimensions (SCD) の概念を覚えているかもしれません。 SCDはオプションで属性への変更の履歴を保持します。 これにより、ある時点の属性の値に対するメトリクスをレポートすることができます。 しかし、これはデフォルトの動作ではありません。 デフォルトでは、ディメンジョン・テーブルは最新の値で更新されます。 では、Hadoopではどのようなオプションがあるのでしょうか。 覚えておいてください。 データを更新することはできません。 SCDをデフォルトの動作にして、変更を監査すればよいのです。 現在の値に対してレポートを実行したい場合は、SCDの上に最新の値のみを取得するViewを作成することができます。 これは、ウィンドウ機能を使って簡単に行うことができます。 また、最新の値だけを含むディメンション テーブルの別バージョンを物理的に作成する、いわゆるコンパクション サービスを実行することもできます。 Hive では、ACID トランザクションと更新可能なテーブルがあります。 未解決の大きな問題の数と私自身の経験に基づいて、この機能はまだ実運用には適していないようですが。 Clouderaは異なるアプローチを採用している。 Kuduでは、HDFSではなく、ローカルのOSファイルシステム上に置く、更新可能な新しいストレージ形式を作成した。 これはHadoopの制限を完全に取り払い、カラムナーMPPの従来のストレージレイヤーに似ている。 一般的には、BIやダッシュボードのユースケースは、HadoopよりもImpala + KuduなどのMPPで実行した方が良いと思われる。 とはいえ、MPPにはレジリエンス、並行処理、スケーラビリティの面で限界があります。 これらの制限に直面した場合、BIワークロードにはHadoopとその近縁のSparkが良い選択肢となる。 私たちは、トレーニング コース「Big Data for Data Warehouse Professionals」でこれらの制限をすべて取り上げ、RDBMS を使用する場合と Hadoop/Spark で SQL を使用する場合の推奨事項を示しています。 ディメンジョンモデルとスタースキーマは時代遅れか?
Ralph Kimball氏が引退したことは皆知っています。 しかし、彼の原則的なアイデアやコンセプトはまだ有効であり、生き続けています。 4651>
キャリアアップのためにビッグデータを教えてください
ビッグデータ時代の次元モデリングに関する補足資料
Tom Breur.S.A.S.S.S.S.S.S.S.S.S.S.S.S.S……………-(英語 次元モデリングの過去と未来
エドサ・オダロ:ビッグデータ統合をスピーディに行うための5つの抜本的ヒント-アンチデータウェアハウス・パターン
。