- A função e sua derivada são ambas monotônicas
- O rendimento é zero “cêntrico”
- Otimização é mais fácil
- Derivado/Diferencial da função Tanh (f'(x)) ficará entre 0 e 1.
Cons:
- Derivante da função Tanh sofre de “Vanishing gradient and Exploding gradient problem”.
- Slow convergence- as its computationally heavy.(Motivo do uso da função matemática exponencial )
“Tanh é preferível à função sigmóide uma vez que é zero centrado e os gradientes não estão restritos a mover-se numa determinada direcção”
3. Função ReLu Activation(ReLu – Unidades Lineares Rectificadas):


>
ReLU é a função de ativação não-linear que ganhou popularidade na IA. A função ReLu também é representada como f(x) = max(0,x).
- A função e sua derivada são ambas monotônicas.
- Vantagem principal de usar a função ReLU- Não ativa todos os neurônios ao mesmo tempo.
- Computacionalmente eficiente
- Derivado/Diferencial da função Tanh (f'(x)) será 1 se f(x) > 0 mais 0.
- Converge muito rápido
Cons:
- Função ReLu em não “zero-centric”.Isto faz com que as atualizações de gradiente vão muito longe em diferentes direções. 0 < saída < 1, e torna a optimização mais difícil.
- Neurônio morto é o maior problema. Isto é devido ao Não-diferenciável em zero.
“Problema do neurônio morto/neurônio morto : Como a derivada ReLu f'(x) não é 0 para os valores positivos do neurônio (f'(x)=1 para x ≥ 0), ReLu não satura (exploid) e nenhum neurônio morto (neurônio desaparecido)é relatado. Saturação e gradiente de fuga só ocorrem para valores negativos que, dados a ReLu, são transformados em 0- Isto é chamado de problema de neurônio moribundo”
4. Função de ativação de ReLu vazante:
Leaky função ReLU não é mais que uma versão melhorada da função ReLU com introdução de “inclinação constante”


- Leaky ReLU é definido para resolver o problema do neurónio/neurónio morto.
- Problema de neurônio/neurônio morto é abordado através da introdução de uma pequena inclinação com os valores negativos escalados por α permite que seus neurônios correspondentes “permaneçam vivos”.
- A função e sua derivada são ambas monotônicas
- Permite valor negativo durante a propagação de retorno
- É eficiente e fácil de calcular.
- Derivado de Vazamento é 1 quando f(x) > 0 e varia entre 0 e 1 quando f(x) < 0.
Cons:
- Leaky ReLU não fornece previsões consistentes para valores de entrada negativos.
5. ELU (Exponential Linear Units) Função de ativação:

- ELU também é proposto para resolver o problema do neurónio moribundo.
- Não há problemas de ReLU morto
- Zero-cêntrico
Cons:
- Computativamente intensivo.
- Similiar ao ReLU vazado, embora teoricamente melhor que o ReLU, não há atualmente nenhuma boa evidência na prática de que o ELU é sempre melhor que o ReLU.
- f(x) só é monotônico se o alfa for maior ou igual a 0.
- f'(x) derivado de ELU é monotônico somente se o alfa estiver entre 0 e 1,
- Baixa convergência devido à função exponencial.
6. P ReLu (ReLU Paramétrica) Função de ativação:

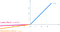
>
- A ideia de fuga de ReLU pode ser ainda mais alargada.
- Em vez de multiplicar x com um termo constante, podemos multiplicá-lo com um “hiperparâmetro (parâmetro a-treinável)” que parece funcionar melhor o ReLU com fugas. Esta extensão para ReLU vazante é conhecida como ReLU Paramétrico.
- O parâmetro α é geralmente um número entre 0 e 1, e é geralmente relativamente pequeno.
- Dispor de ligeira vantagem sobre a Relu vazante devido ao parâmetro treinável.
- Pega o problema do neurônio moribundo.
Cons:
- O mesmo que Relu com fugas.
- f(x) é monotónico quando a> ou =0 e f'(x) é monotónico quando a =1
7. Swish (A Self-Gated) Função de ativação:(Sigmoid Linear Unit)

- Google Brain Team propôs uma nova função de ativação, chamada Swish, que é simplesmente f(x) = x – sigmoid(x).
- As suas experiências mostram que o Swish tende a funcionar melhor do que o ReLU em modelos mais profundos através de vários conjuntos de dados desafiantes.
- A curva da função Swish é suave e a função é diferenciável em todos os pontos. Isto é útil durante o processo de otimização do modelo e é considerado como uma das razões que fazem com que o swish tenha um desempenho superior ao do ReLU.
- A função Swish não é “monotônica”. Isto significa que o valor da função pode diminuir mesmo quando os valores de entrada estão aumentando.
- Função não é limitada acima e é limitada abaixo.
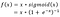
“Swish tende a igualar ou superar continuamente o ReLu”
Nota que a saída da função swish pode cair mesmo quando a entrada aumenta. Este é um recurso interessante e específico do Swish (devido ao caráter não-monotônico)
f(x)=2x*sigmoid(beta*x)
Se acharmos que beta=0 é uma versão simples do Swish, que é um parâmetro aprendível, então a parte sigmoid é sempre 1/2 e f (x) é linear. Por outro lado, se o beta é um valor muito grande, o sigmóide torna-se uma função de quase dois dígitos (0 para x<0,1 para x>0). Assim f (x) converge para a função ReLU. Portanto, a função Swish padrão é selecionada como beta = 1. Desta forma, é fornecida uma interpolação suave (associando os conjuntos de valores variáveis com uma função no intervalo dado e a precisão desejada). Excelente! Uma solução para o problema do desaparecimento dos gradientes foi encontrada.
8.Softplus
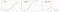
A função softplus é semelhante à função ReLU, mas é relativamente mais suave.Função Softplus ou SmoothRelu f(x) = ln(1+exp x).
Derivado da função Softplus é f'(x) é função logística (1/(1+exp x)).
Valor da função (0, + inf).Ambos f(x) e f'(x) são monotônicos.
9.Softmax ou função exponencial normalizada:

A função “softmax” também é um tipo de função sigmóide, mas é muito útil para lidar com problemas de classificação multi-classe.
“Softmax pode ser descrito como a combinação de função sigmóide múltipla.”
“A função Softmax retorna a probabilidade de um datapoint pertencente a cada classe individual.”
> Enquanto se constrói uma rede para um problema de múltiplas classes, a camada de saída teria tantos neurônios quanto o número de classes no alvo.
>Por exemplo, se você tiver três classes, haveria três neurônios na camada de saída. Suponha que você obteve o output dos neurônios como .Aplicando a função softmax sobre esses valores, você obterá o seguinte resultado – . Estes representam a probabilidade para o ponto de dados pertencente a cada classe. Do resultado podemos concluir que o input pertence à classe A.
“Note que a soma de todos os valores é 1.”
Qual é melhor usar ? Como escolher um certo?
Para ser honesto, não há nenhuma regra difícil e rápida para escolher a função de ativação. Não podemos diferenciar entre função de ativação. Cada função de ativação como seus próprios pro e con. Todos os bons e ruins serão decididos com base na trilha.
Mas com base nas propriedades do problema poderemos fazer uma melhor escolha para uma fácil e rápida convergência da rede.
- As funções Sigmoid e suas combinações geralmente funcionam melhor no caso de problemas de classificação
- As funções Sigmoid e Tanh às vezes são evitadas devido ao problema de gradiente de fuga
- A função de ativação da ReLU é amplamente utilizada na era moderna.
- Em caso de neurónios mortos nas nossas redes devido a ReLu então a função ReLU com fugas é a melhor escolha
- A função ReLU só deve ser usada nas camadas ocultas
“Como regra geral, pode-se começar por usar a função ReLU e depois passar para outras funções de activação no caso da função ReLU não fornecer resultados óptimos”