上の画像で、この記事が何であるかは十分お分かりいただけたかと思います。
この投稿では、重要なファジー (正確に等しくないが、同じ文字列の塊、たとえば RajKumar & Raj Kumar) 文字列照合アルゴリズムをいくつか紹介します。
Hamming Distance
Levenstein Distance
Damerau Levenstein Distance
N-Gram based string matching
BK Tree
Bitap algorithm
しかし我々はまず、現実のシナリオを考えると、なぜファジーマッチが重要かを知るべきだろう。 ユーザーが何らかのデータを入力することが許可されている場合、次のケースのように本当に厄介なことになります!
Let,
- Your name is ‘Saurav Kumar Agarwal’.
- You have given a library card (with a Unique ID of course) which is valid for every member of your family.
- Iou go to library to issue some books every week.あなたは図書館へ行き、毎週数冊の本を発行しています。 しかしそのためには、まず図書館の入り口にある登録簿に、自分のID & 名を記入する必要があります。
さて、図書館当局はこの図書館登録簿のデータを分析し、毎月訪れる固有の読者の見当をつけることにします。 さて、これはいろいろな理由(土地を拡張するかどうか、本の数を増やすべきか、など)で行うことができます。
彼らはこれを、1ヶ月に登録された(固有名、図書館ID)ペアを数えることによって行うことを計画しました。
123 Mehul
123 Rajesh
123 Mehul
133 Rajesh
133 Sandesh
この場合、固有読者は4人となるはずです。
wooohhh!!!
Pretty bad estimate I must say !!!
or they missed a trick here?
After the deeper analysis, a major issue came up. あなたの名前、「Saurav Agarwal」を思い出してください。 彼らは、あなたのファミリー ライブラリ ID にわたって、5 人の異なるユーザーにつながるいくつかのエントリを発見しました。
- Saurav K Aggrawal (ダブル「g」、「ra-ar」に注目)。 KumarがKになる)
- Saurav Kumar Agarwal
- Sourav Aggarwal
- SK Agarwal
- Agarwal
図書館当局は
- あなたの家族から何人が図書館に来ているか知らないのであいまいな部分がある。 この5人の名前は、1人の読者なのか、2人、3人の読者なのか。 教師なし問題と呼ばれるもので、標準化されていない名前を表す文字列がありますが、標準化された名前は知られていません(例:Saurav Agarwal: Saurav Kumar Agarwal は知られていない)
- それらすべてを「Saurav Kumar Agarwal」にマージすべきでしょうか? SK Agarwal が Shivam Kumar Agarwal(あなたの父親の名前)であるかもしれませんから、そうとは言えません。
最後の2つのケース(SK Agarwal & Agarwal)は、読者の実際の名前を決定するために、いくつかの追加情報(性別、生年月日、出版物など)をMLアルゴリズムに供給する必要があります。
How can be done?
ここで、ファズ文字列マッチングが登場します。これは、「Agarwal」 & 「Aggarwal」 & 「Aggrawal」のように(主に間違ったスペルのために)互いにわずかに異なる文字列間でほぼ完全に一致することを意味します。 もし、許容範囲内の誤り率(例えば1文字違い)で文字列が得られたら、それを一致と見なすことになる。 それでは、→
ハミング距離とは、同じ長さの2つの文字列の間で計算される最も明白な距離で、与えられたインデックスに対応する一致しない文字の数を与えます。 例えば、’Bat’ & ‘Bet’ はインデックス 1 でハミング距離 1、’a’ は ‘e’ と等しくない
Levenstein Distance/ Edit Distance
Levenstein distance & Recursion はご存知かと思いますが、’Bat’ はインデックス 1 でハミング距離 2、’Bet’ はインデックス 3 でハミング距離 4 と等しいです。 そうでない場合は、これを読んでください。
Levenstein Distance は、’Str1′ を ‘Str2’ に変換するために、文字の追加、削除、または置換を行うのに必要な最小限の編集回数を計算します。 したがって、「Cat」&「Bat」の編集距離は「1」(「C」を「B」に置換)、「Ceat」&「Bat」の編集距離は「2」(「C」を「B」に置換、「e」を削除)である。
アルゴリズムについて説明すると、大きく分けて5つのステップがあります
int LevensteinDistance(string str1, string str2, int x, int y){if (x == len(str1)+1) return len(str2)-y+1;if (y == len(str2)+1) return len(str1)-x+1;if (str1 == str2)
return LevensteinDistance(str1, str2, x+ 1, y+ 1);return 1 + min(LevensteinDistance(str1, str2, x, y+ 1), #insert LevensteinDistance(str1, str2, x+ 1, y), #remove LevensteinDistance(str1, str2, x+ 1, y+ 1) #replace
}
LevenesteinDistance('abcd','abbd',1,1)
やっていることは、1文字目から文字列を読み始めることです
- str1 のインデックス ‘x’ の文字が str2 のインデックス ‘y’ の文字と一致したら、その文字に対応する文字列を読み始めます。 編集不要 &
LevensteinDistance(str1,str2)
- もし一致しなければ、編集が必要であることがわかる。 そこで現在のedit_distanceに+1する & 3つの条件に対して再帰的にedit_distanceを計算 & 3つのうち最小値を取る:
Levenstein(str1,str2) →str2 に挿入(Insertion).
Levenstein(str1,str2) →str2の削除
Levenstein(str1,str2)→str2 の置換
- recursion中にいずれかの文字が無くなったら、その文字列を削除。 もう一方の文字列の残りの文字数を編集距離に加える(1つ目のif文)
Demerau-Levenstein距離
‘abcd’ & ‘acbd’ を考慮する。 ルベンシュタイン距離でいくと、(str2のインデックス位置2 & 3にある’b’-‘c’ & ‘c’-‘b’ を置換)となるが、よく見るとstr1のように両方の文字が入れ替わっている & もし、「加算」「削除」&「置換」と一緒に新しい操作「スワップ」を導入したらこの問題を解決することができるだろう。
この操作は以下のコードで追加されます。
1 +
(x - last_matching_index_y - 1 ) +
(y - last_matching_index_x - 1 ) +
LevinsteinDistance(str1, str2)
ここで、
initial_x=1 & initial_y=1 (両方の文字列に0からではなく1からインデックス作成を開始)と仮定して、上記の操作を ‘abcd’ & ‘acbd’ に実行してみます。
current x=3 & y=3なので、str1 & str2 はそれぞれ ‘c’ (abcd) & ‘b’ (acbd) になります。
後述のスライス処理に含まれる上限値です。
- last_matching_index_y は str1 とマッチした str2 の last_index になります。つまり、2 が ‘acbd’ の ‘c’ (index 2) と ‘abcd’ の ‘c’ にマッチしました。
- last_matching_index_x は str1 とマッチした str2 の last_index になります。e 2 as ‘abcd’ (index 2)matched with ‘b’ in ‘acbd’.
- したがって、上記の疑似コードに従って、DemarauLevenstein(‘abc’,’acb’)=
1+(4-3-1) + (4-3-1)+LevensteinDistance(‘a’,’a’)=1+0+0+0=1. これはLevenstein Distance
N-Gram
N-gram とは、基本的には文字列から、連続して現れる「n」の文字/単語を対にして生成した値の集合にほかならない。 例えば、’abcd’ の n=2 の N-gram は ‘ab’,’bc’,’cd’ となる。
さて、これらの N-gram は類似性を測定する必要がある文字列に生成できる & 類似性の測定には、異なる測定基準を使用することが可能だ。
‘abcd’ & ‘acbd’ をマッチする2つの文字列とする。
‘abcd’=ab,bc,cd
‘acbd’=ac,cb,bd
成分マッチ (qgrams)
2文字で完全にマッチする n-grams 数を数える。 ここでは0
Cosine Similarity
文字列のn-gramをベクトルに変換してドットプロダクトを計算
Component match (no order considered)
bc=cb というように要素の順序を無視してn-gramの成分をマッチングする。
Jaccard distance や Tversky Index など、ここでは説明しないが、他にも多くのメトリクスが存在する。 BK ツリーは、
- レーベンシュタイン距離
- 三角不等式 (このセクションの最後で取り上げます)
を使って類似した文字列 (& 1 つの最適な文字列だけではない) を見つけ出すものである。 例えば、D={Book, Books, Cake, Boo, Boon, Cook, Cape, Cart} という辞書があるとする。
- ルートノード(任意の単語)を選択する。 これを「Books」とする
- 辞書Dのすべての単語Wを調べて、ルートノードとのレーベンシュタイン距離を計算し、親に対して同じレーベンシュタイン距離を持つ子が存在しなければ、その単語Wをルートの子にする。 Books & Cake.
Levenstein(Books,Book)=1 & Levenstein(Books,Cake)=4 と挿入する。 Book’に同じ距離の子が見つからなかったので、それらをrootの新しい子にする。
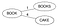
- もし親Pに対して同じレーベンシュタインの距離を持つ子供が存在するのなら。 Levenstein(parent, word) を計算し、親 P1 に対して同じ距離の子が存在しなければ、単語 W を P1 の新しい子とし、それ以外はツリーを下っていきます。
Booを挿入することを検討する。 Levenstein(Book, Boo)=1だが、同じ子、つまりBooksがすでに存在する。 よって、Levenstein(Books, Boo)=2を計算する。 Booksには同じ距離を持つ子が存在しないので、BooをBooksの子とします。

Similarly, BKツリーに辞書からすべての単語を挿入する

一度、BKツリーを準備したら、与えられた単語(クエリー単語)に対して類似単語を探すためには許容閾値を「t」に設定しなければなりません。
- これは、& query_wordのノード間の類似性を考慮する最大の編集距離である。
- また、親ノードの子ノードのうち、Levenstein(Child, Parent)が
以内にあるものだけをQueryとの比較対象として考慮する予定です。 27>
- もしこの条件が子について真であれば、
Levenshtein(Child, Query)≤t の場合、クエリと同様と見なされる Levenstein(Child, Query) を計算することになるでしょう。
- したがって、クエリ単語 & を含む辞書内のすべてのノード/単語に対してレーベンシュタイン距離を計算する必要がないため、単語のプールが巨大な場合
したがって、多くの時間を節約することができます。 ChildがQueryに似ている場合
- Levenstein(Parent, Query)-t ≦ Levenstein(Child,Parent) ≦ Levenstein(Parent,Query)+t
- Levenstein(Child,Query)≦t
早速例を見てみよう。 t’=1
類似語を探す必要がある単語を「Care」(Query word)
- Levenstein(Book,Care)=4 としてみます。 4>1なので、’Book’は棄却される。 ここで、’Book’の子で、LevisteinDistance(Child,’Book’)が3(4-1) & 5(4+1)のものだけを検討することにする。 したがって、’Book’ & の子には1が設定された限界にないので、すべて拒否することになります
- Levenstein(Cake, Book)=4 は3 & 5の間にあるので、≦1なので似た言葉として Levenstein(Cake, Care)=1 を確認することになります。
- 制限を再調整すると、Cakeの子供の場合、0(1-1) & 2(1+1)
- Cartの場合、Cape & 共にLevenstein(Child, Parent)=1 & 2なので、どちらも「ケア」でテストを受ける資格があると言えます。
- Levenstein(Cape,Care)=1 ≦1& Levenstein(Cart,Care)=2>1 なので、Capeだけが’Care’に類似した単語とみなされます。 Cake & Cape
しかし、子ノードの制限
Levenstein(Parent,Query)-t, Levenstein(Parent,Query)+t.
は何を基準に決定するのでしょう。
これは、
Distance(A,B) + Distance(B,C)≧Distance(A,C) (A,B,C は三角形の辺)という三角形の不等式から導かれます。
この考え方がどのようにこれらの限界に達するのに役立つのか、見てみましょう:
Query,=Q 親=P & 子=C と、Levenstein distanceをエッジ長として三角形を形成するとしましょう。 t’を許容閾値とする。 すると、上記の不等式
Levenstein(P,C) + Levenstein(P,Q)≥Levenstein(C,Q)as Levenstein(C, Q) can't exceed 't'(threshold set earlier for C to be similar to Q), HenceLevenstein(P,C) + Levenstein(P,Q)≥ t
OrLevenstein(P,C)≥|Levenstein(P,Q)-t| i.e the lower limit is setにより、三角形の不等式
Levenstein(P,Q) + Levenstein(C,Q) ≥ Levenstein(P,C) or
Levenstein(P,Q) + t ≥ Levenstein(P,C) or the upper limit is setBitap algorithm
これも非常に速いアルゴリズムで、かなり効率的にファジー文字列のマッチングに利用できる。 これはビット演算&を使用しているためで、かなり高速なアルゴリズムとして知られています。
S0=’ababc’ を文字列 S1=’abdabababc’ とマッチングするパターンとします。
まず、
- S1 & S0 で a,b,c,d であるすべての固有の文字を探します
- 各文字に対してビットパターンを形成してください。 どうやって?

- 検索するパターンS0を反転する
- 文字xのビットパターンはパターン中で発生するところに0を置きそれ以外は1にします。
同様に、辞書の異なる文字に対して他のすべてのビットパターンを形成する。
S0=ababc S1=abdabababc
- すべて1のビットパターンの初期状態をとります。
- S1で検索を開始し、任意の文字を通過したら、
Sの最下位ビット、つまり右から5ビット目に0をシフトする &
SとTのOR演算を行う。
したがって、S1で1番目の’a’に遭遇するので、
- Sの最下位ビットに0を左シフトして11111 →11110
- 11010 | 11110=11110
さて、2番目の文字’b’に移るとき
- S iに0シフトしてください。eから11110 →11100
- S |T=11100 | 10101=11101
‘d’に遭遇したので
- Sに0シフトして11101 →11010
- S |T=11010 |111=11111
‘d’ がS0に入っていないのでS状態はリセットされていることに注意すること。 S1全体を走査すると、各文字で以下の状態になります。

どうすれば、ファジー/フルマッチを見つけたかどうかがわかりますか。
- 状態Sのビットパターンの最上位ビットに0があれば(最後の文字「c」のように)完全一致です
- ファズ一致の場合、状態Sの異なる位置の0を観察します。 0が4位にある場合、S0と同じ配列の文字が4/5個見つかったことになります。
一つ、これらのアルゴリズムはすべて文字列のスペルの類似性で動作することがお分かりいただけたかと思います。 ファジーマッチングに他の基準はあるのでしょうか。 はい、
Phonetics
次は音声学(Saurav & Sourav のように音声学で完全に一致する必要がある)ベースのファジーマッチのアルゴリズムに取り組みます!
- Dimension Reduction (3 parts)
- NLP Algorithms(5 parts)
- Reinforcement Learning Basics (5 parts)
- Starting off with Time-
- NLP Algorithms (5 parts)
- NLPアルゴリズム(3 parts)
- NLPアルゴリズム(5 parts)シリーズ(全7回)
- YOLOを使った物体検出(全3回)
- 初心者のためのTensorflow(コンセプト+サンプル)(全4回)
- 時系列の前処理(コード付き)
- 初心のためのデータ解析
- 初心のための統計(全4回)