方法1、悪いです。 ORDER BY NEWID()
書くのは簡単ですが、クラスタ化インデックス全体をスキャンし、すべての行でNEWID()を計算するため、高温でゴミのようなパフォーマンスになってしまいます。 (そして、Users テーブルは 1GB もありません。)
Method 2、より良いが奇妙な方法。 TABLESAMPLE
これは 2005 年に発表されたもので、多くの欠陥があります。 これは、ランダムなページを選択し、そのページから行の束を返すようなものです。 最初の行はちょっとランダムですが、残りはランダムではありません。
Transact-
|
1
|
SELECT * FROM StackOverflow.dbo.Users TABLESAMPLE (.01 PERCENT);
|
このプランはテーブルスキャンを行っているように見えますが、7つの論理読み込みしか行っていません。
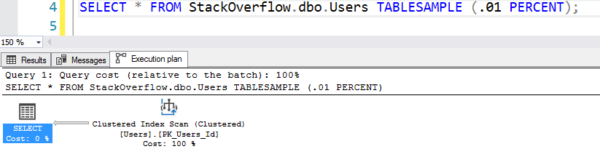
偽スキャンによるプラン
でも、これがその結果です-ランダムに8Kページに飛び、それから順番に行の読み出しを開始していることがわかります。
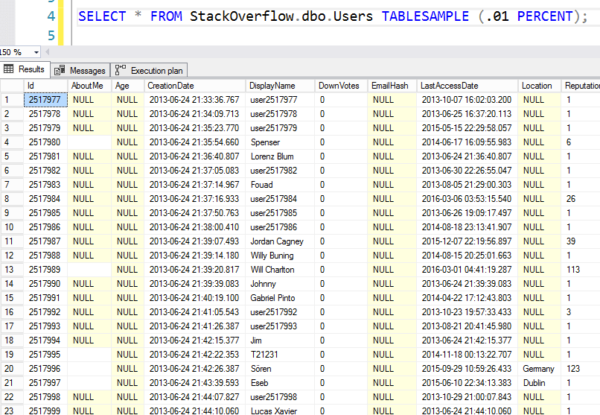
Random like mafia lottery numbers
代わりにROWSサンプルサイズを使うことができますが、これはかなり奇妙な結果をもたらします。 たとえば、Stack Overflow Users テーブルでは、TABLESAMPLE (50 ROWS) と言ったとき、実際には 75 行が返されました。 これは、SQL Server が行のサイズをパーセンテージに変換するためです。
Method 3, Best but Requires Code: ランダムな主キー
テーブルのトップ ID フィールドを取得し、乱数を生成して、その ID を探します。 ここで、我々は実際に存在するトップレコードを見つけたいので、IDでソートしている(一方、乱数は削除されている可能性があります)かなり高速ですが、単一のランダムな行にのみ適しています。 10行欲しい場合は、このようなコードを10回呼び出す必要があります(または、10個の乱数を生成してIN句を使用します。ここに表示されているすべてについて、6 回の論理読み取りを行うだけで、ほぼ瞬時に終了します。

The plan that can
ひとつ問題があります。 (たとえば、ID フィールドを -1 で開始し、-1 をステップして、私のモラルのように常に下に向かうとします。)
Method 4, OFFSET-FETCH (2012+)
Daniel Hutmacher がコメントでこれを追加しました:
そして、「しかしそれはクラスター化インデックスでのみ適切に実行されます」と述べました。 これは、インデックス シークを行う代わりに、ヒープ内の (@rows) 行をスキャンするためだと思います」
Bonus Track #1。 私たちが議論しているところを見る
私たちの会社のチャット ルームにいるようなものだと思ったことはありませんか。 この 10 分間の Slack ディスカッションでは、かなり良いアイデアを得ることができます。
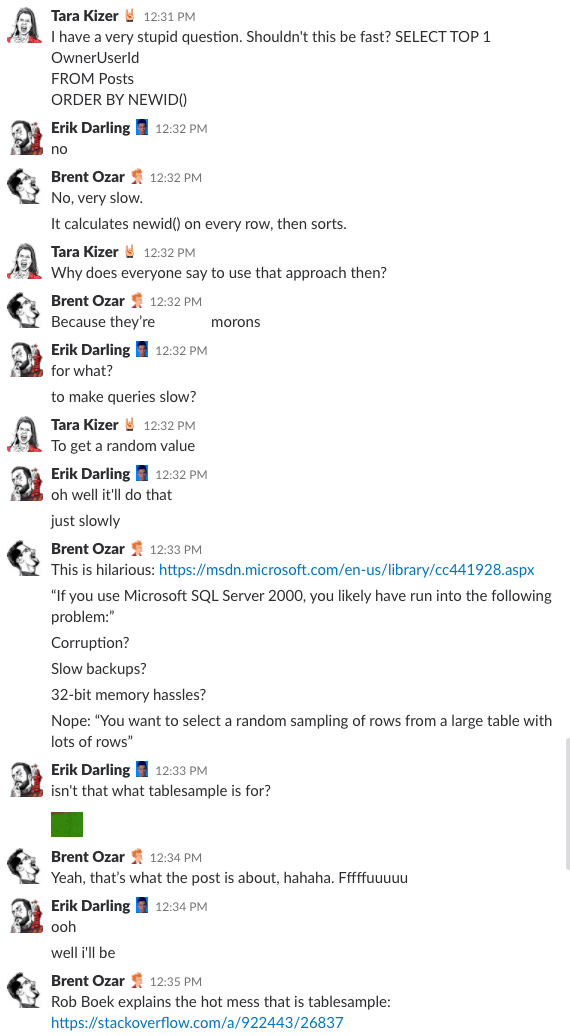
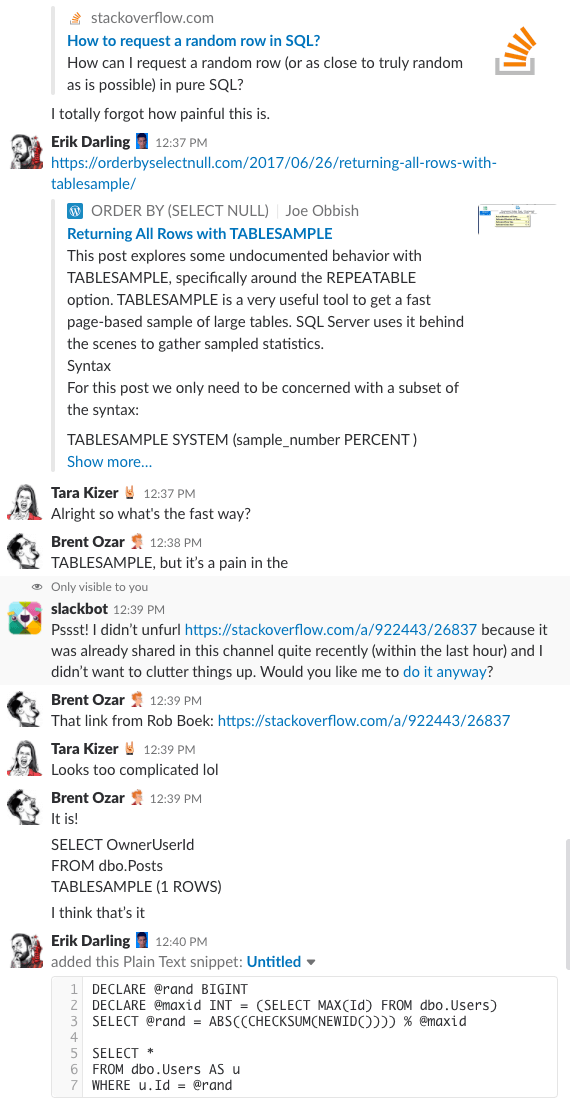
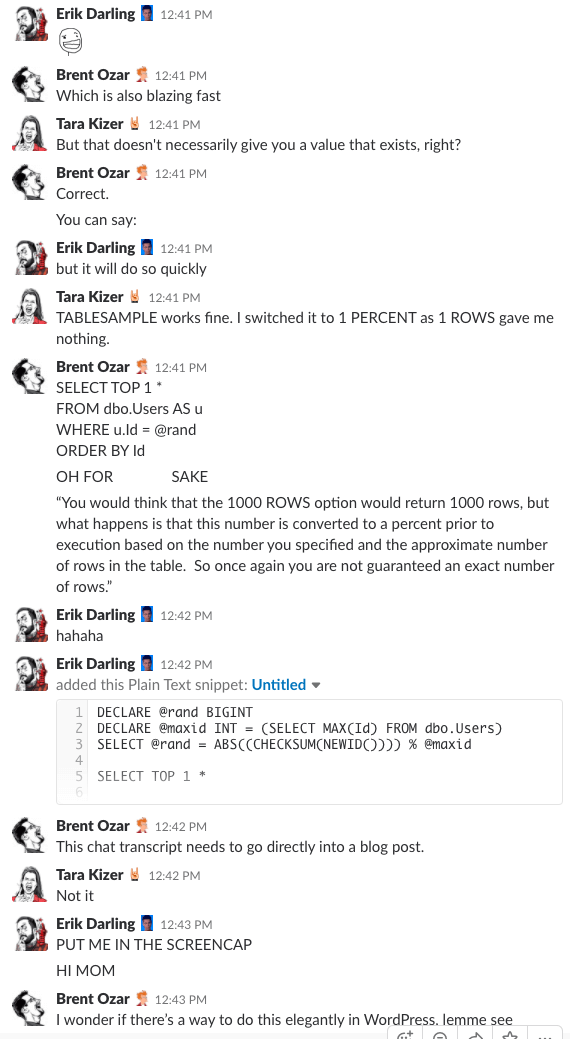
Spoiler alert: ありませんでした。 1214>
Bonus Track #2: Mitch Wheat Digs Deeper
いくつかの異なる技法のランダム性について、深く分析したいですか? Mitch Wheat は、グラフを使いながら、本当に深く掘り下げていきます!
。