はじめに このチュートリアルでは、Adobe® Acrobat® 用 AutoSplit™ プラグインを使って、同じ PDF 文書内の類似または重複したページを検索して削除する方法について説明します。 この操作では、類似したページが検出され、ユーザーに表示され、確認することができます。 ユーザーは結果を確認し、重複しているページのリストから個々のページを選択/解除して、削除や抽出の可能性を検討することができます。 以下の操作が可能です。
- 重複および重複に近いページを検出する
- 重複ページをブックマークする
- 重複ページを別の PDF 文書に抽出する
- 文書から重複ページを削除する
- ページの類似性レポートを保存する
このプラグインには重複または重複に近いページを検出する 2 つの異なる方法が用意されています。 ページテキストのみを比較する 見た目に関係なく、ページテキストを比較するためにこの方法を使用します。 これは、テキストの内容のみに基づいてページの類似性を計算し、ページに存在する可能性のあるテキストの外観、レイアウト、画像、およびグラフィックを完全に無視します。 ほとんどの種類の文書で重複を検出するのに最適な方法です。 ページの外観を比較する この方法は、ページを「画像として」比較し、まったく同じに見えるページを検出します。 この方法では、ページ上に存在する可能性のある不可視のテキストは比較されません。 スキャンした紙文書にこの方法を使用することはお勧めしません。 スキャンした紙文書の使用 スキャンした紙文書の中から重複するページを見つけるために、この操作を行うことがよくあります。 スキャンした文書は、テキストベースの処理に使用する前に、OCR処理する必要があります。 OCRは、スキャンされた文書内のテキストを認識し、検索可能にするプロセスです。 スキャンした文書のテキスト認識にはエラーが発生しやすく、100%正確であることは稀であることを理解することが重要です。 エラーの数は、スキャン解像度とオリジナル文書の品質に依存します。 多くの場合、スキャンしたページには1~10個の認識エラーがあり、特定の文字が誤って認識されることがあります。 例えば、フォントによっては、小文字のlが数字の1と全く同じに見えることがあります。 また、大文字のOを数字の0、大文字のSを数字の5などと誤認識することがよくあります。 多くの英数字は、物理的な特徴が似ているか、同じであるため、識別が困難な場合が多い。 このため、類似性に基づく比較は、テキスト認識プロセスで生成されるページ間の小さな違いを検出するのに有効である。 低品質のスキャン ドキュメントには多くのエラーが含まれている可能性があり、信頼できるテキスト ベースの比較には使用できません。 スキャンした文書をOCRし、テキストベースの処理への適合性を評価する方法については、次のチュートリアルを参照してください。 . 前提条件 このチュートリアルを使用するには、Adobe® Acrobat®のコピーとAutoSplit™プラグインがコンピュータにインストールされている必要があります。 Adobe® Acrobat®とAutoSplit™プラグインの体験版は、こちらからダウンロードできます。 目次
- ページテキストのみを比較する
- ビジュアルアピアランスのみを比較する
- 複数ドキュメントを比較する
方法1 – ページテキストのみを比較する 概要 この方法は、ページの内容に基づいてページの類似性のみを比較する方法です。 視覚的な外観、テキストの位置や順序は関係ありません。 また、この方法では、ページ上に存在する画像やグラフィックは無視されます。 テキストコンテンツに基づいた2つのページの類似度を計算するために、修正コサイン類似度メトリックが使用されます。 手順1 – PDFファイルを開く Adobe® Acrobat® アプリケーションを起動し、「ファイル > 開く…」メニューを使用してPDFファイルを開きます。.PNG) ステップ2 – 「重複ページの検索」ダイアログを開く プラグイン > 文書の分割 > 重複ページの検索と削除…」を選択し、「重複ページの検索」ダイアログを開きます。
ステップ2 – 「重複ページの検索」ダイアログを開く プラグイン > 文書の分割 > 重複ページの検索と削除…」を選択し、「重複ページの検索」ダイアログを開きます。.PNG) ステップ3 – 設定の指定 「ページのテキストだけを比較する(ページの外観を無視する)」にチェックを入れます。
ステップ3 – 設定の指定 「ページのテキストだけを比較する(ページの外観を無視する)」にチェックを入れます。.PNG) 定義済み設定の使用 テキストベース方式では、認識エラーの量が異なるさまざまな種類のドキュメントを比較するのに適した、定義済みパラメータセットが多数用意されています。 それぞれの事前定義されたパラメーターセットは、類似度計算のための異なる条件を提供します。
定義済み設定の使用 テキストベース方式では、認識エラーの量が異なるさまざまな種類のドキュメントを比較するのに適した、定義済みパラメータセットが多数用意されています。 それぞれの事前定義されたパラメーターセットは、類似度計算のための異なる条件を提供します。
- カスタム設定 – すべての設定はユーザーによって指定されます
- スキャンされたペーパードキュメント。 High Quality
- Scanned Paper Document: Medium Quality
- Fax Document: Low Quality
- Non-scanned PDF: Exact match
- Non-scanned PDF: fuzzy match
- Exact match (with text order)- this method does not use cosine similarity
.PNG) Settings are appears below the menu after selecting a predefined parameter set.
Settings are appears below the menu after selecting a predefined parameter set..PNG) ここでは、定義済みセットで使用される設定について説明します。
ここでは、定義済みセットで使用される設定について説明します。.PNG) “Edit… “をクリックすると、ページの類似度設定をカスタマイズできます。
“Edit… “をクリックすると、ページの類似度設定をカスタマイズできます。.PNG) テキスト比較方式では、3つのパラメーターを使って2つの「類似」したページの違いを制限します。 これらのパラメータを変化させることで、異なる類似度を持つページを検出することができます。
テキスト比較方式では、3つのパラメーターを使って2つの「類似」したページの違いを制限します。 これらのパラメータを変化させることで、異なる類似度を持つページを検出することができます。
- Minimal allowed page text similarity (in percent) – cosine similarity metric の値をパーセントで表示したものです。
- 最大許容ページ長差(文字単位)
- 最大許容ページテキスト差(単語単位)
特定のドキュメント用に処理アルゴリズムを調整する必要がある場合に、これらの設定を使用して処理設定を実験します。.PNG) サンプルページを使用する オプションで「ページサンプルから設定…」をクリックすると、2つのサンプルページを元にページの類似度設定を指定できます。
サンプルページを使用する オプションで「ページサンプルから設定…」をクリックすると、2つのサンプルページを元にページの類似度設定を指定できます。.PNG) 同一と見なせるページを2つ選択します。 ソフトウェアがページの類似度を自動計算し、ダイアログの左下に統計値が表示されます。 OK」をクリックすると、現在の類似度設定が保存されます。
同一と見なせるページを2つ選択します。 ソフトウェアがページの類似度を自動計算し、ダイアログの左下に統計値が表示されます。 OK」をクリックすると、現在の類似度設定が保存されます。.PNG) テキストフィルタリングオプションの指定 テキスト比較アルゴリズムによって分析されるページ内容を制御するいくつかのパラメータがあります。 さまざまなテキスト認識エラーを含む可能性のあるスキャンされた紙文書を比較するときに、これらのオプションを使用します。 これらのオプションは、特定の種類の文字を処理から除外します。 多くの場合、より正確な類似性メトリックを計算するのに役立つことがあります。
テキストフィルタリングオプションの指定 テキスト比較アルゴリズムによって分析されるページ内容を制御するいくつかのパラメータがあります。 さまざまなテキスト認識エラーを含む可能性のあるスキャンされた紙文書を比較するときに、これらのオプションを使用します。 これらのオプションは、特定の種類の文字を処理から除外します。 多くの場合、より正確な類似性メトリックを計算するのに役立つことがあります。
- Ignore text case – このオプションは、テキストの比較時にテキストの大文字/小文字を無視します。
- Ignore punctuation (,.!?-) – このオプションは比較からすべての区切り文字を除外します。
- Ignore non-alphanumeric characters – このオプションは文字と数字以外のすべての文字を無視します。
ページ類似度設定を保存するには [OK] をクリックしてください。.PNG) [OK]をクリックして、現在のPDF文書から重複するページの検索を開始します。
[OK]をクリックして、現在のPDF文書から重複するページの検索を開始します。.PNG) ステップ4 – 重複したページを検査する “Delete Duplicate Pages” ダイアログは、重複したページまたは重複に近いページのリストを表示します。 ページレコードをクリックすると、対応するページがビューア内に表示されます。 ページを確認し、削除するページを選択/解除します。 オプションで「レポートを保存…」をクリックすると、HTML形式のページ類似性レポートが作成されます。 また、「ページをブックマーク」をクリックすると、選択した重複ページに対してPDFでブックマークが作成されます。
ステップ4 – 重複したページを検査する “Delete Duplicate Pages” ダイアログは、重複したページまたは重複に近いページのリストを表示します。 ページレコードをクリックすると、対応するページがビューア内に表示されます。 ページを確認し、削除するページを選択/解除します。 オプションで「レポートを保存…」をクリックすると、HTML形式のページ類似性レポートが作成されます。 また、「ページをブックマーク」をクリックすると、選択した重複ページに対してPDFでブックマークが作成されます。.PNG) このプラグインは、見つかった重複ページや重複に近いページをプレビュー/比較することができます。 ページの類似度(%)と不一致の単語数が、ページのペアごとに表示されます。 以下は、スキャンした紙文書のペアに対して計算された例です。
このプラグインは、見つかった重複ページや重複に近いページをプレビュー/比較することができます。 ページの類似度(%)と不一致の単語数が、ページのペアごとに表示されます。 以下は、スキャンした紙文書のペアに対して計算された例です。.PNG)
.PNG) なお、テキストの外観や位置は結果に影響を与えません。
なお、テキストの外観や位置は結果に影響を与えません。.PNG) これら2つのページは、文字色の違いにもかかわらず同一とみなされる。これら2つのページは、コンテンツレイアウトの違いにもかかわらず同一とみなされる。
これら2つのページは、文字色の違いにもかかわらず同一とみなされる。これら2つのページは、コンテンツレイアウトの違いにもかかわらず同一とみなされる。.PNG) この2つのページは、テキストの順序、レイアウト、画像の有無の違いにもかかわらず、94%類似していると考えられます。
この2つのページは、テキストの順序、レイアウト、画像の有無の違いにもかかわらず、94%類似していると考えられます。.PNG) ステップ5 – 重複するページを抽出またはブックマークする オプションとして、「ページをブックマークする」ボタンを使用して、チェックしたすべてのページをブックマークすることができます。 これは、見つかった重複ページをドキュメントから削除する予定がない場合に便利です。 ページの前にあるチェックボックスを使って、処理セットから選択したり、選択解除したりすることができます。 ページを抽出…」ボタンを使って、チェックしたすべてのページを別のPDF文書に抽出します。 この操作では、現在の文書からページが削除されることはありません。
ステップ5 – 重複するページを抽出またはブックマークする オプションとして、「ページをブックマークする」ボタンを使用して、チェックしたすべてのページをブックマークすることができます。 これは、見つかった重複ページをドキュメントから削除する予定がない場合に便利です。 ページの前にあるチェックボックスを使って、処理セットから選択したり、選択解除したりすることができます。 ページを抽出…」ボタンを使って、チェックしたすべてのページを別のPDF文書に抽出します。 この操作では、現在の文書からページが削除されることはありません。.PNG) 「レポートを保存…」ボタンで、ページ類似度計算レポートをHTMLファイルに保存します。 このレポートには、ページの類似度の詳細、ページ間の差分、不足単語のリストが含まれています。 詳細な分析のために非常に有用です。
「レポートを保存…」ボタンで、ページ類似度計算レポートをHTMLファイルに保存します。 このレポートには、ページの類似度の詳細、ページ間の差分、不足単語のリストが含まれています。 詳細な分析のために非常に有用です。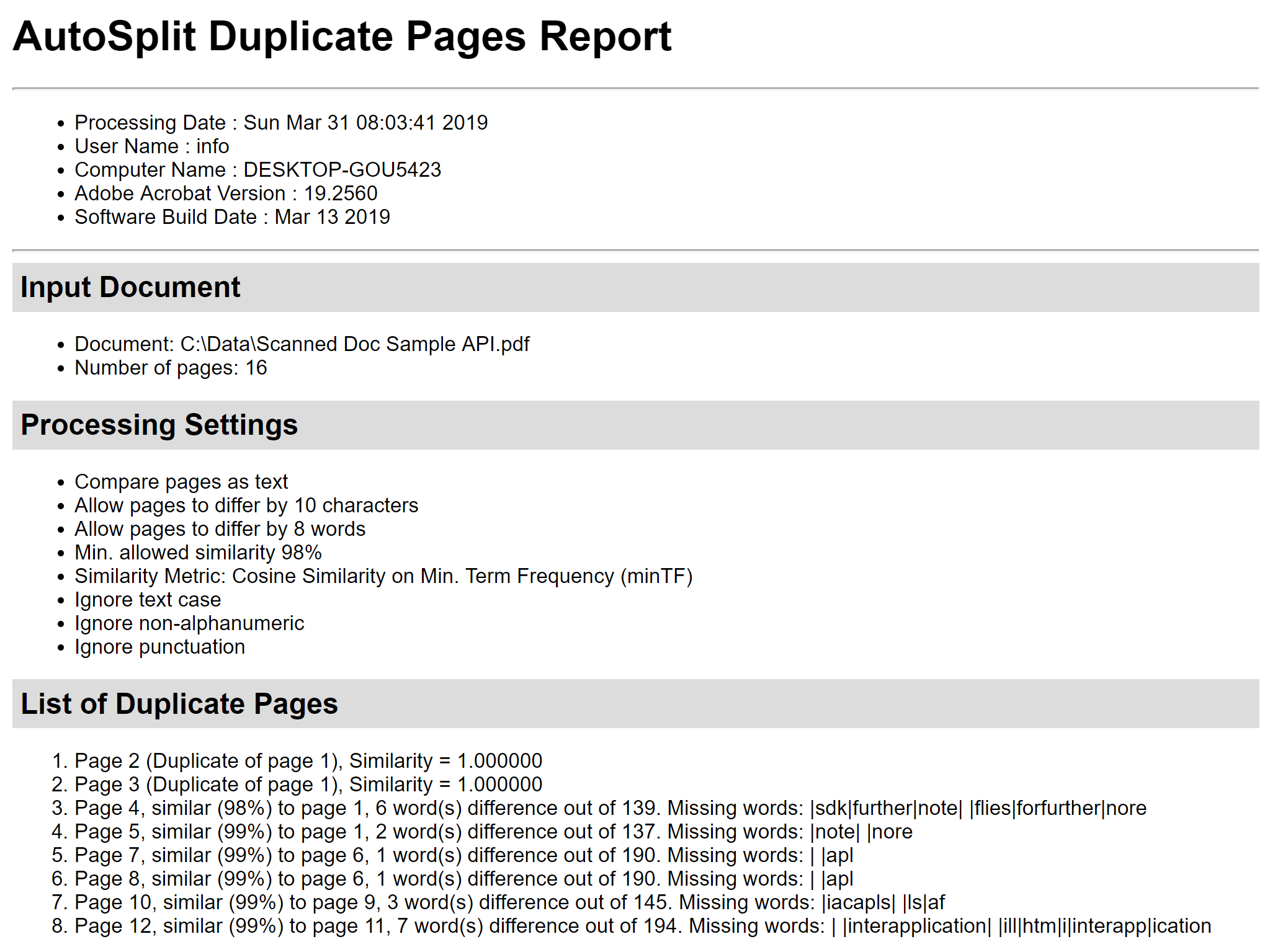 Step 6 – Delete Duplicate Pages ページの前にあるチェックボックスを使って、削除するページを選択したり、削除しないようにしたりします。 重複ページの削除」ダイアログで「ページの削除」ボタンを押すと、現在のPDF文書からすべてのチェックされたページが削除されます。
Step 6 – Delete Duplicate Pages ページの前にあるチェックボックスを使って、削除するページを選択したり、削除しないようにしたりします。 重複ページの削除」ダイアログで「ページの削除」ボタンを押すと、現在のPDF文書からすべてのチェックされたページが削除されます。.PNG) 「OK」ボタンをクリックし、確定します。 ページは永久に削除されます。
「OK」ボタンをクリックし、確定します。 ページは永久に削除されます。.PNG) 方法2 – 外観のみを比較する 概要 この方法は、ページを「画像として」比較し、まったく同じに見えるページを検出するものです。 この方法では、ページ上に存在する可能性のある不可視のテキストは比較されません。 スキャンした紙文書にこの方法を使用することはお勧めしません。 手順1 – PDFファイルを開く Adobe® Acrobat®アプリケーションを起動し、「ファイル > 開く…」メニューでPDFファイルを開きます。ステップ2 – 「重複ページの検索」ダイアログを開く プラグイン > 文書の分割 > 重複ページの検索と削除…]を選択し、「重複ページの検索」ダイアログを開く。ステップ3 – 設定の指定 「完全一致のために外観を比較する(画像の比較に使用できる)」にチェックを入れます。
方法2 – 外観のみを比較する 概要 この方法は、ページを「画像として」比較し、まったく同じに見えるページを検出するものです。 この方法では、ページ上に存在する可能性のある不可視のテキストは比較されません。 スキャンした紙文書にこの方法を使用することはお勧めしません。 手順1 – PDFファイルを開く Adobe® Acrobat®アプリケーションを起動し、「ファイル > 開く…」メニューでPDFファイルを開きます。ステップ2 – 「重複ページの検索」ダイアログを開く プラグイン > 文書の分割 > 重複ページの検索と削除…]を選択し、「重複ページの検索」ダイアログを開く。ステップ3 – 設定の指定 「完全一致のために外観を比較する(画像の比較に使用できる)」にチェックを入れます。.PNG) 「OK」をクリックすると、重複するページの検索を開始します。 Step 4 – 重複ページの検査 「重複ページの削除」ダイアログには、重複しているページや重複しているに近いページの一覧が表示されます。 ページレコードをクリックすると、対応するページがサイド・バイ・サイド表示されます。 ページを確認し、削除するページを選択/解除します。
「OK」をクリックすると、重複するページの検索を開始します。 Step 4 – 重複ページの検査 「重複ページの削除」ダイアログには、重複しているページや重複しているに近いページの一覧が表示されます。 ページレコードをクリックすると、対応するページがサイド・バイ・サイド表示されます。 ページを確認し、削除するページを選択/解除します。.PNG) オプションとして、「レポートを保存…」をクリックすると、HTML形式のページ類似性レポートが作成されます。 また、「ページをブックマークする」をクリックすると、選択した重複ページに対してPDFでブックマークが作成されます。 この方法は、ページの小さい(サンプル)コピーを作成し、「画像として」比較するものです。 次の例は、グラフィックスだけを含み、検索可能なテキストを含まない、2つの同じページを示しています。
オプションとして、「レポートを保存…」をクリックすると、HTML形式のページ類似性レポートが作成されます。 また、「ページをブックマークする」をクリックすると、選択した重複ページに対してPDFでブックマークが作成されます。 この方法は、ページの小さい(サンプル)コピーを作成し、「画像として」比較するものです。 次の例は、グラフィックスだけを含み、検索可能なテキストを含まない、2つの同じページを示しています。.PNG) ページが視覚的に同一である場合、ソフトウェアはそれらを重複として検出します。
ページが視覚的に同一である場合、ソフトウェアはそれらを重複として検出します。.PNG) この2つのページは、片方のページに「Approved」のスタンプがあるため、異なるページとみなされます。
この2つのページは、片方のページに「Approved」のスタンプがあるため、異なるページとみなされます。.PNG) この2つのページは、この方法によって同一とみなされます。
この2つのページは、この方法によって同一とみなされます。.PNG) テキストベースの比較方法とは異なり、テキストの色やスタイルが異なる場合、そのページは同一であるとはみなされません。
テキストベースの比較方法とは異なり、テキストの色やスタイルが異なる場合、そのページは同一であるとはみなされません。.PNG) ステップ5 – 重複したページを削除する “重複したページを削除する “ダイアログで “ページを削除 “をクリックして進みます。 現在のPDF文書からページを削除するには、 “OK “ボタンをクリックします。 ページは永久に削除されます。複数のPDF文書を比較する この操作により、複数のPDF文書から重複するページを探し出し、削除することができます。 方法は、1つ以上の文書を1つのPDFファイルに結合し、できたファイルに対して「重複ページの検索と削除」操作を実行することです。 これにより、基本的に重複のない1つの文書ができあがります。 オプションとして、検出されたすべての重複ページを別のPDF文書に抽出することも可能です。 ステップ1 – 複数のPDF文書を結合する 概要 Adobe® Acrobat® アプリケーションを起動し、メニューから「ツール」を選択します。 ツール一覧から「ファイルを結合」アイコンを選択します。
ステップ5 – 重複したページを削除する “重複したページを削除する “ダイアログで “ページを削除 “をクリックして進みます。 現在のPDF文書からページを削除するには、 “OK “ボタンをクリックします。 ページは永久に削除されます。複数のPDF文書を比較する この操作により、複数のPDF文書から重複するページを探し出し、削除することができます。 方法は、1つ以上の文書を1つのPDFファイルに結合し、できたファイルに対して「重複ページの検索と削除」操作を実行することです。 これにより、基本的に重複のない1つの文書ができあがります。 オプションとして、検出されたすべての重複ページを別のPDF文書に抽出することも可能です。 ステップ1 – 複数のPDF文書を結合する 概要 Adobe® Acrobat® アプリケーションを起動し、メニューから「ツール」を選択します。 ツール一覧から「ファイルを結合」アイコンを選択します。.PNG) 「ファイルを結合」メニューの「ファイルを追加…」をクリックし、結合するPDFファイルを選択して比較します。
「ファイルを結合」メニューの「ファイルを追加…」をクリックし、結合するPDFファイルを選択して比較します。.PNG) メニューの「結合」ボタンをクリックし、選択したPDFファイルを結合します。
メニューの「結合」ボタンをクリックし、選択したPDFファイルを結合します。.PNG) ステップ2 – 重複ページを見つける 結合された出力PDFファイルは、画面上に表示されます。 そうでない場合は、結合されたPDFファイルを開きます。 プラグイン > ドキュメントを分割する > 重複ページを検索して削除… “を選択して、”重複ページを検索 “ダイアログを表示します。「外観を比較して完全に一致させる(画像の比較に使用可能)」にチェックを入れます。 OK]をクリックすると、重複するページの検索が開始されます。
ステップ2 – 重複ページを見つける 結合された出力PDFファイルは、画面上に表示されます。 そうでない場合は、結合されたPDFファイルを開きます。 プラグイン > ドキュメントを分割する > 重複ページを検索して削除… “を選択して、”重複ページを検索 “ダイアログを表示します。「外観を比較して完全に一致させる(画像の比較に使用可能)」にチェックを入れます。 OK]をクリックすると、重複するページの検索が開始されます。.PNG) ステップ3 – 重複するページを抽出する 「重複するページの削除」ダイアログには、重複しているページや重複に近いページの一覧が表示されます。 ページレコードをクリックすると、対応するページがビューアに表示されます。 ページを調べ、選択・解除します。 ページを抽出…」をクリックすると、選択した重複ページを新しいPDF文書に抽出します。
ステップ3 – 重複するページを抽出する 「重複するページの削除」ダイアログには、重複しているページや重複に近いページの一覧が表示されます。 ページレコードをクリックすると、対応するページがビューアに表示されます。 ページを調べ、選択・解除します。 ページを抽出…」をクリックすると、選択した重複ページを新しいPDF文書に抽出します。.PNG) 出力先フォルダとファイル名を指定します。 完了したら[保存]をクリックします。
出力先フォルダとファイル名を指定します。 完了したら[保存]をクリックします。.PNG) 別文書に抽出されたページ数を示すダイアログが表示されます。 これで、重複しているページをすべて別のPDFファイルに保存してから削除することができました。 これらのページは、必要に応じて後で調べ、使用することができます。 OK」をクリックして、ダイアログを閉じます。
別文書に抽出されたページ数を示すダイアログが表示されます。 これで、重複しているページをすべて別のPDFファイルに保存してから削除することができました。 これらのページは、必要に応じて後で調べ、使用することができます。 OK」をクリックして、ダイアログを閉じます。.png) ステップ4 – 重複したページを削除する 重複したページの削除」ダイアログの「ページの削除」をクリックして先に進みます。
ステップ4 – 重複したページを削除する 重複したページの削除」ダイアログの「ページの削除」をクリックして先に進みます。.PNG) ダイアログの[OK]をクリックすると、現在のPDF文書から選択した重複したページが削除されます。
ダイアログの[OK]をクリックすると、現在のPDF文書から選択した重複したページが削除されます。.PNG) 選択された重複ページは、PDF文書から永久に削除されます。 変更した文書をディスクに保存するには、[ファイル > 保存]メニューを使用する必要があります。 利用可能なすべてのステップバイステップのチュートリアルのリストについては、ここをクリックしてください。
選択された重複ページは、PDF文書から永久に削除されます。 変更した文書をディスクに保存するには、[ファイル > 保存]メニューを使用する必要があります。 利用可能なすべてのステップバイステップのチュートリアルのリストについては、ここをクリックしてください。