What is Cross-Sectional Data Analysis?
横断的データ分析とは、ある時点のデータセットを分析することを指します。 調査や政府の記録は、横断的なデータの一般的なソースです。 このデータセットには、特定の時点における複数の変数の観測結果が記録されています。 財務アナリスト財務アナリストの役割は、例えば、特定の時点における2つの企業の財務状況を比較したい場合があります。 そのためには、2社の貸借対照表を比較することになる。貸借対照表は、3つの基本的な財務諸表のうちの1つである。 貸借対照表は、3つの基本的な財務諸表のうちの1つであり、財務モデリングと会計の両面で重要な役割を果たす。 以下は、アマゾンとアップルの年度末の連結貸借対照表である。 アナリストはこれを使って、彼らの2018年の財務状況を見ることができます。 しかし、報告期間の終了日がわずかに異なるため、いくつかの調整を行う必要があるかもしれません。

CFI’s Advanced Financial Modeling & Valuation Courseには、Amazonに関する幅広いケーススタディが含まれています。
クロスセクションデータセットの例:
- Gross Domestic Product (GDP)Gross Domestic Product (GDP)は、国の経済的健全性の標準指標であり、生活水準を示す指標でもあります。 また、GDPは異なる国間の生産性のレベルを比較するために使用することができます。 2012年の北米諸国の – 分析の経済単位は、北アメリカの国である。 経済分析単位は2012年です。 データセットからの典型的なエントリは、(アメリカ合衆国、16.16兆ドル)です。
- 2010年のヨーロッパ諸国の一人当たりGDP – 分析の経済単位は、ヨーロッパの国である。 分析単位は2010年です。 データセットからの典型的なエントリは、(ドイツ、41,700ドル)です。
- 2015年のアジア諸国による鉄鋼輸出総額 – 分析の経済単位は、アジアの国である。 分析単位は、2015年の期間です。 データセットからの典型的なエントリは、(インド、31.7億ドル)です。
- 2018年にガーナの世帯が食べたオレンジの合計 – 分析の経済単位は、ガーナの世帯である。 分析経済単位は、期間2018年のものです。 データセットからの典型的なエントリは、(世帯302、200オレンジ)です。
Uses of Cross-Sectional Data
Cross-sectional datasets are extensively used in economics and other social sciences.経済学や他の社会科学で広く使用されています。 応用ミクロ経済学では、労働市場の分析にクロスセクショナル・データセットを使用します。労働市場とは、雇用の需要と供給が出会う場所であり、労働者や労働力は雇用者、公共金融、産業組織論、医療経済学などが提供するサービスを提供するものです。 政治学者は、クロスセクショナルデータを用いて、人口動態や選挙キャンペーンを分析する。 財務アナリストは、通常、財務諸表を比較する3つの財務諸表3つの財務諸表は、損益計算書、貸借対照表、キャッシュフロー計算書です。 この3つの中心的な財務諸表は2つの会社のもので、クロスセクション分析とは、同じ時点の2つの会社の財務諸表を比較することである。 時系列データ分析と対比させる時系列データ分析時系列データ分析とは、一定期間ごとに変化するデータセットを分析することである。 時系列データセットには、様々な時点における同じ変数の観測結果が記録されています。 金融アナリストは、株価の動きや企業の売上高などの時系列データを使用し、複数の期間にわたって同じ企業の財務諸表を比較することになります。
Sources of Cross-Sectional Data
- Bureau of Labor Statistics
- Census data
- Population surveys
- Panel Study of Income Dynamics
- US Bureau of Economic Analysis
- CompuStat
- Bank for International Settlements (BIS)Bank for International Settlements (BIS)BIS は1930年に始まり、各国の中央銀行により所有されています。 加盟する中央銀行の銀行として、国際通貨、金融の安定、金融公社を育成することを役割としている。 国際決済銀行は、
Federal ReserveFederal Reserve (The Fed) は、米国の中央銀行で世界最大の自由市場経済の金融機関であり、米国内の金融機関の中で最も権威があります。
Random Sampling
Random Sampling frameworkは、データ分析で広く使用されている統計的枠組みである。 ランダムサンプリング法は、母集団とその母集団から採取したサンプルとの間に密接な関係が存在するという仮定のもとに機能します。
上述したガーナの世帯によるオレンジ消費の例について考えてみましょう。 ガーナのすべての世帯の実際のオレンジの消費を測定するには、多くの資源(時間とお金の両方)が必要です。 ガーナの1,000世帯のオレンジ消費量だけを測定する方が、はるかに安上がりでしょう。 このような場合,母集団はガーナのすべての世帯からなり,標本はオレンジの消費データがわかっている1,000世帯からなる.
横断的データセットの計量分析は通常,データが独立して生成され,観測値が相互に独立していることを仮定する. このような独立データの仮定は、分析の経済単位が人口に比して大きい場合、破られる。 この場合、母集団は23カ国で構成される。 母集団から構築するどのようなサンプルも、相互に独立したランダムなサンプルの構築をサポートできない可能性があります。 例えば、アメリカのGDPがカナダのGDPと相関している可能性は極めて高い。
Random Sample in Cross-Sectional Data Analysis
時間tにN個の異なる経済主体のK個の特性を測定する横断的データセットについて考えてみよう。 クロスセクションデータセットにおける個々の観測は,次のような形式である:
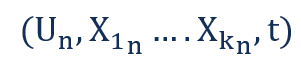
Where:
- Un is the nth economic unit of analysis
- X1n is the ith characteristic for the nth economic unit
- t is the time
crosssectional dataset was created using a random sample drawn from the population (F, X, t), where F is the joint distribution of all (U, X) in the population at time t.クロスセクションデータセットは、Fの集団から抽出されたランダムサンプルを使用して作成されました。
Additional Resources
CFI は、財務モデリング & 評価アナリスト (FMVA)™FMVA® CertificationAmazon、JP Morgan、Ferrari  などの企業で働く 850,000 以上の学生の一員となって、次のレベルへのキャリアを目指す人向けの認定プログラムを行っています。 また、「My Favorite Enemies」「My Favorite Enemies」「My Favorite Enemies」「My Favorite Enemies」「My Favorite Enemies」「My Favorite Enemies」「My Favorite Enemies」「My Favorite Enemies」「My Favorite Enemies」「My Favorite Enemies」「My Favorite Enemies」「My Favorite Enemies」は、それぞれ、「My Favorite Enemies」「My Favorite Enemies」と「My Favorite Enemies」の略称です。 さらに、統計学の概念は、投資家が
などの企業で働く 850,000 以上の学生の一員となって、次のレベルへのキャリアを目指す人向けの認定プログラムを行っています。 また、「My Favorite Enemies」「My Favorite Enemies」「My Favorite Enemies」「My Favorite Enemies」「My Favorite Enemies」「My Favorite Enemies」「My Favorite Enemies」「My Favorite Enemies」「My Favorite Enemies」「My Favorite Enemies」「My Favorite Enemies」「My Favorite Enemies」は、それぞれ、「My Favorite Enemies」「My Favorite Enemies」と「My Favorite Enemies」の略称です。 さらに、統計学の概念は、投資家が
感度分析は、独立変数のセットのための異なる値が従属変数にどのように影響するかを分析するために、金融モデリングで使用されるツールです。