Update 29-May-2018: Tämän artikkelin tarkoitus on kolminkertainen (1) Osoittaa, että tulemme aina tarvitsemaan tietomallia (joko ihmisten tai koneiden tekemänä) (2) Osoittaa, että fyysinen mallintaminen ei ole sama asia kuin looginen mallintaminen. Itse asiassa se on hyvin erilainen ja riippuu taustalla olevasta teknologiasta. Tarvitsemme kuitenkin molempia. Havainnollistin tätä asiaa käyttämällä Hadoopia fyysisellä tasolla (3) Osoitan muuttumattomuuden käsitteen vaikutuksen tietomallinnukseen.
- Onko dimensiomallinnus kuollut?
- Miksi meidän on mallinnettava tietomme?
- Mihin tarvitsemme dimensiomalleja?
- Tietomallinnus vs. dimensiomallinnus
- Miksi jotkut siis väittävät, että dimensiomallinnus on kuollut?
- Datavaratalo on kuollut Sekaannus
- The Schema on Read -väärinkäsitys
- Denormalisointi uudelleen. Mallin fyysiset näkökohdat.
- Taking de-normalization to its full conclusion
- Datan jakaminen hajautetussa relaatiotietokannassa (MPP)
- Datan jakelu Hadoopissa
- Dimensional Models on Hadoop
- Hadoop ja hitaasti muuttuvat dimensiot
- Tallennuksen kehitys Hadoopissa
- Tuomio. Ovatko dimensiomallit ja tähtikaaviot vanhentuneita?
- Lisälukemista dimensiomallinnuksesta Big Datan aikakaudella
Onko dimensiomallinnus kuollut?
Ennen kuin annan vastauksen tähän kysymykseen, otetaan askel taaksepäin ja tarkastellaan ensin, mitä tarkoitamme dimensiomallinnuksella.
Miksi meidän on mallinnettava tietomme?
Yleisestä väärinkäsityksestä huolimatta tietomallien ainoa tarkoitus ei ole toimia ER-kaaviona fyysisen tietokannan suunnittelussa. Tietomallit kuvaavat yrityksen liiketoimintaprosessien monimutkaisuutta. Ne dokumentoivat tärkeitä liiketoimintasääntöjä ja -käsitteitä ja auttavat standardoimaan yrityksen keskeistä terminologiaa. Ne luovat selkeyttä ja auttavat paljastamaan liiketoimintaprosesseihin liittyviä epäselvyyksiä ja epäselvyyksiä. Lisäksi tietomallien avulla voi kommunikoida muiden sidosryhmien kanssa. Et rakentaisi taloa tai siltaa ilman pohjapiirustusta. Miksi siis rakentaisit datasovelluksen, kuten tietovaraston, ilman suunnitelmaa?
Mihin tarvitsemme dimensiomalleja?
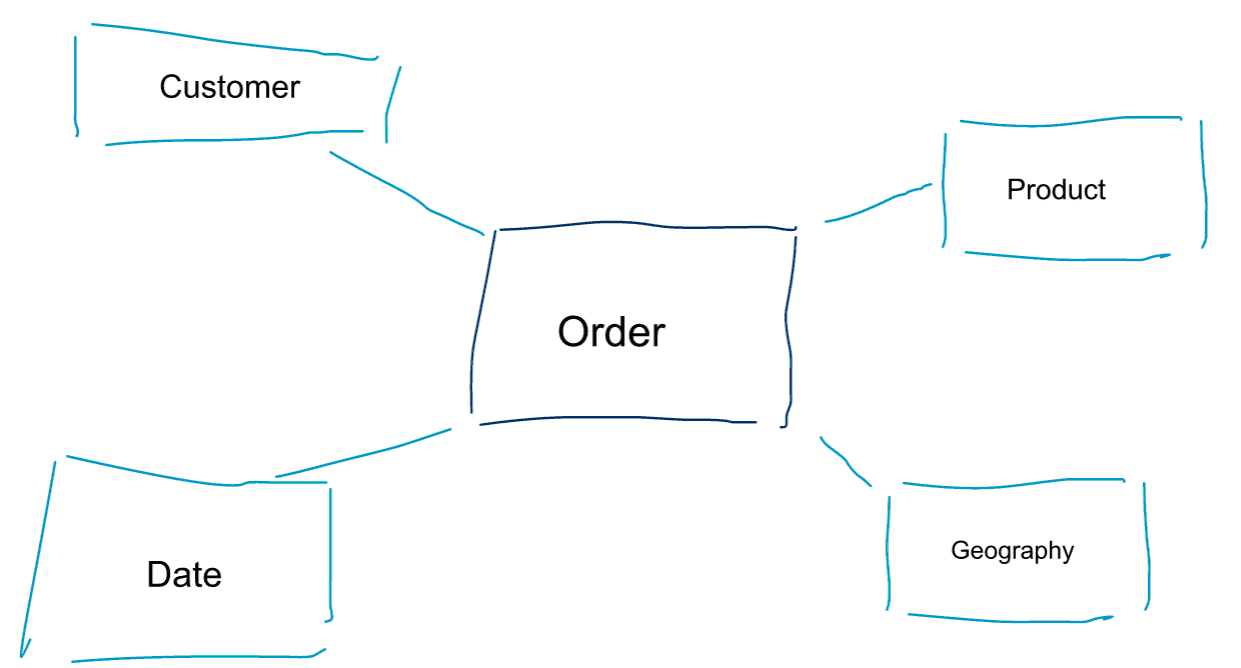
Dimensiomallinnus on erityinen lähestymistapa tiedon mallintamiseen. Käytämme dimensiomallin synonyymeina myös sanoja data mart tai star schema. Tähtikaaviot on optimoitu data-analytiikkaa varten. Tutustu alla olevaan dimensiomalliin. Se on varsin intuitiivinen ymmärtää. Näemme heti, miten voimme pilkkoa tilaustietomme asiakkaan, tuotteen tai päivämäärän mukaan ja mitata Tilaukset-liiketoimintaprosessin suorituskykyä aggregoimalla ja vertailemalla mittareita.
Yksi ulottuvuusmallinnuksen ydinajatuksista on määritellä transaktionaalisen liiketoimintaprosessin alin rakeisuusaste. Kun viipaloimme ja kuutioimme tietoja ja porautumme niihin, tämä on lehtitaso, josta emme voi porautua pidemmälle. Toisin sanottuna tähtikaavion alin rakeisuustaso on faktan liittäminen kaikkiin dimensiotaulukoihin ilman aggregaatioita.
Tietomallinnus vs. dimensiomallinnus
Vakiotietomallinnuksessa pyrimme poistamaan datan toiston ja redundanssin. Kun datassa tapahtuu muutos, meidän tarvitsee muuttaa sitä vain yhdessä paikassa. Tämä auttaa myös tiedon laadussa. Arvot eivät mene sekaisin useissa paikoissa. Katso alla olevaa mallia. Se sisältää erilaisia taulukoita, jotka edustavat maantieteellisiä käsitteitä. Normalisoidussa mallissa jokaiselle entiteetille on oma taulukko. Ulottuvuusmallissa meillä on vain yksi taulukko: maantiede. Tässä taulukossa kaupungit toistuvat useita kertoja. Kerran kutakin kaupunkia kohti. Jos maan nimi muuttuu, joudumme päivittämään maan monessa paikassa
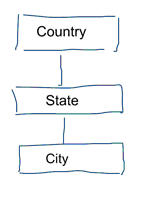
Huomautus: Normaalista tietomallinnuksesta käytetään myös nimitystä 3NF-mallinnus.
Normaali lähestymistapa tietomallinnukseen ei sovellu Business Intelligence -työtehtäviin. Monet taulukot johtavat moniin yhdistämisiin. Joins hidastavat toimintaa. Data-analytiikassa vältämme niitä mahdollisuuksien mukaan. Dimensiomalleissa normalisoimme useita toisiinsa liittyviä taulukoita yhdeksi tauluksi, esimerkiksi edellisen esimerkkimme eri taulukot voidaan yhdistää vain yhdeksi tauluksi: Maantiede.
Miksi jotkut siis väittävät, että dimensiomallinnus on kuollut?
Luotan, että olet samaa mieltä siitä, että tietomallinnus yleensä ja dimensiomallinnus erityisesti on varsin hyödyllistä toimintaa. Miksi jotkut siis väittävät, että dimensiomallinnus ei ole hyödyllistä big datan ja Hadoopin aikakaudella?
Kuten voitte kuvitella, tähän on useita syitä.
Datavaratalo on kuollut Sekaannus
Ensinnäkin jotkut sekoittavat dimensiomallinnuksen ja tietovarastoinnin. He väittävät, että tietovarastointi on kuollut ja sen seurauksena myös dimensiomallinnus voidaan heittää historian roskakoriin. Tämä on loogisesti johdonmukainen väite. Tietovaraston käsite ei kuitenkaan ole suinkaan vanhentunut. Tarvitsemme aina integroituja ja luotettavia tietoja BI-mittaristojen täyttämiseen. Jos haluat lisätietoja, suosittelen Big Data for Data Warehouse Professionals -koulutustamme. Kurssilla syvennyn yksityiskohtiin ja selitän, miten tietovarasto on yhtä ajankohtainen kuin ennenkin. Näytän myös, miten kehittyvät big data -työkalut ja -teknologiat ovat hyödyllisiä tietovarastoinnissa.

The Schema on Read -väärinkäsitys
Toinen usein kuulemani väite menee näin. ’Noudatamme schema on read -lähestymistapaa, eikä meidän tarvitse enää mallintaa tietoja’. Mielestäni schema on read -käsite on yksi data-analytiikan suurimmista väärinkäsityksistä. Olen samaa mieltä siitä, että on hyödyllistä tallentaa raakadata aluksi skeemattomaan datadumppiin. Tätä väitettä ei kuitenkaan pidä käyttää tekosyynä sille, että tietoja ei mallinneta lainkaan. Schema on read -lähestymistapa on vain tölkin alas potkimista ja vastuun siirtämistä myöhemmille prosesseille. Jonkun on silti pureuduttava datatyyppien määrittelyyn. Jokaisen prosessin, joka käyttää skeemattomia datatyyppejä, on itse selvitettävä, mistä on kyse. Tällainen työ kasvaa, on täysin turhaa ja voidaan helposti välttää määrittelemällä tietotyypit ja kunnollinen skeema.
Denormalisointi uudelleen. Mallin fyysiset näkökohdat.
Onko oikeasti olemassa päteviä perusteita julistaa dimensiomallit vanhentuneiksi? On todellakin olemassa parempia argumentteja kuin ne kaksi, jotka olen luetellut edellä. Ne edellyttävät jonkinlaista ymmärrystä fyysisestä tietomallinnuksesta ja Hadoopin toimintatavasta. Kärsivällisyyttä.
Aiemmin mainitsin lyhyesti yhden syyn siihen, miksi mallinnamme datamme dimensiomaisesti. Se liittyy tapaan, jolla data tallennetaan fyysisesti tietovarastoomme. Tavallisessa tietomallinnuksessa jokainen reaalimaailman entiteetti saa oman taulukkonsa. Näin vältämme tietojen päällekkäisyyden ja riskin, että tietojen laatuun liittyvät ongelmat hiipivät tietoihimme. Mitä enemmän taulukoita meillä on, sitä enemmän tarvitsemme liitoksia. Tämä on haittapuoli. Taulukkojen yhdistäminen on kallista, varsinkin kun yhdistämme suuren määrän tietueita tietokokonaisuuksistamme. Kun mallinnamme tietoja dimensiomaisesti, yhdistämme useita taulukoita yhdeksi tauluksi. Sanomme, että esiliitämme tai de-normalisoimme tiedot. Meillä on nyt vähemmän taulukoita, vähemmän yhdistämisiä ja sen seurauksena pienempi latenssi ja parempi kyselysuorituskyky.
Osallistu tämän viestin keskusteluun LinkedInissä
Taking de-normalization to its full conclusion
Miksi ei kannata viedä de-normalisointia loppuun asti? Hankkiudutaan eroon kaikista joinseista ja otetaan vain yksi ainoa faktataulu? Tämä todellakin poistaisi yhdistämisten tarpeen kokonaan. Kuten voitte kuvitella, sillä on kuitenkin joitakin sivuvaikutuksia. Ensinnäkin se lisää tarvittavan tallennustilan määrää. Meidän on nyt tallennettava paljon tarpeetonta tietoa. Kun data-analytiikassa käytetään sarakkeellisia tallennusmuotoja, tämä on nykyään vähemmän ongelma. Normalisoinnin purkamisen suurempi ongelma on se, että aina kun jonkin attribuutin arvo muuttuu, meidän on päivitettävä arvo useaan paikkaan – mahdollisesti tuhansia tai miljoonia päivityksiä. Yksi tapa kiertää tämä ongelma on ladata mallit kokonaan uudelleen joka yö. Usein tämä on paljon nopeampaa ja helpompaa kuin useiden päivitysten tekeminen. Pylvästietokannoissa käytetään yleensä seuraavaa lähestymistapaa. Ne tallentavat datan päivitykset ensin muistiin ja kirjoittavat ne asynkronisesti levylle.
Datan jakaminen hajautetussa relaatiotietokannassa (MPP)
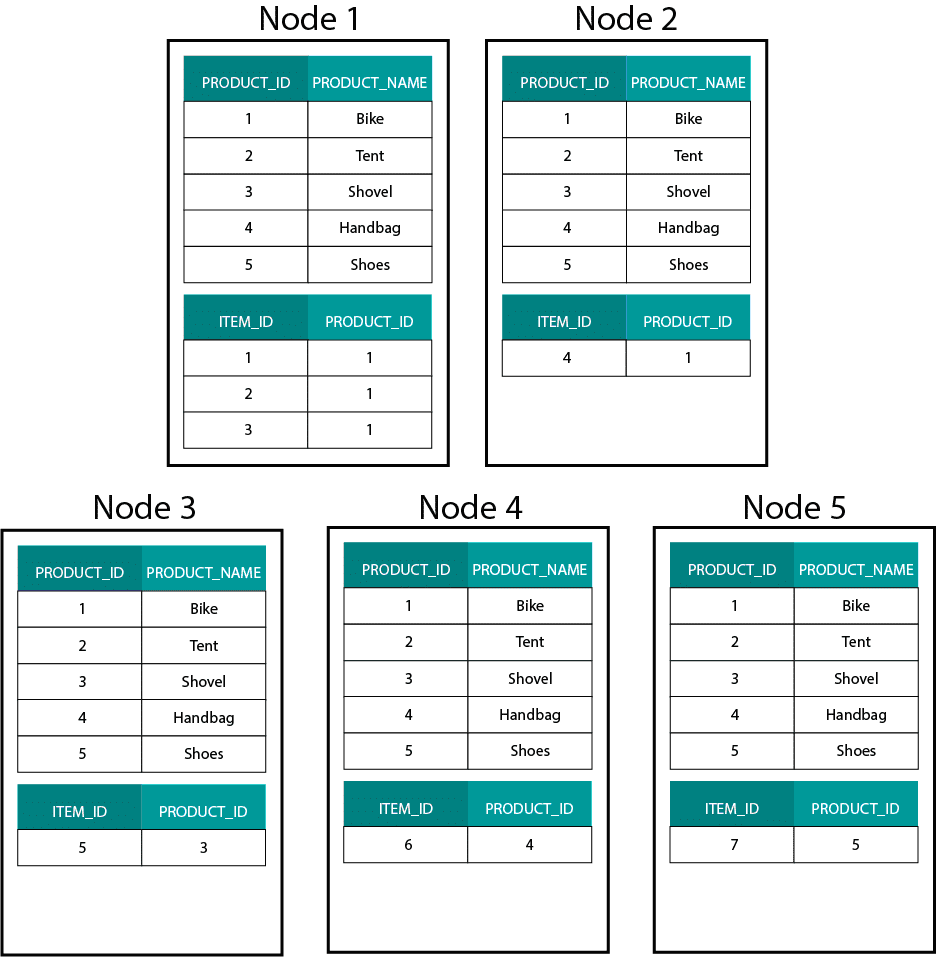
Luotaessamme dimensiomalleja Hadoopissa, esimerkiksi Hivessä, SparkSQL:ssä jne. meidän on ymmärrettävä paremmin yksi tekniikan ydinominaisuus, joka erottaa sen hajautetusta relaatiotietokannasta (MPP), kuten Teradatasta jne. Kun tietoja jaetaan MPP:n solmuihin, voimme hallita tietueiden sijoittelua. Osiointistrategian (esim. hash, lista, alue jne.) perusteella voimme sijoittaa yksittäisten tietueiden avaimet saman solmun eri välilehdille. Kun tietojen yhteissijaisuus on taattu, yhdistymiset ovat erittäin nopeita, koska meidän ei tarvitse lähettää tietoja verkon yli. Katso alla olevaa esimerkkiä. Tietueet, joilla on sama ORDER_ID ORDER- ja ORDER_ITEM-taulukoista, päätyvät samaan solmuun.
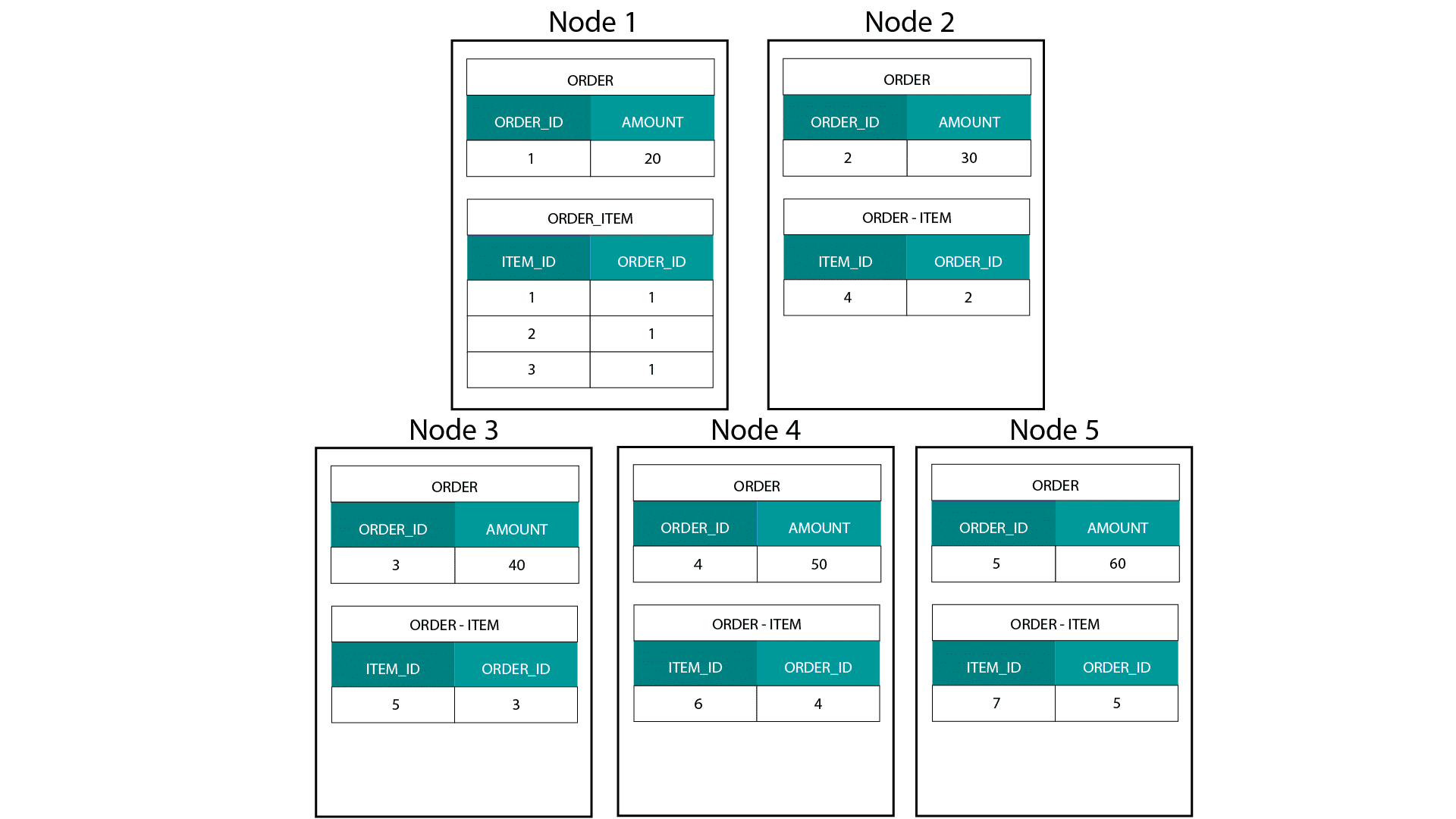
Order- ja order_item-taulukoiden order_id:n avaimet sijaitsevat samoissa solmuissa.
Datan jakelu Hadoopissa
Tämä eroaa hyvin paljon Hadoop-pohjaisista järjestelmistä. Siellä jaamme datamme suuriin palasiin ja jaamme ja replikoimme sen solmuihin Hadoopin hajautetussa tiedostojärjestelmässä (HDFS). Tällä datan jakelustrategialla emme voi taata datan samanaikaisuutta. Katso alla olevaa esimerkkiä. ORDER_ID-avaimen tietueet päätyvät eri solmuihin.
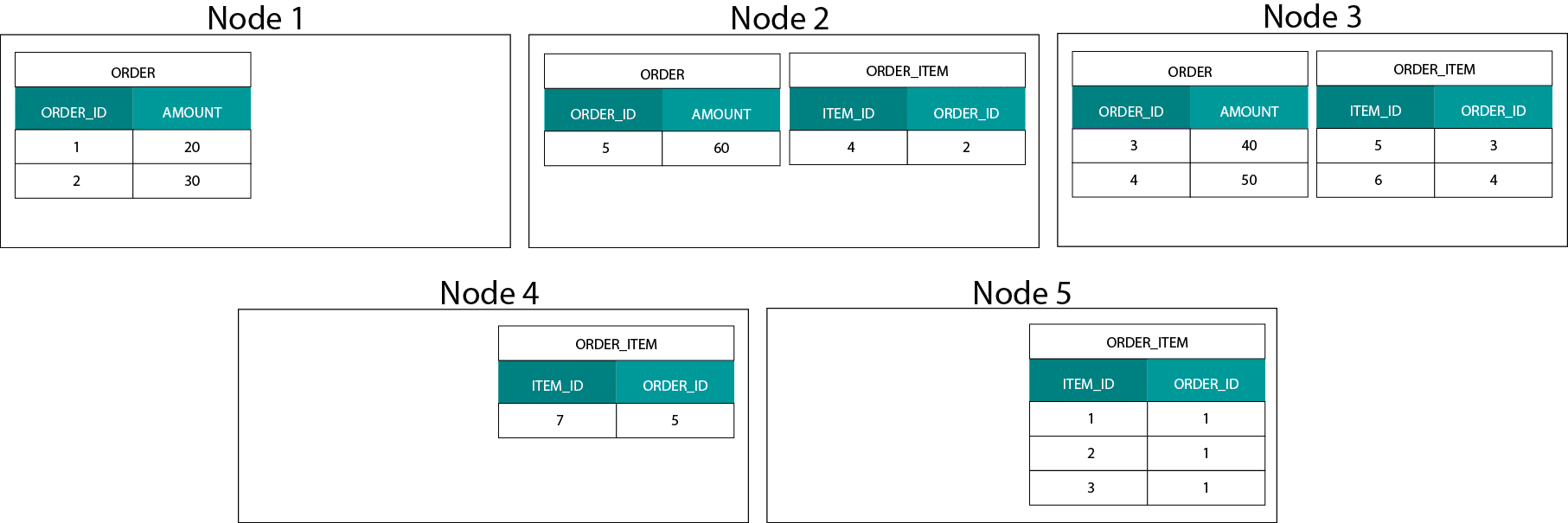
Yhteenliittymistä varten meidän on lähetettävä dataa verkon yli, mikä vaikuttaa suorituskykyyn.
Yksi strategiaksi tämän ongelman ratkaisemiseksi on replikoida yksi yhteenliittymistaulukoista klusterin kaikkiin solmuihin. Tätä kutsutaan broadcast joiniksi, ja käytämme samaa strategiaa MPP:ssä. Kuten voitte kuvitella, se toimii vain pienille lookup- tai dimensiotaulukoille.
Mitä sitten teemme, kun meillä on suuri faktataulu ja suuri dimensiotaulu, esimerkiksi asiakas tai tuote? Tai itse asiassa silloin, kun meillä on kaksi suurta faktataulukkoa.
Dimensional Models on Hadoop
Tämän suorituskykyongelman kiertämiseksi voimme de-normalisoida suuret dimensiotaulukot faktataulukkoon, jotta voimme taata, että tiedot ovat rinnakkain. Voimme lähettää pienemmät dimensiotaulukot kaikkiin solmuihimme.
Kahden suuren faktataulukon yhdistämistä varten voimme sijoittaa pienemmän rakeisuuden omaavan taulukon suuremman rakeisuuden omaavan taulukon sisälle, esimerkiksi suuren ORDER_ITEM-taulun, joka on sijoitettu ORDER-taulun sisälle. Nykyaikaiset kyselymoottorit, kuten Impala tai Drill, mahdollistavat tämän datan litistämisen

Tämä tiedon pesäkkeistämisstrategia on hyödyllinen myös tuskallisissa Kimball-konsepteissa, kuten silta-taulukoissa, joilla voidaan esittää M:N-suhteita dimensiomallissa.
Hadoop ja hitaasti muuttuvat dimensiot
Tallennustila Hadoopin tiedostojärjestelmässä on muuttumaton. Toisin sanoen voit vain lisätä ja liittää tietueita. Et voi muokata tietoja. Jos tulet relaatiotietovarastotaustasta, tämä voi aluksi tuntua hieman oudolta. Konepellin alla tietokannat toimivat kuitenkin samalla tavalla. Ne tallentavat kaikki tietoihin tehdyt muutokset muuttumattomaan write ahead -lokiin (joka tunnetaan Oraclessa nimellä redo log), ennen kuin prosessi päivittää datatiedostojen tiedot asynkronisesti.
Mitä vaikutusta muuttumattomuudella on dimensiomalleihimme? Muistat ehkä hitaasti muuttuvien ulottuvuuksien (Slowly Changing Dimensions, SCD) käsitteen ulottuvuusmallinnuskurssiltasi. SCD:t säilyttävät valinnaisesti attribuuttien muutoshistorian. Niiden avulla voimme raportoida mittareita attribuutin arvoa vastaan tiettynä ajankohtana. Tämä ei kuitenkaan ole oletuskäyttäytyminen. Oletusarvoisesti päivitämme dimensiotaulukot uusimmilla arvoilla. Mitä vaihtoehtoja meillä on Hadoopissa? Muista! Emme voi päivittää tietoja. Voimme yksinkertaisesti tehdä SCD:stä oletuskäyttäytymisen ja tarkastaa kaikki muutokset. Jos haluamme ajaa raportteja nykyisten arvojen perusteella, voimme luoda SCD:n päälle näkymän, joka hakee vain uusimman arvon. Tämä voidaan tehdä helposti ikkunointitoimintojen avulla. Vaihtoehtoisesti voimme käyttää niin sanottua tiivistämispalvelua, joka luo fyysisesti erillisen version dimensiotaulukosta, jossa on vain viimeisimmät arvot.
Tallennuksen kehitys Hadoopissa
Hadoop-alustojen toimittajat eivät ole jääneet huomaamatta näitä Hadoopin rajoituksia. Hivessä on nyt ACID-transaktiot ja päivitettävät taulukot. Avoimien suurten ongelmien määrän ja oman kokemukseni perusteella tämä ominaisuus ei kuitenkaan näytä olevan vielä tuotantokelpoinen . Cloudera on omaksunut erilaisen lähestymistavan. Kudun avulla he ovat luoneet uuden päivitettävän tallennusmuodon, joka ei sijaitse HDFS:ssä vaan käyttöjärjestelmän paikallisessa tiedostojärjestelmässä. Se pääsee kokonaan eroon Hadoopin rajoituksista ja on samanlainen kuin perinteinen tallennuskerros sarakkeellisessa MPP:ssä. Yleisesti ottaen BI- ja kojelautakäyttötapaukset on todennäköisesti parempi toteuttaa MPP:ssä, esimerkiksi Impala + Kudu, kuin Hadoopissa. Tästä huolimatta MPP:llä on omat rajoituksensa joustavuuden, samanaikaisuuden ja skaalautuvuuden osalta. Kun näihin rajoituksiin törmää, Hadoop ja sen lähiserkku Spark ovat hyviä vaihtoehtoja BI-työmäärille. Käsittelemme kaikkia näitä rajoituksia Big Data for Data Warehouse Professionals -koulutuksessamme ja annamme suosituksia, milloin kannattaa käyttää RDBMS:ää ja milloin SQL:ää Hadoopissa/Sparkissa.
Tuomio. Ovatko dimensiomallit ja tähtikaaviot vanhentuneita?
Me kaikki tiedämme, että Ralph Kimball on jäänyt eläkkeelle. Mutta hänen periaatteelliset ideansa ja käsitteensä ovat edelleen voimassa ja elävät edelleen. Meidän on mukautettava niitä uusiin teknologioihin ja tallennustyyppeihin, mutta ne tuovat edelleen lisäarvoa.
Opeta minulle Big Data edistämään uraani
Lisälukemista dimensiomallinnuksesta Big Datan aikakaudella
Tom Breur: The Past and Future of Dimensional Modeling
Edosa Odaro: 5 radikaalia vinkkiä nopeaan Big Data -integraatioon – Anti Data Warehouse Pattern