Revisado: 11 de dezembro de 2020
Os sujeitos dizem a verdade?
A confiabilidade dos dados de auto-relato é um calcanhar de Aquiles da pesquisa de pesquisa. Por exemplo, pesquisas de opinião indicam que mais de 40 por cento dos americanos freqüentam a igreja toda semana. Entretanto, ao examinar os registros de comparecimento à igreja, Hadaway e Marlar (2005) concluíram que o comparecimento real era inferior a 22 por cento. Em seu trabalho seminal “Todo mundo mente”, Seth Stephens-Davidowitz (2017) encontrou amplas evidências para mostrar que a maioria das pessoas não faz o que dizem e não dizem o que fazem. Por exemplo, em resposta às sondagens, a maioria dos eleitores declarou que a etnia do candidato não é importante. No entanto, ao verificar os termos de pesquisa no Google Sephens-Davidowitz encontrou o contrário. Especificamente, quando os utilizadores do Google introduziram a palavra “Obama”, eles sempre associaram o seu nome com algumas palavras relacionadas com a raça.
Para pesquisas sobre instruções baseadas na web, os dados de uso da web podem ser obtidos analisando o log de acesso do usuário, configurando cookies, ou fazendo upload do cache. No entanto, estas opções podem ter uma aplicabilidade limitada. Forexample, o log de acesso do usuário não pode rastrear usuários que seguem links para outros sites. Além disso, as abordagens de cookies ou cache podem levantar questões de privacidade. Nessas situações, os dados auto-reportados coletados por pesquisas são utilizados. Isto dá origem à pergunta: Quão precisos são os dados auto-reportados? Cook e Campbell (1979) apontaram que os sujeitos (a) tendem a relatar o que acreditam que o pesquisador espera ou (b) relatam o que reflete positivamente sobre suas próprias habilidades, conhecimentos, crenças ou opiniões. Outra preocupação sobre tais centros de dados é se os sujeitos são capazes de lembrar com precisão os comportamentos passados. Os psicólogos alertaram que a memória humana é falível (Loftus, 2016; Schacter, 1999). Às vezes as pessoas “lembram-se” de eventos que nunca aconteceram. Assim a confiabilidade dos dados auto-reportados é tênue.Embora os pacotes de software estatísticos sejam capazes de calcular números até 16-32 decimais, esta precisão não tem sentido se os dados não puderem ser precisos mesmo no nível inteiro. Alguns estudiosos haviam alertado os pesquisadores sobre como o erro de medida poderia prejudicar a análise estatística (Blalock, 1974) e sugeriram que uma boa prática de pesquisa requer o exame da qualidade dos dados coletados (Fetter,Stowe, & Owings, 1984).
Bias e Variância
Erros de medida incluem dois componentes, a saber, viés e erro variável.viés é um erro sistemático que tende a empurrar as pontuações relatadas para um extremo. Por exemplo, várias versões de testes de QI são encontradas para serem enviesadas contra não-Brancos. Isto significa que negros e hispânicos tendem a receber pontuações mais baixas, independentemente da sua inteligência real. O erro avariável, também conhecido como variância, tende a ser aleatório. Em outras palavras, as pontuações relatadas podem estar acima ou abaixo das pontuações reais (Salvucci, Walter, Conley, Fink, & Saba, 1997).
Os achados desses dois tipos de erros de medida têm aplicações diferenciadas. Por exemplo, em um estudo comparando dados auto-relatados de altura e peso com dados medidos diretamente (Hart & Tomazic, 1999), constatou-se que os sujeitos tendem a sobre-relatar sua altura, mas sub-relatam seu peso. Obviamente, este tipo de padrão de erro é mais isbias do que variâncias. Uma possível explicação deste viés é que a maioria das pessoas quer apresentar uma melhor imagem física aos outros. No entanto, se o erro de medida for aleatório, a explicação pode ser mais complicada.
Uma pessoa pode argumentar que erros variáveis, que são aleatórios por natureza, poderiam cancelar uns aos outros e, portanto, não ser uma ameaça para o estudo. Forexample, o primeiro usuário pode superestimar suas atividades na Internet em 10%, mas o segundo usuário pode subestimar as dela em 10%. Neste caso, a média ainda pode estar correta. No entanto, a sobre-estimativa e a subestimativa aumentam a variabilidade da distribuição. Em testes maniparamétricos, a variabilidade dentro do grupo é usada como termo de erro. Uma variabilidade inflada afetaria definitivamente o significado do teste. Alguns textos podem reforçar a concepção acima. Por exemplo, Deese (1972) disse,
A teoria estatística diz-nos que a tereliabilidade das observações é proporcional à raiz quadrada do seu número. Quanto mais observações houver, mais influências aleatórias existirão. E a teoria estatística sustenta que quanto mais erros aleatórios houver, mais provavelmente eles se cancelarão e produzirão distribuição anormal (p.55).
Primeiro, é verdade que à medida que o tamanho da amostra aumenta a variância da distribuição diminui, isso não garante que a forma da distribuição se aproximaria da normalidade. Em segundo lugar, a confiabilidade (a qualidade dos dados) deve ser ligada à medição e não à determinação do tamanho da amostra. Um grande tamanho de amostra com muitos erros de medida, mesmo erros aleatórios, inflaria o termo de erro para testes paramétricos.
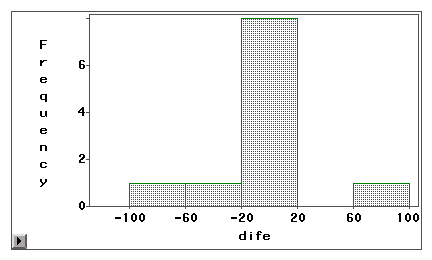
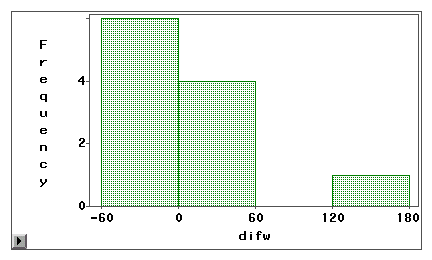
Um gráfico de haste e folha ou um histograma pode ser usado para examinar visualmente se um erro de medida é devido a um viés sistemático ou variância aleatória. No exemplo a seguir, dois tipos de acesso à Internet (navegação na Web e e-mail) são medidos tanto por pesquisa auto-reportada quanto por logbook. As pontuações das diferenças (medida 1 – medida 2) são plotadas nos seguintes histogramas.
O primeiro gráfico revela que a maioria das pontuações das diferenças está centrada em torno de zero. A sub e sobre-reportagem aparece perto de ambas as extremidades sugerindo que o erro de medição é aleatório e não sistemático.
O segundo gráfico indica claramente que existe um elevado grau de erros de medição porque muito poucas pontuações de diferença estão centradas em torno de zero. Além disso, a distribuição é enviesada negativamente e o erro é enviesado em vez de variância.
Quão fiável é a nossa memória?
Schacter (1999) avisou que a memória humana é falível. Existem sete falhas na nossa memória:
- Transiência: Diminuindo a acessibilidade da informação ao longo do tempo.
- Ausência de mentalidade: Processamento desatento ou superficial que contribui para memórias fracas.
- Bloqueio: A inacessibilidade temporária da informação que é armazenada na memória.
- Má atribuição Atribuição de uma lembrança ou ideia à fonte errada.
- Suggestibilidade: Memórias que são implantadas como resultado de perguntas ou expectativas.
- Viés: Distorções retrospectivas e influências inconscientes que estão relacionadas ao conhecimento e crenças atuais.
- Persistência: Memórias patológicas – informações ou eventos que não podemos esquecer, mesmo que desejássemos.
 |
“Eu tenho norecolha destes. Não me lembro de ter assinado o documento paraWhitewater. Não me lembro porque o documento desapareceu, mas reapareceu mais tarde. Não me lembro de nada.” “Lembro-me de pousar (na Bósnia) sob fogo de atirador furtivo. Era suposto haver algum tipo de cerimônia de saudação no aeroporto, mas em vez disso corremos com a cabeça baixa para entrar nos veículos para chegar à nossa base.” Durante a investigação do envio de informações confidenciais via servidor de e-mail apessoal, Clinton disse ao FBI que ela não podia “lembrar” ou “lembrar” nada 39 vezes. Cautela: Um novo vírus de computador chamado “Clinton” é descoberto. Se o computador estiver infectado, esta mensagem aparecerá com frequência ‘fora da memória’, mesmo que tenha aRAM adequada. |
| P: “Se Vernon Jordon nos tivesse dito que você tem uma memória extraordinária, uma das maiores memórias que ele já viu num político, isso seria algo que você se importaria de disputar?”
A: “Eu tenho uma boa memória… Mas Idon não se lembra se eu estava sozinho com Monica Lewinsky ou não. Como eu poderia acompanhar tantas mulheres na minha vida?” Q: Por que Clinton recomendou Lewinsky para um trabalho na Revlon? A: Ele sabia que ela seria boa a inventar coisas. |
 |
É importante notar que algumas vezes a confiabilidade da nossa memória está ligada à conveniência do resultado. Por exemplo, quando um investigador médico tenta recolher dados relevantes de mães cujos bebés são saudáveis e de mães cujos filhos são malformados, os dados destes últimos são geralmente mais precisos do que os dos primeiros. Isto porque as mães de bebés malformados têm revisto cuidadosamente cada doença que ocorreu durante a gravidez, cada droga tomada, cada detalhe directa ou remotamente relacionado com a tragédia, numa tentativa de encontrar uma explicação. Pelo contrário, as mães de bebês saudáveis não prestam muita atenção às informações anteriores (Aschengrau & SeageIII, 2008). O GPA inflante é outro exemplo de como a precisão da memória e a integridade dos dados são afetadas pelo desirabilityaffects. Em alguma situação há uma diferença de gênero na inflação do GPA. Um estudo conduzido por Caskie etal. (2014) descobriu que dentro do grupo de alunos de graduação com menor GPA, as mulheres eram mais propensas a relatar um GPA maior do que os homens.
Para neutralizar o problema dos erros de memória, alguns pesquisadores pesquisaram coletando dados relacionados ao pensamento ou sentimento momentâneo do participante, ao invés de pedir que ele ou ela se lembrasse de eventos remotos (Csikszentmihalyi & Larson, 1987; Finnigan & Vazire,2018). Os seguintes exemplos são itens da pesquisa em 2018 Programa de Avaliação Internacional do Estudante: “Você foi tratado com respeito todo o dia de ontem?” “Você sorriu ou riu muito ontem?” “Você aprendeu ou fez algo interessante ontem?” (Organização para a Cooperação Econômica e Desenvolvimento, 2017). No entanto, o responsável depende do que aconteceu ao participante em torno daquele momento em particular, o que pode não ser típico. Especificamente, mesmo que o responsável não tenha sorrido ou rido muito ontem, isso não implica necessariamente que o respondente esteja sempre infeliz.
O que devemos fazer?
Alguns pesquisadores rejeitam o uso de dados auto-relatados devido à sua suposta qualidade pobre. Por exemplo, quando um grupo de pesquisadores investigou se a alta religiosidade levou a uma menor adesão a abrigos nos EUA durante a pandemia da COVID19 , eles usaram o número de congregações por 10.000 residentes como uma medida aproximada da religiosidade da região, em vez da religiosidade auto-relatada, que tende a torrefletir o desejo social (DeFranza, Lindow, Harrison, Mishra, &Mishra, 2020).
No entanto, Chan (2009) argumentou que a chamada má qualidade dos dados auto-relatados nada mais é do que uma lenda urbana. Impulsionados pelo desejo social, os entrevistados podem fornecer aos pesquisadores dados imprecisos em algumas ocasiões, mas isso não acontece o tempo todo. Por exemplo, é improvável que os respondentes mintam sobre seus dados demográficos, como gênero e etnia. Segundo, embora seja verdade que os respondentes tendem a falsificar suas respostas em estudos experimentais, esta questão é menos séria nas medidas usadas em estudos de campo e cenários naturalistas. Além disso, existem inúmeras medidas bem estabelecidas de diferentes construções psicológicas, as quais têm obtido evidência de validade através de validação convergente e discriminante. Por exemplo, os traços de personalidade Big-five, personalidade proativa, disposição afetiva, auto-eficácia, orientações de metas, apoio organizacional percebido, e muitos outros.No campo da epidemiologia, Khoury, James e Erickson (1994) afirmaram que o efeito do viés de recall é superestimado. Mas sua conclusão pode não ser bem aplicada a outros campos, tais como educação e psicologia. Apesar da ameaça de imprecisão de dados, é impossível para o pesquisador acompanhar cada assunto com uma filmadora e registrar tudo o que ele faz. No entanto, o pesquisador pode utilizar um subconjunto de sujeitos para obter dados observados, como o acesso ao log de usuário ou o log diário de acesso à web em papel. Por exemplo,
- Quando o log de acesso do usuário está disponível para o pesquisador, ele pode pedir aos sujeitos para relatar a frequência do seu acesso ao servidor web.
- O pesquisador pode pedir a um subconjunto de usuários para manter um livro de registro de suas atividades na Internet por um mês. Em seguida, os mesmos usuários são solicitados a preencher uma pesquisa sobre o seu uso da web.
Algém pode argumentar que a abordagem do logbook é demasiado exigente. De facto, em muitos estudos de investigação científica, pede-se muito mais aos sujeitos do que isso. Por exemplo, quando os cientistas estudaram como o sono profundo durante as viagens espaciais ao longo do espaço afectaria a saúde humana, os participantes foram convidados a deitar-se na cama durante um mês. Em um estudo sobre como um ambiente fechado afeta a psicologia humana durante as viagens espaciais, os sujeitos também foram trancados em um quarto individualmente por um mês. O custo de uma semana de verdades científicas é elevado.
Após diferentes fontes de dados serem coletadas, a discrepância entre o registro e os dados auto-relatados pode ser analisada para estimar a confiabilidade dos dados. À primeira vista, esta abordagem parece ser um teste de retestreabilidade, mas não é. Primeiro, na confiabilidade do test-retest o instrumento utilizado em duas ou mais situações deve ser o mesmo. Segundo, quando a confiabilidade do test-retest é baixa, a fonte de erros está com o instrumento. Entretanto, quando a fonte de erros é externa ao instrumento, como erros humanos, a confiabilidade entre avaliadores é mais apropriada.
O procedimento sugerido acima pode ser conceituado como uma medida de confiabilidade de dados entre avaliadores, que se assemelha à confiabilidade entre avaliadores e medidas repetidas. Existem quatro formas de estimar a confiabilidade entre os interatores, a saber, coeficiente Kappa, Índice de Inconsistência, medidas repetidas ANOVA e análise de regressão. A seção seguinte descreve como essas medidas de confiabilidade entre avaliadores podem ser usadas como medidas de confiabilidade entre dados.
Coeficiente Kappa
Na pesquisa psicológica e educacional, não é incomum empregar dois ou mais avaliadores no processo de medição de temas quando a avaliação envolve julgamentos subjetivos (por exemplo, ensaios de classificação). A confiabilidade entre avaliadores, que é medida pelo coeficiente Kappa, é usada para indicar a confiabilidade dos dados. Por exemplo, o desempenho dos participantes é classificado por dois ou mais avaliadores como “mestre” ou “não mestre” (1 ou 0). Assim, esta medida é normalmente computada em procedimentos de análise de dados categóricos como PROC FREQ em SAS, “medição de concordância” em SPSS, ou calculadora anonline Kappa (Lowry, 2016). A imagem abaixo é uma imagem da calculadora online Vassarstats.
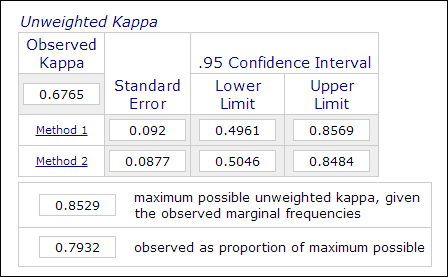
É importante notar que mesmo que 60% de dois conjuntos de dados concordem um com o outro, isso não significa que as medições sejam confiáveis. O coeficiente Kappa leva isso em conta e exige um maior grau de correspondência para atingir a consistência.
No contexto da instrução baseada na Web, cada categoria do uso do próprio site pode ser recodificada como uma variável binária. Forexample, quando a pergunta um é “quantas vezes você usa telnet”, as respostas categóricas possíveis são “a: diariamente”, “b: três a cinco vezes por semana”, “c: três a cinco vezes por mês”, “d: raramente”, e “e:nunca”. Neste caso, as cinco categorias podem ser recodificadas em cinco variáveis: Q1A, Q1B, Q1C, Q1D, e Q1E. Com esta estrutura de dados, as respostas podem ser codificadas como “1” ou “0” e assim é possível a medição do acordo de classificação. A concordância pode ser calculada usando o coeficiente Kappa e assim a confiabilidade dos dados pode ser estimada.
Subjectos Dados do livro de registo Self.dados do relatório Subjecto 1 1 1 Subjecto 2 0 0 Subjecto 3 1 0 Subjunto 4 0 1 Indice de Inconsistência
Outra forma de calcular os dados categóricos acima mencionados é o Índice de Inconsistência (IOI). No exemplo acima, como existem duas medidas (log e dados auto-reportados) e cinco opções na resposta, uma tabela de 4 X 4 é formada. O primeiro passo para calcular a IOI é dividir a tabela RXC em várias sub-mesas 2X2. Por exemplo, a lastocepção “nunca” é tratada como uma categoria e todas as restantes são agrupadas noutra categoria como “nunca”, como mostra a tabela que se segue.
Self…dados reportados Log Nunca Nunca Total Nunca a b a+b Não Nunca c d c+d c+d Total a+c b+d n=Soma(a-d) A percentagem de IOI é calculada através da seguinte fórmula:
IOI% = 100*(b+c)/ onde p = (a+c)/n
Após o IOI ser calculado para cada 2X2 sub-mesa, uma média de todos os índices é usada como indicador da inconsistência da medida. O critério para julgar se os dados são consistentes é o seguinte:
- Uma IOI inferior a 20 é baixa variância
- Uma IOI entre 20 e 50 é moderada
- Uma IOI acima de 50 é alta variância
A confiabilidade dos dados é expressa nesta equação: r = 1 – IOI
Coeficiente de correlação da classe interna
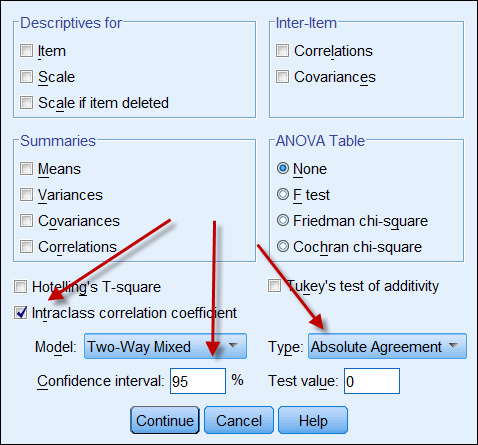
Se ambas as fontes de dados produzem dados contínuos, então pode-se calcular o coeficiente de correlação da classe interna para indicar a confiabilidade dos dados. A seguir, uma captura de tela das opções ICC do SPSS. Em Typethere estão duas opções: “consistência” e “concordância absoluta”. Se “consistência” for escolhida, então mesmo que um conjunto de números seja consistente (por exemplo 9, 8, 9, 8, 7…) e o outro seja consistência baixa (por exemplo 4,3, 4, 3, 2…), a sua forte correlação não significa que os dados estão alinhados uns com os outros. Portanto, é aconselhável escolher “acordo absoluto”.
Medidas repetidas
A medida de confiabilidade entre dados também pode ser conceitualizada e processada como umaANOVA de medidas repetidas. Numa ANOVA de medidas repetidas, as medidas são dadas aos mesmos sujeitos várias vezes, como pré-teste, meio-termo e pós-teste. Neste contexto, os sujeitos também são medidos repetidamente pelo log de usuário da web, o livro de registro e o questionário auto-reportado. O seguinte é o código SAS para uma ANOVA de medidas repetidas:
data one; input user $ web_log log_book self_report;
cards;
1 215 260 200
2 178 200 150
3 100 111 120
4 135 172 100
5 139 150 140
6 198 200 230
7 135 150 180
8 120 110 100
9 289 276 300
proc glm;
classes user;
model web_log log_book self_report = user;
repeated time 3;
run;
No programa acima, o número de websites visitados por nove voluntários é registrado no log de acesso do usuário, no livro de registro pessoal e na pesquisa auto-reportada. Os usuários são tratados como um fator entre-subjetos, enquanto as três medidas são consideradas como fator entre-medidas. O seguinte é uma saída condensada:
Fonte de variação DF Quadrado do Método Entre-subject (utilizador) 8 10442.50 Entre-medida (tempo) 2 488.93 Residual 16 454.80 Com base nas informações acima, o coeficiente de confiabilidade pode ser calculado usando esta fórmula (Fisher, 1946; Horst, 1949):
r = MSbetween-medida – MSresidual ————————————————————– MSbetween-medida + (dfbetween-people X MSresidual) Ponhamos o número na fórmula:
r = 488.93 – 454,80 ————————————— 488,93 + ( 8 X 454,80) A fiabilidade é de cerca de .0008, o que é extremamente baixo. Portanto, wecan ir para casa e esquecer os dados. Felizmente, é apenas um conjunto de dados hipotéticos. Mas, e se for um conjunto de dados real? Você tem que ser duro o suficiente para desistir de dados pobres em vez de publicar algumas conclusões que não são totalmente confiáveis.
Análise de correlação e regressão
Análise de correlação, que utiliza o produto Pearson Momentcoeficiente, é muito simples e especialmente útil quando as escalas de duas medidas não são as mesmas. Por exemplo, o log do servidor web pode rastrear o número de acessos de páginas enquanto os dados auto-reportados são escalonados por um clique (por exemplo, com que frequência você navega na Internet? 5=muito frequentemente,4=frequentemente, 3=sempre, 2=sempre, 5=nunca). Neste caso, os próprios resultados relatados podem ser usados como um preditor para retroceder em relação ao acesso à página.
Uma abordagem semelhante é a análise de regressão, na qual um conjunto de pontuações (por exemplo, dados da pesquisa) é tratado como o preditor enquanto outro conjunto de pontuações (por exemplo, log diário do usuário) é considerado a variável dependente. Se mais de duas medidas forem empregadas, um modelo de regressão múltipla pode ser aplicado, ou seja, aquele que produz resultados mais precisos (por exemplo, log de acesso do usuário à Web) é considerado como a variável dependente e todas as outras medidas (por exemplo, log diário do usuário, dados da pesquisa) são tratadas como variáveis independentes.
Referência
- Aschengrau, A., & Seage III, G. (2008). Aspectos essenciais da epidemiologia em saúde pública. Boston, MA: Jones e Bartlett Publishers.
- Blalock, H. M. (1974). (Ed.) Measurement in the social sciences: Teorias e estratégias. Chicago, Illinois: Aldine Publishing Company.
- Caskie, G. I. L., Sutton, M. C., & Eckhardt, A. G.(2014). Precisão da auto-relatação do GPA universitário: Diferenças moderadas de género por nível de desempenho e auto-eficácia académica. Journal of College Student Development, 55, 385-390. 10.1353/csd.2014.0038
- Chan, D. (2009). Então, por que me perguntar? Os dados do self report são realmente tão ruins assim? Em Charles E. Lance e Robert J. Vandenberg (Eds.), mitos estatísticos e metodológicos e lendas urbanas: Doutrina, veridade e fábula nas ciências organizacionais e sociais (pp309-335). Nova York, NY: Routledge.
- Cook, T. D., & Campbell, D. T. (1979). Quase-experimentação: Questões de design e análise. Boston, MA: Houghton Mifflin Company.
- Csikszentmihalyi, M., & Larson, R. (1987). Validade e confiabilidade do método de amostragem por experiência. Journal of Nervous and Mental Disease, 175, 526-536. https://doi.org/10.1097/00005053-198709000-00004
- Deese, J. (1972). Psicologia como ciência e arte. Nova York, NY: Harcourt Brace Jovanovich, Inc.
- DeFranza, D., Lindow, M., Harrison, K., Mishra, A., &Mishra, H. (2020, 10 de agosto). Religião e reações às diretrizes da COVID-19mitigation. Psicólogo Americano. Publicação online avançada. http://dx.doi.org/10.1037/amp0000717.
- Fetters, W., Stowe, P., & Owings, J. (1984). High School and Beyond. Um estudo longitudinal nacional para a década de 1980, qualidade das respostas dos alunos do ensino médio aos itens do questionário. (NCES 84-216).Washington, D. C.: Departamento de Educação dos EUA. Office of EducationalResearch and Improvement (Escritório de Pesquisa e Melhoramento Educacional). National Center for Education Statistics.
- Finnigan, K. M., & Vazire, S. (2018). Avalidade incremental dos auto-relatos estaduais médios em relação aos auto-relatos globais de personalidade. Journal of Personality and Social Psychology, 115, 321-337. https://doi.org/10.1037/pspp0000136
- Fisher, R. J. (1946). Métodos estatísticos para trabalhadores de pesquisa (10ª ed.). Edinburgh, UK: Oliver and Boyd.
- Hadaway, C. K., & Marlar, P. L. (2005). Quantos Americanos freqüentam o culto a cada semana? Uma abordagem alternativa para a adoração? Journal for the Scientific Study of Religion, 44, 307-322. DOI: 10.1111/j.1468-5906.2005.00288.x
- Hart, W.; & Tomazic, T. (1999 agosto). Comparação das distribuições percentis para medidas antropométricas entre três conjuntos de dados. Trabalho apresentado na Reunião Estatística Conjunta Anual, Baltimore, MD.
- Horst, P. (1949). Uma expressão generalizada para a confiabilidade das medidas. Psychometrika, 14, 21-31.
- Khoury, M., James, L., & Erikson, J. (1994). Sobre o uso de controles afetados para abordar o viés de recall em estudos de casos-controle de defeitos de nascença. Teratology, 49, 273-281.
- Loftus, E. (2016, abril). A ficção da memória. Trabalho apresentado na Convenção da Associação Psicológica Ocidental. Long Beach, CA.
- Lowry, R. (2016). Kappa como medida de concordância na ordenação categórica. Obtido de http://vassarstats.net/kappa.html
- Organização para a Cooperação e Desenvolvimento Económico. (2017). Questionário de bem-estar para o PISA 2018. Paris: Autor. Obtido de https://www.oecd.org/pisa/data/2018database/CY7_201710_QST_MS_WBQ_NoNotes_final.pdf
- Schacter, D. L. (1999). Os sete pecados da memória: Insights from psychology and cognitive neuroscience. Psicologia Americana, 54, 182-203.
- Salvucci, S.; Walter, E., Conley, V; Fink, S; & Saba, M. (1997). Estudos de erros de medição no Centro Nacional de Estatística da Educação. Washington D. C.: Departamento de Educação dos EUA.
- Stephens-Davidowitz, S. (2017). Toda a gente mente: Grandes dados, novos dados, e o que a Internet nos pode dizer sobre quem realmente somos. Nova York, NY: Dey Street Books.
>
> Ir para o menu principal
Outros cursos
Procurar Motor

Contacte-me