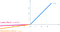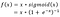- 関数とその微分がともに単調
- 出力はゼロ「中心」
- 最適化が容易
- Tanh関数の微分/微分(f'(x))は0~1であること。
短所:
- Tanh 関数の微分は「消失勾配と爆発勾配問題」に悩まされます。(指数関数を使う理由)
「Tanhはゼロ中心で勾配が特定の方向に制限されないのでシグモイド関数より好ましい」
3. ReLu活性化関数(ReLu – Rectified Linear Units)。


ReLUは、AIで人気を博している非線形活性化関数である。 ReLU関数はf(x) = max(0,x)とも表される。
- この関数とその導関数はともに単調である。
- Computationally efficient
- Derivative /Differential of the Tanh function (f'(x)) will be 1 if f(x) > 0 else 0.Comverge very fast
Cons:
- ReLu function in not “zero-centric”.This makes the gradient updates too far in different directions.これは勾配の更新が異なる方向に行ってしまうため。 0 < 出力 < 1 となり、最適化が難しくなる。
- Dead neuronは最大の問題で、これはNon-differentiable at zeroに起因します。
“Problem of Dying neuron/Dead neuron : ReLu derivative f'(x) is not 0 for the positive values of the neuron (f'(x)=1 for x≥ 0) as ReLu does not saturate (exploreoid) and no dead neurons (Vanishing neuron) are reported.これは、死にかけたニューロンがないことを示します。 飽和と消失勾配は、ReLuに与えられた負の値が0になったときのみ発生します。これは、dying neuronの問題と呼ばれます。 leaky ReLuの活性化関数。
リーキーReLU関数は、ReLU関数に「一定の傾き」を導入して改良したものである
![]()
![]()
LeLu activation (blue) , 誘導体(オルガノ)
- Leaky ReLUは、Dying neuron/dead neuronの問題を解決するために定義されました。
- この関数とその導関数はともに単調で、
- 逆伝播の際に負の値を許容する
- 効率的で計算が容易である。
- Leakyの微分はf(x) > 0のとき1、f(x) < 0のとき0と1の間にある。
短所:
- Leaky ReLUは負の入力値に対する予測に一貫性がない。 ELU (Exponential Linear Units) 活性化関数。
![]()
![]()
ELU とその誘導体
- ELU もまた、死にゆくニューロンの問題を解決するために提案されたものである。
- Dead ReLUの問題はない
- Zero-centric
Cons:
- Computationally intensive.
- Leaky ReLU と同様に、理論的には ReLU よりも優れているが、ELU が常に ReLU よりも優れているという良い証拠は今のところ実際にはない。
- f(x) is monotonic only if alpha is greater or equal to 0.
- f'(x) derivative of ELU is monotonic only if alpha lies between 0 and 1.
- Slow convergence due to exponential function.
6. P ReLu (Parametric ReLU)活性化関数。
![]()
![]()
Leaky ReLU vs P Relu
- leaky ReLUの考え方はさらに拡張することが可能です。
- x に定数項を乗じる代わりに、「ハイパーパラメーター (a-trainable parameter)」を乗じることができ、これはリーキー ReLU よりもうまくいくように思われます。 このリーキーReLUの拡張はパラメトリックReLUとして知られている。
- パラメータαは一般に0から1の間の数で、一般に比較的小さい。
- 訓練可能なパラメータによりリーキーリリューよりもわずかに有利である。
欠点:
- LeakyReluと同じ。
- f(x) は a> または =0 で単調、a =1 で単調
7. Swish (A Self-Gated) Activation Function:(Sigmoid Linear Unit)
![]()
- Google Brain Teamは新しい活性関数、Swishと名づけ、単純に f(x) = x – sigmoid(x) というのを提案しています。
- 彼らの実験によると、多くの困難なデータ セットにわたる深いモデルにおいて、Swish は ReLU よりもよく機能する傾向があることが示されました。 これは、モデル最適化プロセスにおいて有用であり、Swish が ReLU を上回る理由の 1 つであると考えられています。
- Swish関数は「単調ではない」。 これは、入力値が増加している場合でも、関数の値が減少する可能性があることを意味します。
- 関数は上では非束縛、下では束縛されます。
![]()
“Swish tend to continuously match or outform the ReLu”
swish functionの出力が、入力が増加しても低下するかもしれないことに注意することです。 これはSwish特有の面白い特徴です。(非単調性のため)
f(x)=2x*sigmoid(beta*x)
学習可能なパラメータであるβ=0のSwishの簡易版と考えると、シグモイド部は常に1/2でf (x) は線形になります。 一方、βが非常に大きな値であれば、シグモイドはほぼ2桁の関数になる(x<0で0,x>0で1)。 したがって、f (x)はReLU関数に収束する。 そこで、標準的なSwish関数をβ=1として選択する。 このようにして、ソフト補間(変数の値集合を与えられた範囲と所望の精度の関数に関連付ける)が提供されるのである。 素晴らしい 勾配の消失の問題に対する解決策が見つかりました。
8.Softplus
![]()
Activation function,first order derivative,second order derivative softplus functionはReLU functionと似ているが比較的滑らかである。SoftplusまたはSmoothReluの関数 f(x) = ln(1+exp x).
Softplus関数の微分 f'(x) はロジスティック関数 (1/(1+exp x)).
関数値の範囲は (0, + inf).f(x), f'(x) 共に単調です.
9.微分(1階)、2階(2階)は、漸化式(1階)です.
9.微分(1階)は、微分関数 (1+exp).です。ソフトマックスまたは正規化指数関数:
![]()
「ソフトマックス」関数もシグモイド関数の一種ですが、多クラス分類問題を扱うのに非常に有効な関数です。”
“ソフトマックス関数は、データポイントが各クラスに属する確率を返します。”
![]()
多クラス問題用のネットワークを構築する場合、出力層には対象のクラスの数と同数のニューロンを配置することになります。 これらの値に対してソフトマックス関数を適用すると、次のような結果が得られます。 これらは、データポイントが各クラスに属する確率を表しています。 この結果から、入力はクラスAに属することがわかります。
「すべての値の合計は1であることに注意してください」
どれを使うのが良いですか? それぞれの活性化関数には長所と短所があり、すべての長所と短所は軌跡に基づいて決定されます。
- Sigmoid 関数とその組み合わせは、一般に分類問題の場合によく機能する。
- Sigmoids と tanh 関数は、勾配の消失問題のために避けられることもある。
- ReLU によってネットワークで死んだニューロンがある場合、リーク ReLU 関数が最適な選択となる。