Revised: 2020年12月11日
被験者は真実を語っているのか
自己報告データの信頼性は、調査研究のアキレス腱である。 例えば、世論調査によると、アメリカ人の40%以上が毎週教会に通っているとのことである。 しかし、Hadaway and Marlar (2005)は、教会の出席記録を調べることで、実際の出席率は22%以下であると結論付けている。 Seth Stephens-Davidowitz (2017)は、彼の代表的な著作 “Everybody lies “で、ほとんどの人が言ったことを実行せず、whatthey doを言わないことを示す十分なevidencetoを発見しました。 例えば、世論調査に対して、ほとんどの有権者は、候補者の民族性は重要でないと宣言しています。 具体的には、Googleのユーザーが「Obama」と入力すると、必ず彼の名前と人種に関連するいくつかの単語を連想することがわかったのです。
Webを利用した授業の研究では、ユーザーのアクセスログを解析したり、クッキーを設定したり、キャッシュをアップロードすることで、Webの利用状況データを取得することができる。 しかし、これらの方法は適用範囲が限定される可能性がある。 例えば、ユーザーアクセスログでは、リンクをたどって他のWebサイトに移動するユーザーを追跡することができない。 また、Cookieやキャッシュによるアプローチは、プライバシーの問題を引き起こす可能性がある。 このような場合、アンケートによる自己申告のデータを利用することになる。 そこで疑問が生じる。 という疑問が生じる。 Cook and Campbell (1979)は、被験者が(a)調査者が期待していると思われることを報告する傾向がある、(b)自分自身の能力、知識、信念、意見を肯定的に反映することを報告する傾向がある、と指摘している。 もう一つの懸念は、被験者が過去の行動を正確に思い出すことができるかどうかという点である。 心理学者は、人間の記憶は誤りやすいと警告している(Loftus, 2016; Schacter, 1999)。 時には、人は起こってもいない出来事を「記憶」している。 したがって、自己報告データの信頼性は微妙です。統計ソフトウェアパッケージは16-32小数までのcalcnumbersが可能ですが、datacannotが整数レベルでも正確でなければ、この精度は無意味です。 測定誤差がいかに統計的分析に支障をきたすかを警告し(Blalock, 1974)、優れた研究実践には、収集したデータの質を調べることが必要であると示唆した学者も少なくない(Fetter, Stowe, & Owings, 1984)。
Bias and Variance
測定誤差にはバイアスおよび変数誤差という二つの構成要素があります。バイアスとは、報告したスコアをある極端に押し下げる傾向がある系統的誤差のことを指します。 例えば、いくつかのバージョンのIQテストは、非白人に対して偏りがあることが分かっている。 これは、黒人やヒスパニック系が実際の知能に関係なく低い点数を受け取る傾向があることを意味します。 変動誤差は、分散とも呼ばれ、ランダムになる傾向があります。 つまり、報告されたスコアは実際のスコアより上にも下にもなりうるのである(Salvucci, Walter, Conley, Fink, & Saba, 1997)。
これら2つのタイプの測定誤差の知見は、異なる示唆を与えている。 例えば、身長と体重の自己申告データを直接測定したデータと比較した研究(Hart & Tomazic, 1999)では、被験者は身長を過大申告し、体重を過小申告する傾向があることが明らかになった。 このような誤差は分散というよりバイアスであることは明らかである。 このバイアスの説明として考えられるのは、ほとんどの人が他人に対してより良い身体的イメージを与えたいと考えていることである。 しかし、測定誤差がランダムである場合、説明はより複雑になるかもしれない。
自然にランダムである変動誤差は、互いに相殺され、したがって、研究に対する脅威にはならないかもしれないと主張する人がいるかもしれない。 例えば、最初のユーザーは自分のインターネット活動を10%過大評価しているかもしれないが、2番目のユーザーは彼女のインターネット活動を10%過少評価しているかもしれない。 この場合、平均値はまだ正しいかもしれない。 しかし、過大評価や過小評価は、分布のばらつきを増加させます。 多くのパラメトリック検定では,誤差項としてグループ内変動が使われる。 ばらつきが大きくなると、検定の有意性に影響を与えることは間違いないでしょう。 このような誤解を補強するような文章もある。 例えば、Deese (1972) は、
Statistical theory tells us that thereliability of observations is proportional to the square root of theirnumber.と述べている。 観測値が多ければ多いほど、ランダムな影響も多くなる。
まず、サンプルサイズが大きくなると分布の分散が小さくなることは事実であるが、分布の形が正規分布に近づくことを保証するものではない。 第二に、信頼性(データの質)は、サンプルサイズの決定よりも、測定に結びつけられるべきである。
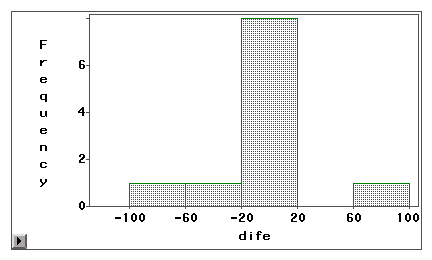
測定誤差が系統的な偏りによるものか、ランダムな分散によるものかを視覚的に調べるには、幹と葉のプロットやヒストグラムを使用することができる。 次の例では、2種類のインターネットアクセス(ウェブブラウジングと電子メール)が、自己報告式の調査と日誌の両方によって測定されています。 最初のグラフは、ほとんどの差分スコアがゼロの周りに集中していることを明らかにしている。 両端付近で過少申告と過剰申告が見られることから、測定誤差は系統的な偏りではなく、ランダムな誤差であることがわかる。
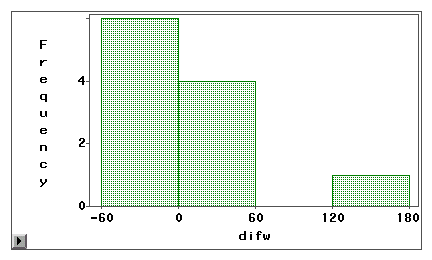
2番目のグラフは、差の得点が0を中心とするものはほとんどないことから、測定誤差が大きいことが明らかである。 また、分布は負に傾いており、誤差は分散ではなく偏りである。
我々の記憶の信頼度は?
Schacter (1999)は人間の記憶が誤りやすいことに警告している。 私たちの記憶には7つの欠点があるのです。
- 一過性。 時間の経過とともに情報へのアクセス性が低下すること。
- 不在意識(Absent-mindedness)。
- ブロッキング:不注意や浅い処理で、弱い記憶を助長する。
- ブロッキング:記憶している情報に一時的にアクセスできなくなること
- 誤帰属:記憶や考えを間違ったソースに帰属させること
- 暗示性。 誘導尋問や期待によって植えつけられた記憶。
- バイアス:偏見。
- 偏り:現在の知識や信念に関連した、回顧的な歪曲や無意識の影響。
 |
“I have norecollection of these.” (これらの記憶がない) ホワイトウォーターの文書に署名したことは覚えていない。 なぜその文書が消え、後に再び現れたのか覚えていない。 何も覚えていない」 「(ボスニアに)上陸して、狙撃されたことを覚えている。 空港で何らかの挨拶があるはずだったが、代わりに私たちはただ頭を下げて走って、私たちの基地に行くための車に乗り込んだ」 個人用電子メールサーバーで機密情報を送信したことの捜査中、クリントンはFBIに対して39回も「思い出す」または「覚えている」ことができなかったと語った。 新しいコンピュータウイルス「Clinton」が発見されました。 このウィルスに感染すると、十分なメモリがあるにもかかわらず、「メモリ不足」というメッセージが頻繁に表示されるようになります。 |
| Q: 「もしヴァーノン・ジョードンが、あなたの記憶力は並外れたもの、彼が今まで見た政治家の中で最大の記憶力のひとつだと言ってきたら、これはあなたが異議を唱えるべき事柄でしょうか?「
A: “私は良い記憶力を持っています…しかし、モニカ・ルインスキーと二人きりになったかどうか覚えていないのです。 Q: なぜクリントンはレブロンでの仕事にルインスキーを推薦したのですか? A: 彼は彼女が物事をでっち上げるのが得意だと知っていた。 |
 |
記憶の信頼性が結果の望ましさと結びついている場合があることに注意することが重要です。 たとえば、医学研究者が、赤ちゃんが健康な母親と、子供が奇形である母親から関連データを収集しようとすると、通常、後者からのデータの方が前者のデータよりも正確である。 なぜなら、奇形児の母親は、妊娠中に起こったあらゆる病気、服用した薬、悲劇に直接または間接的に関連するあらゆる詳細を慎重に検討し、その説明を見つけようとしているからです。 逆に、健康な乳児の母親は、先の情報にはあまり注意を払わない(Aschengrau & SeageIII, 2008)。 GPAの水増しは、desirabilityが記憶の正確さとデータの完全性に影響を与えるもう一つの例である。 ある状況では、GPAのインフレーションに性差がある。 Caskie etal.が行った研究。 (2014)は、GPAの低い学部生のグループ内で、女性は男性よりも実際よりも高いGPAを報告する傾向があることを発見しました。
記憶エラーの問題に対抗するために、いくつかの研究者は、遠隔の出来事を思い出すように求めるのではなく、参加者の瞬間的な思考や感情に関連するデータを収集することを提案した(Csikszentmihalyi & Larson, 1987; Finnigan & Vazire,2018 )。 以下の例は、2018 Programme forInternational Student Assessment の調査項目である。 “昨日一日、敬意を持って扱われましたか?” “昨日はよく笑ったり、微笑んだりしましたか?” “昨日は何か面白いことを学んだり、したりしましたか?” (Organisation forEconomic Cooperation and Development, 2017)という項目がある。 しかし、回答はその特定の瞬間の周りに参加者に起こったことに依存し、典型的なものではないかもしれない。 具体的には、昨日、回答者があまり笑わなかったとしても、回答者がいつも不幸であることを必ずしも意味するものではありません。
どうしましょうか?
研究者の中には、自己報告データは質が悪いと言われており、利用を拒否する人もいます。 たとえば、研究者グループが、COVID19パンデミック時の米国で、宗教性の高さが避難所設置指示の遵守の低さにつながったかどうかを調査したとき、社会的望ましさを反映する傾向がある自己報告式の宗教性ではなく、地域の宗教性の代理指標として住民1万人あたりの集会数を使用しました (DeFranza, Lindow, Harrison, Mishra, &Mishra, 2020)。
しかし、Chan (2009)は、いわゆる自己報告データの質の低さは都市伝説に過ぎないと論じている。 社会的望ましさに駆られて、回答者が研究者に不正確なデータを提供することもあるかもしれないが、それが常に起こるわけではない。 例えば、回答者が性別や民族などのデモグラフィックについて嘘をつくことはまずありえない。 第二に、実験的研究では回答者が回答を偽る傾向があるのは事実ですが、野外調査や自然主義的な環境で用いられる測定では、この問題はそれほど深刻ではありません。 さらに、様々な心理的構成要素に関する確立された自己報告式測定法が数多くあり、それらは収束的妥当性と判別的妥当性の両方を通じて構成要素の妥当性が証明されている。 例えば、Big-5性格特性、積極性性格、情緒性気質、自己効力感、目標志向性、知覚的組織支援、その他多数。疫学分野では、Khoury, James and Erickson (1994)が、想起バイアスの影響は過大評価であると主張している。 しかし、彼らの結論は、教育や心理学などの他の分野にはうまく適用できないかもしれない。データの不正確さの脅威にもかかわらず、研究者がすべての被験者をカムコーダーで追跡し、彼らの行動をすべて記録することは不可能である。 しかし、研究者は、被験者の一部を用いて、ユーザーログのアクセスや日々のウェブアクセスのハードコピーなどの観察データを取得することができる。 例えば、
- ユーザーアクセスログが研究者に入手可能な場合、研究者は被験者にウェブサーバーへのアクセス頻度を報告するよう求めることができる。
- 研究者は、ユーザーのサブセットに1ヶ月間インターネット活動のログブックを保持するように依頼することができます。 その後、同じユーザーにWeb使用に関するアンケートに回答してもらう。
ログブック方式は厳しすぎると主張する人がいるかもしれません。 実際、多くの科学的な調査研究において、被験者はそれ以上のことを要求されます。 例えば、科学者が長距離宇宙旅行中の深い眠りが人間の健康にどのような影響を与えるかを研究したとき、被験者は1ヶ月間ベッドに横たわるよう要求されました。 また、宇宙旅行中の閉鎖環境が人間の心理にどのような影響を与えるかについての研究では、被験者は1ヶ月間、個室に閉じ込められました。 科学的な真実を追求するためには、高いコストがかかります。
異なるデータ源を収集した後、ログと自己報告データの間の不一致を分析し、データの信頼性を推定することができます。 一見すると、この方法はテスト・リテスタビリティのように見えますが、そうではありません。 まず、テスト・リテストの信頼性では、2つ以上の状況で使用される測定器は同じでなければなりません。 第二に、テスト・テスト信頼性が低い場合、誤差の原因は測定器内にある。
以上の手順は、データ間信頼性の測定として概念化でき、評価者間信頼性と反復測定に類似したものである。 評価者間信頼性を推定する方法としては、カッパ係数、非整合性指数、反復測定ANOVA、回帰分析の4つがある。
Kappa coefficient
心理学や教育学の研究において、主観的な判断を伴う評価(例えば、小論文の採点)では、2人以上の評価者を用いて測定することが少なくない。 例えば、被験者の成績を2人以上の評価者が「名人」「非名人」(1か0)で評定する場合、カッパ係数で測定される評価者間信頼性は、データの信頼性を示すのに用いられる。 したがって、この測定は通常、SASのPROC FREQ、SPSSの「一致度測定」、またはオンラインKappa計算機(Lowry, 2016)などのカテゴリデータ分析手続きで計算されます。 下の画像は、Vassarstatsオンライン計算機のスクリーンショットです。
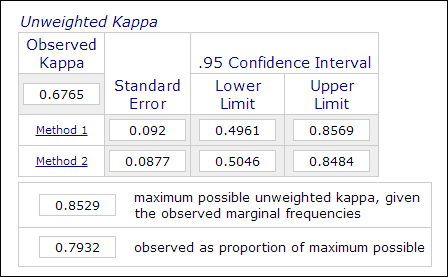
二つのデータセットの60%が互いに一致しても、それは測定が信頼できるという意味ではありません。結果は二値なので、thetwo測定が一致する確率は50%あります。 カッパ係数はこれを考慮し、整合性を得るために、より高い一致度を要求する。
Webベースの教育の文脈では、自己報告によるWebサイト利用の各カテゴリは、バイナリ変数として再コード化することができる。 たとえば、質問1が「どのくらいの頻度でtelnetを使用しますか」であるとき、可能なカテゴリ回答は「a: 毎日」、「b: 1週間あたり3~5回」、「c: 1ヶ月あたり3~5回」、「d: まれに」、「e: 決して」である。 この場合、5つのカテゴリは5つの変数に再コード化できる。 Q1A、Q1B、Q1C、Q1D、Q1E。 このデータ構造では、回答は “1 “または “0 “としてコード化でき、分類の一致度を測定することができる。 この一致度はカッパ係数で計算され、データの信頼性を推定することができる。
被験者 ログブック・データ 自己紹介報告書データ 件名1 1 件名 2 0 0 対象 3 1 0 Subject 4 0 1 Index of Inconsistency
前述のカテゴリーデータのもう一つの計算方法として、IOI (Index ofInconsistency) があります。 上記の例では、測定値が2つ(logと自己申告)、回答が5つあるので、4×4の表が形成される。 IOI を計算する最初のステップは、RXC テーブルをいくつかの 2X2 サブテーブルに分割することである。 例えば,以下の表のように,最後の選択肢である “決して “を1つのカテゴリとし,残りを “決してではない “という別のカテゴリに分解する。
Self->Systems報告データ Log ない 合計 ない a b a+b ない c d c+d 合計 a+c b+d n=Sum(a-> )d)
IOIのパーセントは次の式で計算されます。
IOI% = 100*(b+c)/ where p = (a+c)/n
各2X2サブテーブルでIOIを計算した後、すべてのインデックスの平均は、指標の不整合性の指標として使用されます。 データの整合性を判断する基準は以下の通りである。
- IOIが20未満は低分散
- IOIが20から50は中分散
- IOIが50以上は高分散
データの信頼性はこの式で表現される。 r = 1 – IOI
Intraclass correlation coefficient
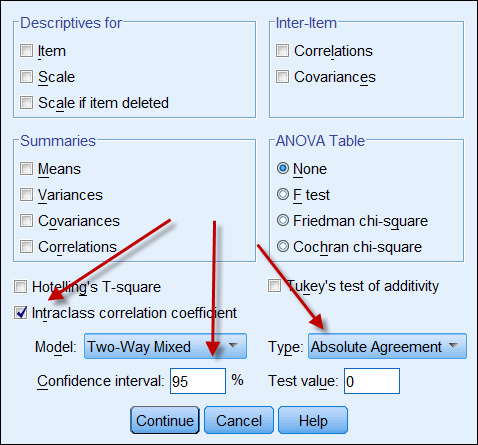
両方のデータソースから連続データが得られる場合、データの信頼性を示すためにIntraclass correlation coefficientを計算することができます。 以下は、SPSSのICCのオプションのスクリーンショットです。 タイプでは、2つのオプションがあります。 “一貫性 “と “絶対一致”。 一貫性」を選択した場合、一方の数値セットが一貫性高(例:9、8、9、8、7・・・)、他方が一貫性低(例:4、3、4、3、2・・・)であっても、それらの強い相関は、データが互いにalignmentであると誤認させるものである。 従って、”絶対一致 “を選択することが望ましい。
反復測定
データ間信頼性の測定も反復測定ANOVAとして概念化、手続き化することができる。 反復測定ANOVAでは、測定は同じ被験者に対して前試験、中間試験、後試験のように数回行われる。 この文脈では、被験者は、Webユーザーログ、ログブック、自己報告式調査によって、繰り返し測定されます。 以下は反復測定ANOVAのSASコードである:
data one; input user $ web_log log_book self_report;
cards;
1 215 260 200
2 178 200 150
3 100 111 120
4 135 172 100
5 139 150 140
6 198 200 230
7 135 150 180
8 120 110 100
9 289 276 300
proc glm;
classes user;
model web_log log_book self_report = user;
repeated time 3;
run;
上記のプログラムでは、9人のボランティアによるWebサイトの訪問回数が、ユーザーアクセスログ、個人ログブック、自己報告式アンケートに記録される。 ユーザーを被験者間要因、3つの尺度を測定者間要因として扱っている。 以下は凝縮された出力である:
Source of variation DF Mean Square Between-subject (user) 8 10442.DF
とあるように、この3つは被験者間要因として扱われる。50 Between-measure (time) 2 488.93 Residual 16 454.1 Between-Measure (時間) Between-Measure (time) 421 Delay (時間)80 以上の情報をもとに、信頼性係数は次の式で計算できる(Fisher, 1946; Horst, 1949)。
r = MSbetween-measure – MSresidual ————————————–。———- MSbetween-measure + (dfbetween-people X MSresidual) 式に数字を突っ込んでみましょう。
r = 488.93 – 454.80 ———————– 488.93 + ( 8 X 454.80)
信頼度は約 0.0008 と非常に低くなっていますね。 したがって、このデータのことは家に帰って忘れてもよい。 幸いなことに、これは仮説的なデータセットに過ぎない。 しかし、それが実際のデータセットであったらどうでしょうか。
相関分析と回帰分析
ピアソンの積率係数を利用した相関分析は非常に簡単で、2 つの測定値の尺度が同じでない場合に特に有効です。 例えば、Webサーバーのログはページへのアクセス数を記録しているかもしれませんが、自己申告のデータはLikert-scaled(例えば、どのくらいの頻度でインターネットを見ますか? 5=とてもよく、4=よく、3=ときどき、2=あまり、5=まったく)。 この場合、自己申告のスコアは、ページアクセスに対して回帰するための予測因子として使用することができます。
同様のアプローチは回帰分析で、スコアの1つのセット(例:調査データ)を予測因子として扱い、別のスコアのセット(例:ユーザーの日報)を従属変数と見なすものです。 すなわち、より正確な結果をもたらすもの(例えば、ウェブ・ユーザーのアクセス・ログ)を従属変数とみなし、他のすべての尺度(例えば、ユーザーの日報、調査データ)を独立変数として扱います。
Reference
- Aschengrau, A., & Seage III, G. (2008). 公衆衛生における疫学のエッセンス. ボストン、マサチューセッツ州。 ジョーンズ アンド バートレット パブリッシャーズ
- Blalock, H. M. (1974). (編) 社会科学における測定法: 理論と戦略. シカゴ、イリノイ州。 Aldine Publishing Company.
- Caskie, G. I. L., Sutton, M. C., & Eckhardt, A. G. (2014). 自己申告の大学GPAの正確さ。 達成水準と学問的自己効力感によるジェンダー・モデレートされた差異. ジャーナル・オブ・カレッジ・スチューデント・ディベロップメント,55,385-390. 10.1353/csd.2014.0038
- Chan, D. (2009). では、なぜ私に尋ねるのか? 自己申告データは本当に悪いのか? Charles E. Lance and Robert J. Vandenberg (Eds.), Statistical and methodological myths and urban legends.にて。 統計的・方法論的神話と都市伝説:組織・社会科学における教義・真実・寓話(pp309-335). ニューヨーク、NY: Routledge.
- Cook, T. D., & Campbell, D. T. (1979). 準実験。 設計と分析の問題点. ボストン、マサチューセッツ州:ホートン・ミフリン・カンパニー.
- Csikszentmihalyi, M., & Larson, R. (1987). 経験サンプリング法の妥当性と信頼性. ジャーナル・オブ・ナーバス・アンド・メンタルディジーズ、175、526-536。 https://doi.org/10.1097/00005053-198709000-00004
- Deese, J. (1972). 科学と芸術としての心理学。 New York, NY: Harcourt Brace Jovanovich, Inc.
- DeFranza, D., Lindow, M., Harrison, K., Mishra, A., &Mishra, H. (2020, August 10).を参照。 COVID-19軽減ガイドラインに対する宗教とリアクタンス. アメリカン・サイコロジスト. アドバンスオンラインパブリケーション。 http://dx.doi.org/10.1037/amp0000717.
- Fetters, W., Stowe, P., & Owings, J. (1984)。 ハイスクール・アンド・ビヨンド. A national longitudinal study for the 1980s, quality of responses of high school students to questionnaire items.1980年代の全国縦断的研究、アンケート項目に対する高校生の回答の質。 (NCES 84-216).Washington, D. C..: U.S. Department of Education. Office of EducationalResearch and Improvement(教育研究改善局). National center for Education Statistics.
- Finnigan, K. M., & Vazire, S. (2018). The incrementalvalidity of average state self-reports over global self-reports ofpersonality. ジャーナル・オブ・パーソナリティ・アンド・ソーシャル・サイコロジー、115、321-337。 https://doi.org/10.1037/pspp0000136
- Fisher, R. J. (1946). 研究者のための統計的方法(第10版). Edinburgh, UK: Oliver and Boyd.
- Hadaway, C. K., & Marlar, P. L. (2005). How manyAmericans attend worship each week? 測定への代替アプローチ? 宗教の科学的研究のためのジャーナル、44、307-322。 DOI: 10.1111/j.1468-5906.2005.00288.x
- Hart, W.; & Tomazic, T. (1999 8月). 3つのデータセット間の身体測定値に対するパーセンタイル分布の比較。 Annual Joint Statistical Meeting, Baltimore, MDで発表した論文。
- Horst, P. (1949). 測定の信頼性に関する一般化された表現。 Psychometrika, 14, 21-31.
- Khoury, M., James, L., & Erikson, J. (1994). 先天性異常の症例-対照研究における想起バイアスに対処するための患児対照の使用について。 Teratology, 49, 273-281.
- Loftus, E. (2016, April). 記憶のフィクション 西部心理学会大会での論文発表。 Long Beach, CA.
- Lowry, R. (2016). カテゴリカルソーティングにおける一致度の指標としてのカッパ。 http://vassarstats.net/kappa.html
- Organisation for Economic Cooperation and Developmentから取得。 (2017). PISA2018のための幸福度アンケート。 パリ: 著者. Retrieved from https://www.oecd.org/pisa/data/2018database/CY7_201710_QST_MS_WBQ_NoNotes_final.pdf
- Schacter, D. L. (1999). 記憶の7つの罪。 心理学と認知神経科学からの洞察。 アメリカン・サイコロジー、54、182-203。
- Salvucci, S.; Walter, E., Conley, V; Fink, S; & Saba, M. (1997). 国立教育統計センターにおける測定誤差研究. ワシントン D. C: U. S. Department of Education.
- Stephens-Davidowitz, S. (2017). 誰もが嘘をつく。 Big data, new data, and what the Internet can tell us about who we really are. New York, NY: デイ・ストリート・ブックス
 メインメニューに上がる
メインメニューに上がる ナビゲーションその他のコースサーチエンジン
|

お問い合わせ
|