はじめに
現実の世界で機械学習モデルを構築する場合、データセット内のすべての変数がモデル構築に有用であることはほとんどない。 冗長な変数を追加すると、モデルの汎化能力が低下し、また分類器の全体的な精度も低下する可能性があります。 さらに、モデルにより多くの変数を追加すると、モデルの全体的な複雑さが増します。
「オッカムの剃刀」のパーシモンの法則によると、問題に対する最善の説明は、可能な限り少ない仮定を含むものであるとしています。
目標
機械学習における特徴選択の目標は、研究された現象の有用なモデルを構築できるような特徴の最適なセットを見つけることである。
機械学習における特徴選択の技術は、大きく以下のカテゴリに分類できる。 これらの技術はラベル付けされたデータに使用することができ、分類や回帰などの教師ありモデルの効率を高めるために関連する特徴を識別するために使用される。
分類学的な観点から、これらの技術は次のように分類されます:
A. フィルタリング手法
B. ラッパーメソッド
C. 埋め込み型手法
D. ハイブリッド手法
この記事では、機械学習における特徴選択でよく使われるいくつかの手法について説明します。 フィルター法
フィルター法は、クロスバリデーションの性能の代わりに、一変量統計で測定した特徴の本質的な特性をピックアップするものである。 これらの方法はラッパーメソッドよりも高速で、計算量も少ない。 高次元データを扱う場合、フィルター法を使用する方が計算コストが低くなります。
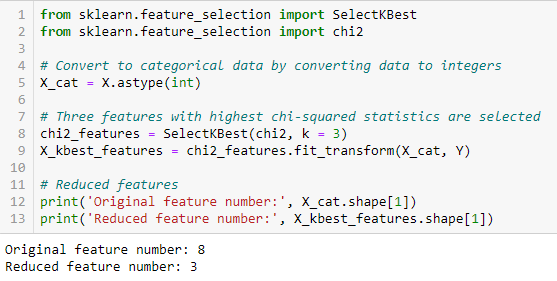
Information Gain
Information Gain は、データセットの変換によるエントロピーの減少を計算します。 ターゲット変数のコンテキストで各変数の情報利得を評価することにより、特徴選択に使用することができる。 各特徴とターゲットとの間のカイ二乗を計算し、最も良いカイ二乗のスコアを持つ特徴を所望の数だけ選択する。 データセット内のさまざまな特徴とターゲット変数の間の関係をテストするために、カイ二乗を正しく適用するためには、次の条件が満たされなければならない:変数はカテゴリでなければならず、独立してサンプリングされ、値は5より大きい予想頻度を持つべきである。
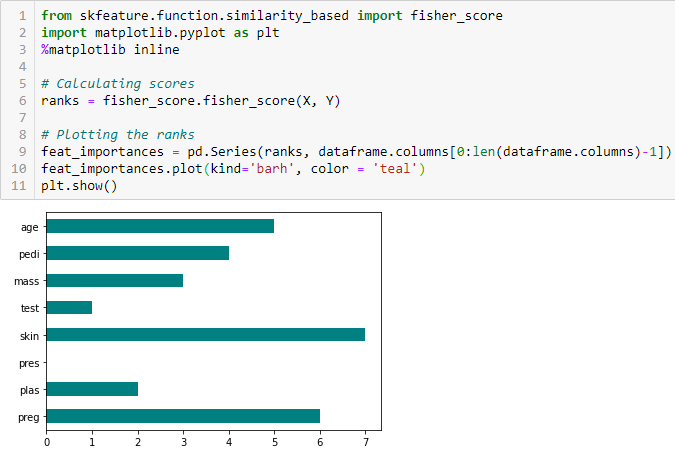
フィッシャースコア
フィッシャースコアは最も広く使われている教師あり特徴選択法の1つである。 我々が使用するアルゴリズムは、降順でフィッシャースコアに基づいて、変数のランクを返します。
相関係数
相関は、2つ以上の変数の線形関係の尺度である。 相関関係を通じて、我々は、他の変数から1つの変数を予測することができます。 特徴抽出に相関を用いる論理は、良い変数はターゲットと高い相関を持つということである。 さらに、変数はターゲットと相関しているが、それ自身は相関していないことが望ましい。
2 つの変数に相関がある場合、他から 1 つを予測することができます。 したがって、2つの特徴が相関している場合、2つ目の特徴は追加情報を加えないので、モデルはそのうちの1つだけが本当に必要である。 ここではピアソン相関を使用する。
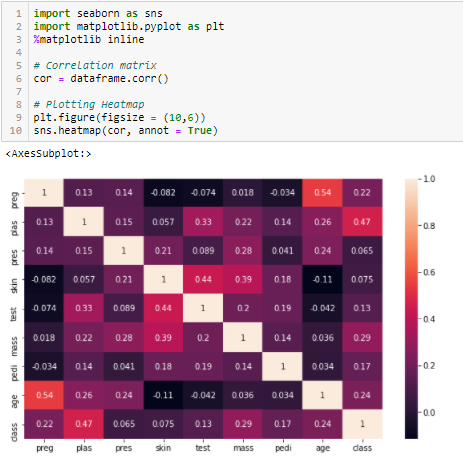
変数を選択する閾値として、絶対値、たとえば0.5を設定する必要がある。 予測変数同士が相関していることがわかれば、ターゲット変数との相関係数の値が低い変数を削除することができます。 また,2つ以上の変数が互いに相関しているかどうかを確認するために,重相関係数を計算することができる. この現象は多重共線性と呼ばれる。
分散閾値
分散閾値は特徴選択に対するシンプルなベースラインアプローチである。 これは、分散がある閾値を満たさないすべての特徴を削除する。 デフォルトでは、分散がゼロの特徴、つまり全てのサンプルで同じ値を持つ特徴を全て削除する。 分散が大きい特徴ほど有用な情報が含まれている可能性があるが、フィルタ手法の欠点である特徴変数間や特徴変数とターゲット変数間の関係を考慮していないことに注意されたい。

get_support はブール値のベクトルを返し、ここで True はその変数がゼロ分散でないことを意味します。
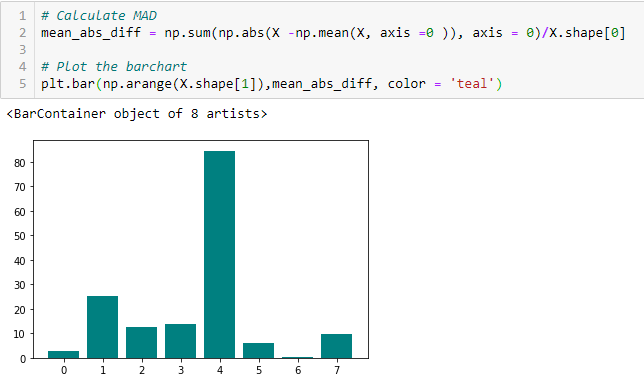
Mean Absolute Difference (MAD)
‘mean absolute difference (MAD) は平均値からの絶対差を計算するものである。 分散とMADの主な違いは、後者には二乗がないことです。 また、MADは分散と同様に尺度の変種です’。 これはMADが大きいほど識別力が高いことを意味する。
分散比
『分散のもう一つの尺度は算術平均(AM)と幾何平均(GM)を応用したものである。 n個のパターン上の与えられた(正の)特徴Xiに対して、AMとGMはそれぞれ
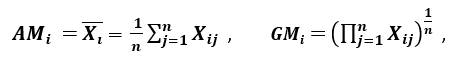
で与えられる。AMi ≥ GMi で、Xi1 = Xi2 = … = Xin のときだけ等しいので、比率
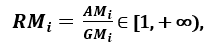
は分散尺度として使用可能である。 分散が大きいとRiの値が大きく、したがって関連性の高い特徴であることを意味する。 逆に、すべての特徴サンプルが(ほぼ)同じ値を持つとき、Riは1に近くなり、関連性の低い特徴を示す’。

 ‘
‘
B. Wrapper Methods.の項参照。
ラッパーは、特徴のすべての可能なサブセットの空間を検索し、その特徴サブセットで分類器を学習および評価することによってその品質を評価する、何らかの方法を必要とする。 特徴選択プロセスは、与えられたデータセットに適合させようとしている特定の機械学習アルゴリズムに基づきます。 評価基準に対して可能なすべての特徴の組み合わせを評価することで、貪欲な探索アプローチに従います。 ラッパー メソッドは通常、フィルター メソッドよりも優れた予測精度になります。
Let’s discuss some of these techniques:
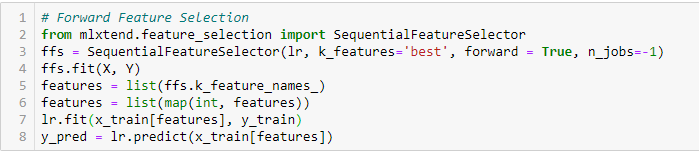
Forward Feature Selection
This is a iterative method where we start with the best performing variable against the target.Why? 次に、最初に選択した変数との組み合わせで最高のパフォーマンスを与える別の変数を選択する。 このプロセスは、事前に設定された基準が達成されるまで続けられます。
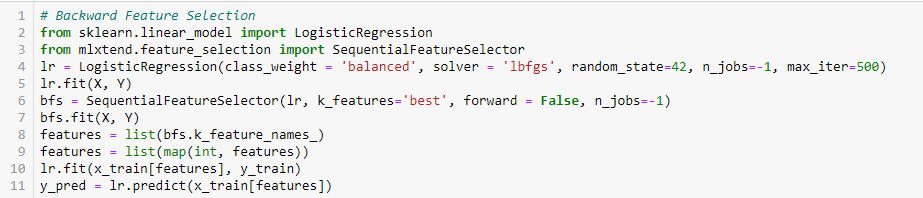
Backward Feature Elimination
この方法は、Forward Feature Selection 方法とまったく逆に機能します。 ここでは、利用可能なすべての特徴から始めて、モデルを構築する。 次に、そのモデルから最も良い評価指標値を与える変数を選択する。 このプロセスは、事前に設定された基準が達成されるまで続けられます。
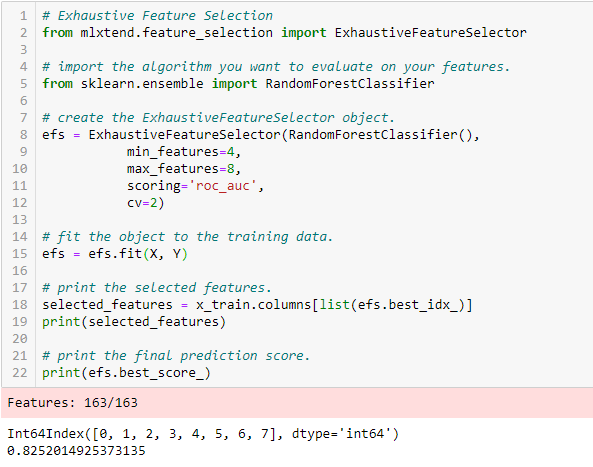
この方法は、前述の方法と合わせて、逐次特徴選択法としても知られています。 これは、各特徴の部分集合を総当り的に評価するものである。 これは、変数のあらゆる可能な組み合わせを試し、最も性能の良いサブセットを返すことを意味する。
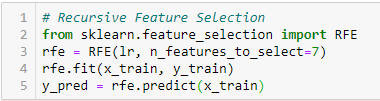
Recursive Feature Elimination
「特徴(例えば、線形モデルの係数)に重みを割り当てる外部推定器があるとき、再帰的特徴除去(RFE)の目標は、より小さな特徴のセットを繰り返し検討して、特徴を選択することである」。 まず、推定器は初期特徴セットで学習され、各特徴の重要度はcoef_属性またはfeature_importances_属性で求められる。
次に、現在の特徴量から最も重要度の低い特徴量を刈り取る。 この手順は、最終的に選択する特徴の望ましい数に達するまで、刈り込まれた集合に対して再帰的に繰り返される」
C. Embedded Methods:
これらの方法は、特徴の相互作用を含みつつ、妥当な計算コストを維持することにより、ラッパー法とフィルター法の両方の利点を包含している。 5929>
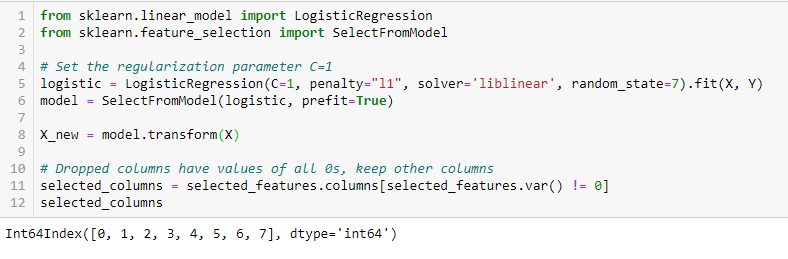
LASSO 正則化 (L1)
正則化は、機械学習モデルの異なるパラメーターにペナルティを追加して、モデルの自由度を下げ、オーバーフィットを防ぐものです。 線形モデルの正則化では、予測変数のそれぞれに乗じる係数にペナルティが適用される。 様々な正則化の中から、Lasso または L1 は、いくつかの係数をゼロに縮めることができる性質を持っています。 したがって、その特徴をモデルから取り除くことができる。
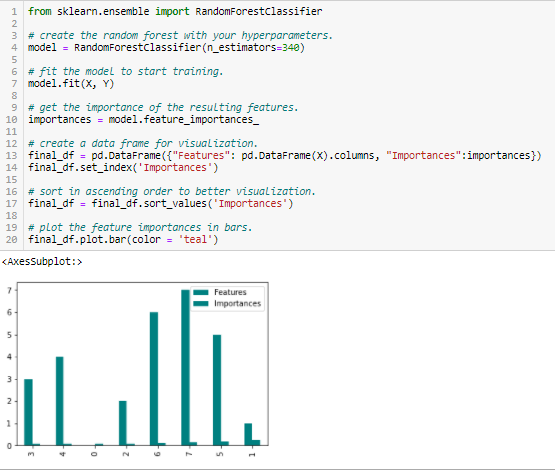
Random Forest Importance
Random Forests は特定数の決定木を集約した Bagging Algorithm の一種である。 ランダムフォレストで使われるツリーベースの戦略は、当然ながらノードの純度、言い換えれば全ツリーに対する不純度(Gini impurity)の減少をどれだけ改善したかによってランク付けされる。 不純度の減少が最も大きいノードは木の始点で起こり、不純度の減少が最も小さいノートは木の終点で起こる。 このように、特定のノード以下の木を刈り込むことで、最も重要な特徴のサブセットを作ることができる。
結論
特徴選択のためのいくつかの技術について述べてきた。 ここではあえて主成分分析、特異値分解、線形判別分析などの特徴抽出技術を残している。 これらの手法は、データの分散を維持したまま、データの次元を下げたり、変数の数を減らしたりするのに役立ちます。
上で述べた手法以外にも、特徴選択には多くの手法があります。 フィルタリングとラッピングの両方の技術を使用するハイブリッド手法もあります。 特徴選択技術についてもっと知りたい場合は、Urszula Stańczyk と Lakhmi C. による「Feature Selection for Data and Pattern Recognition」が素晴らしい包括的な読み物だと私は考えています。 Jain.
です。